MySQL高频面试题
Posted 知其黑、受其白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL高频面试题相关的知识,希望对你有一定的参考价值。
阅读目录
1、B树和B+树之间的区别是什么?
2、Innodb中的B+树有什么特点?
3、什么是Innodb中的page?
4、Innodb中的B+树是怎么产生的?
5、什么是聚簇索引?
6、Innodb是如何支持范围查找能走索引的?
7、什么联合索引?对应的B+树是如何生成的?
8、什么是最左前缀原则?
9、为什么要遵守最左前缀原则才能利用到索引?
10、什么是索引条件下推?
11、什么是覆盖索引?
12、有哪些情况会导致索引失败?
1、B树和B+树之间的区别是什么?
什么是B树
利用工具
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html

插入12345678.
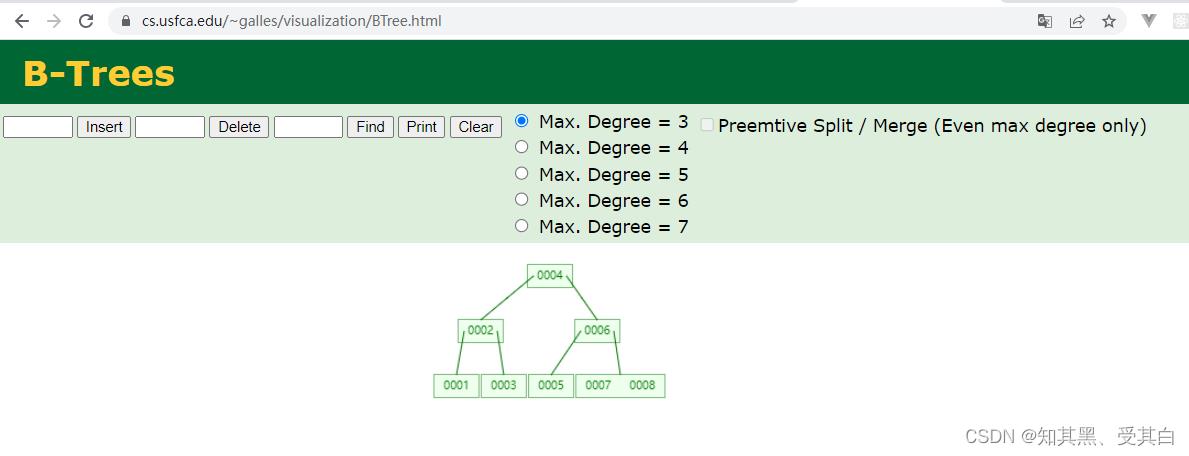
根节点指向叶子节点。
忽略了叶子节点相互的指向。
什么是B+树
利用工具
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
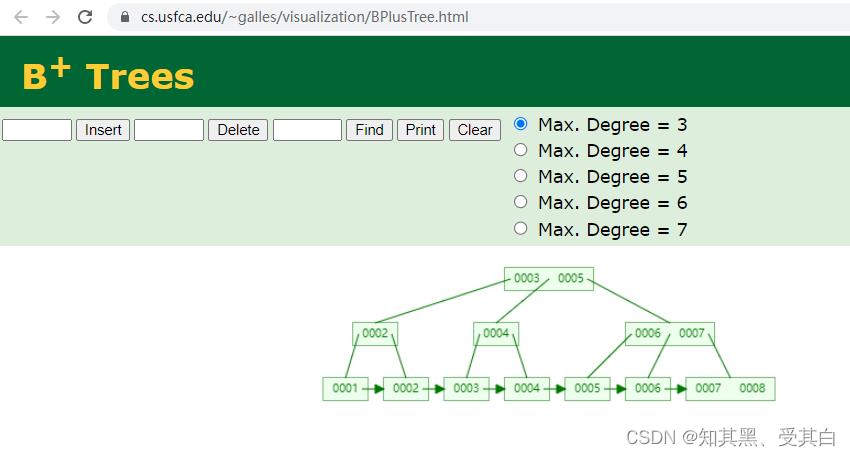
1、一个叶节点有多个元素
2、排了序
3、叶子节点有指针
4、非叶子节点都冗余了一份叶子节点,用指针联系起来的,而且是排序的。
2、mysql索引的底层数据结构
索引是帮助MySQL高效获取数据的排好序的数据结构。
索引数据结构
- 二叉树
- 红黑树
- Hash表
- B-Tree
1. 说明
我们平时所说的:
- 聚集索引(主键索引),
- 次要索引,
- 覆盖索引,
- 复合索引,
- 前缀索引,
- 唯一索引
在MySQL5.7和 8.0版本默认都是使用B+Tree索引,除此之外还有 Hash索引。至于MySQL5.7之前版本,这里就不过多探究了。
2. 有索引和没索引的区别
下图,左边表格是没有索引,右边是二叉树索引,以col2为索引列。
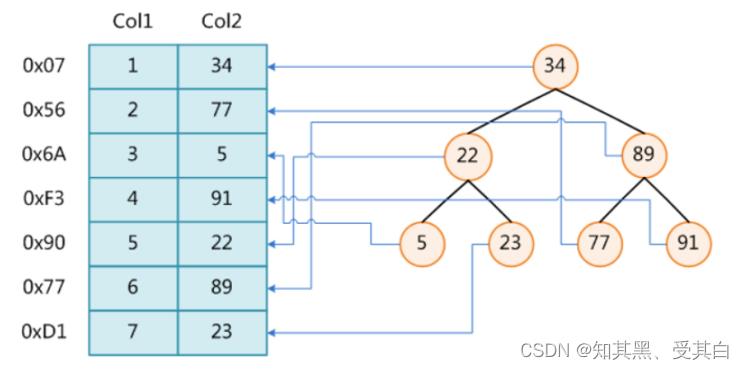
PS: 在右边二叉树的结构中,每个节点都是 key-value 键值对的形式。key:col2所在行在磁盘文件中的地址指针(比如 34 所在行,通过key中存储 0x07 这个指针就能找到是第1行),value:就是col2的值。
分析下面SQL语句
select * from t where col2 = 89;
(1). 左边没有索引,搜索 col2=89 需要从上往下搜索, 6次 才能找到,也就是 6次回表操作(6次IO)。
(2). 右边是二叉树索引,搜索 col2=89 搜索 2次 就可以找到,也就是 2次回表操作(2次IO),性能提升明显。
二叉树、红黑树、Hash
1. 二叉树
(1). 二叉树的特点
左子节点值 < 节点值;右子节点值 > 节点值;当数据量非常大时,要查找的数据又非常靠后,和没有索引相比,那么二叉树结构的查询优势将非常明显。
