优化基础知识点分享
Posted 海洋_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优化基础知识点分享相关的知识,希望对你有一定的参考价值。
很久没写博客了,由于负责的项目比较多,Unity项目,UE项目,无法分身,这次利用闲暇时刻,在程序员节日1024来临之际写一篇优化相关的基础文章,给研发人员一点小小的提示吧。
优化和项目品质二者是相生相克的,既要追求好的品质,又要追求好的效率,如何在二者之间找到一个平衡点,是研发团队绞尽脑汁要去平衡的事情,Epic团队内部也在追求二者的平衡点,如下图所示:
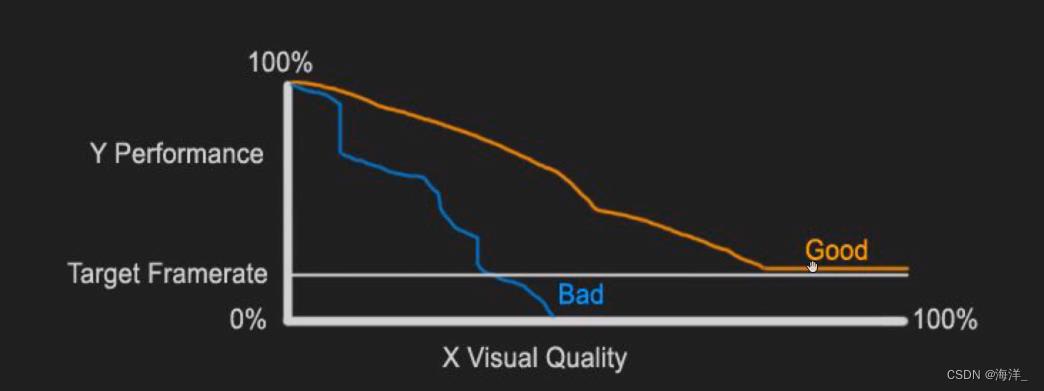
在追求效率时,会损失一些品质方面的东西,那在项目优化时关注那几个点呢?在移动端主要关注的点是:
一、手机发热,电池消耗过快,手机升温(平均在55度以下),每次温度高了,QA都会叫,让引擎和项目组去查看问题出在哪里?
二、游戏低帧,卡顿(30帧 建议最低在25帧左右),低帧率和卡帧是不一样的,低帧率是在某个时间段的帧率,卡顿是在某个时刻,卡顿在项目中所占的比重应该在2-3%左右,是允许存在的,比如在加载资源时刻,在GC时刻,但是也是有概率限制的,不能频繁的卡顿。低帧率是不允许的
三、游戏闪退(内存占比),这个就要看PSS峰值,内存泄漏相关的BUG
在项目里如何解决上述的问题,是项目优化重点关注的点,当然这些只是表面东西,落实到项目中主要是落实如下问题:
1、什么原因导致的手机耗电快,温度升的快?
2、为什么通过判断DrawCall/Batches的数值知道CPU压力大?
3、如何选择合批技术?
4、如何减少CPU/GPU压力?
5、OverDraw是如何产生的?为什么OverDraw耗费性能?
6、为什么UE里面叫 Quad OverDraw?
