DEiT:通过注意力训练数据高效的图像transformer &蒸馏
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DEiT:通过注意力训练数据高效的图像transformer &蒸馏相关的知识,希望对你有一定的参考价值。
摘要
最近,纯基于注意力的神经网络被证明可以解决图像理解任务,如图像分类。这些高性能的是使用大型基础设施预先训练数以亿计的图像,从而限制了它们的采用。
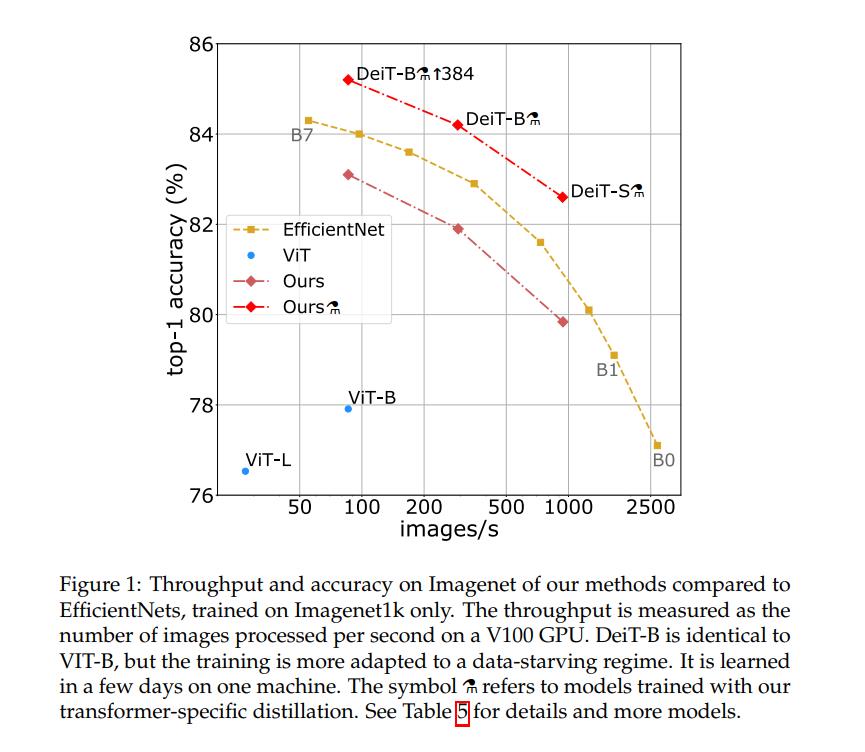
本文仅通过在Imagenet上训练,产生有竞争力的无卷积transformer。我们用一台电脑在不到3天的时间里训练它们。所提出的参考视觉transformer (86M参数)在没有外部数据的情况下,在ImageNet上实现了83.1%(单裁剪)的top-1精度。
更重要的是,引入了transformer特有的师生策略。它依赖于蒸馏标记,确保学生通过注意力从老师那里学习。展示了这种基于令牌的蒸馏的兴趣,特别是在使用convnet作为老师时。这导致我们报告的结果在Imagenet(获得高达85.2%的精度)和转移到其他任务时都与convnets竞争。我们共享我们的代码和模型。
1 介绍
卷积神经网络一直是图像理解任务的主要设计范式,正如最初在图像分类任务中演示的那样。他们成功的一个因素是大型训练集的可用性,即Imagenet[13,42]。受自然语言处理中基于注意的模型的成功[14,52]的激励,人们对利用convnets中的注意机制的架构越来越感兴趣[2,34,61]。最近,一些研究人员提出了将transformers成分移植到convet的混合架构,以解决视觉任务[6,43]。
Dosovitskiy等人[15]介绍的vision transformer(ViT)是直接继承自然语言处理[52]的体系结构,但应用于以原始图像补丁为输入的图像分类。他们的论文展示了用大型私有标记图像集(JFT-300M[46], 3亿张图像)训练的transformers的出色结果。本文的结论是,transformers“在数据量不足的情况下,不能很好地进行泛化训练”,而这些模型的训练需要大量的计算资源。
在本文中,我们用2到3天(53小时的预训练,可选的20小时的微调)在单个8-GPU节点上训练一个vision transformer,这与具有相似数量参数和效率的convnets具有竞争力。它使用Imagenet作为唯一的训练集。我们在Dosovitskiy等人[15]的可视化转换器架构和timm库[55]中的改进基础上进行构建。使用我们的数据高效图像转换器(DeiT),我们报告了比以前结果的较大改进,参见图1。我们的消融研究详细描述了超参数和成功训练的关键成分,如重复增强。
我们要解决另一个问题:如何蒸馏这些模型?我们介绍了一种基于令牌的策略,具体到transformers,用DeiT⚗表示,并表明它有效地取代了通常的蒸馏。
综上所述,我们的工作有以下贡献:
- 不包含卷积层的神经网络在没有外部数据的情况下,可以在ImageNet上取得与最先进水平相当的结果。它们在三天内使用4个GPU在单个节点上完成训练。我们的两个新模型DeiT-S和DeiT-Ti具有更少的参数,可以被视为ResNet-50和ResNet-18的对应模型。
