spark技术特点
Posted 苏云南雁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark技术特点相关的知识,希望对你有一定的参考价值。
一、Hadoop是什么?Hadoop和Spark有什么区别
Hadoop是什么?
-
Hadoop是一个开源的框架,可编写和运行分布式应用处理大规模数据,是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。Hadoop=HDFS(文件系统,数据存储技术相关)+ Mapreduce(数据处理),Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力,不管任何数据形式最终会转化为key/value,key/value是基本数据单元。用函数式编程Mapreduce代替SQL,SQL是查询语句,而Mapreduce则是使用脚本和代码,而对于适用于关系型数据库,习惯SQL的Hadoop有开源工具hive代替。
-
Spark就是一个分布式计算的解决方案。
Hadoop和Spark的区别
1、解决问题的层面不一样
-
Hadoop实质上更多是一个分布式数据基础设施,它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储;同时hadoop也能做离线计算
-
Spark,则是那么一个专门用来对那些分布式存储的大数据进行处理的工具,它并不会进行分布式数据的存储。
2、Spark数据处理速度秒杀MapReduce
-
hadoop的mapreduce要大量操作磁盘IO,MapReduce是分步对数据进行处理的: ”从集群中读取数据,进行一次处理,将结果写到集群,从集群中读取更新后的数据,进行下一次的处理,将结果写到集群,等等…“
-
Spark,它会在内存中以接近“实时”的时间完成所有的数据分析:“从集群中读取数据,完成所有必须的分析处理,将结果写回集群,完成,”
3、灾难恢复
-
Hadoop将每次处理后的数据都写入到磁盘上,所以其天生就能很有弹性的对系统错误进行处理。
-
Spark的数据对象存储在分布于数据集群中的叫做弹性分布式数据集(RDD: Resilient Distributed Dataset)中。“这些数据对象既可以放在内存,也可以放在磁盘,所以RDD同样也可以提供完成的灾难恢复功能,”
3、处理数据
-
Hadoop适合处理静态数据,对于迭代式流式数据的处理能力差;
-
Spark通过在内存中缓存处理的数据,提高了处理流式数据和迭代式数据的性能;
4、中间结果
-
Hadoop中中间结果存放在HDFS中,每次MR都需要刷写-调用;
-
Spark中间结果存放优先存放在内存中,内存不够再存放在磁盘中,不放入HDFS,避免了大量的IO和刷写读取操作.
二、Spark技术特点,架构思路
1、spark有四个技术特点
Simple(简单)、Fast(快速)、Scalable(可扩展的?)、Unified(统一的,通用的)
这里补充下spark产生的原因,基于MRv1的缺陷、MRv2的缺陷,通过5方面的优化,形成spark计算引擎,也就是这4个特点的基础。
(1)MRv1的缺陷:早在 Hadoop1.x 版本,当时采用的是 MRv1 版本的 MapReduce 编程模型。MRv1包括三个部分:运行时环境(JobTracker和TaskTracker)、编程模型(MapReduce)、数据处理引擎(MapTask和ReduceTask)。 它存在如下不足之处: ①可扩展性差 JobTracker既负责资源管理又负责任务调度,当集群繁忙时,JobTracker很容易成为瓶颈 ②可用性差 当集群繁忙时,JobTracker很容易成为瓶颈 ③资源利用率低 TaskTracker使用“slot”等量划分本节点上的资源量 ④资源利用率低
(2)MRv2的缺陷:MRv2中,重用了MRv1中的编程模型和数据处理引擎。但是运行时环境被重构了。存在不足之处:磁盘 I/O 成为系统性能的瓶颈,因此只适用于离线数据处理或批处理,而不能支持对迭代式、交互式、流式数据的处理。
(3)spark诞生,从五个方面做了优化:①减少磁盘I/O;②增加并行度;③避免重新计算;④可选的shuffle和排序;⑤灵活的内存管理策略
2、主要功能(Key features)
①Batch/streaming data (批/流式数据)
Unify the processing of your data in batches and real-time streaming, using your preferred language: Python, SQL, Scala, Java or R.
统一处理批量数据和实时流数据,使用您喜爱的语言:Python, SQL, Scala, Java或R。
②SQL analytics(SQL分析)
Execute fast, distributed ANSI SQL queries for dashboarding and ad-hoc reporting. Runs faster than most data warehouses.
执行快速、分布式的ANSISQL查询以实现仪表板和临时报告。运行速度比大多数数据仓库快。
③Data science at scale(大规模数据科学)
Perform Exploratory Data Analysis (EDA) on petabyte-scale data without having to resort to downsampling
对PB级数据执行探索性数据分析(EDA),而无需进行采用降维技术
④Machine learning(机器学习)
Train machine learning algorithms on a laptop and use the same code to scale to fault-tolerant clusters of thousands of machines.
