100天精通Python(数据分析篇)——第70天:Pandas常用排序排名方法(sort_indexsort_valuesrank)
Posted 无 羡ღ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了100天精通Python(数据分析篇)——第70天:Pandas常用排序排名方法(sort_indexsort_valuesrank)相关的知识,希望对你有一定的参考价值。

文章目录
对数据集进行排序和排名的是常用最基础的数据分析手段,pandas提供了方便的排序和排名的方法,通过简单的语句和参数就可以实现常用的排序和排名
一、按索引排序:sort_index()
sort_index() 是 pandas 中按索引排序的函数,默认情况下, sort_index 是按行索引来排序。
语法格式:
sort_index(
self,
axis=0,
level=None,
ascending: bool | int | Sequence[bool | int] = True,
inplace: bool = False,
kind: str = "quicksort",
na_position: str = "last",
sort_remaining: bool = True,
ignore_index: bool = False,
key: IndexKeyFunc = None,
)
常用参数说明:
- axis:默认为axis=0表示按行排序,当axis=1表示按列排序。
- ascending:默认为True升序排序,为False降序排序
- inplace:是否修改原始数据
1. Series类型排序
Series对象排序中,axis参数只能为0
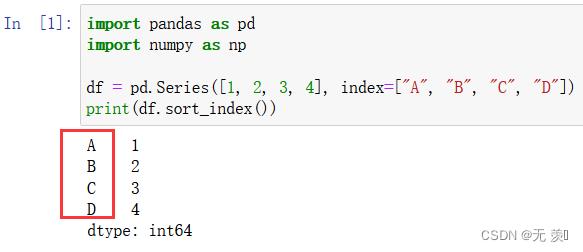
1)升序
默认 ascending=True 升序
import pandas as pd
import numpy as np
df = pd.Series([1, 2, 3, 4], index=["A", "B", "C", "D"])
print(df.sort_index())
运行结果:
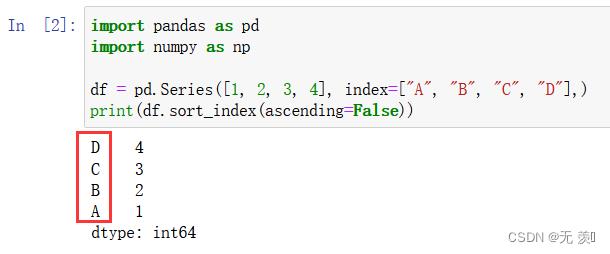
2)降序
设置 ascending=False 倒序
import pandas as pd
import numpy as np
df = pd.Series([1, 2, 3, 4], index=["A", "B", "C", "D"],)
print(df.sort_index(ascending=False))
运行结果:
2. DataFrame类型排序