- 引入了一个基于蒸馏标记的新蒸馏程序,其作用与类标记相同,只是它旨在重现老师估计的标签。两个token通过注意力在transformer中相互作用。这种特定于transformer的策略明显优于vanilla distillation。
- 有趣的是,通过蒸馏,图像transformer从卷积网络中学到的东西比从另一个性能相当的transformer中学到的东西更多。
- 在Imagenet上预学习的模型在迁移到不同的下游任务时,如细粒度分类,在几个流行的公共基准上是有竞争力的:CIFAR-10、CIFAR-100、牛津-102鲜花、斯坦福汽车和iNaturalist-18/19。
本文的构成如下:回顾了第2节中的相关工作,并在第3节中重点介绍了用于图像分类的transformer。我们将在第4节介绍transformer的蒸馏策略。实验部分第5节提供了与convnets和最近的transformer的分析和比较,以及对特定于transformer的蒸馏的比较评估。第六节详细介绍了我们的培训计划。它包括对数据高效训练选择的广泛消融,这对DeiT所涉及的关键成分提供了一些见解。我们在第7节结束。
2 相关工作
图像分类是计算机视觉的核心,经常被用作衡量图像理解进展的基准。任何进展通常都会转化为其他相关任务的改进,如检测或分割。自2012年AlexNet[32]以来,convnets一直主导这一基准,并已成为事实上的标准。ImageNet数据集[42]上最新技术的发展反映了卷积神经网络架构和学习的进展[32,44,48,50,51,57]。
尽管有几次尝试使用transformers进行图像分类[7],但到目前为止,它们的性能一直不如卷积网络。然而,结合卷积网络和transformers的混合架构,包括自注意机制,最近在图像分类[56]、检测[6,28]、视频处理[45,53]、无监督对象发现[35]和统一文本视觉任务[8,33,37]方面展示了具有竞争力的结果。
最近,视觉 transformers(ViT)[15]在不使用任何卷积的情况下缩小了与ImageNet上最先进技术的差距。这种性能是显著的,因为卷积图像分类方法受益于多年的调整和优化[22,55]。然而,根据这项研究[15],需要对大量策展数据进行预训练才能使学习的transformers有效。在我们的论文中,我们不需要大量的训练数据集,即仅使用Imagenet1k,就实现了强大的性能。
由Vaswani等人提出的用于机器翻译的Transformer架构目前是所有自然语言处理(NLP)任务的参考模型。许多用于图像分类的卷积算法的改进都是受到transformers的启发。例如,挤压和激励[2]、选择核[34]和分裂注意网络[61]利用了类似transformers自注意(SA)机制的机制。
由Hinton等人提出的知识蒸馏(KD)是指学生模型利用来自强大教师网络的“软”标签的训练范式。这是教师的softmax函数的输出向量,而不仅仅是分数的最大值,它给出了一个“硬”标签。这样的训练提高了学生模型的表现(或者,它可以被看作是将教师模型压缩成一个更小的模型——学生)。一方面,老师的软标签将有类似的标签平滑[58]的效果。另一方面,如Wei et al.[54]所示,教师的监督考虑了数据增强的影响,有时会导致真实标签与图像之间的错位。例如,让我们考虑一个带有“猫”标签的图像,它代表一个大的风景和角落里的一只小猫。如果猫不再在数据增强的作物上,它会隐式地改变图像的标签。KD可以将归纳偏差[1]以一种温和的方式转移到学生模型中,使用教师模型,其中它们将以一种艰难的方式合并。例如,通过使用卷积模型作为教师,在转换器模型中诱导由于卷积而产生的偏差可能是有用的。在我们的论文中,我们研究了一个transformers学生或transformers教师的蒸馏。介绍了一种新的transformers蒸馏工艺,并说明了该工艺的优越性。
