金融业务如何高性能传输数据
Posted JavaEdge.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了金融业务如何高性能传输数据相关的知识,希望对你有一定的参考价值。
对系统要求高,通常按金融级标准设计。金融数据传输要求速度快,流量大,极强容灾。
案例分析
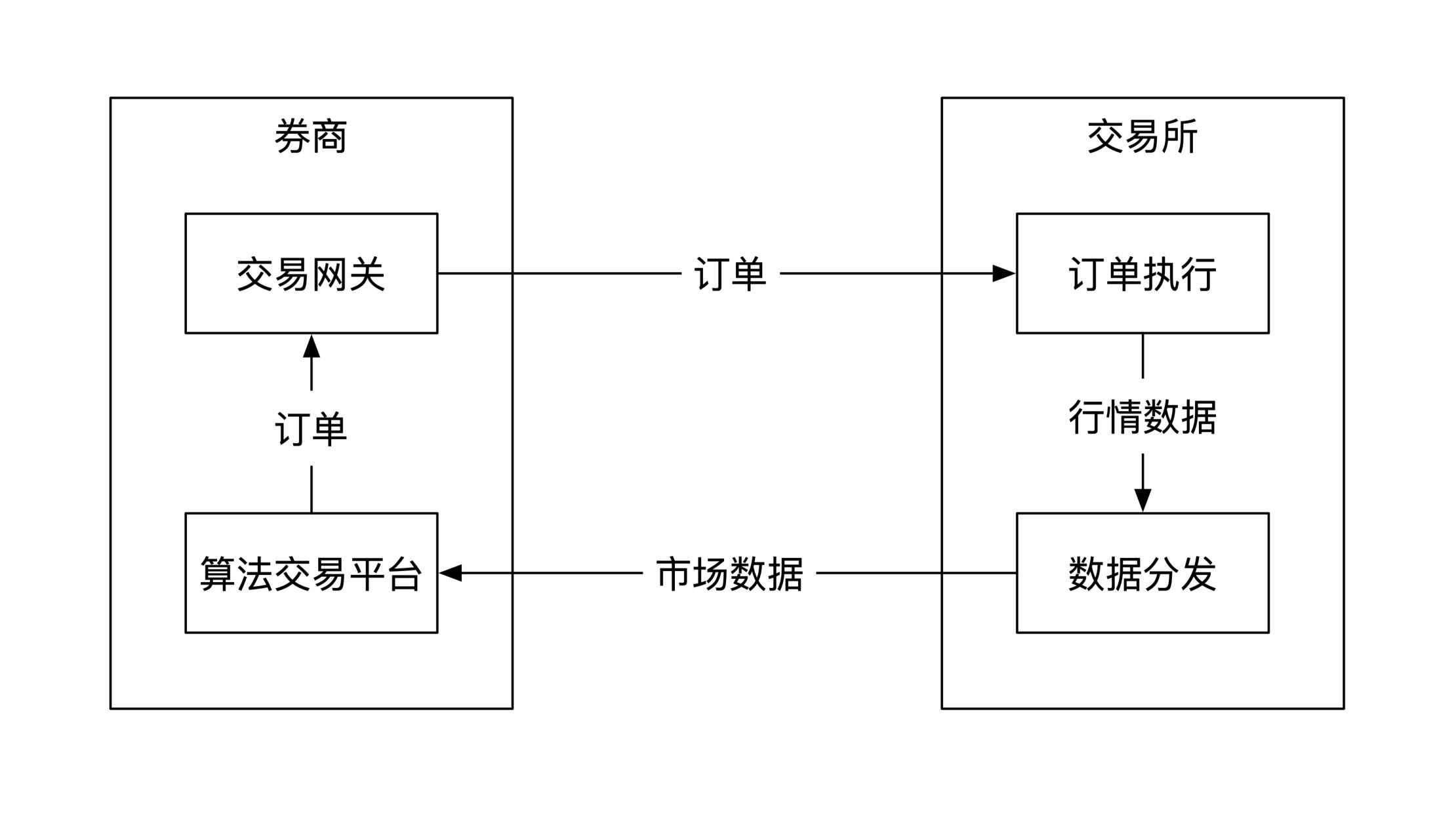
简化版券商算法交易平台对接交易所:
- 涉及场景多。既有事务数据,也有市场数据
- 模型简单。只涉及到2个主体
- 复杂度可选。连接交易所的要求可以很高,也可以很低,具体取决于你愿意出多少钱,有多久研发时间
两个主体:
- 券商,任务是将券商提供的市场交易信息发到自己的算法交易平台,平台分析这些信息后,发买卖订单给交易所
- 交易所负责处理收到的订单,在处理完后,将交易信息传递给券商
整个过程都是用软件实现,不用硬件。
交易数据
券商发给交易所的订单数据属于事务数据。这里的事务指的是数据库事务(Transaction)。所以交易数据的传输需满足顺序正确性要求,既要保证顺序的正确性,也要保证消息处理的一次性。
既然我们这节课讲的是数据传输质量问题,那么我们还是要分析一下可能的异常情况。数据传输已经具有事务性了,还能出啥问题?
网页刷新太快,可能会收到远端服务器拒绝访问的消息。这意味着电商服务器觉得你的访问频率过高,临时降低提供给你的服务质量。
金融行业里的服务器容量也有上限,也普遍采取了限流。
限流
常用限流方法:
漏桶算法
