HDFS—存储优化(纠删码)
Posted 刘元涛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS—存储优化(纠删码)相关的知识,希望对你有一定的参考价值。
纠删码原理
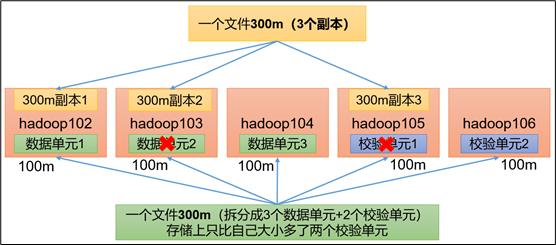
HDFS 默认情况下,一个文件有3个副本,这样提高了数据的可靠性,但也带来了2倍的冗余开销。
Hadoop3.x 引入了纠删码,采用计算的方式,可以节省约50%左右的存储空间。
此种方式节约了空间,但是会增加 cpu 的计算。
纠删码策略是给具体一个路径设置。所有往此路径下存储的文件,都会执行此策略。
默认只开启对 RS-6-3-1024k 策略的支持,如要使用别的策略需要提前启用。
1 )纠删码操作相关的命令
2 )查看当前支持的纠删码策略

3 )纠删码策略解释
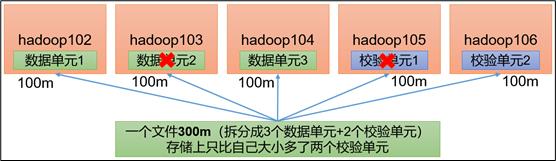
** RS-3-2-1024k *** :**使用 RS 编码,每3个数据单元,生成2个校验单元,共5个单元,也就是说:这5个单元中,只要有任意的3个单元存在(不管是数据单元还是校验单元,只要总数=3),就可以得到原始数据。每个单元的大小是1024k=1024 1024=1048576。
** RS-10-4-1024k *** :**使用RS编码,每10个数据单元(cell),生成4个校验单元,共14个单元,也就是说:这14个单元中,只要有任意的10个单元存在(不管是数据单元还是校验单元,只要总数=10),就可以得到原始数据。每个单元的大小是1024k=1024 1024=1048576。
** RS-6-3-1024k *** :**使用RS编码,每6个数据单元,生成3个校验单元,共9个单元,也就是说:这9个单元中,只要有任意的6个单元存在(不管是数据单元还是校验单元,只要总数=6),就可以得到原始数据。每个单元的大小是1024k=1024 1024=1048576。
** RS-LEGACY-6-3-1024k ****:**策略和上面的 RS-6-3-1024k 一样,只是编码的算法用的是 rs-legacy 。
** XOR-2-1-1024k *** :**使用XOR编码(速度比RS编码快),每2个数据单元,生成1个校验单元,共3个单元,也就是说:这3个单元中,只要有任意的2个单元存在(不管是数据单元还是校验单元,只要总数= 2),就可以得到原始数据。每个单元的大小是1024k=1024 1024=1048576。
4)具体步骤
(1)开启对 RS-3-2-1024k 策略的支持
[lytfly@node101 hadoop]$ hdfs ec -enablePolicy -policy RS-3-2-1024k
Erasure coding policy RS-3-2-1024k is enabled
(2)在 HDFS 创建目录,并设置 RS-3-2-1024k 策略
[lytfly@node101 hadoop]$ hdfs dfs -mkdir /input
[lytfly@node101 hadoop]$ hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
(3)上传文件,并查看文件编码后的存储情况
[lytfly@node1 hadoop-3.1.4]$ hdfs dfs -put web.log /input
注:你所上传的文件需要大于2M才能看出效果。(低于2M,只有一个数据单元和两个校验单元) (4)查看存储路径的数据单元和校验单元,并作破坏实验
以上是关于HDFS—存储优化(纠删码)的主要内容,如果未能解决你的问题,请参考以下文章