3 视觉transformer概述
在本节中,我们简要回顾与视觉transformer相关的初步内容[15,52],并进一步讨论位置编码和分辨率。
多头自注意力层(MSA)。 注意力机制基于(键,值)向量对的可训练联想记忆。使用内积将查询向量
q
∈
R
d
q \\in \\mathbbR^d
q∈Rd与一组k个键向量(打包成矩阵
K
∈
R
k
×
d
K \\in \\mathbbR^k \\times d
K∈Rk×d)进行匹配。然后用softmax函数对这些内积进行缩放和归一化,以获得k个权重。注意力的输出是一组k值向量的加权和(打包成
V
∈
R
k
×
d
V \\in \\mathbbR^k \\times d
V∈Rk×d)。对于一个包含N个查询向量的序列(打包到
Q
∈
R
N
×
d
Q \\in \\mathbbR^N \\times d
Q∈RN×d中),它产生一个输出矩阵(大小为
N
×
d
N×d
N×d):
Attention
(
Q
,
K
,
V
)
=
Softmax
(
Q
K
⊤
/
d
)
V
(1)
\\operatornameAttention(Q, K, V)=\\operatornameSoftmax\\left(Q K^\\top / \\sqrtd\\right) V \\tag1
Attention(Q,K,V)=Softmax(QK⊤/d)V(1)
其中,Softmax函数应用于输入矩阵的每一行,
d
\\sqrtd
d项提供适当的归一化。
在[52]中,提出了自注意力层。查询、键和值矩阵本身是从N个输入向量序列中计算出来的(打包成 X ∈ R N × D X \\in \\mathbbR^N \\times D X∈RN×D): Q = X W Q , K = X W K , V = X W V Q=X W_\\mathrmQ, K=X W_\\mathrmK, V=X W_\\mathrmV Q=XWQ,K=XWK,V=XWV,使用线性变换 W Q , W K , W V W_\\mathrmQ, W_\\mathrmK, W_\\mathrmV WQ,WK,WV的约束条件是k = N,这意味着注意力位于所有输入向量之间。
最后,通过考虑h个注意力"头",即h个自注意力函数应用于输入,定义了多头自注意力层(MSA)。每个头提供一个大小为N × d的序列。这些h序列被重新排列为N × dh序列,并通过线性层重投影到N × d中。
用于图像的Transformer块。为了像[52]那样得到一个完整的transformer块,我们在MSA层的顶部添加一个前馈网络(FFN)。该FFN由两个线性层组成,由GeLu激活的[23]分隔。第一层线性层将维度从D扩展到4D,第二层将维度从4D降回D。由于skip-connections, MSA和FFN都作为残差算子运行,并具有层归一化[3]。
为了让transformer处理图像,我们的工作建立在ViT模型[15]的基础上。这是一个简单而优雅的架构,它处理输入图像就像处理输入标记序列一样。将固定大小的输入RGB图像分解为N个固定大小的16 × 16像素块(N = 14 × 14)。每个patch被投影为一个线性层,该层保持其整体尺寸3 × 16 × 16 = 768。