消息的生产者将所有请求放到一个容量固定的桶。消费者匀速从桶里消费消息。因为桶的消息满了就丢掉,所以这个桶叫作漏桶。
令牌桶算法
和漏桶算法一样,也有容量固定的桶,桶装的令牌。系统按固定速度往令牌桶里放令牌,满了之后就会溢出。消费者每处理一个消息都消耗一个令牌,所以桶里面的令牌总数决定了处理消息的最快速度,而放令牌速度决定处理消息的平均速度。
券商如何选择。**当两个不同组织之间的金融系统进行对接的时候,接收方一般要假设发送方是恶意的。**因此交易所要限制券商的消息发送速度,如1s内最多只能发多少消息。这时券商可漏桶算法限制自己对外的消息发送速度。
尽管交易所明文规定每家券商的速度上限,但交易所不相信券商会遵守规则,因此交易所依然对券商消息限流。这些经过限流的券商流量最终汇集,再集中处理。
虽然对每家的流量都做了限制,但他们的总流量还可能超出系统承载上限。所以交易所还需要对总流量限流。
这时你就有个选择,如你想对总流量微调,可选择令牌桶算法,就可通过调整生成令牌的速度调整处理速度。令牌桶里的总令牌数目代表了系统的峰值处理流量,这样系统还具有一定峰值处理能力。
**一旦上下游间做限流,整个系统就需要假设数据会丢。**因此你需要处理好订单发送不出去,或发送出去后无法被执行。
市场数据
交易数据的处理一般具有事务性,所以选择灵活度比较小。市场数据就不一样了,选择面要宽泛很多。
市场,指金融交易市场,**所以市场数据指的是金融市场成交信息。**股价就是股票买卖双方的成交价格。
交易数据是事务型数据,那市场数据也是事务型数据吗?这个问题是市场数据处理的最核心问题。