1)按行索引排序
默认 axis=0 按行标签索引排序
-
- 默认 ascending=True 升序排序
import pandas as pd import numpy as np data = np.arange(16).reshape((4, 4)) df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_index(axis=0))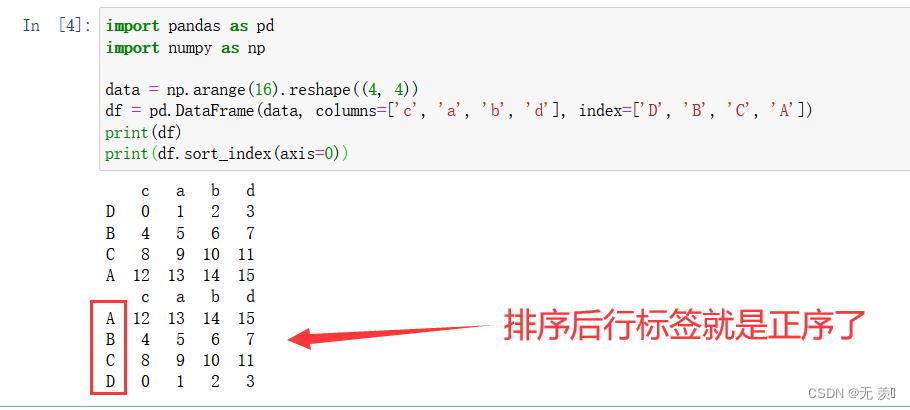
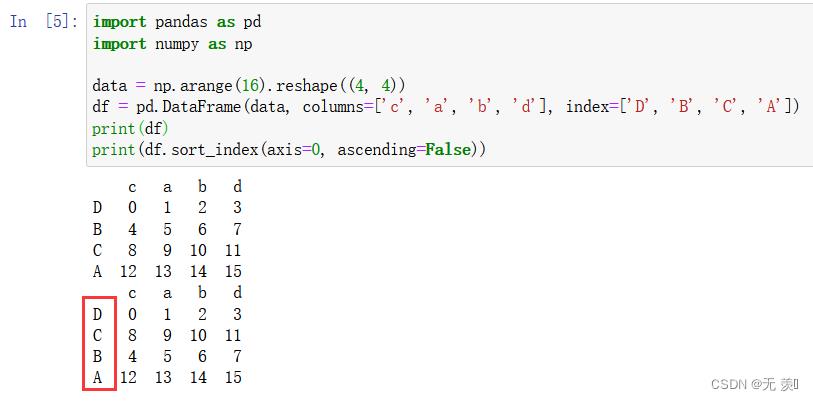
-
- 设置 ascending=False 倒序
import pandas as pd import numpy as np data = np.arange(16).reshape((4, 4)) df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_index(axis=0, ascending=False))运行结果:
2)按列索引排序
设置 axis=1 按列标签索引排序
-
- 默认 ascending=True 升序排序
import pandas as pd import numpy as np data = np.arange(16).reshape((4, 4)) df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_index(axis=1, ascending=True))运行结果:
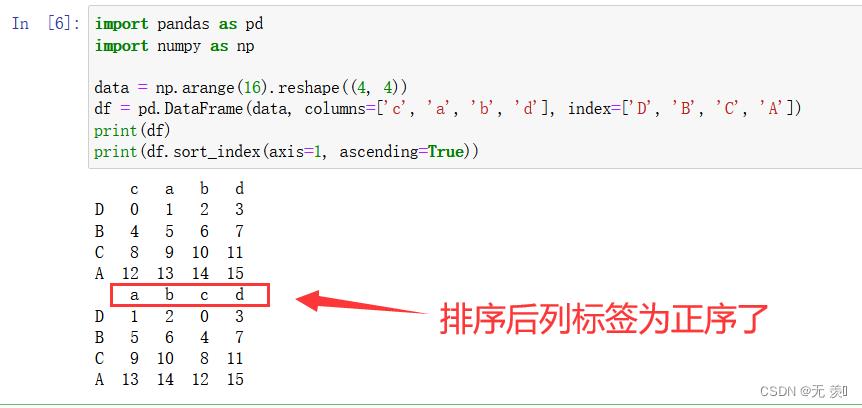
-
- 设置 ascending=False 倒序
import pandas as pd import numpy as np data = np.arange(16).reshape((4, 4)) df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_index(axis=1, ascending=False))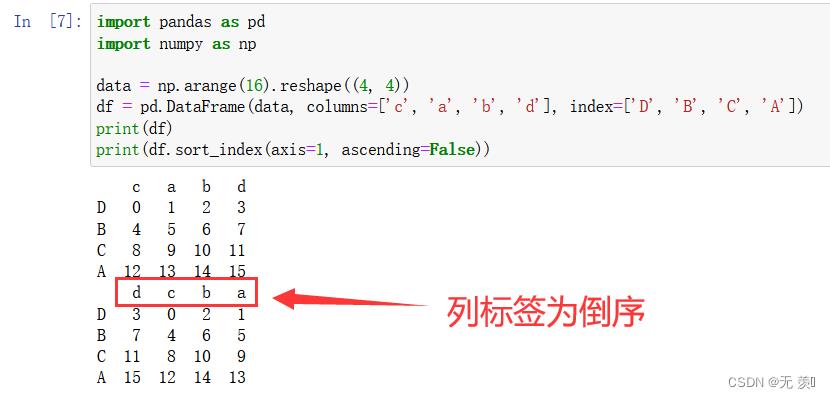
二、按值排序:sort_values()
在实际数据分析过程中用得最多是按某一列的值进行排序,在pandas中sort_values() 是按数值排序的方法
1. Series类型排序
语法格式:
sort_values(
self,
axis=0,
ascending: bool | int | Sequence[bool | int] = True,
inplace: bool = False,
