自然语言处理ELMo 讲解
Posted 不牌不改
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理ELMo 讲解相关的知识,希望对你有一定的参考价值。
有任何的书写错误、排版错误、概念错误等,希望大家包含指正。
作图属实不易!
ELMo 讲解
ELMo 的核心思想是,基于深度语言模型进行训练,学习不同语境下的词向量用于更好地配合下游任务。
ELMo 的主要创新点在于结合双向语言模型(Bidirectionbbal Language Model,BiLM)和深度模型以解决一词多义的问题。双向语言模型使得 ELMo 捕捉来自上文和下文的信息;借助深度学习的思想,ELMo 对双向语言模型深度化,通过多层 BiLM 的堆叠来获取不同层次的特征。这两点创新使得作为第二代预训练模型(pre-trained model)之一的 ELMo 不同于第一代预训练模型(如Word2Vec等),第一代预训练模型也被认为是静态模型,它们为一个单词分配一个词向量,这无法处理单词在不同语境下一词多义的情况,而动态模型 ELMo 可以根据每次输入句子的不同,输出不同的词向量,很好地解决了一词多义的问题。
本文不具体区分“词嵌入”和“词表示”等概念,对应英文中的“word embedding”和“word representation”,统一用“词向量”表达,不影响理解。
严谨来说,“word representation”的概念是大于“word embedding”的,“embedding”是“representation”的具体一种,“representation”可以有很多,比如“one-hot”。但是也有很多文献不对二者进行细致区分。
结构
ELMo 框架主要包括三层,字符编码层(Char Encoder Layer)、双向语言模型(BiLMs)和混合层(Scaler Mixer),以整个句子作为输入,词向量作为输出。如图 1 1 1 所示。

图 1 ELMo 整体框架
输入张量的维度为 B × W × C \\rm B\\times W\\times C B×W×C,其中 B \\rm B B 表示 batch 的大小; W \\rm W W 表示语句中的单词数目,不讨论不同长度语句的处理; C \\rm C C 表示每个单词的字符数目,不讨论不同长度单词的处理; D \\rm D D 表示输入到 BiLMs 中的词向量维度,亦 ELMo 最终输出词向量维度的一半。