如你关心订单成交信息,那这成交信息是事务类数据。但例子里,券商的算法交易平台关心的不是自己的交易信息,而是当前所有人的交易信息,所以算法交易平台并不需要数据有事务保证,即案例里允许掉数据。
正因放松假设,对市场数据的处理才有多种选择。不同能力的算法交易平台对数据的实效性要求不一。
非实时市场数据
非实时,主要指那些对延时要求不特别高。这时消息的传输本着尽量快原则,稍微慢几百毫秒或几秒钟问题不大。绝大多数情况下,你碰到的都是这种非实时的市场数据场景。
非实时市场数据的分类。
订阅发布与消息
数据传输方式分为
-
订阅发布(Pub/Sub)
每个消息的消费者互相独立,每个人都要处理所有消息,并且每个人处理消息的顺序必须一样。
-
消息(Messaging)
所有人之间共享所有消息。即每个人处理的只是一部分消息,从他的角度来看消息是断断续续、不连续
RabbitMQ、RocketMQ最开始都按消息方式设计。而Apache Kafka和Google Cloud Pub/Sub按订阅发布方式设计。
这些都只是这些数据系统最开始的设计目标。系统架构在演进过程中可能会同时具有订阅发布和消息的一些能力,如Apache Kafka。
券商需要哪种数据传输方式。如果算法平台只有部分数据,可能缺失一些重要历史信号,所以算法交易平台需要所有历史数据。所以券商需要订阅发布数据传输方式,从交易所接收数据。这也是为什么现在Apache Kafka在金融系统中使用得越来越多。
优化及原理
