PANNs:用于音频模式识别的大规模预训练音频神经网络
Posted AI 菌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PANNs:用于音频模式识别的大规模预训练音频神经网络相关的知识,希望对你有一定的参考价值。
文章目录
摘要
音频模式识别是机器学习领域的一个重要研究课题,它包括音频标注、声音场景分类、音乐分类、语音情感分类和声音事件检测等任务。近年来,神经网络已被应用于解决音频模式识别问题。然而,以前的系统是建立在特定数据集上的,数据集时长有限。
最近,在计算机视觉和自然语言处理中,在大规模数据集上进行预训练的系统已经很好地推广到一些任务上了。然而,在大规模数据集上进行音频模式识别的预训练系统的研究还很有限。本文提出了在大规模音频数据集上训练的预训练音频神经网络(PANN)。
本文提出了一种同时使用对数-梅尔谱和波形作为输入特征的Wavegram-Logmel-CNN结构。本文最好的PAN系统在Audioset标签上达到了最先进的平均平均精度(MAP)0.439,超过了之前最好的系统0.392。本文将PAN迁移到六个音频模式识别任务中,并在其中几个任务中展示了最先进的性能。
源码和预训练模型见: https://github.com/qiuqiangkong/audioset_tagging_cnn
1、引言
音频模式识别的一个里程碑是AudioSet的发布,这是一个包含超过5,000小时的527个声音类别的音频记录的数据集。AudioSet没有发布原始音频记录,而是发布了从预先训练的卷积神经网络中提取的音频片段的编码特征。一些研究人员已经研究了具有编码特征的 building systems。
然而,编码特征可能不是音频记录的最佳表示,这可能限制那些系统的性能。在本文中,提出了使用多种神经网络对原始音频集录音进行训练的预训练音频神经网络(PANN)。本文显示了几个PAN系统比以前最先进的音频标记系统性能更好。我们还研究了PANN的音频标记性能和计算复杂性。
我们提出将PANN迁移到其他音频模式识别任务中。以前的研究人员已经研究了音频标记的迁移学习。例如,在《Transfer learning by supervised pre-training for audio-based music classification》中提出的百万首歌曲数据集上对音频标签系统进行预训练,从预训练的卷积神经网络(CNN)中提取的编码特征被用作第二阶段分类器的输入,例如神经网络或支持向量机(SVMs)。在MagnaTagATune和声学场景数据集上预先训练的系统在其他音频标记任务上进行了微调。这些迁移学习系统主要使用音乐数据集进行训练,并且限于比AudioSet更小的数据集。
本文的主要工作包括:
- 介绍了2020年8月23日在AudioSet上训练的两个具有190万个音频片段和527个声音类的本体的PANN;
- 研究了各种PANN的音频标记性能和计算复杂度之间的权衡;
- 提出了一个称为Wavegram-Logmel-CNN的系统,它在音频集标注上达到了0.439的平均精度(MAP),超过了以前最先进的系统MAP 0.392和Google的MAP 0.314;
- 证明了PANN可以转移到其他音频模式识别任务,性能优于几个最先进的系统;
2、音频标记系统
音频标记是音频模式识别的一项基本任务,其目的是预测音频片段中音频标记的存在与否。音频标记的早期工作包括使用手动设计的特征作为输入,如音频能量、过零率和梅尔频率倒谱系数(MFCC)。
