Bigtable论文笔记
Posted 神技圈子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Bigtable论文笔记相关的知识,希望对你有一定的参考价值。
Bigtable作为一个分布式存储平台,能够可靠的扩展存储PB级的数据,并分布到上千台服务器上。
适合多种应用,从需要高吞吐量的批处理工作到延时敏感的实时性服务(Bigtable是如何达到这些目的的?在架构上是如何体现的?),具有良好的可伸缩性、高效性、高可用性、高性能(如何达到这些目的?如何设计的?)。一致性、可靠性的问题,论文中没有提到(如何做到这些?依靠底层GFS,还是依靠上层应用的设计?或者不应该考虑这个问题)。
论文中提到,Bigtable利用了很多关系型数据的实现策略,具体有哪些?他们对实现Bigtable的设计目标有何帮助?
Bigtable只支持单行事物,不支持跨行事物(如何做到支持跨行,跨IDC的事物?如何在性能和事物之间找到折中?)。
Bigtable只提供一个简单的数据模型,支持动态的控制数据分布和格式,用户可推测底层数据的位置相关性(这个怎么理解?有什么实际作用?)(Megastore的数据模型相当于一个用户自定义的schema,精心设计schema对性能提高很有帮助。)
Bigtable用行名和列名对数据做了索引。Key-value形式的存储。
对每行的操作都是原子的,不管你读或者写了该行的多少列。(这样设计有何目的?)
Bigtable按字典序组织数据,动态分区为tablets,tablets是数据分布和负载均衡的基本单位,tablets可提高读取性能,如何提高的?(tablet大小可控制,是否对适应各种应用有帮助?)
降低磁盘IO,利用分布式并行特性。
论文中多次提到位置相关性,可见设计上这个特性很重要。
使用列簇概念,相同列簇的数据属于同一类型,可压缩存放在一起。(设计列簇概念,目的是什么?方便存储,还是方便查询、修改等。)
访问控制是在列族层面进行的,列族是访问控制的基本单位。
读写都是以行为单位的,对行的操作都是原子的。
Bigtable提供的一些操作数据方法:
- 可建立和删除表以及列族,还可以修改集群、biao和列族的元数据;
- 支持单行上的事物处理,提供一个允许用户跨行批量写入数据的接口,但是不支持通用的跨行事务处理;
- 允许把数据项用作计数器;(这个怎么理解,有什么用处?)
- 允许用户在服务器地址空间内执行脚本程序,但不允许在脚本中向Bigtable写入数据,允许多种形式的数据转换、基于任意表达式的数据过滤以及使用多种操作符的数据汇总;
Bigtable可与Mapreduce架构一起使用。
Bigtable依赖GFS来存储日志文件和数据文件,依赖集群管理系统来调度任务、管理共享机器上的资源、处理机故障以及监视机器的状态。(这是否意味着Bigtable本身不提供相关容错处理?)
Bigtable还依赖一个高可用的、持久化的分布式锁服务组件,叫做Chubby。
Bigtable使用Chubby完成以下几个任务:
- 确保在任何给定的事件内最多最多只有一个活动的Master;
- 存储Bigtable数据的自引导指令的位置;(这个是啥意思?)应该是指所Bigtable表对应的Tablets的源数据信息位置
- 查找Tablet服务器的位置,以及在Tablet服务器失效时进行善后;
- 存储Bigtable的模式信息(每张表的列族信息)
- 存储访问控制列表;
如果Chubby长时间无法访问,Bigtable就会失效。
一个Chubby服务包含5个活动的副本,5个副本中的一个会被选为Master提供锁服务。Chubby服务器只有在大多数副本在正常运行,并且彼此之间能够相互通信的时候,才是可用的。(拜占庭将军问题,保证可靠性)
Chubby使用Paxos算法保证副本之间的一致性(副本宕机之后重新启动)。
Chubby服务中提供了一个名字空间,里面包含了很多目录和小文件,每一个目录或者小文件都可作为一个锁,对一个文件的读写都是原子的(目录是什么作用,小文件中存放的又是什么?)。
每一个Chubby的客户端的库会提供Chubby 文件的一致性缓存。
每一个客户端都会保持一个与Chubby服务器的会话,需要定时跟新会话的租约时间,否则该会话会失效,会话失效后,客户端将失去所拥有的锁和打开的句柄。
Chubby客户端还可以在Chubby文件和目录上注册毁掉函数,以便在发生改变或者会话过期的时候通知客户端。
Bigtable包含三个主要的组件:
链接到客户程序中的库(客户端用的还是服务器端用的?)、一个Master服务器和多个Tablet服务器
针对系统工作的负载变化情况,Bigtable可以动态的向集群中添加(或者删除)Tablet服务器(Bigtable如何感知到负载的变化情况?依赖集群管理系统,还是Master服务器?)