要利用金融数据的一个属性——数据的时效性。数据的时效性指的是不同时间的数据对你的价值。
对金融市场数据,你永远得不到当前的数据。不管延时多低,你收到市场数据的时候已是历史数据,所以我们在这里谈论的都是历史数据的时效性。
如果所有历史数据对你的价值都是一样高,那么一般来说数据需要尽量完整。相反,如果越接近现在的数据对你的价值越高,那么数据则有可能允许丢失。因为就算丢失了,你只要稍微等一段时间,丢失的数据重要性就会变得很低,这样丢失对你的影响就会很小。
算法交易平台属于高频交易类型,它需要根据最近的趋势预测未来的盈利机会。如果数据的时间太久,可能市场上的其他参与者早就利用这些信息赚过了钱,这种时间太久的数据就没剩多少价值了。所以算法交易平台的数据属于具有时效性的数据,允许部分缺失。
金融系统不是所有地方的数据要求都很高,这就是例子。所以你一定要结合业务特点来选择合适系统架构。知道这特点,就可针对性地调整数据传输系统的容灾能力。
比如说Apache Kafka默认带有一定容灾功能。一般要求部署3个节点,其中一个是主节点,另外两个是备份节点。
每当Kafka收到数据后,会将数据先同步给备份节点,可以将同步数设为0,牺牲掉部分不重要的容灾能力,换来更快的处理速度。
就算数据可以丢失,也要避免这种情况频繁出现。所以,你要建立合理的监控机制,当数据频繁丢失的时及时反应。
实时市场数据
金融行业的非实时市场数据的处理和互联网行业接近,系统架构也类似,所以你会有似曾相识感觉。
实时市场数据的处理,这和互联网的处理区别比较大。
特殊部署
