Netty_03_ByteBuf和网络中拆包粘包问题及其解决
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Netty_03_ByteBuf和网络中拆包粘包问题及其解决相关的知识,希望对你有一定的参考价值。
文章目录
- 一、前言
- 二、ByteBuf(Netty API中定义的数据类型)
- 三、网络传输中的拆包粘包问题
- 四、Netty解决网络传输中的拆包粘包问题(编码解码)
- 五、小结
一、前言
本文讲述三个问题
bytebuf + 网络中的粘包拆包 + 编码解码
源码下载:https://www.syjshare.com/res/1PGT166S
二、ByteBuf(Netty API中定义的数据类型)
bytebuff四点
(1) 256 扩容方式(小于512 大于512)
(2)新建bytebuff两种方式 堆内(jvm) 堆外(操作系统)
(3)四个字段:废弃 读指针 写指针 可扩容 读写api
(4)零拷贝三种方式
2.1 ByteBuf
在Netty中,还有另外一个比较常见的对象ByteBuf,它其实等同于Java Nio中的ByteBuffer,但是
ByteBuf对Nio中的ByteBuffer的功能做了很作增强,下面我们来简单了解一下ByteBuf。
下面这段代码演示了ByteBuf的创建以及内容的打印,这里显示出了和普通ByteBuffer最大的区别之
一,就是ByteBuf可以自动扩容,默认长度是256,如果内容长度超过阈值时,会自动触发扩容
2.1.1 ByteBuf创建的方法有两种
第一种,创建基于堆内存的ByteBuf
ByteBuf buffer=ByteBufAllocator.DEFAULT.heapBuffer(10);
第二种,创建基于直接内存(堆外内存)的ByteBuf(默认情况下用的是这种)
ByteBuf buffer=ByteBufAllocator.DEFAULT.directBuffer(10);
Java中的内存分为两个部分,一部分是不需要jvm管理的直接内存,也被称为堆外内存。堆
外内存就是把内存对象分配在JVM堆意外的内存区域,这部分内存不是虚拟机管理,而是由
操作系统来管理,这样可以减少垃圾回收对应用程序的影响
直接内存的好处是读写性能会高一些,如果数据存放在堆中,此时需要把Java堆空间的数据发送到
远程服务器,首先需要把堆内部的数据拷贝到直接内存(堆外内存),然后再发送。如果是把数据
直接存储到堆外内存中,发送的时候就少了一个复制步骤
但是它也有缺点,由于缺少了JVM的内存管理,所以需要我们自己来维护堆外内存,防止内存溢出。