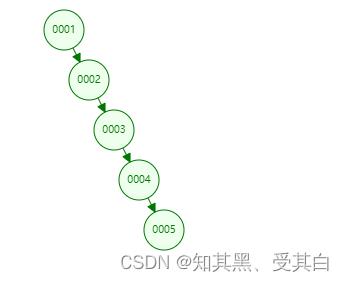
(2). 存在的问题
如下图,可以看出,二叉树出现单边增长时,二叉树变成了“链”,这样查找一个数的时候,速度并没有得到很大的优化。
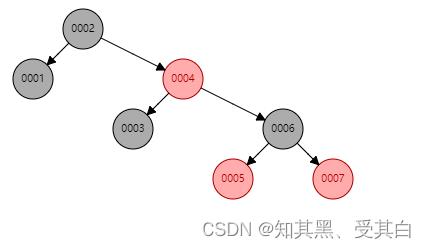
2. 红黑树
(1). 特点
A. 节点是红色或者黑色
B. 根节点是黑色
C. 每个叶子的节点都是黑色的空节点(NULL)
D. 每个红色节点的两个子节点都是黑色的。
E. 从任意节点到其每个叶子的所有路径都包含相同的黑色节点。
(2). 存在的问题
红黑树虽然和二叉树相比,一定程度上缓解了单边过长的问题,但是它依旧存储高度问题。
假设现在数据量有100万,那么红黑树的高度大概为 100,0000 = 2^n, n大概为 20。那么,至少要20次的磁盘IO,这样,性能将很受影响。如果数据量更大,IO次数更多,性能损耗更大。所以红黑树依旧不是最佳方案。
(3). 思考:针对上面的红黑树结构,我们能否优化一下呢?
上述红黑树默认一个节点就存了一个 (索引+磁盘地址),我们设想一个节点存多个 (索引+磁盘地址),这样就可以降低红黑树的高度了。 实际上我们设想的这种结构就是 B-Tree。
3. Hash
(1). 原理
A. 事先将索引通过 hash算法后得到的hash值(即磁盘文件指针)存到hash表中。
B. 在进行查询时,将索引通过hash算法,得到hash值,与hash表中的hash值比对。通过磁盘文件指针,只要一次磁盘IO就能找到要的值。
例如:
在第一个表中,要查找 col=6 的值。hash(6) 得到值,比对hash表,就能得到89。性能非常高。
(2). 存在的问题
但是hash表索引存在问题,如果要查询 带范围的条件时,hash索引就歇菜了。
select *from t where col1>=6;
3、 为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
A. 为什么要有主键?
mysql底层就是用B+Tree维护的,而B+Tree的结构就决定了必须有主键才能构建B+Tree树这个结构。每个表在磁盘上,是单独的一个文件。索引和数据都在其中,文件是按照主键索引组织的一个B+TREE结构。假如没有定义主键,MySQL会在挑选能唯一标识的字段作为索引;假如找不到,会生成一个默认的隐藏列作为主键列。
B. 为什么用整型主键?
假如使用类似 UUID 的字符串作为主键,那么在查找时,需要比较两个主键是否相同,这是一个相比整型比较 非常耗时的过程。需要一个字符,一个字符的比较,自然比较慢。
C. 为什么用自增主键?
① 后面的主键索引总是大于前面的主键索引,在做范围查询时,非常方便找到需要的数据。
② 在添加的过程中,因为是自增的,每次添加都是在后面插入,树分裂的机会小;而UUID大小不确定,分裂机会大,需要重新平衡树结构,性能损耗大。
以上是关于MySQL高频面试题的主要内容,如果未能解决你的问题,请参考以下文章
急急急!高频面试题 数据库必问——MySQL篇(基本已完结,建议收藏)