实时市场数据,对延时要求非常高的数据场景。低延时的系统维护对交易所本身是一笔很大的开销,而且因为能支持的用户数有限,所以一般都需要收费,也就是常说的席位费。
交完席位费后,一般就能连到交易所,获取一些低延时数据,同时还有可能得到更详细数据内容。
一般来说你的服务器和交易所有一定的物理距离,跨省传播数据的话,延时可能在几毫秒到几十毫秒。如你觉得这几十毫秒很重要,你可再用更多钱来解决这个问题。交易所一般会提供同机房主机服务,你可以将自己的系统部署在交易所的机房内。这样你的系统和交易所系统的物理距离只有几米左右,光速带来的影响基本忽略不计。
不过,因为交易所机房的物理机器有限,你需要和其他有钱的金融公司竞争这为数不多的位置,可能需要付出天价运营费用。
数据分发
实时市场数据的消费者之间并不是平等关系。谁的钱多,谁的延时就低。这表示实时数据分发的系统架构是一个层级结构,越接近上层的人收到的消息越快。
先从交易所出发。当交易所生成完数据之后,会将数据传送给顶层的数据节点。这一层会部署多个节点以防单点故障。
假如Kafka,交易所数据应该发给一个主节点,主节点负责和备份节点之间通讯。但是这样会有一个网络延时,所以交易所采用的是局域网内广播,所有第一层节点都会同时收到所有数据信息:
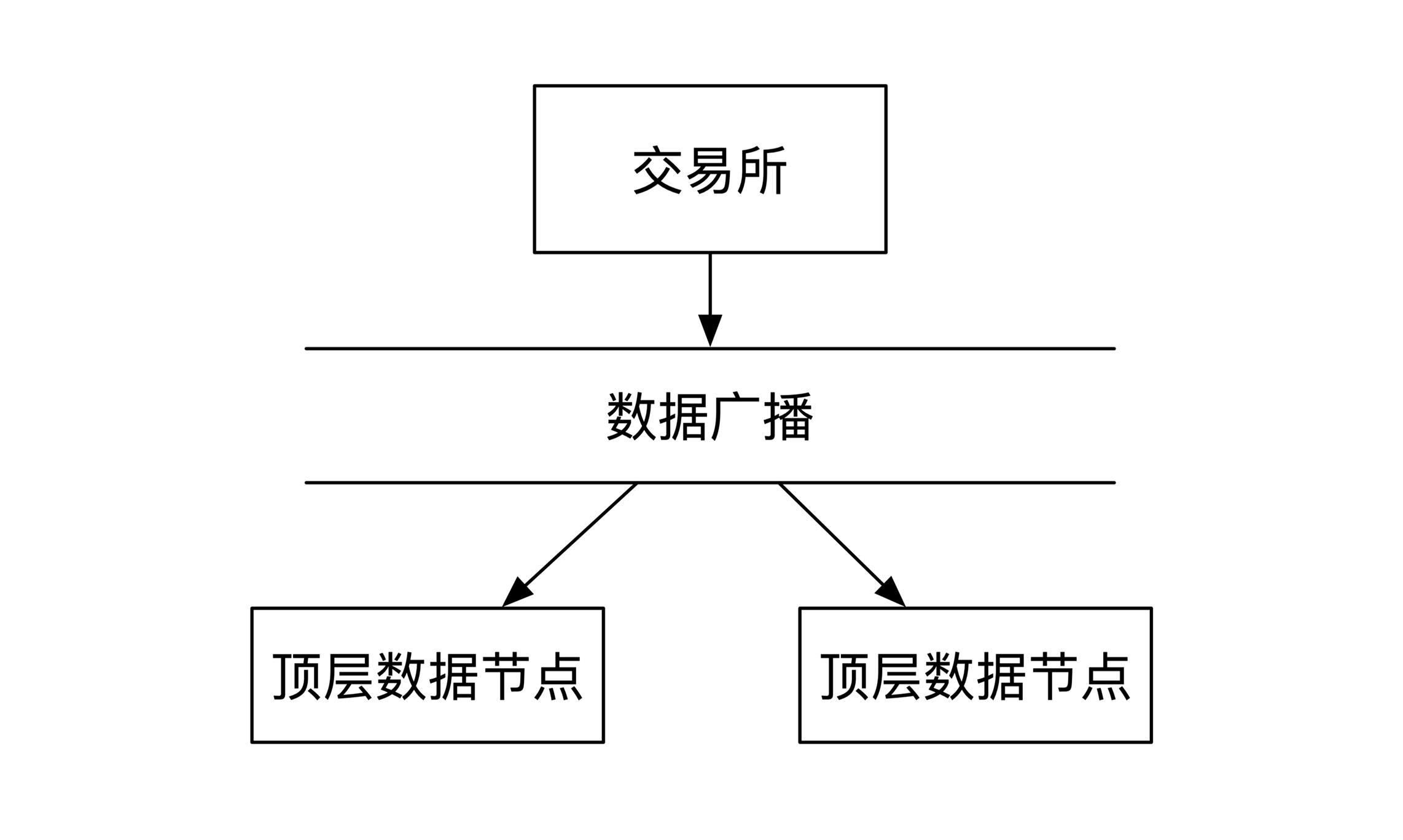
顶层数据节点收到数据之后会做两件事情,分别是推送给优先级最高的VIP客户,以及推送给下一层的数据分发节点。
低延时架构优化的是系统延时,而非系统的吞吐量。互联网常见的**消息系统普遍采用消费者定时拉数据模式。**优点是能支持大量的数据消费者,但两次拉取之间有一定时间间隔。如Apache Kafka的默认客户端。