整体上来看,输入语句会先经过字符编码层,ELMo 对更加细粒度的字符,而非单词,进行编码,即每个字符都对应一个向量,每个单词又由每个字符向量组成的矩阵表示。经过字符编码层后得到维度为 B × W × D \\rm B\\times W\\times D B×W×D 的张量, D \\rm D D 为人为指定的超参数。随后,张量输入 BiLMs 层。BiLMs 层作为 ELMo 的核心部分,由 L \\rm L L 层双向 LSTM构成。每层双向 LSTM 提取语句不同的特征,将这些特征向量以及输入向量进行堆叠(stack)得到每个单词在 BiLMs 层的输出,因此对于这个 batch 本层输出的张量维度为 ( L + 1 ) × B × W × 2 D ) \\rm (L+1)\\times B\\times W\\times 2D) (L+1)×B×W×2D)。混合层将得到的张量进行线性融合,得到最终的 ELMo 词向量,每个单词对应的 ELMo 词向量为 2 D \\rm 2D 2D 维。
字符编码层(Char Encoder Layer)
字符编码层的输入维度是 B × W × C \\rm B \\times W\\times C B×W×C,输出维度是 B × W × D \\rm B \\times W\\times D B×W×D,本层的作用是在字符级别的粒度上对单词进行编码,以便模型能捕捉单词的内部结构信息。比如“beauty”和“beautiful”,即使不了解这两个词的上下文,后续的 BiLMs 层也能够识别出二者在一定程度上的相关性。另外,尽管世界上的单词非常多,甚至无限,但是字符的数量有限且非常少,所以任何单词都可以通过字符向量的拼接唯一表示,因此只要保证模型在有限大小的词典上训练好,那么模型可以获取任意语句(无论是否包括未登录词)中任意单词(无论是否为未登录词)对应的词向量,解决了模型效果受限于单词量的问题。
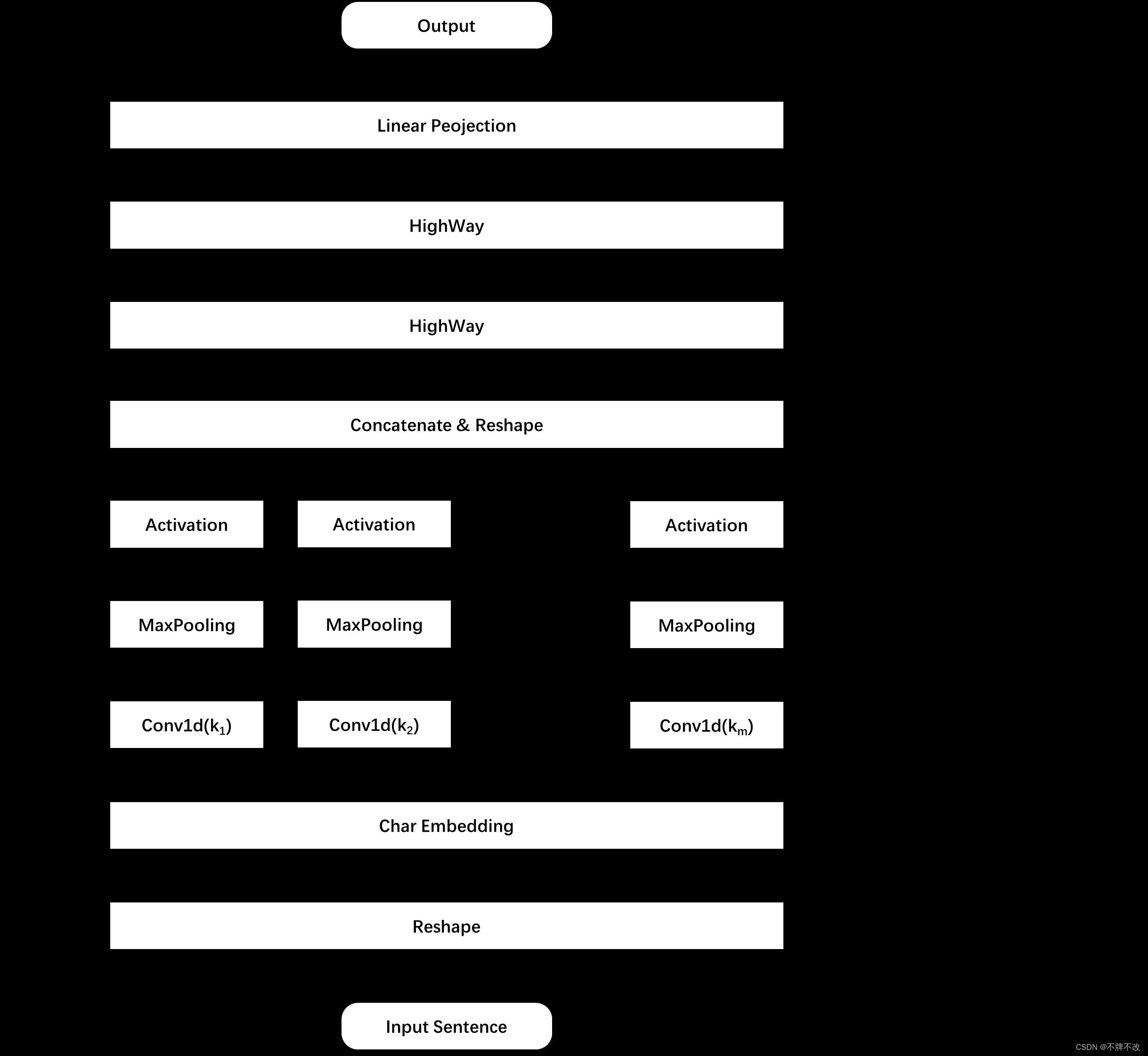
图 2 字符编码层框架
字符编码层整体框架如图 2 2 2 所示,具体分析每一子层的任务:
-
Reshape:将输入张量进行简单变形,主要是在实现时方便处理,对概念模型而言无意义。
-
Char Embedding:对每个字符编码,张量从两个维度伸展到三个维度。在具体实现中,字符表大小为 262,其中前 256 个是 unicode 编码包含的 255 个字符所对应的字符向量;最后 6 个是特殊标记,分别为