7、。。。。。。。。。。。。。。。。。。。
在项目优化时,我们首先关注的点是合批,合批要解决的问题是什么?在这里给大家在强调一遍:
1、合批只是对CPU的优化,与GPU没有任何关系
2、合批是节省了CPU的相关准备工作的工作量
3、批量渲染是通过减少CPU向GPU发送渲染命令(DrawCall)的次数,以及减少GPU切换渲染状态的次数,尽量让GPU一次多做一些事情,来提升逻辑线和渲染线的整体效率
看到了吧,以后QA再提起DC高,找引擎渲染的时候,直接告诉他,这个是CPU端的问题,与GPU没半毛钱关系,为此NVIDIA专门做了测试,如下图所示:
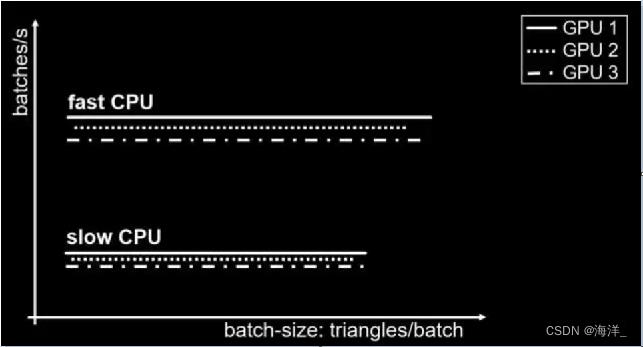
上图展示了:
1、每秒钟能够处理的Batch数量跟CPU的性能有非常直接的关系。
2、GPU的性能对每秒能够处理的Batch数量影响比较小。
3、不同的Batch大小似乎对每秒能够处理的Batch数量没有影响
另外大家在面试的时候,面试官经常会问,你们项目场景面数是多少,在这里也给大家强调一遍,并不是真正的模型面数,给大家分享一下数据和相关的知识点,这样你就不用再为面试的问题而发愁了。
1、在低端机型上将同屏渲染面片数控制在30万面以内,即便是高端机也不建议超过60万面
2、当前帧所渲染的面片数,其数值不仅与模型面片数有关,也和渲染次数相关;
例如:场景中的网格模型面片数为1万,而其使用的Shader拥有2个渲染Pass,或者有2个相机对其同时渲染;又或者使用了SSAO、Reflection等后处理效果中的一个,那么此处所显示的Triangle数值将为2万。
优化时会重点关注某帧的数据,在一帧中,大致的流程为:
1、CPU执行一系列运算后确定动画、网格和材质信息
项目中存在大量零散琐碎的物体;有大量可以共用材质的物体却没有共用材质;有大量复杂的动画运算和蒙皮运算等,这些都会使CPU计算和收集渲染数据的时间延长。
2、CPU发起DrawCall
该阶段产生的性能问题就是常说的 带宽问题,CPU 与 GPU 用于传递数据的通道,尤其对于移动端,由于移动端的 CPU 和 GPU 间的带宽本来就较小,且移动端 CPU 和 GPU 都在一块芯片上,共用一整块功率,当出现带宽问题时,使用功率上升,导致手机发热较快。 贴图占用内存过大、网格数据占用内存过大、一些大物体在CPU端视锥体检测无法被筛掉等,这些都会触发带宽问题。
内存带宽:以最低分辨率1280x720计算,一个屏幕缓冲区加上深度缓冲检测,每个像素需要6byte,然后以60帧/s的帧率要求,乘起来的结果是:绘制一屏幕数据(1 overdraw),需要的带宽至少是331776000bytes,也就是0.316Gbytes。不过,由于透明物体需要和原屏幕像素进行混合,所以还需要回读一次屏幕缓冲区的数据,会增加接近一倍,0.527Gbytes。再加上后处理渲染,全屏特效特别容易到达高值
如何减少带宽:移动端贴图建议使用ASTC6x6进行压缩,压缩后效果不行,可以换为 ASTC4x4。对于 HDR 贴图 可以采样 ASTC HDR 6x6 或 4x4 的压缩格式。
贴图大小:贴图大小就是尽可能的小。
Mipmap:对于始终只出现在很远处的物体,其贴图尺寸我们可以给很小,并且不需要生成 Mipmap。 同样对于始终只出现在很近处的物体,我们可以给个较大的贴图尺寸,并且不需要生成 Mipmap。
3、GPU收到DrawCall和数据开始渲染