上面描述的transformer块与块嵌入的顺序无关,因此没有考虑它们的相对位置。位置信息被合并为固定的[52]或可训练的[18]位置嵌入。它们被添加到第一个transformer块之前的补丁令牌,然后将补丁令牌馈送到transformer块的堆栈。
类令牌是一个可训练的向量,添加到第一层之前的patch标记中,通过transformer层,然后用线性层进行投影以预测类。这个类令牌继承自NLP[14],并与计算机视觉中用于预测类的典型池化层不同。因此,transformer处理D维的(N + 1)批次令牌,其中只有类向量用于预测输出。这种架构迫使自注意力在块标记和类标记之间传播信息:在训练时,监督信号仅来自类嵌入,而块令牌是模型的唯一变量输入。
修复跨分辨率的位置编码。 Touvron等人的[50]研究表明,使用较低的训练分辨率并在较大的分辨率下微调网络是可取的。这加快了完全训练的速度,并提高了在主流数据增强方案下的准确性。当增加输入图像的分辨率时,我们保持patch大小相同,因此输入patch的数量N确实会改变。由于transformer块和类标记的架构,模型和分类器不需要修改以处理更多标记。相比之下,人们需要适应位置嵌入,因为有N个位置嵌入,每个patch一个。Dosovitskiy 等人[15]在改变分辨率时插值位置编码,并证明该方法在后续的微调阶段有效。
4 通过注意力蒸馏
在本节中,我们假设我们可以使用一个强大的图像分类器作为教师模型。它可以是卷积网络,也可以是分类器的混合。本文解决了如何利用这个老师来学习transformer的问题。正如我们将在第5节中通过比较精度和图像吞吐量之间的权衡看到的,用transformer代替卷积神经网络可能是有益的。本节涵盖蒸馏的两个轴:硬蒸馏与软蒸馏,以及经典蒸馏与蒸馏token。
软蒸馏:[24,54]最小化教师模型的softmax和学生模型的softmax之间的Kullback-Leibler散度。
Z
t
Z_t
Zt是教师模型的对数,
Z
s
Z_s
Zs是学生模型的对数。我们通过
τ
τ
τ表示用于蒸馏的温度,λ表示平衡地面真值标签y上的Kullback-Leibler散度损失(KL)和交叉熵(LCE)的系数,以及softmax函数。蒸馏的目的是:
L
global
=
(
1
−
λ
)
L
C
E
(
ψ
(
Z
s
)
,
y
)
+
λ
τ
2
K
L
(
ψ
(
Z
s
/
τ
)
,
ψ
(
Z
t
/
τ
)
)
(2)
\\mathcalL_\\text global =(1-\\lambda) \\mathcalL_\\mathrmCE\\left(\\psi\\left(Z_\\mathrms\\right), y\\right)+\\lambda \\tau^2 \\mathrmKL\\left(\\psi\\left(Z_\\mathrms / \\tau\\right), \\psi\\left(Z_\\mathrmt / \\tau\\right)\\right) \\tag2
Lglobal =(1−λ)LCE(ψ(Zs),y)+λτ2KL(ψ(Zs/τ),ψ(Zt/τ))(2)
Hard-label蒸馏。我们引入了蒸馏的一种变体,将老师的艰难决定作为真正的标签。设
y
t
=
