说话人识别的数据需求
Posted DEDSEC_Roger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了说话人识别的数据需求相关的知识,希望对你有一定的参考价值。
概述
- 机器学习领域名言“Garbage In, Garbage Out!”不论神经网络多么先进,如果输入是垃圾,那么输出也一定是垃圾
- 在说话人识别领域,所需的最小数据单元,包括:
- 一段只包含单一说话人语音的音频,被称为Utterance(话语)
- 该段音频的说话人标签,能够唯一地在整个数据集中标识该说话人
- 怎么样的数据不是Garbage呢?或者说,如何评价一个数据集的质量呢?有以下这些指标:
- 说话人的数量
- 每个说话人的话语个数
- 文本的多样性
- 口音和语调的多样性
- 录音设备和声学环境的多样性
- 数据的正确性
说话人的数量、每个说话人的话语个数
- 几乎可以肯定:运行时要识别的说话人,不会出现在数据集中。因此说话人的数量,对系统的泛化性能非常重要
- 用于学术研究的数据集通常包含数千个说话人,例如:VoxCeleb,而实际落地的系统至少需要数万个说话人
- 在训练和测试时,需要正样本和负样本
- 说话人的数量决定了负样本的数量,说话人的数量越多越好
- 每个说话人的话语个数决定了正样本的数量,通常每个人有10~100个话语即可
文本多样性
- 文本多样性指:
- 发音多样性
- 词汇多样性
- 话题多样性
- 对于文本相关的说话人识别,文本多样性是不重要的
- 而对于文本无关的说话人识别,如果运行时的文本,是数据集中未出现过的,那么系统性能会很差。比如:古诗文本的数据集,不能用于经济新闻的说话人识别
口音和语调的多样性
- 使用普通话数据集训练的系统,在遇到粤语、闽南语、四川话等语言时,识别效果会差
- 使用新闻播音数据集训练的系统,在遇到电竞、体育直播这种语速快、情绪波动大,行业黑话多的场景时,识别效果会差
录音设备和声学环境的多样性
- 不同的录音设备录制的音频,频谱分布和音频质量会有比较大的差别,数据集应尽可能覆盖不同的录音设备,包括:
- 手机麦克风
- 电脑麦克风
- 录音棚麦克风
- 不同的声学环境,会形成不同的噪声和混响,数据集应尽可能覆盖不同的声学环境,包括:
- 街头
- 商店、餐厅
- 车内、家中
- 歌剧院
数据的正确性
- 数据的正确性包括:
- 音频的正确性
- 音频文件是否破损
- 音频内容是语音还是纯噪声
- 音频是否只包含单一说话人
- 说话人标签的正确性
- 标签是否发生反转,即属于说话人A的话语被标注成了说话人B的话语
- 音频的正确性
- 数据的正确性是难以达到100%的,越是大的数据集就越是会出现数据错误,著名的ImageNet ILSVRC 2012就存在至少十万个数据错误
- 音频错误可视为一种离群点噪声,标签错误可视为一种标签反转噪声,不同的损失函数对不同的噪声鲁棒性不一样,下图是Deep Face Recognition: A Survey中,对数据错误的讨论:
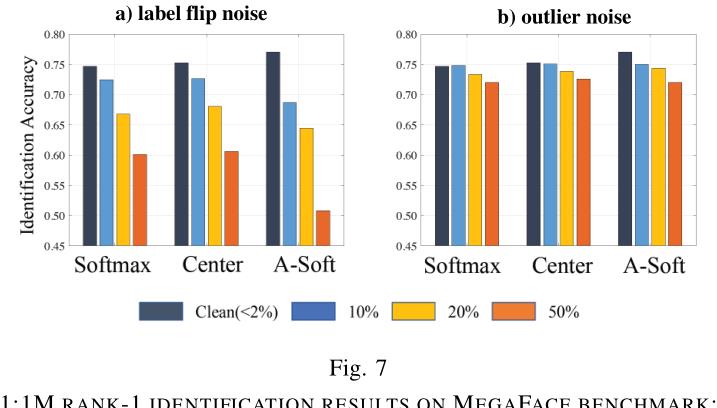
- 总而言之,数据错误越少越好,保证数据正确性很要必要,在错误的数据上做数据增强,只会创造更多Garbage
数据采集
- 不同于ImageNet、人脸等数据集,说话人识别的数据集是无法人工标注的,因为人类难以根据人的语音,辨认人的身份
- 要采集说话人识别的数据集,有两种途径:
- 在录音阶段就进行标注
- 利用视频数据里的人脸识别信息,对视频里的说话人进行标注
以上是关于说话人识别的数据需求的主要内容,如果未能解决你的问题,请参考以下文章