该阶段导致性能问题的就是 DrawCall 的数量 和 DrawCall 本身的复杂度了,DrawCall 其耗时就是本身指令执行的耗时。通常我们认为渲染在GPU上有性能问题时,往往最终是由于 DrawCall 数过多导致GPU开始渲染的时间节点被大幅延迟导致的。该合批的没有合批、该用同一个材质的没有用同种材质、美术资源的制作上导致合批困难、材质有大量的属性和变量等,都会导致 DrawCall 数量的上升 和 DrawCall本身指令的复杂化。
4、在GPU渲染的同时 CPU 可继续向后运行
这一阶段会产生性能问题的主要原因有:渲染顺序的不合理和特效面片的不合理导致过多的Overdraw、Shader中冗余或复杂的计算、贴图或网格数据过大导致运算时加载数据过慢、对于移动端 一些骚操作或者不合理的渲染流程还会触发 TileBase 架构的 GMEM_Load 操作导致渲染过程变慢。
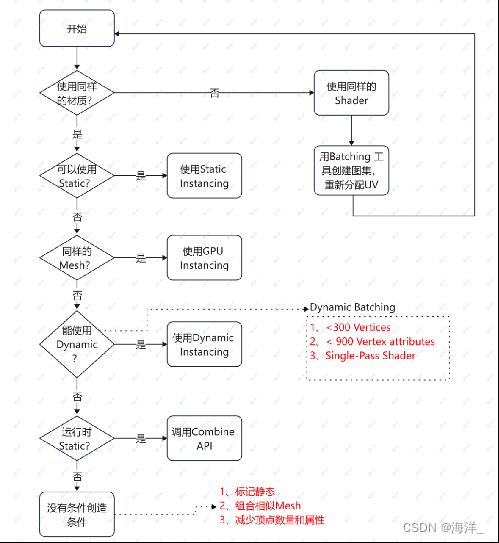
合批常用的是静态合批,动态合批,GPU Instancing合批等等等。
在静态合批方面做了数据测试供大家参考:
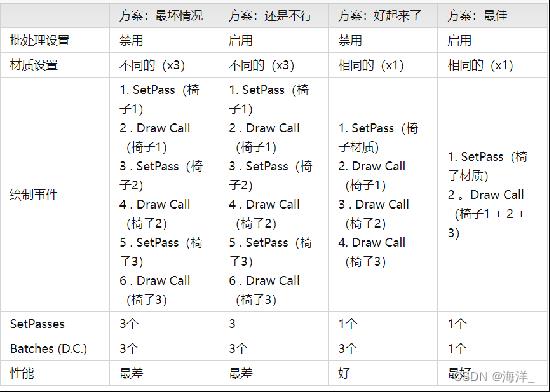
静态批处理复杂场景不要用,可能会导致渲染队列混乱,产生严重的OverDraw而且会增大内存占用
LightMap无法使用合批(包括静态合批,GPU合批);阴影会增加Batches数量;使用图集减少显存的吞吐量。
静态批处理并不减少Draw call的数量,但是由于我们预先把所有的子模型的顶点变换到了世界空间下,并且这些子模型共享材质,所以在多次Draw call调用之间并没有渲染状态的切换,渲染API会缓存绘制命令,起到了渲染优化的目的。
开启静态批处理,在Unity执行Build的时候,场景中所有引用相同模型的GameObject都必须将模型顶点信息复制,并经过计算变化到最终在世界空间中,存储在最终生成的Vertex buffer中。这就导致了打包的体积及运行时内存的占用增大。
比如说,四个物体要静态批次合并前三个物体每个顶点只需要位置,第一套uv坐标信息,法线信息,而第四个物体除了以上信息,还多出来切线信息,则这个VBO会在每个顶点都包括所有的四套信息,毫无疑问组合这个VBO是要对CPU和显存有额外开销的。要求每一次Static Batching使用同样的material,但是对mesh不要求相同。
Unity默认策略是优先static,其次gpu instancing,最后dynamic
再介绍一下OverDraw,
1、OverDraw会导致GPU每帧处理理时间增加,导致渲染帧率差。
2、后处理效果(例如 color grading)会对每个像素至少计算一次,由于它重画了屏幕上的每个像素,这直接增加了100%(1.0x)的OverDraw。
3、OverDraw会增加游戏渲染消耗的内存带宽
4、UI,特效,绘制顺序等
半透的OverDraw:

特效OverDraw:

UI的OverDraw

当Overdraw过高的时候,即使shader性能再好,也会导致填充率过高的问题,这时候需要同时考虑的是去优化overdraw,比如特效,因为填充率一旦超过瓶颈(读者可根据实际情况自己去测试,一般超过4倍就有些严重了),GPU耗时高手机发热等问题无法避免了, 这种情况下性能再好的shader也无法发挥作用了)
场景中MipMap的使用,通过数据对比,大家就一目了然了:
比如渲染如下的场景地形,有Mipmap和没有MipMap的数据对比:

无MipMap消耗时间:

有MipMap消耗时间:
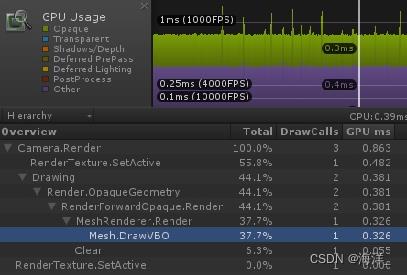
产生的主要原因是:Texture Catch Missing