<bow>(begin of word)、<eow>(end of word)、<bos>(begin of sentence)、<eos>(end of sentence)、<pow>(placeholder of word)和<pos>(placeholder of sentence)。在代码中,字符向量的维度 d \\rm d d 取值为 16,单词长度 C \\rm C C 取值为 50。经过本子层,每个单词都由构成其的字符对应的向量表示,也可以理解为每个单词都由大小为 m × d \\rm m\\times d m×d 的矩阵表示。 -
Convolution Layers:本子层共 m 种卷积核,每种卷积核的大小为 ( k i , d ) \\rm (k_i, d) (ki,d),个数为 d i \\rm d_i di,对一个长度为 C \\rm C C 的单词进行卷积后得到的“新单词”的长度为 C i \\rm C_i Ci。在具体实现中,作者选用了 7 种卷积核,卷积核第二维大小与字符向量维度一致,第一维大小分别为 1 至 7,通道数也即每种卷积核的个数分别为 32、32、64、128、256、512、1024。对 m 种卷积后的“新单词”分别沿字符向量维度进行最大池化操作,激活得到的这 m 组 d i \\rm d_i di 维向量作为卷积子层的输出。为了更好地理解,不妨以仅考虑某一个单词的字符编码矩阵经过本子层的卷积过程为例,过程如图 3 3 3 所示。
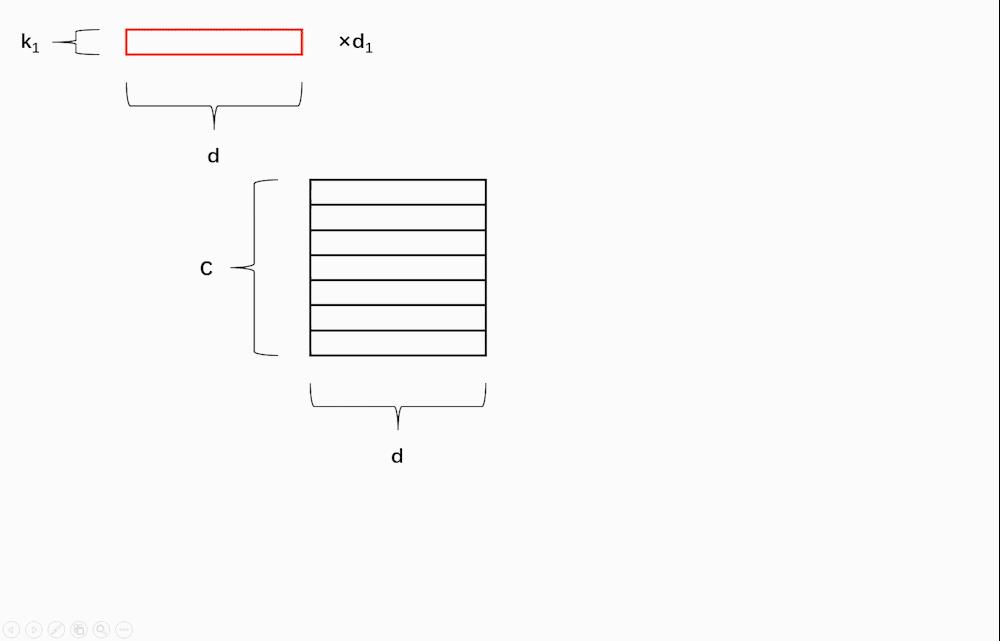
图 3 卷积过程
在官方代码实现中,对数据进行特殊处理后,使用一维卷积函数;而在非官方实现的代码中,常采用二维卷积函数,这也与我们直观感受一致,只不过没有在某个维度上滑动,所以二维卷积可以退化成一维卷积。
-
Concatenate and Reshape:将每个单词对应的 m 个向量拼接,同时对 batch 对应的张量进行变形,方便后续处理。在具体实现中,拼接后每个单词向量的长度为 d 1 + d 2 + ⋯ + d m = 2048 \\rm d_1+d_2+\\dots+d_m=2048 d1+d2+⋯+dm=2048。
-