生成模型,包括高斯混合模型(GMM)、隐马尔可夫模型(HMM)和判别支持向量机(SVMS)已经被用作分类器。最近,卷积神经网络(CNN)等基于神经网络的方法被用来预测音频记录的标签。基于CNN的系统在几个DCASE挑战任务中取得了最先进的性能,包括声学场景分类和声音事件检测。
然而,这些作品中的许多都集中在特定的任务上,声音类的数量有限,并且没有被设计成识别广泛的声音类。本文重点是在AudioSet上训练大规模的PANNs来解决一般的音频标记问题。
2.1 CNNs
- 普通卷积层:每个卷积层包含几个核,这些核与输入特征图卷积以捕获其局部模式。用于音频标记的CNN通常使用LOG Mel谱图作为输入。将短时傅立叶变换(STFT)应用于时间域波形以计算频谱图。然后,对谱图应用Mel滤波器组,然后进行对数运算以提取对数Mel谱图。
- 使CNN适应于AudioSet标注:本文使用的PANN是基于我们之前为DCASE 2019挑战提出的跨任务CNN系统,在CNN的倒数第二层增加了一个额外的完全连接层进一步提高表象能力。本文将大小为2×2的平均池化应用于每个卷积块用于下采样,因为2×2平均池化已被证明优于2×2最大池化。

- 使用二进制交叉熵损失函数来训练PANN:

2.2 ResNets
- ResNets:对于音频分类,较深的CNN比较浅的CNN具有更好的性能。非常深的传统CNN的一个挑战是,梯度不能从顶层正确地传播到底层。为了解决这个问题,ResNets[32]在卷积层之间引入了快捷连接。这样,前向和后向信号可以从一个层直接传播到任何其他层。捷径连接只引入少量的额外参数和少量的额外计算复杂性。一个ResNet由多个块组成,每个块由两个核大小为3×3的卷积层组成,以及输入和输出之间的快捷连接。每个瓶颈块由三个卷积层组成,该卷积层具有网络中的网络体系结构,其可以用来代替ResNet中的基本块[。
- 为AudioSet标记调整的ResNet:我们对ResNet进行如下调整以用于AudioSet标记。首先,在对数MEL谱图上应用两个卷积层和一个下采样层,以减小输入的对数MEL谱图大小。我们实现了三种不同深度的ResNet:22层8个基本块的ResNet,38层16个基本块的ResNet,以及16个剩余块的54层ResNet。表二显示了适用于AudioSet标签的ResNet系统的架构。BasicB和BotchieckB分别是基本块和瓶颈块的缩写。

2.3 MobileNets
- 传统的MobileNets:当系统在便携式设备上实现时,计算复杂性是一个重要的问题。与CNN和ResNet相比,MobileNets的目的是减少CNN中的参数数量和乘加运算。通过将标准卷积分解为深度卷积和1×1逐点卷积,MobileNet基于深度可分离卷积。
- 使MobileNets适应AudioSet标签:我们采用MobileNetV1和MobileNetV2系统进行音频集标记,如表III所示。V1块和V2块是MobileNet卷积块,分别由两层和三层卷积层组成。

2.4 一维CNNs
以前的音频标记系统是基于Log Mel谱图的,这是一种手工制作的功能。为了提高性能,一些研究人员提出建立一维CNN,直接在时域波形上操作。例如,戴等人提出了一种基于一维CNN的声学场景分类方法,Lee等人提出了一种新的分类方法。
- DaiNet:DaiNet将长度为80且跨度为4的核应用于音频记录的输入波形。这些核是可以在训练中学习的。首先,对第一卷积层进行最大值运算,使系统对输入信号的相移具有较强的鲁棒性。然后,利用核大小为3、步长为4的一维卷积块提取高层特征。在UrbanSound8K分类中,每个卷积块有四个卷积层的18层DAINet获得了最好的结果。