Master服务器的组要工作:
- 将Tablets分配给Tablet服务器;
- 检测新加入的或者过期的Tablet服务器,同时进行负载均衡;
- 对保存在GFS上的文件进行垃圾收集;(这个是如何做的,流程是怎么样的,如何触发这个操作?)
- 处理对模式的相关修改操作,如建表和列族等。
每个Tablet服务器管理一个Tablet的集合(通常每个Tablet服务器有大约数十个至上千个Tablet)。
Tablet服务器的主要工作:
- 负责处理它所加载的Tablet的读写操作(从底层的SSTable到上层Bigtable的recover过程是怎样的?)
- 在Tablet过大时,对其进行分割。
Bigtable的客户程序不必通过Master服务器来获取Tablet的位置信息,也不通过Master来获取数据。客户程序直接和Tablet服务器通信进行读写操作。
一个Bigtable集群中存储了很多表,每个表包含了一个Tablet的集合,即一张表被切分成了多个Tablet,每个Tablet都是某个范围内的行的集合,这些行包含相互关联的数据。
在初始状态下,一个表只有一个Tablet,随着数据的增长,它被自动的分割成多个Tablet,缺省情况下,每个Tablet的尺寸大小约是100MB到200MB。
Tablet的位置
记录使用一个三层结构、类似B+树的结构来存储Tablet的位置信息。
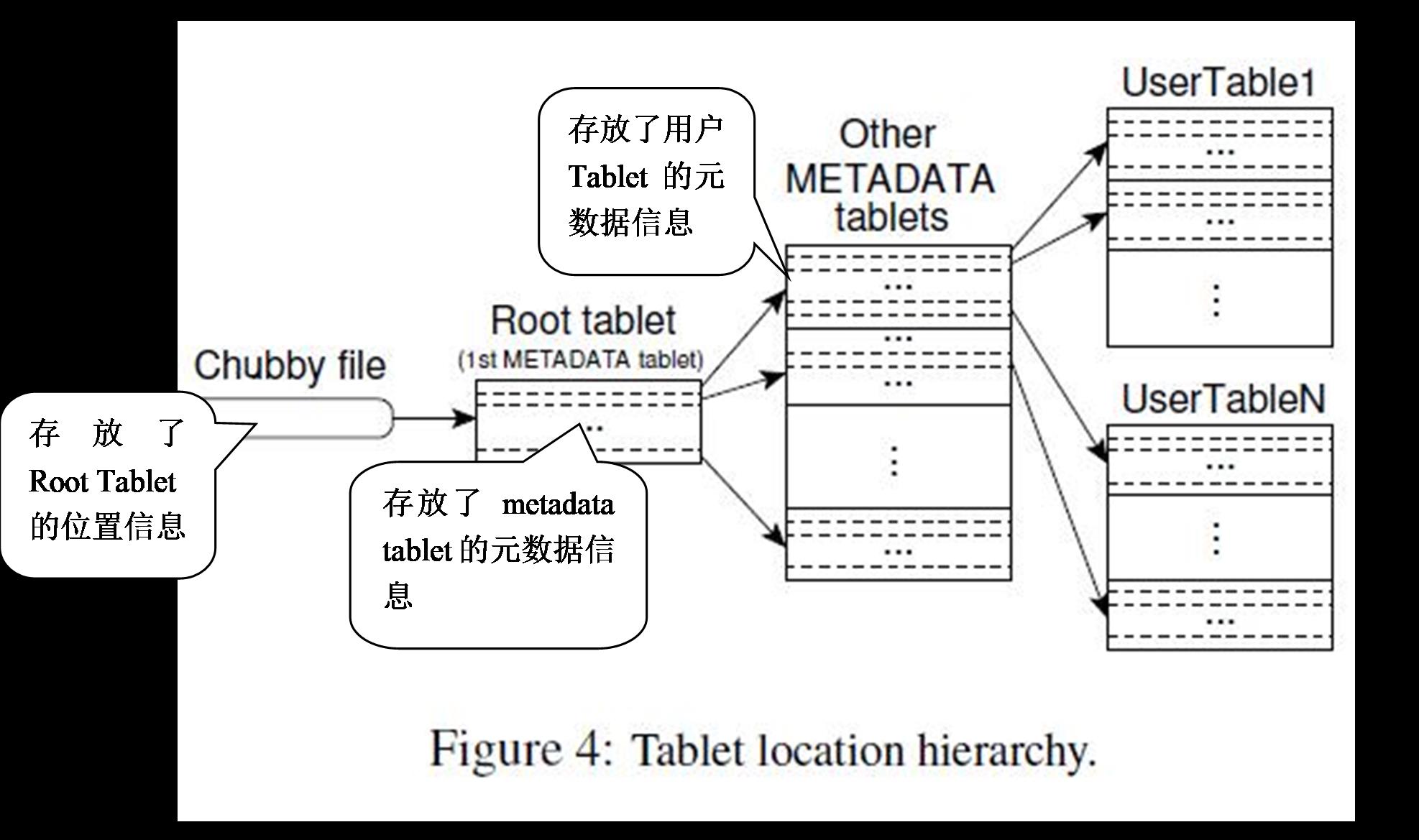
所有表的Tablet的元数据信息可构成新的Tablet,这些Tablet的存储跟其他的存放数据的Tablet一样存放。(client通过查找这些元数据信息知道tablet的位置;Master在启动的时候通过扫描这些元数据信息,确认从Tablet服务器上获得的tablet分布信息;一个Tablet在恢复的时候,会读取这些元数据信息,获得组成这个tablet的SSTable列表)
第一层是一个存放在Chubby中的文件,该文件记录了Root Tablet的位置信息(不仅存放了位置信息,还存放了其他一些元数据信息,包括一个Tablet包含的SSTable列表,以及REDO point)。
Redo point本质上是一个事件(一个更新操作),可看成一个标志,在redo point之前的所有操作所涉及的改变已经全部写入到磁盘上,他们对数据的恢复没有用处,redo point之后的操作所做的改变还未写入到磁盘上,如果此时出现故障,那么数据恢复就会从该redo point开始,按照日志恢复数据。