kind: str = "quicksort",
na_position: str = "last",
ignore_index: bool = False,
key: ValueKeyFunc = None,
)
常用参数说明:
- axis:只能为0
- ascending:默认为True升序排序,为False降序排序
- inplace:是否修改原始Series
1)升序
默认 ascending=True 升序
import pandas as pd
import numpy as np
df = pd.Series([5, 3, 2, 4, 1], index=["A", "B", "C", "D", "E"])
print(df)
print(df.sort_values())
运行结果:
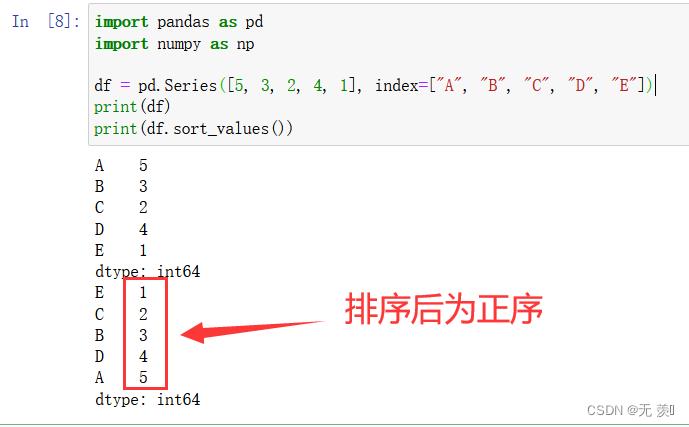
2)降序
设置 ascending=False 倒序
import pandas as pd
import numpy as np
df = pd.Series([5, 3, 2, 4, 1], index=["A", "B", "C", "D", "E"])
print(df)
print(df.sort_values(ascending=False))
运行结果:
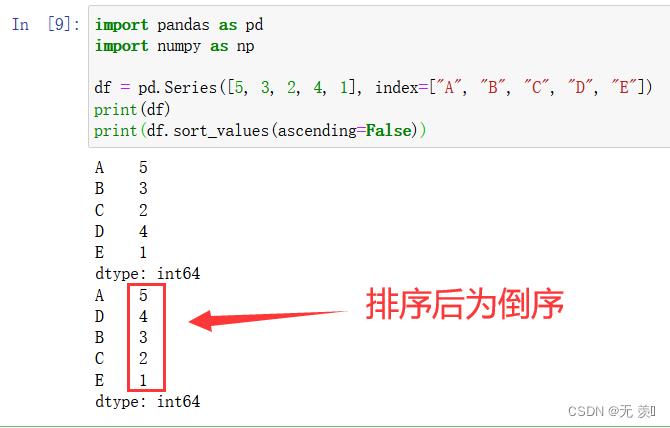
2. DataFrame类型排序
语法格式:
sort_values( # type: ignore[override]
self,
by,
axis: Axis = 0,
ascending=True,
inplace: bool = False,
kind: str = "quicksort",
na_position: str = "last",
ignore_index: bool = False,
key: ValueKeyFunc = None,
)
常用参数说明:
- by:字符串或者List<字符串>,单列排序或者多列排序
- ascending:默认为True升序排序,为False降序排序
- inplace:是否修改原始数据
- kind:选择排序算法,默认是 ‘quicksort’,该参数只针对单个列时才有效
- mergesort:归并排序
- heapsort:堆排序
- quicksort:快速排序
- na_position:缺失值处理
- last:缺失值排最后
- first:缺失值排开头
1)单列排序
-
- 默认 ascending=True 升序排序