数据的实时推送会消耗很多推送端的硬件资源,但交易所的VIP客户数目少,实时推送对系统影响可控,所以数据可通过顶层数据节点直推给用户。
经济学角度。VIP席位费的总盈利是总VIP客户数乘以席位费,VIP客户数减少之后,VIP之间的价格竞争会更激烈,所以席位费会增加。因为总盈利是这两者的乘积,很有可能总盈利会因为席位费的增加而大幅增加。
利润角度,系统也不一定需要支持很多VIP用户。选择系统架构,要结合业务。VIP席位需具备一定价格弹性(Price Elasticity)。
数据除了顶层的VIP用户之外,还有非VIP的付费实时数据用户。但由于数据已有延时,这时不一定要用到数据广播,可选择让顶层节点推送数据给下层节点。这时架构示意图:
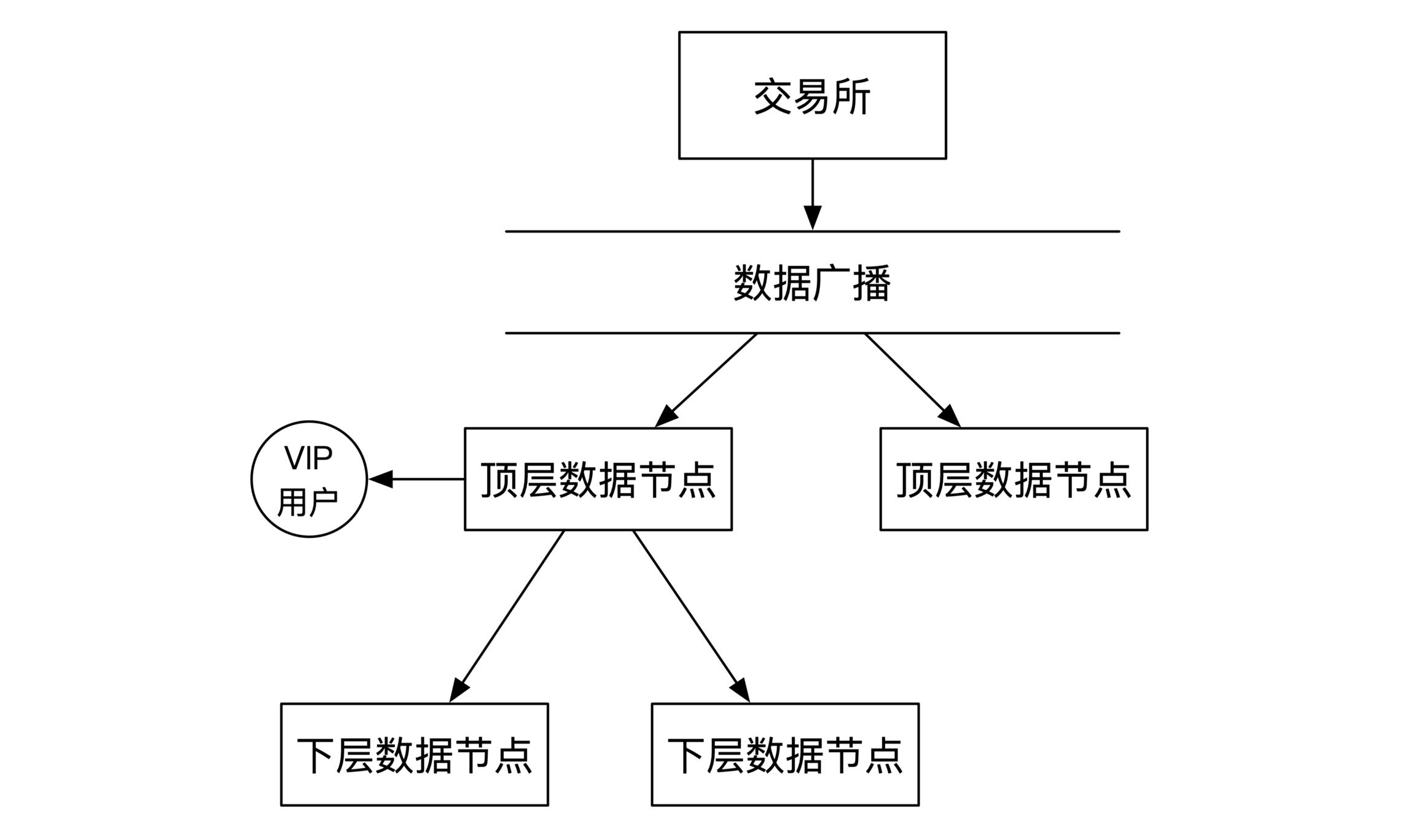
以此类推,每层往下继续分发数据。这时候数据分发的对象有交易所的非VIP付费客户,也有其他数据节点。
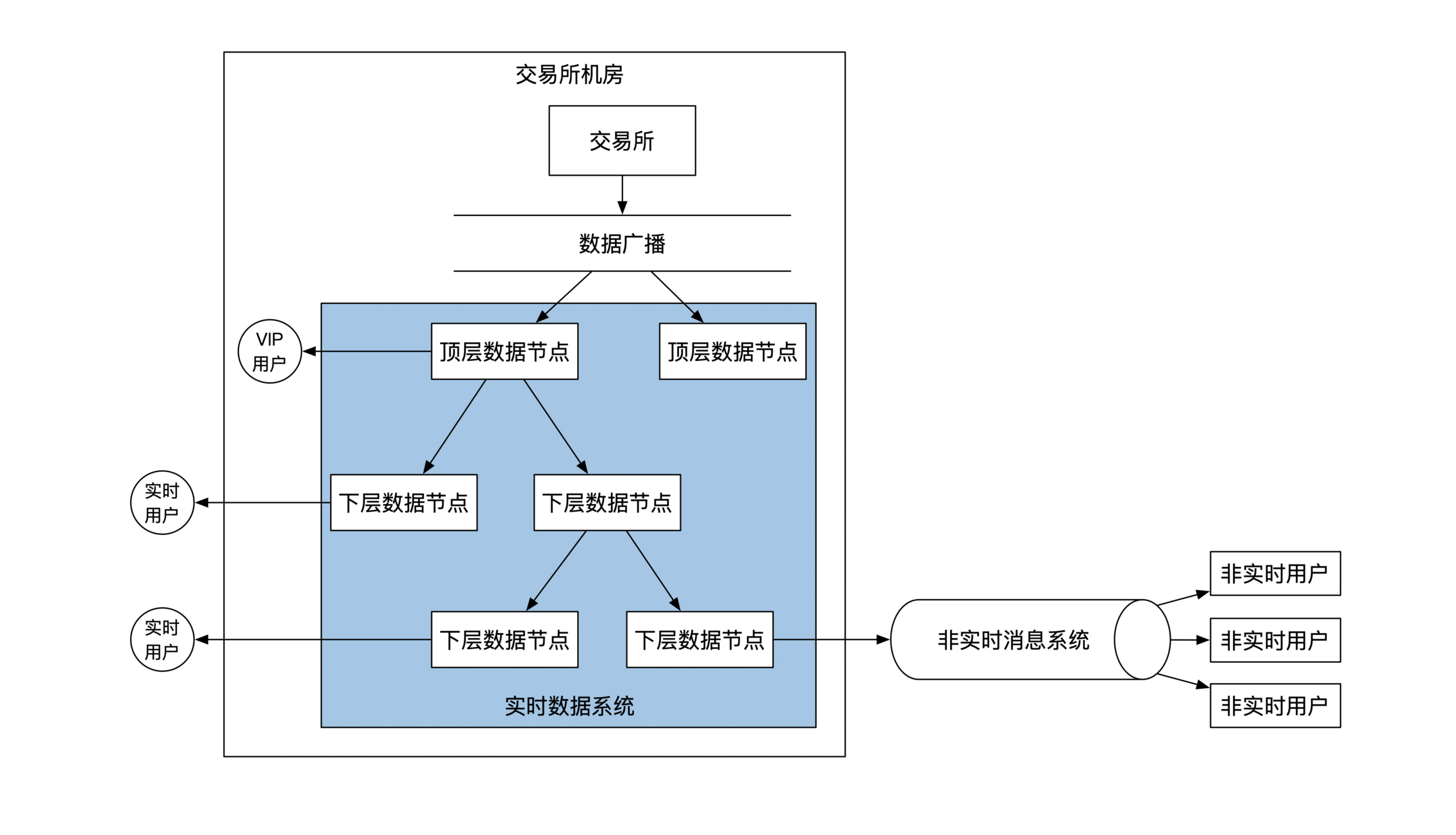
当交易所解决完所有付费用户的实时数据推送问题后,怎么把实时数据变为非实时数据,即怎么让非付费用户也能访问数据。只要将某层的实时数据节点对接到非实时数据系统。这时**数据由实时推送方式变为非实时拉取方式。**更新后的系统架构:
数据压缩
实时数据系统大部分的时间都花费在数据的解、编码。想速度快,首要数据量小,这也是金融系统架构和互联网架构很大区别。