另外,需要注意的是,ByteBuf默认采用了池化技术来创建。关于池化技术在前面的课程中已经重复讲
过,它的核心思想是实现对象的复用,从而减少对象频繁创建销毁带来的性能开销。
池化功能是否开启,可以通过下面的环境变量来控制,其中unpooled表示不开启。
-Dio.netty.allocator.type=unpooled|pooled
public class NettyByteBufExample
public static void main(String[] args)
ByteBuf buf= ByteBufAllocator.DEFAULT.buffer();
System.out.println(buf);
2.1.2 ByteBuf的存储结构
ByteBuf的存储结构如图3-1所示,从这个图中可以看到ByteBuf其实是一个字节容器,该容器中包含三
个部分
- 已经丢弃的字节,这部分数据是无效的
- 可读字节,这部分数据是ByteBuf的主体数据,从ByteBuf里面读取的数据都来自这部分; 可写字
节,所有写到ByteBuf的数据都会存储到这一段 - 可扩容字节,表示ByteBuf最多还能扩容多少容量。
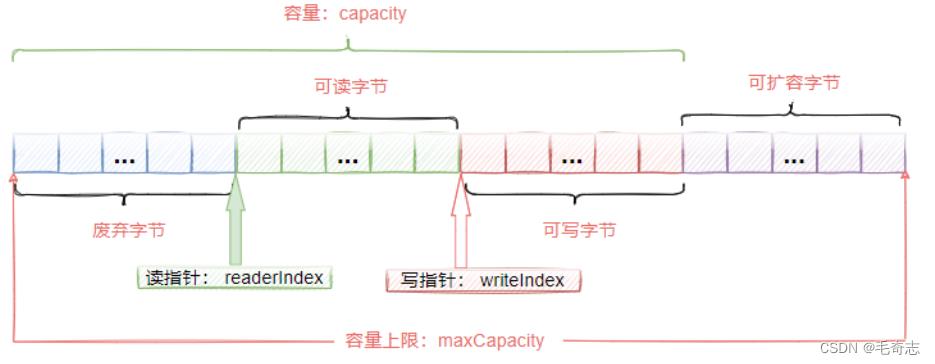
在ByteBuf中,有两个指针