在笔记本电脑上训练机器学习算法,并使用相同的代码扩展到数千台机器的容错集群。
3、spark的技术架构
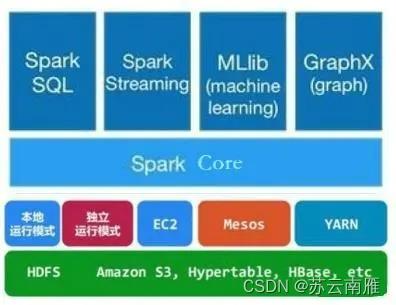
spark是基于Hadoop分布式文件系统HDFS的计算引擎,框架核心模块为:
Spark Core:包含Spark的基本功能,包含任务调度、内存管理、错误恢复、存储系统交互等模块,以及对弹性分布式数据集RDD的API定义。
Spark SQL:是操作结构化数据的程序包,通过Spark SQL可以使用SQL或者HQL来查询多种数据源,比如Hive表、Parquet以及JSON等。
Spark Streaming:是实时数据进行流式计算的组件,允许程序能够像普通RDD一样处理实时数据。
Spark MLlib:是机器学习功能的程序库,包含分类、回归、聚类、协同过滤等操作,还提供了模型评估、数据导入等额外的支持功能。
GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。
4、spark的工作机制

spark执行流程如下:
1、当有Application提交到Spark集群后,会创建一个Driver进程。Driver初始化Application运行环境,启动SparkContext ,构建出DAGScheduler和TaskScheduler;
2、SparkContext向资源管理器(Standalone,Mesos或Yarn),注册并申请Application运行的Executor资源,Executor启动StandaloneExecutorbackend,向SparkContext注册并申请Task任务;
3、Driver执行Application,读取数据源,将待处理数据生成RDD,每执行一个Action都会创建一个Job提交给DAGScheduler;
4、DAGScheduler会为每个Job划分多个Stage,每个Stage根据RDD的Partition决定Task个数,然后每个Stage创建一个TaskSet,将TaskSet提交到TaskScheduler。TaskScheduler会将每个TaskSet里的Task,提交到Executor运行;
5、Executor每接受一个Task都会用TaskRunner封装,从线程池获取一个线程来执行,最后一个Stage的ResultTask运行完后释放所有资源。
5、spark的不同部署模式
spark以分布式集群部署时,可以依赖外部资源调度框架(Mesos,yarn或EC2),也可以使用内建的资源调度。根据资源调度器的不同,主流三种部署模式为:
Standalone模式,是自带资源调度框架的集群管理模式,即独立模式。Standalone是最简单最容易部署的一种模式,无需依赖任何其他资源管理系统,其主要的节点有 Driver 节点、Master 节点和 Worker 节点。
Spark on YARN模式,是运行在Hadoop YARN框架的模式,使用YARN为上层应用提供统一的资源管理和调度,已成为大数据集群资源管理系统的标准。目前仅支持粗粒度模式,在YARN上的Container资源是不可以动态伸缩的,一旦Container启动之后,可使用的资源将不再发生变化。
Spark on Mesos模式,是运行在Apache Mesos框架的模式,作为官方推荐的模式。Apache Mesos是一个更强大的分布式资源管理框架,负责集群资源的分配,Spark运行在Mesos上会比运行在YARN上更加灵活,不仅支持粗粒度模式,还提供细粒度调度模式,实现资源使用中按需分配。
6、spark技术的启示
spark项目比较有特点的一项是,用了分层的思路,他并不试图全部都完成,对于存储这块依然使用了HDFS,反而对于计算这一层,单独抽取出来进行完善,然后用RDD来完成存储、调用的过程,这个思路很重要的一点就是妥善地划分好过程,进行分层处理,每一个项目专注于解决一项问题。
6、Spark基本架构
从集群部署的角度来看,Spark集群由以下部分组成:
-
Cluster Manager
-
Worker
-
Executor
-
Driver
-
Application
Cluster Manager
-
集群管理器,主要负责整个集群资源的分配与管理;
-
Cluster Manger分配的资源属于一级分配,将各个Worker上的内存、CPU分配给Application,但并不负责对Executor资源的分配
-
YARN部署模式下为ResourceManager
Worker
-
工作节点,YARN部署模式下由NodeManager替代;
-
负责以下工作:
-
将自己的内存、CPU等资源通过注册的机制告知ClusterManger
-
创建Executor
-
将资源和任务进一步分配给Executor
-
同步资源信息、Executor状态信息给Cluster Manager
-
Executor
-
执行任务的一线组件
-
主要负责:
-
任务的执行
-
与Worker、Driver信息的同步
-
Driver
-
Application的驱动程序,Application通过Driver与Cluster Manager和Executor进行通信;
-
Driver可以运行在Application中,也可以由Application提交给Cluster Manager并由Cluster Manager安排Worker执行;
三、Spark的核心机制有哪些
1、RDD
1.1 RDD概述
-
RDD 是 Spark 的基石,是实现 Spark 数据处理的核心抽象。那么 RDD 为什么会产生呢?