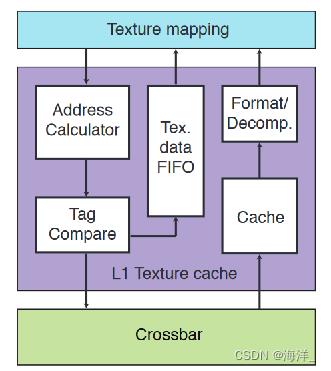
不论Unity引擎还是UE引擎,为什么要压缩贴图:
1、可以节省带宽,解压缩发生在读取压缩的纹理和准备 texture filter之间
2、因为cache中存储的是压缩的texel,所以能增加tex cache中存储texel的数量,因为解压缩是在数据出tex cache后在tex unit中进行的。
3、FIFO先入先出的队列数据流,排在后面的尽管被缓存命中也要等待排在前面的没有命中的部分
如下图所示:
在项目优化中,我们会使用很多工具,这里给大家列举一下:
Unity:OverDraw可视化模式
RenderDoc OverDraw分析
使用Compute Shader测量OverDraw
Snapdragon Profiler
Mali GPU工具
XCode
另外,Unity使用不带Z-Write的附加着色器来显示它,因此你将看到的大多数不透明对象上的OverDraw都是假的。正常情况下,很多不透明元素的渲染会被Z-Test剔除掉。
减少OverDraw的方法:
避免因为大量三角形占据面积小于一个像素带来的OverDraw(UE5的Nanite)
通过将渲染队列更改为Geometry-1,Geometry + 1等来手动设置Unity渲染顺序)
减少半透明渲染产生的OverDraw
对于由于渲染顺序不合理导致的 Overdraw,就只有自己根据实际情况去调整渲染队列了。例如对于一个 有河流、草、树木 和 地面的场景,我们应该 先渲染草,然后渲染树木的树叶、之后是树木、接着是地面,最后是河流。这样在渲染地面时,地面就会有大量像素因为被草和树木遮挡而没能通过深度测试,也就没有被光栅化渲染,从而减少了Overdraw。而因为河流是一个半透明物体(我们可以透过河流看到河水下面的地面),因此河流需要在地面渲染之后才渲染,这样才能和地面做半透明混合。
再介绍闪退相关的:
PSS(Proportional Set Size)内存,其含义为一个进程在RAM中实际使用的空间地址大小,即实际使用的物理内存。就结果而言,当一个游戏进程中PSS内存峰值越高、占当前硬件的总物理内存的比例越高,则该游戏进程被系统杀死(闪退)的概率也就越高。
避免游戏闪退的重点在于控制PSS内存峰值。而PSS内存的大头又在于Reserved Total中的资源内存和Mono堆内存。对于使用Lua的项目来说,还应关注Lua内存。
只有当PSS内存峰值控制在硬件总内存的0.5-0.6倍以下的时候,闪退风险才较低。举例而言,对于2GB的设备而言,PSS内存应控制在1GB以下为最佳,3GB的设备则应控制在1.5GB以下。
终极优化DrawCall方案:
GPU_Driven_Pipeline是一种为了减少CPU提交次数的充分利用GPU性能的一种绘制技术。为了让绘制更加高效,更加合理,又加入了各种变种的剔除算法,绘制优化等优化算法等。
Indirect Draw也就是间接绘制,不是由CPU指定绘制目标,而是由GPU自行支配,这种时候我们就可以把模型数据长存在显存中,比如使用贴图或者StructuredBuffer储存顶点数据,然后Indirect Draw则会提供给Vertex Shader一个索引整数值,开发者则需要在Shader中手动读取显存,获取模型数据。

优化的知识点比较琐碎,本篇文章只是介绍了冰山一角,CPU和GPU都有涉及,后面有时间了再深入的介绍代码相关的优化方案。
最后祝程序员节日快乐,1024节日快乐!
以上是关于优化基础知识点分享的主要内容,如果未能解决你的问题,请参考以下文章