HighWays:NLP 中的 HighWay 整体思想与 CV 中的 Residual 一致,都是进行跨层连接。一层 HighWay Network 通过门控机制实现,灵感来源于 LSTM 中的门控机制,通过“门”控制信息的流量。具体来说,假设输入为 x x x,那么 HighWay Network 的输出为
y = t ⊙ H ( W H , x ) + ( 1 − t ) ⊙ x y = t⊙H(W_H, x) + (1-t)⊙x y=t⊙H(WH,x)+(1−t)⊙x
其中, H H H 表示非线性变换, W H W_H WH 为对应参数; t t t 为
t = σ ( W t T x ) t=\\sigma (W^T_tx) t=σ(WtTx)
其中, W t W_t Wt 为对应参数。可见, t t t 起到了门控的作用, t t t 与 H H H 相乘得到变换后信息的流量, 1 − t 1-t 1−t 与 x x x 相乘得到原始信息的流量。根据两个公式可知,经过多层 HighWay Network 不改变输入张量的大小。
-
Linear Projection:前面计算得到的单词向量维度比较大,通过线性映射层将维度投影到人为规定的 D \\rm D D 维。在具体实现中, D = 512 \\rm D=512 D=512。
双向语言模型(BiLMs)
语言模型(LM)的一般任务是根据输入的若干个单词预测下一个单词,利用概率评估预测的好坏,以此进行模型训练。常见的语言模型有,N-gram/NNLM、RNN、LSTM、GRU 等。
双向语言模型(BiLM)是对语言模型的扩展,考虑到语句中某对单词对应的不同出现顺序可能不影响整个语句的语义,或者是语句中的单词适当地调换顺序不影响我们的理解,那么仅仅从一个方向捕获信息只能考虑到一个单词前面或者后面的信息。双向语言模型既从单词的上文提取信息又从下文提取信息,充分考虑了单词的上下文。双向语言模型并不是非常高深的模型,它只是简单地融合了正向(Forward)语言模型的输出和反向(Backward)语言模型的输出。注意,正向语言模型和反向语言模型的内部单元是共享模型参数的,但是两个语言模型之间的模型参数是独立的,是分别训练的。
具体的语言模型训练流程可以参考“LSTM 讲解”。