import pandas as pd import numpy as np data = values = [[4, 7, 3, 1], [5, 3, 9, 8], [4, 1, 8, 5], [6, 2, 3, 5]] df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_values(by='a'))运行结果:

-
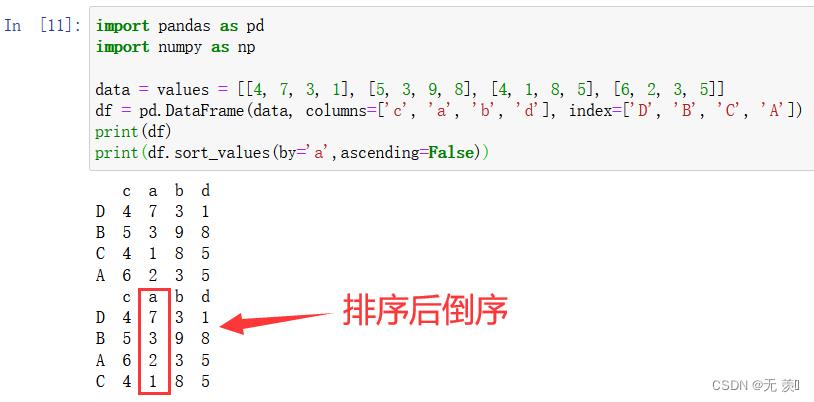
- 设置 ascending=False 倒序
import pandas as pd import numpy as np data = values = [[4, 7, 3, 1], [5, 3, 9, 8], [4, 1, 8, 5], [6, 2, 3, 5]] df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_values(by='a',ascending=False))运行结果:
2)多列排序
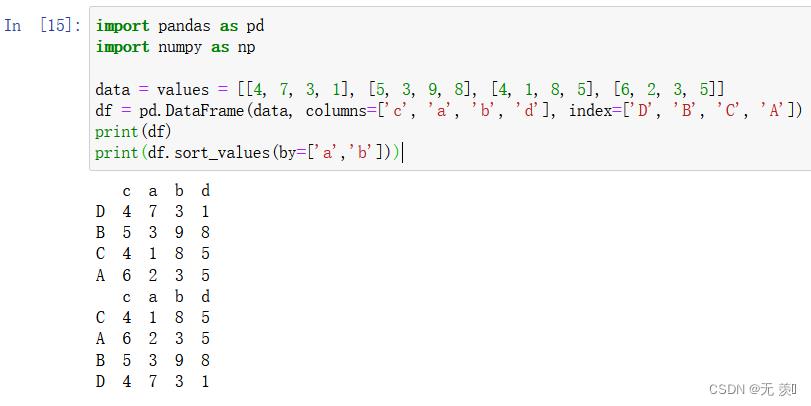
-
- 两列排序:默认 ascending=True 升序排序
import pandas as pd
import numpy as np
data = values = [[4, 7, 3, 1], [5, 3, 9, 8], [4, 1, 8, 5], [6, 2, 3, 5]]
df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A'])
print(df)
print(df.sort_values(by=['a','b']))
运行结果:
-
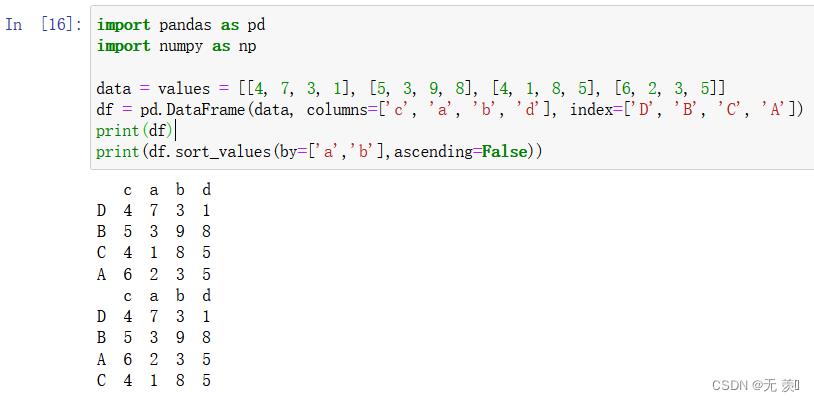
- 两列排序:默认 ascending=False 降序排序
import pandas as pd import numpy as np data = values = [[4, 7, 3, 1], [5, 3, 9, 8], [4, 1, 8, 5], [6, 2, 3, 5]] df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) print(df.sort_values(by=['a','b'],ascending=False))运行结果:
-
- 两列排序:分别指定排序方法
import pandas as pd import numpy as np data = values = [[4, 7, 3, 1], [5, 3, 9, 8], [4, 1, 8, 5], [6, 2, 3, 5]] df = pd.DataFrame(data, columns=['c', 'a', 'b', 'd'], index=['D', 'B', 'C', 'A']) print(df) # 分别指定升序和降序 print(df.sort_values(by=['a','b'], ascending=[True, False]))运行结果:

3)排序算法
几种排序主要是程序运行时占用的资源和运行速度有差异
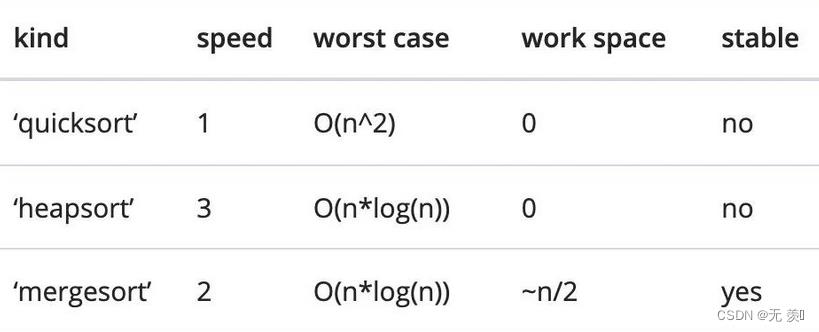
kind:选择排序算法,默认是 ‘quicksort’,该参数只针对单个列时才有效
- mergesort:归并排序
- heapsort:堆排序
- quicksort:快速排序
4)缺失值
na_position:缺失值处理
- last:缺失值排最后
- first:缺失值排开头
1、默认 na_position = last 缺失值排最后:
import pandas as pd
import numpy as np
data = 'A': [1, 5, 9, 6, 3],
'B': [5, 9, 2, np.nan, 3],
'C': [0, 8, 4, 3, 2],
df = pd.DataFrame(data)
print(df)
print(df.sort_values(by='B'))
运行结果:
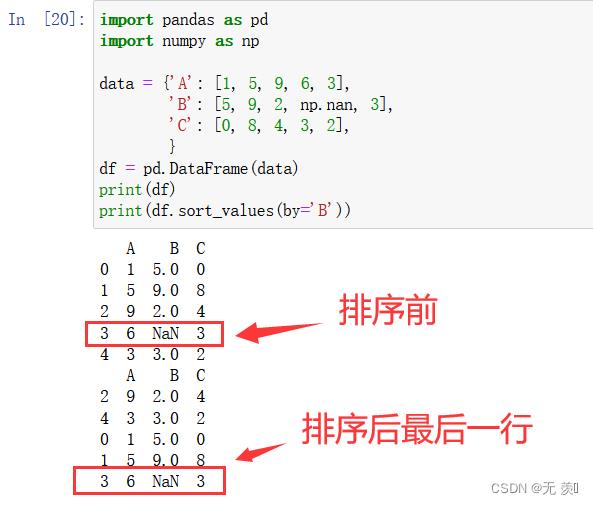
2、设置 na_position = first 缺失值排开头:
import pandas as pd
import numpy as np
data = 'A': [1, 5, 9, 6, 3],
'B': [5, 9, 2, np.nan, 3],
'C': [0, 8, 4, 3, 2],
df = pd.DataFrame(data)
print(df)
print(df.sort_values(by='B',na_position = 'first'))
运行结果:
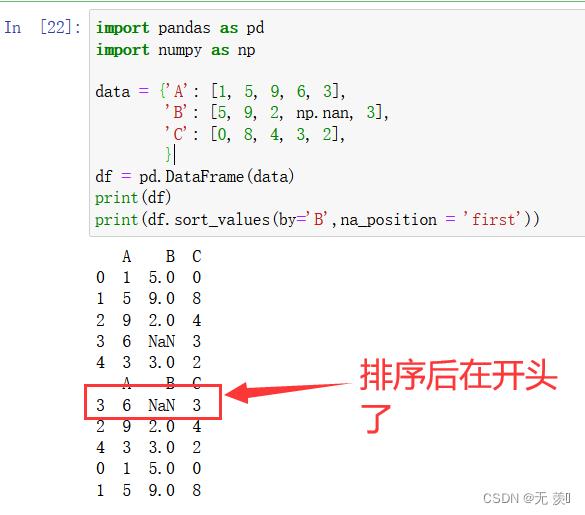
5)key参数
通过设置 key 参数,可以将列按照特定条件进行排序,对比下下面的排序
import pandas as pd
import numpy as np
data = 'A': ['BB', 'AA', 'DD', 'EE','CC'],
'B': [5, 9, 2, np.nan, 3],
'C': [0, 8, 4, 3, 2],
df = pd.DataFrame(data)
print(df.sort_values(by='B'))
# key参数:字符串所有大写字符转化为小写
print(df.sort_values(by='B', key=lambda col: col.str.lower()))