-
MapReduce的这种方式对数据领域两种常见的操作不是很高效。第一种是迭代式的算法。比如机器学习中ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MapReduce这种模式不太合适,即使多MapReduce串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MapReduce显然不擅长。
-
我们需要一个效率非常快,且能够支持迭代计算和有效数据共享的模型,Spark应运而生。RDD是基于工作集的工作模式,更多的是面向工作流。
-
但是无论是MapReduce还是RDD都应该具有类似位置感知、容错和负载均衡等特性。
1.2. 什么是RDD
-
RDD(Resilient Distributed Dataset)叫做分布式数据集,是 Spark 中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
-
在 Spark 中,对数据的所有操作不外乎创建RDD、转化已有 RDD 以及调用RDD操作进行求值。
可以从三个方面来理解:
-
只读数据集DataSet: RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的 RDD。
-
分布式Distributed/分区:RDD的数据可能在物理上存储在多个节点的磁盘或内存中,也就是所谓的多级存储。
-
弹性Resilient:虽然 RDD 内部存储的数据是只读的,但是,我们可以去修改分区的数量。
Spark的RDD的弹性 :
-
存储的弹性:内存和磁盘的自动切换
-
容错的弹性:数据丢失可以自动恢复
-
计算的弹性:计算出错重试机制
-
分片的弹性:根据需要重新分片
RDDs之间的依赖关系:基于RDDs之间的依赖,RDDs会形成一个有向无环图DAG,该DAG描述了整个流式计算的流程,实际执行的时候,RDD是通过血缘关系(Lineage)一气呵成的,即使出现数据分区丢失,也可以通过血缘关系重建分区,
Lineage :RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
DAG生成:DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage。
1.3. RDD缓存
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存个数据集。当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
Checkpoint
-
Spark中对于数据的保存除了持久化操作之外,还提供了一种检查点的机制,检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。检查点通过将数据写入到HDFS文件系统实现了RDD的检查点功能。
-
cache和checkpoint是有显著区别的,缓存把RDD计算出来然后放在内存中,但是RDD 的依赖链(相当于数据库中的redo日志),也不能丢掉,当某个点某个executor宕了,上面 cache的RDD就会丢掉,需要通过依赖链重放计算出来,不同的是,checkpoint是把RDD保存在HDFS中,是多副本可靠存储,所以依赖链就可以丢掉了,就斩断了依赖链,是通过复制实现的高容错。
2、Shuffle
Shuffle,翻译成中文就是洗牌。之所以需要Shuffle,还是因为具有某种共同特征的一类数据需要最终汇聚(aggregate)到一个计算节点上进行计算。这些数据分布在各个存储节点上并且由不同节点的计算单元处理。
2.1.ShuffleManager
发展概述 :
-
在 Spark 1.2 以前,默认的shuffle计算引擎是 HashShuffleManager。该 ShuffleManager 而HashShuffleManager有着一个非常严重的弊端,就是会产生大量的中间磁盘文件,进而由大量的磁盘IO操作影响了性能
-
因此在Spark 1.2以后的版本中,默认的 ShuffleManager 改成了 SortShuffleManager。SortShuffleManager 相较于 HashShuffleManager 来说,有了一定的改进。主要就在于,每个 Task在进行 shuffle 操作时,虽然也会产生较多的临时磁盘文件,但是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个 Task 就只有一个磁盘文件。在下一个stage的 shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
HashShuffleManager的运行原理 :
未经优化的HashShuffleManager :
-
shuffle write阶段,主要就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey),而将每个task处理的数据按key进行“分类”。所谓“分类”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。
-
shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。
优化后的HashShuffleManager :
-
开启consolidate机制之后,在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了。此时会出现shuffleFileGroup的概念,每个shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。一个Executor上有多少个CPU core,就可以并行执行多少个 task。而第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件内。
-
当Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup,包括其中的磁盘文件。也就是说,此时task会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate机制允许不同的task复用同一批磁盘文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shufflewrite的性能。
SortShuffleManager运行 :
-
Sort Based Shuffle的模式是:每个Shuffle Map Task不会为每个Reducer生成一个单独的文件;相反,它会将所有的结果写到一个文件里,同时会生成一个Index文件,
四、小结
spark技术属于分布式领域非常突出的框架,除了代码级别的设计模式可以参考,架构层面的思路也可以借鉴,不论是将计算能力分裂出来,还是用RDD抽象出来数据概念,都体现了一点,当一个领域的复杂度高到一定程度,按照重要性和必须性二次划分工作流、设计新的逻辑概念,是解决高度复杂问题的良好实践方式。
参考内容
1、简书链接:spark技术架构、工作机制,及安装使用 - 简书
2、spark官网:Apache Spark™ - Unified Engine for large-scale data analytics
3、shuffle详解:Spark Shuffle详解_帅成一匹马的博客-CSDN博客_sparkshuffle
以上是关于spark技术特点的主要内容,如果未能解决你的问题,请参考以下文章