图 4 4 4 为双向语言模型层框架。训练 ELMo 核心在于训练多层双向语言模型部分。考虑某个单词向量,输入到第一层 biLSTM 中,分别经过正向 LSTM 对应单元和反向 LSTM 对应单元得到两个向量,对两个向量进行线性映射改变维度后投入到第二层 BiLSTM 中重复训练。在训练双向语言模型时,允许采用大型语料库进行无监督训练,具体的损失函数可以根据下游任务来确定。这意味着,不一定要将全部的最后一层 BiLSTM 经过映射后的结果输入到 softmax 中进行多分类并据此定义损失函数;类似于标准 LSTM,完全可以选取最后一个 LSTM 单元的输出作为定义损失函数的依据,图中只是展示了定义损失函数的其中一种方式,即利用全部单元多分类的结果。这与其他的一些语言模型(比如 RNN、LSTM 等)的训练思路一致,不展开讲解。
其中,FFNN 为前馈神经网络,可以直接理解为全连接层。BiLMs 部分输出单词的维度可能与词典大小不一致,所以需要映射处理才能进行 softmax,进而定义损失函数。
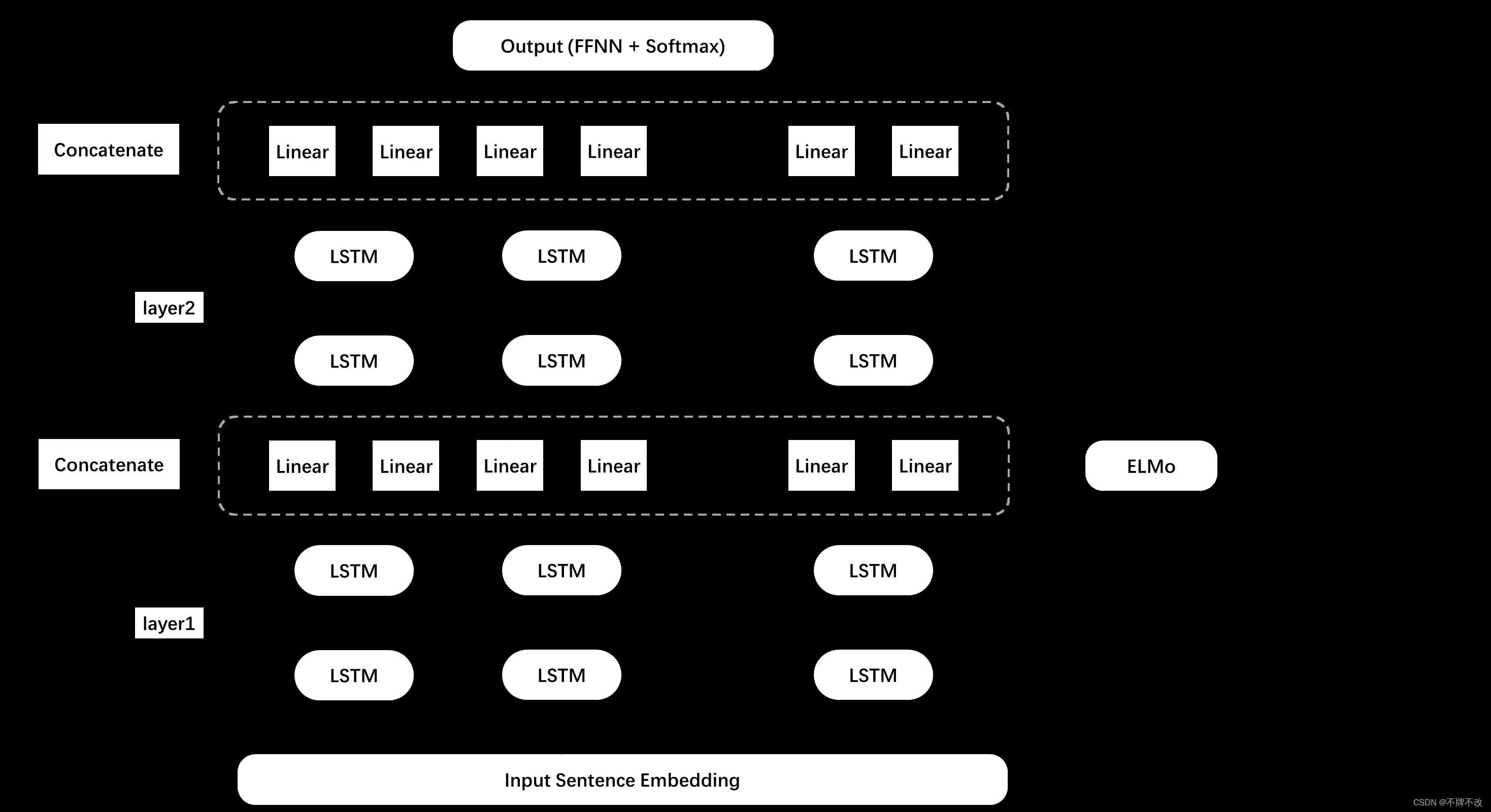
图 4 双向语言模型层(含混合层)框架
双向语言模型层的 BiLM 部分可以选取多层,但是图 4 4 4 以选取两层(即 L = 2 \\rm L=2 L=2)为例。每一层 BiLSTM 的输出要先经过一层线性映射才能投入到下一层中,这是因为 LSTM 单元的输入和其输出(隐藏层)的向量维度往往不一致,所以需要通过线性映射进行调整。在具体实现中,作者认为第一层双向语言模型可以捕捉语句的句法特征(比如应用在词性标注),第二层可以捕捉语句的语义特征(比如应用在语义消歧),因此采用两层 BiLSTM。每层的输入向量为 512 维(即 D \\rm D D 维),输出向量(隐藏层)为 4096 维(即 h \\rm h h 维),所以需要依靠线性映射将当前层 LSTM 单元的输出向量维度变换到下一层 LSTM 单元输入向量的维度。
另外,作者在论文中提到了 skip connection。具体地,将 Embedding 子层的输出向量与线性映射后的第一层 BiLSTM 输出向量相加作为第一层的实际输出并传入第二层。这在官方代码中也有体现。
混合层(Scaler Mixer)
我们利用训练好的模型生成 ELMo 词向量。ELMo 词向量由三部分加权构成,字符编码层的输出向量(即双向语言模型层的输入向量)、经过映射的第一层 BiLSTM 的输出向量(下面仅讨论经过映射变换后的第一层输出向量)和经过映射的第一层 BiLSTM 的输出向量(下面仅讨论经过映射变换后的第二层输出向量)。