三、排名:rank()
沿轴计算数值数据等级(1到n)。默认情况下,相等的值被分配一个等级,该等级是这些值的等级的平均值。
语法格式:
rank(
self: FrameOrSeries,
axis=0,
method: str = "average",
numeric_only: bool_t | None = None,
na_option: str = "keep",
ascending: bool_t = True,
pct: bool_t = False,
) -> FrameOrSeries
最重要的参数就是method,指定排名时用于破坏平级关系的method选项(注:值相同的位同一个分组):
- average:默认值,在每个组中分配平均排名
- min:使用整个整个分组的最小排名
- max: 使用整个分组的最大排名
- first: 按值在原始数据中的出现顺序分配排名
- dense:类似于method=‘min’,但组件排名总是加1,而不是一个组中的相等元素的数量
1. method='average’排名
通过“为各组分配一个平均排名”的方式破坏平级关系的为各组分配一个平均排名
import pandas as pd
import numpy as np
df = pd.Series([3, 4, -2, 1, 4, 5])
print(df)
print(df.rank())
运行结果:
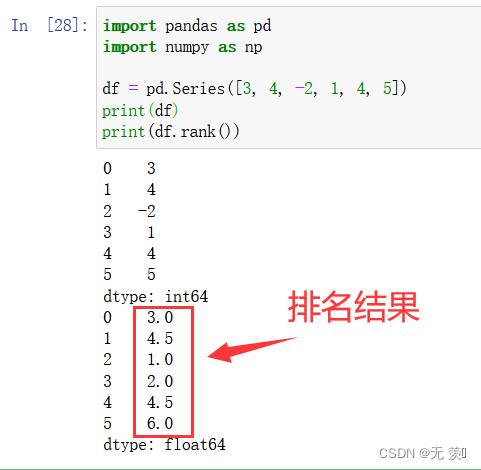
[3, 4, -2, 1, 4, 5],我们手动排一下,-2是第1名,1是第2名,3是第3,4是第4,4是第5,5是第6。其中两个4的排名分别是4和5,在默认的排法,他们平均数4.5,所以两个排名都是4.5。
2. method='min’排名
为各组分配一个最小排名
import pandas as pd
import numpy as np
df = pd.Series([3, 4, -2, 1, 4, 5])
print(df)
print(df.rank(method='min'))
运行结果:
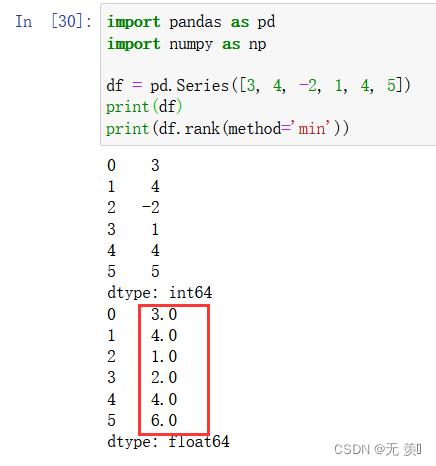
[3, 4, -2, 1, 4, 5],我们手动排一下,-2是第1名,1是第2名,3是第3,4是第4,4是第5,5是第6。其中两个4的排名分别是4和5,在min排法,他们最小值是4,所以两个排名都是4。
3. method='max’排名
为各组分配一个最大排名,与’min’相反
import pandas as pd
import numpy as np
df = pd.Series([3, 4, -2, 1