- LeeNet:与DaiNet在第一层应用大核不同,LeeNet[42]在波形上应用了长度为3的小核,以取代谱图提取的STFT。LeeNet由几个一维卷积层组成,每个卷积层后面跟着一个大小为2的下采样层。最初的LeeNet由11层组成。
- 一维CNN在音频集标注中的应用:我们对LeeNet进行了改进,将其扩展到具有24层的更深层次的体系结构,将每个卷积层替换为由两个卷积层组成的卷积块。为了进一步增加一维CNN的层数,我们提出了一个小核尺寸为3的一维残差网络(Res1dNet)。我们用残差块代替LeeNet中的卷积块,每个残差块由两个核大小为3的卷积层组成。卷积块的第一层和第二卷积层分别有1和2的膨胀,以增加相应残留块的接受场。在每个残差块之后应用下采样。通过使用14和24个剩余块,我们分别获得了具有31层和51层的Res1dNet31和Res1dNet51。
3、Wavegram-CNN 系统
以前的一维CNN系统没有比以对数-梅尔谱作为输入训练的系统性能更好。以前的时域CNN系统的一个特点是它们不是被设计来捕获频率信息的,因为在一维CNN系统中没有频率轴,所以它们不能捕获具有不同基音偏移的声音事件的频率模式。
3.1 Wavegram-CNN systems
频率模式对于音频模式识别很重要,例如,具有不同基音移位的声音属于同一类别。波形图被设计用来学习一维CNN系统中可能缺乏的频率信息。通过从数据中学习一种新的时频变换,波形图还可以改进手工制作的对数MEL频谱图。然后,波形图可以取代对数梅尔谱图作为输入特征,从而产生我们的波形图CNN系统。我们还将Wavegram和log Mel谱图作为新的特征相结合,构建了Wavegram-LogmelCNN系统,如图1所示。

为了建立波形图,我们首先将一维CNN应用于时间域波形。一维CNN从卷积层开始,滤波器层的长度为11,步长为5,以减小输入的大小。这会立即将输入长度减少到原来的1/5,从而减少内存使用量。紧随其后的是三个卷积块,其中每个卷积块由分别具有1和2膨胀的两个卷积层组成,被设计来增加卷积层的感受野。
我们将一维CNN层的输出大小表示为T×C,其中T是帧的数量,C是频道的数量。我们通过将C个通道分成C/F组来将该输出重塑为大小为T×F×C/F的张量,其中每组具有F个频率单元。我们称这个张量为波形图。波形图通过在每个C/F通道中引入F个频率仓来学习频率信息。我们在提取的波形图上应用了第II-A节中描述的CNN14作为主干架构,这样我们就可以公平地比较基于波形图和对数梅尔谱的系统。像CNN14这样的二维CNN可以捕获波形图上的时频不变模式,因为在波形图中核既沿时间轴卷积又沿频率轴卷积。
3.2 Wavegram-Logmel-CNN
此外,我们可以将波形图和对数MEL谱图合并为新的表示法。这样,我们就可以利用来自时间域波形和对数MEL谱图的信息。该组合沿通道尺寸进行。波形图为音频标记提供了额外信息,补充了对数MEL谱图。图1显示了Wavegram-Logmel-CNN的体系结构。
4、数据处理
在这一部分中,我们介绍了AudioSet标签的数据处理,包括数据均衡和数据增强。数据平衡是一种用于在高度不平衡的数据集上训练神经网络的技术。数据增强是一种用于增强数据集的技术,以防止系统在训练期间过度适应。
4.1 数据均衡
可用于训练的音频片段的数量因声音类别而异。例如,有90多万个音频片段属于“演讲”和“音乐”两个类别。另一方面,只有几十个音频片段属于“牙刷”这一类别。不同声音类别的音频片段数量具有长尾分布。