argmax
c
Z
t
(
c
)
y_\\mathrmt=\\operatornameargmax_c Z_\\mathrmt(c)
yt=argmaxcZt(c)是教师的困难决策,与此硬标签蒸馏相关的目标是:
L
global
hardDistill
=
1
2
L
C
E
(
ψ
(
Z
s
)
,
y
)
+
1
2
L
C
E
(
ψ
(
Z
s
)
,
y
t
)
(3)
\\mathcalL_\\text global ^\\text hardDistill =\\frac12 \\mathcalL_\\mathrmCE\\left(\\psi\\left(Z_s\\right), y\\right)+\\frac12 \\mathcalL_\\mathrmCE\\left(\\psi\\left(Z_s\\right), y_\\mathrmt\\right) \\tag3
Lglobal hardDistill =21LCE(ψ(Zs),y)+21LCE(ψ(Zs),yt)(3)
对于给定的图像,与教师相关的硬标签可能会改变,这取决于特定的数据增强。我们将看到,这种选择比传统的选择更好,而且没有参数,概念上更简单:教师预测yt扮演的角色与真实标签y相同。
还请注意,硬标签也可以通过标签平滑[47]转换为软标签,其中真实标签被认为具有
1
−
ε
1-\\varepsilon
1−ε"的概率,其余"在其余类别中共享。在所有使用真实标签的实验中,我们将此参数固定为“
ε
=
0.1
\\varepsilon= 0.1
ε=0.1”。
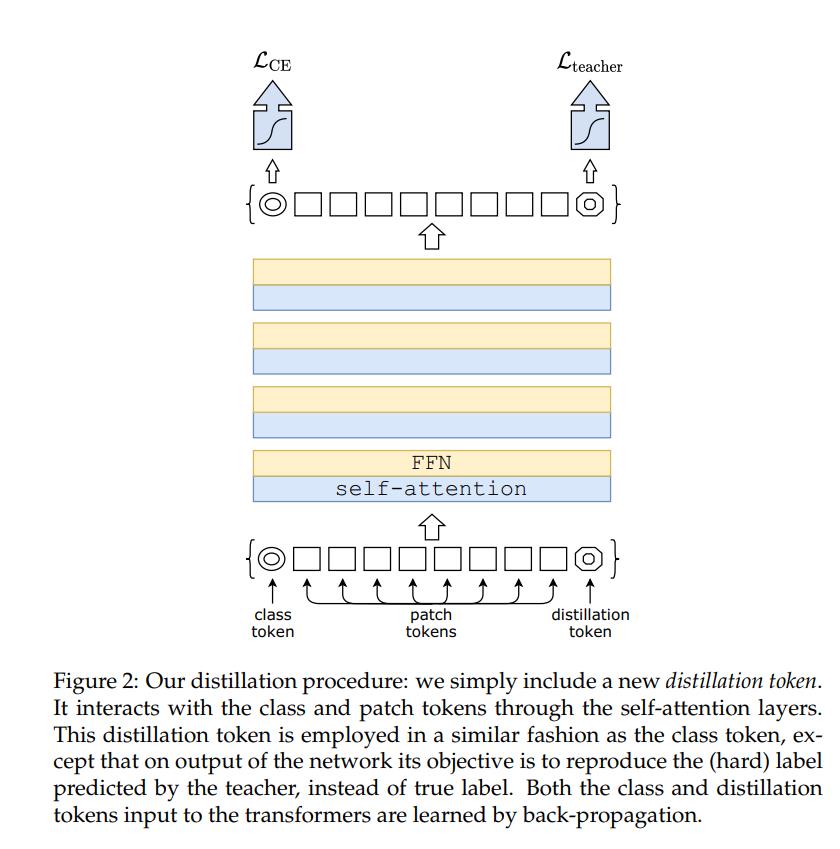
蒸馏令牌。现在我们关注我们的建议,如图2所示。我们将一个新标记,蒸馏标记,添加到初始嵌入(补丁和类标记)。蒸馏标记与类标记的使用类似:它通过自注意力与其他嵌入交互,并在最后一层后由网络输出。其目标目标由损失的蒸馏成分给出。蒸馏嵌入允许我们的模型从老师的输出中学习,就像在常规蒸馏中一样,同时与类嵌入保持互补。
有趣的是,我们观察到学习到的类和蒸馏标记收敛于不同的向量:这些标记之间的平均余弦相似度等于0.06。随着在每一层计算类嵌入和蒸馏嵌入,它们通过网络逐渐变得更相似,一直到最后一层,它们的相似度很高(cos=0.93),但仍然低于1。这是意料之中的,因为它们旨在产生相似但不相同的目标。
与简单地添加与相同目标标签相关联的额外类标记相比,我们验证了蒸馏标记向模型中添加了一些东西:我们用两个类标记进行了transformer实验,而不是教师伪标记。即使我们随机独立地初始化它们,在训练期间它们也收敛于相同的向量(cos=0.999),并且输出嵌入也准相同。这个额外的类标记对分类性能没有任何影响。相比之下,蒸馏策略比vanilla蒸馏基线有显著改进,这一点在5.2节的实验中得到了验证。
使用蒸馏进行微调。在微调阶段,我们在更高分辨率下同时使用真实标签和教师预测。我们使用具有相同目标分辨率的teacher,通常通过Touvron等人[50]的方法从较低分辨率的teacher获得。我们也只测试了真正的标签,但这降低了教师的利益,导致较低的表现。
用我们的方法分类:联合分类器。在测试时,transformer产生的类或蒸馏嵌入都与线性分类器相关,并能够推断图像标签。然而,我们的参考方法是这两个独立头部的后期融合,为此我们将两个分类器的softmax输出相加以进行预测。我们将在第5节中评估这三个选项。