图 4 4 4 中右侧部分对应模型生成词向量的过程。我们要确定某个单词在语句中与语义有关的词向量,只需要让语句先经过字符编码层,将 Embedding 投入到训练好的双向语言模型中,上述三部分向量加权得到最终该单词在语句中的词向量。具体地,考虑一个单词的 ELMo 词向量的生成。对应于图 4 4 4,该单词对应的 Embedding 的输入维度为 D \\rm D D,先对其进行复制拼接,维度变为 2 × D \\rm 2\\times D 2×D;单词对应的第一层单元和第二层单元的输出向量均为 2 × D \\rm 2\\times D 2×D 维,因为正向和反向对应的输出维度均为 D \\rm D D 维,所以二者拼接后为 2 × D \\rm 2\\times D 2×D 维向量。可见,如果总共 L \\rm L L 层双向语言模型,那么 ELMo 词向量对应于 L + 1 \\rm L+1 L+1 个向量加权。另外,论文提到,每个 ELMo 词向量对应 2 × L + 1 \\rm 2\\times L+1 2×L+1 种表征,即 L \\rm L L 种 D \\rm D D 维正向表征向量、 L \\rm L L 种 D \\rm D D 维反向表征向量以及 1 1 1 种 Embedding 表征向量。
假设对于第
k
k
k 个单词,第
j
j
j 层双向语言模型的输出记为
h
k
,
j
h_k,j
hk,j(
j
=
1
,
2
,
…
,
L
j=1,2,\\dots, L
j=1,2,…,L);特别地,Embedding 向量记为
h
k
,
0
h_k,0
hk,0。论文中用如下公式对它们进行 scaler mixer 操作以实现缩放加权:
E
L
M
o
k
t
a
s
k
=
γ
t
a
s
k
∑
j
=
0
L
s
j
t
a
s
k
h
k
,
j
\\rm ELMo_k^\\rm task=\\gamma^\\rm task\\sum_j=0^L s_j^\\rm task h_k,j
ELMoktask=γtaskj=0∑Lsjtaskhk,j
其中,
s
j
s_j
sj 是 softmax 对应的概率值,
γ
\\gamma
γ 是对整个 ELMo 词向量的缩放比例。这两部分都是可学习参数,对于不同的下游任务
t
a
s
k
\\rm task
task 会学习到不同的值,也对应不同的 ELMo 词向量。
另外,论文提到,每一层输出的分布之间可能会有较大差别,
以上是关于自然语言处理ELMo 讲解的主要内容,如果未能解决你的问题,请参考以下文章