在训练期间,训练数据以小批方式输入到PAN。如果没有数据平衡策略,音频剪辑将从AudioSet统一采样。因此,在训练过程中,更有可能对具有更多训练片段的声音类进行采样,例如《讲话》。在极端情况下,小批量中的所有数据可能属于同一声音类别。这将导致PAN过度适应训练片段较多的声音类,而不适合训练片段较少的声音类。为了解决这一问题,我们设计了一种均衡采样策略来训练PANN。也就是说,从所有声音类别中大致相等地对音频片段进行采样,以构成小批量。我们使用术语“大约”是因为一个音频片段可能包含一个以上的标签。
4.2 数据增强
数据增强是防止系统过度匹配的一种有用方法。AudioSet中的一些声音类只包含少量(例如数百个)训练片段,这可能会限制PANN的性能。我们在训练期间应用Mixup和SpeAugment来增加数据。
- Mixup: Mixup是一种通过对来自数据集的两个音频剪辑的输入和目标进行内插来扩充数据集的方法。例如,我们将两个音频片段的输入分别表示为x1、x2,并将它们的目标分别表示为y1、y2。然后,可以分别通过 x = λ x 1 + ( 1 − λ ) x 2 x=λx_1+(1−λ)x_2 x=λx1+(1−λ)x2 和 y = λ y 1 + ( 1 − λ ) y 2 y=λy_1+(1−λ)y_2 y=λy1+(1−λ)y2来获得增广输入和目标,其中λ是从贝塔分布中采样的。默认情况下,我们在对数MEL谱图上应用混合。我们将在第VI-C4节中比较混合增强在对数-梅尔谱图和时间域波形上的性能。
- SpecAugment:SpecAugment使用频率遮罩和时间遮罩对音频片段的对数MEL谱图进行操作。应用频率遮罩,从而对f个连续的MEL频率箱 [ f 0 , f 0 + f ] [f_0,f_0+f] [f0,f0+f]进行遮罩,其中f从0到频率遮罩参数f 0的均匀分布中选择, f 0 f_0 f0从[0,F−f]中选择,其中F是MEL频率箱的数量。每个对数MEL谱图中可以有多个频率遮罩。该频率掩码可以提高PANN对音频片段的频率失真的稳健性。时间掩码类似于频率掩码,但应用于时间域。
5、迁移到其他任务
以前关于音频迁移学习的工作主要集中在音乐标记上,并且局限于比AudioSet更小的数据集。首先,我们在图2(A)中演示了PAN的训练。这里,DAudioSet是AudioSet数据集,X0、Y0分别是训练输入和目标。FCAudioSet是用于AudioSet标记的完全连接层。在本文中,我们提出对以下迁移学习策略进行比较。
- 从零开始训练一个系统。所有参数都是随机初始化的。系统类似于PANN,不同之处在于最终的完全连接层取决于任务相关的输出数量。该系统被用作基准系统,并与其他迁移学习系统进行比较。
- 使用PAN作为特征抽取器。对于新任务,使用Pann计算音频片段的嵌入特征。然后,将嵌入的特征用作分类器的输入,例如完全连接的神经网络。当训练新的任务时,PAN的参数是固定的,并且没有被训练。仅训练建立在嵌入特征上的分类器的参数。图2(B)显示了这一策略,其中DNewTask是一个新的任务数据集,而FCNewTask是一个新任务的完全连接层。PAN被用作特征抽取器。基于提取的嵌入特征构建分类器。带阴影的矩形表示冻结和未训练的参数。
- 微调一个Pann。PANN用于新任务,但最终的完全连接层除外。除了随机初始化的最终完全连接层之外,所有参数都从PAN初始化。所有参数都在DNewTask上进行了微调。图2©演示了PAN的微调。
6、实验