第二层为一个Root Tablet,这个tablet记录了在一个特殊的METADATA表的所有Tablet的位置信息,每个METADATA表的tablet记录的是用户tablet(正真存放数据的tablet)集合的位置信息。
第三层是许多的METADATA tablets,其中存放了所有用户tablet(存放数据的tablet)的位置信息。
第一层的root tablet和第二层的存放用户tablet位置信息METADATA tablet都来自一个特殊的METADATA表(一个Bigtable表),root tablet是该表的第一个tablet,root tablet被特殊处理,它永远不会被分割,以此来保证tablet位置信息的存储永远不会超过三层。
每一个tablet的位置信息在METADATA表中占一行,这个tablet的位置信息是存放在一个行关键字下面,这个行关键字由该tablet所在表的标识符以及这个tablet的最后一行编码而成。每一行存放了大约1K的数据。如果METADATA tablet的大小为128MB,则这个三层结构可存放(27*210*27*210=)234个tablet(如果每个tablet存放128M数据(默认情况下一个tablet为100M~200M),则三层结构可存放(234*27*210*210=)261个字节数据)
整个元数据信息为(27*210*128M)16T
客户端会缓存tablet的位置信息。
如果客户端不知道某个tablet的位置信息或者发现缓存的位置信息有错(比如一个tablet server下线了),那么客户端就会递归的查询上述tablet位置的三层结构,如果客户端缓存为空,则查询算法需要三个来回才能确定一个tablet的位置,具体是第一个来回读取Chubby中的文件,知道root tablet所在的位置,第二个来回,在root tablet中查找对应的METADATA tablet位置,第三个来回,查找对应的METADATA tablet,获取tablet的位置信息。
如果缓存过期,则需要最多6个来回,因为只有在没有找到对应的用户tablet(未击中)的时候才知道缓存已经过期了(如果METADAT tablet经常改变的化,会造成性能的下降)。
缓存机制减少了与GFS的交互,同时也提供预读机制。
METADATA表中还存放了次级信息,包括所有事件的日志(比如一个tablet服务器什么时候提供为一个tablet提供服务的),这些信息有助于调试和性能分析。
以上是关于Bigtable论文笔记的主要内容,如果未能解决你的问题,请参考以下文章