Json或XML格式的数据一定不能用在实时数据系统。因为这些传输格式是为人准备,里面有多余信息,需换成只有机器看得懂的二进制表达方式。如要求不高,一般Google Prototol Buffer协议够,会按照你定义好的二进制表现形式来进行编码,能对数据进行很大幅度压缩。
在要求更高金融场景下,普遍会使用金融行业专用的FIX通讯协议。定义了通讯规则,同时也定义数据传输方式。
市场数据的显著特点:连续两个数据之间大部分内容都一样。如你去比较连续两个股票价格信息数据,它们很可能只有价格指标会变化,其他信息完全一样。
FIX协议就利用了这特性,很多情况下只需传输数据变动部分,就能减少很多数据传输量。设计思想和视频压缩算法类似,视频压缩以关键帧为基准,其他帧只存储相对关键帧的变化。
总结
金融数据分为交易数据和市场数据两种。金融交易数据的处理和互联网处理方法非常类似,在处理的时候需要做好数据限流的架构选型。
市场数据的处理分为非实时和实时两种。非实时市场数据的处理也和互联网处理方法类似,在处理的时候,对订阅发布和消息这两种不同架构选择,我们要做好区分。因为市场数据具有实效性,我们可以容忍偶然的数据丢失,这也给了数据系统一个很大的优化空间。
实时市场数据的消费者分为不同的级别。实时数据系统的架构和用户一样,也是分为不同级别。数据会层层分发下去,不同层级有不同的延时情况和部署方案。实时系统的优化主要体现在数据压缩上,金融行业有自己特有的FIX二进制通讯协议。
以上是关于金融业务如何高性能传输数据的主要内容,如果未能解决你的问题,请参考以下文章