首先,我们评估了PANN在AudioSet标注上的性能。然后,将神经网络转移到多个音频模式识别任务中,包括声学场景分类、一般音频标注、音乐分类和语音情感分类。
6.1 AudioSet 数据集
AudioSet是一个具有527个声音类别的本体的大规模音频数据集[1]。AudioSet中的音频片段是从Y ouTube视频中提取的。训练集由2,063,839个音频片段组成,其中包括22,160个音频片段的“平衡子集”,其中每个声音类别至少有50个音频片段。评估集由20,371个音频片段组成。
我们没有使用[1]提供的嵌入功能,而是在2018年12月使用[1]提供的链接下载了AudioSet的原始音频波形,并忽略了无法再下载的音频片段。我们成功下载了1,934,187个完整训练集的音频片段(94%),包括20,550个平衡训练集的音频片段(93%)。我们成功地下载了评估数据集的18,887个音频片段。如果音频片段短于10秒,我们就用静默将其填充到10秒。考虑到来自Y ouTube的大量音频片段是单声道的,采样率很低,我们将所有音频片段转换为单声道,并将其重新采样到32 kHz。
对于基于对数-梅尔谱图的CNN系统,对具有1024[33]大小的汉明窗口和320个样本的跳跃大小的波形应用STFT。此配置导致每秒100帧。在[33]之后,我们应用64个Mel滤波器组来计算对数Mel谱图。MEL组的下限和上限截止频率设定为50 Hz和14 kHz,以消除低频噪波和锯齿效果。我们使用torchlibrosa1,librosa[46]函数的一个PyTorch实现,将LOG MEL谱图提取构建到PANN中。10秒音频片段的对数MEL谱图的形状为1001×64。额外的一帧是由于在计算短时傅里叶变换时应用“中心”参数造成的。使用批大小为32的ADAM[47]优化器和学习率为0.001的优化器进行训练。系统使用单卡Tesla-V100-PCIe-32 GB进行训练,每个系统需要大约3天的时间从头开始训练600k次。
6.2 评价标准
均平均精度(MAP)、曲线下平均面积(MAUC)和d素数被用作AudioSet标签的官方评估指标。AP是召回和查准率曲线下的区域,AP不依赖于真负例的数量,因为准确率和召回率都不取决于真负例的数量。另一方面,AUC是反映真阴性影响的假阳性率和真阳性率(召回)下的区域。D-素数[1]也被用作度量,并且可以直接从AUC[1]计算。所有指标都是按个别类别计算的,然后求所有类别的平均值。
6.3 AudioSet 打标结果
- 表四显示了我们提出的CNN14系统与以前的AudioSet标签系统的比较。

- 表IV的最下面几行显示了我们提出的CNN14系统获得了0.431的MAP,表现优于以往系统。

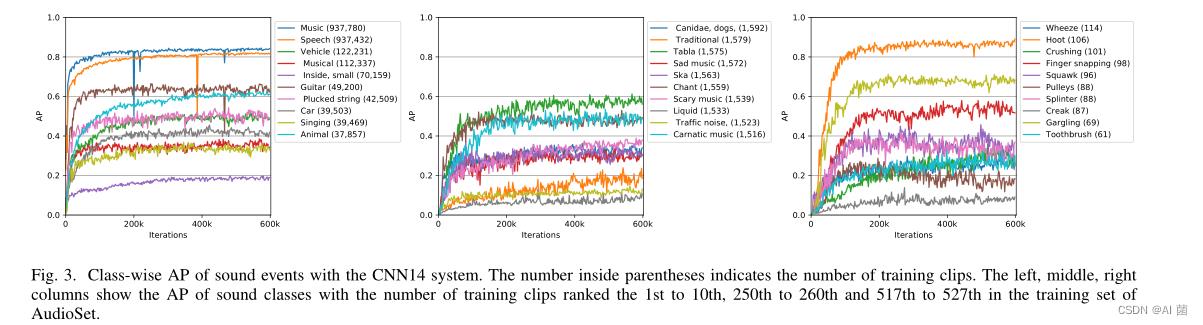
- 各个类上的表现
7、结论
我们提出了在AudioSet上训练的用于音频模式识别的预训练音频神经网络(PANN)。为了建立PANN,人们研究了多种神经网络。我们提出了一种从波形中学习的波形图特征,以及一种在音频集标记中实现最先进性能的波形图-对数-有线电视新闻网,存档了0.439的mAP。我们还研究了PANN的计算复杂性。我们证明了PANN可以被转移到广泛的音频模式识别任务中,并且性能优于以前的几个最先进的系统。当对新任务的少量数据进行微调时,PANN可能会很有用。在未来,我们将把PAN扩展到更多的音频模式识别任务。
以上是关于PANNs:用于音频模式识别的大规模预训练音频神经网络的主要内容,如果未能解决你的问题,请参考以下文章