- readerIndex: 读指针,每读取一个字节,readerIndex自增加1。ByteBuf里面总共有* witeIndexreaderIndex个字节可读,当readerIndex和writeIndex相等的时候,ByteBuf不可读
- writeIndex: 写指针,每写入一个字节,writeIndex自增加1,直到增加到capacity后,可以触发
扩容后继续写入。 - ByteBuf中还有一个maxCapacity最大容量,默认的值是 Integer.MAX_VALUE ,当ByteBuf写入数
据时,如果容量不足时,会触发扩容,直到capacity扩容到maxCapacity。
2.1.3 ByteBuf中常用的方法API
对于ByteBuf来说,常见的方法就是读入和写出
Reader相关方法
reader方法针对不同数据类型提供了不同的操作方法,
readByte ,读取单个字节
readInt , 读取一个int类型
readFloat ,读取一个float类型
Write相关方法
对于write方法来说,ByteBuf提供了针对各种不同数据类型的写入,比如
writeChar,写入char类型
writeInt,写入int类型
writeFloat,写入float类型
writeBytes, 写入nio的ByteBuffer
writeCharSequence, 写入字符串
Write可能导致扩容
当向ByteBuf写入数据时,发现容量不足时,会触发扩容,而具体的扩容规则是
假设ByteBuf初始容量是10。
如果写入后数据大小未超过512个字节,则选择下一个16的整数倍进行库容。 比如写入数据后大
小为12,则扩容后的capacity是16。
如果写入后数据大小超过512个字节,则选择下一个2
n。 比如写入后大小是512字节,则扩容后的
capacity是2
10=1024 。(因为2
9=512,长度已经不够了)
扩容不能超过max capacity,否则会报错。
2.2 ByteBuf代码(演示读写指针移动和扩容)
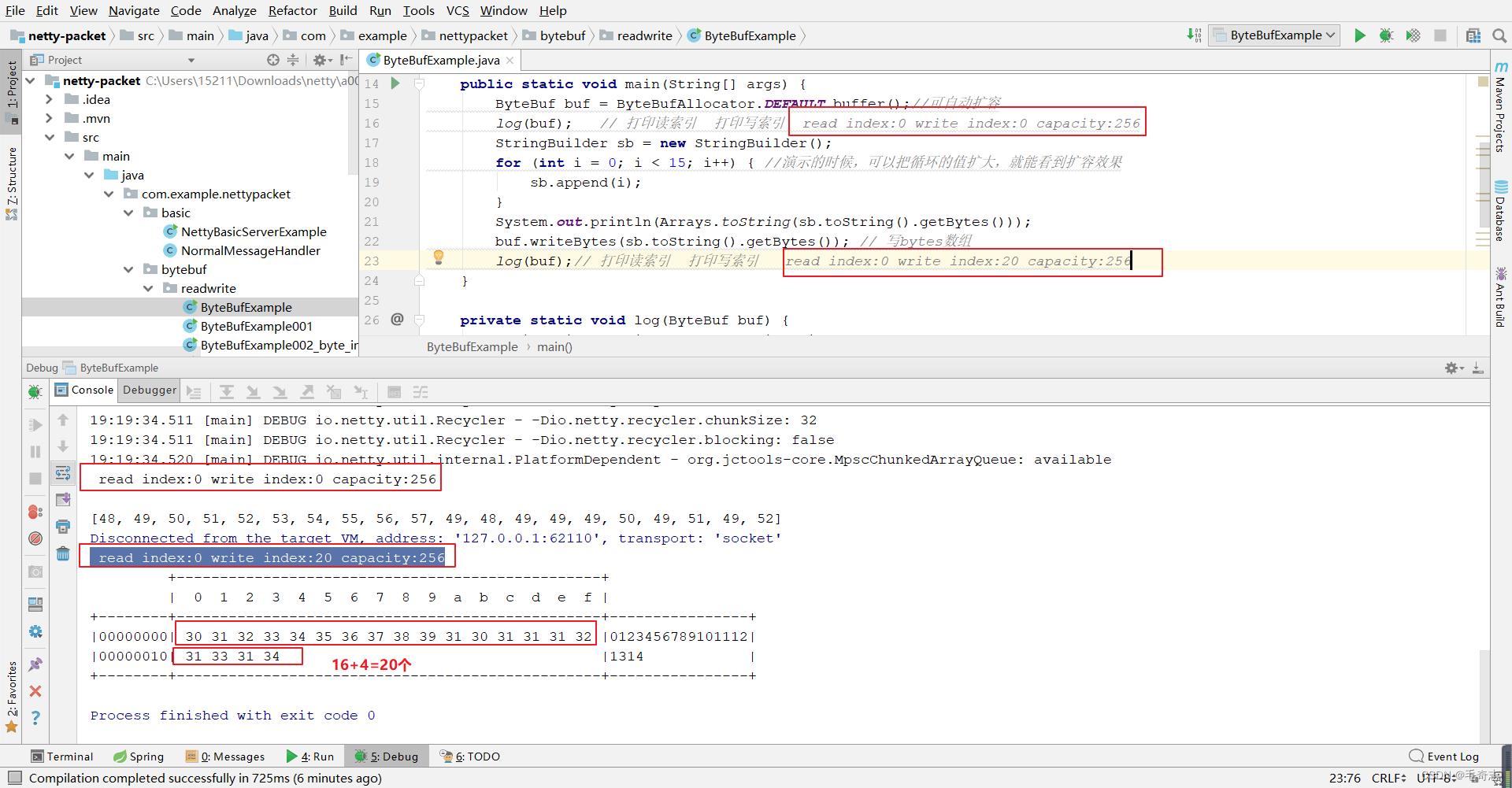
2.2.1 演示不扩容,仅仅指针移动
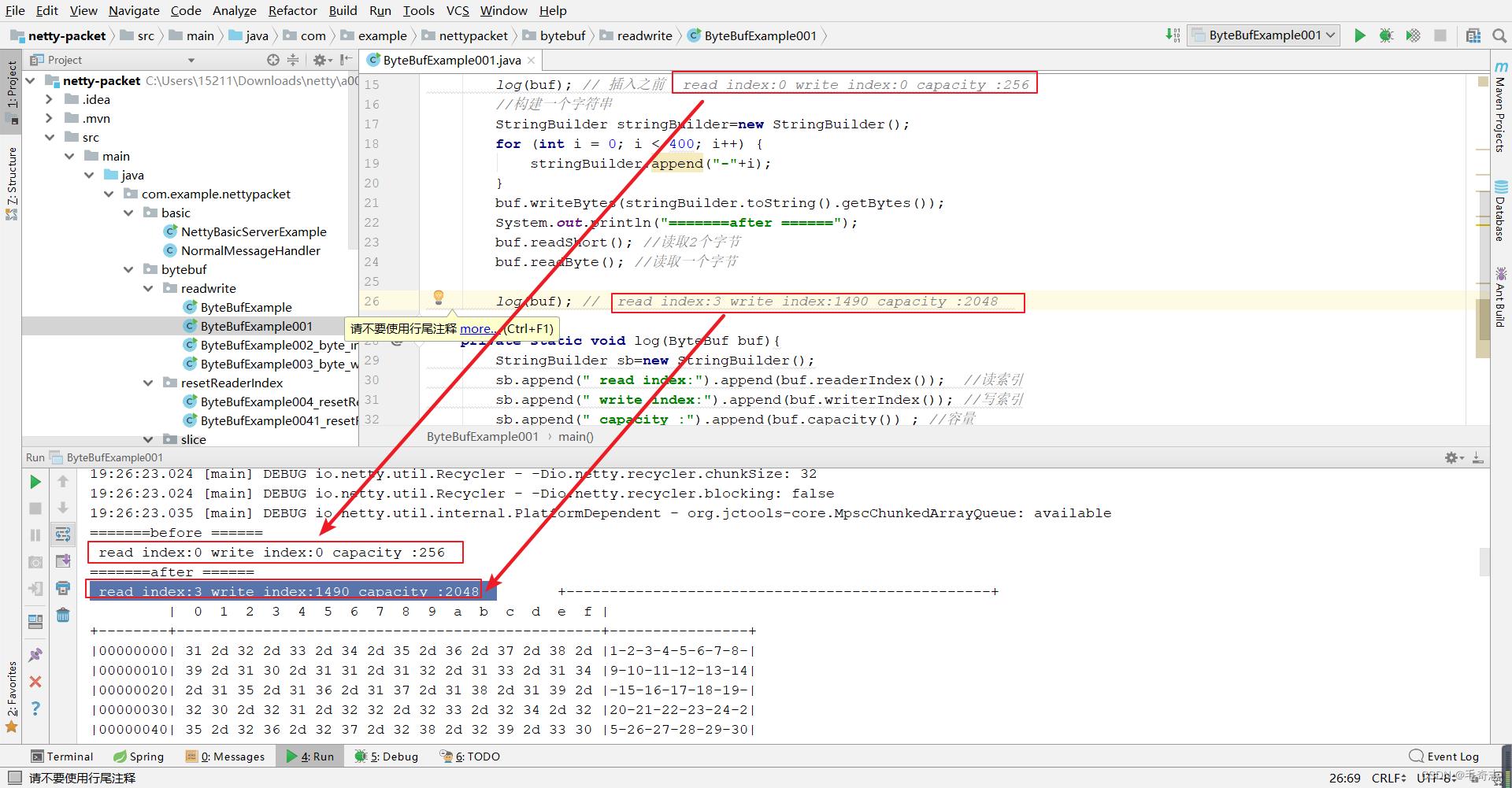
2.2.2 演示扩容
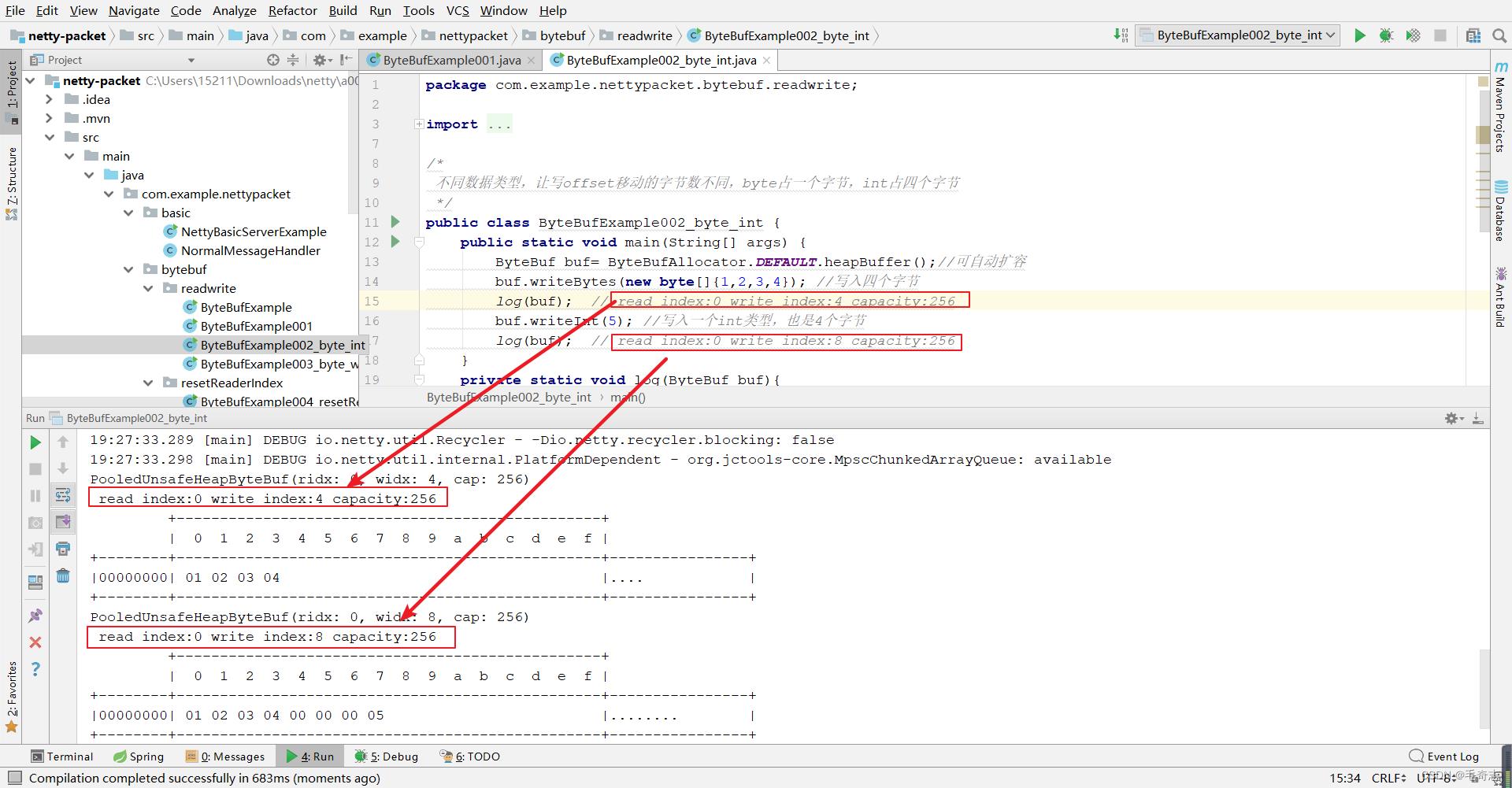
2.2.3 不同数据类型,让写offset移动的字节数不同,byte占一个字节,int占四个字节

2.2.4 先写后读:看写指针移动,看读指针移动
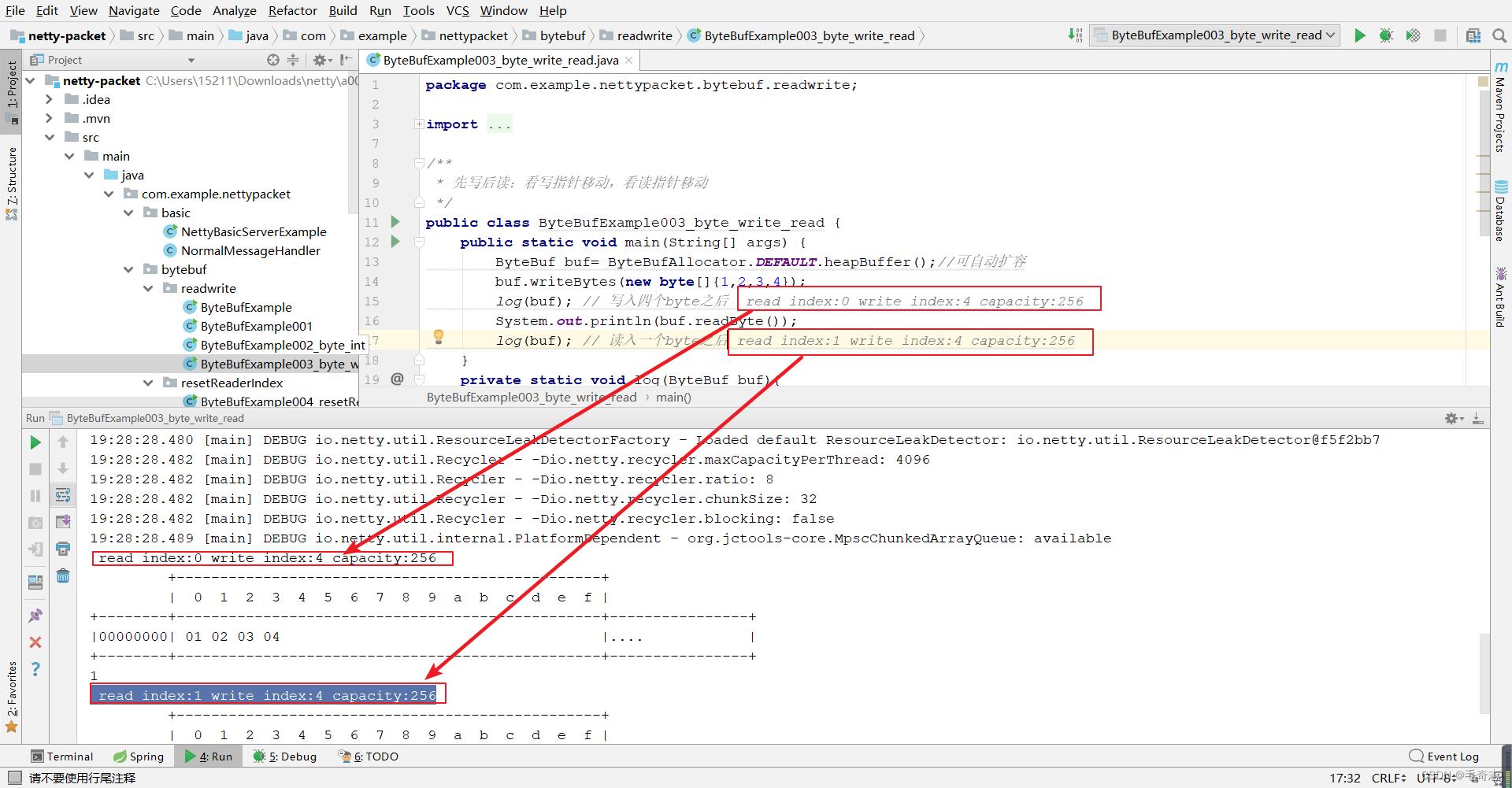

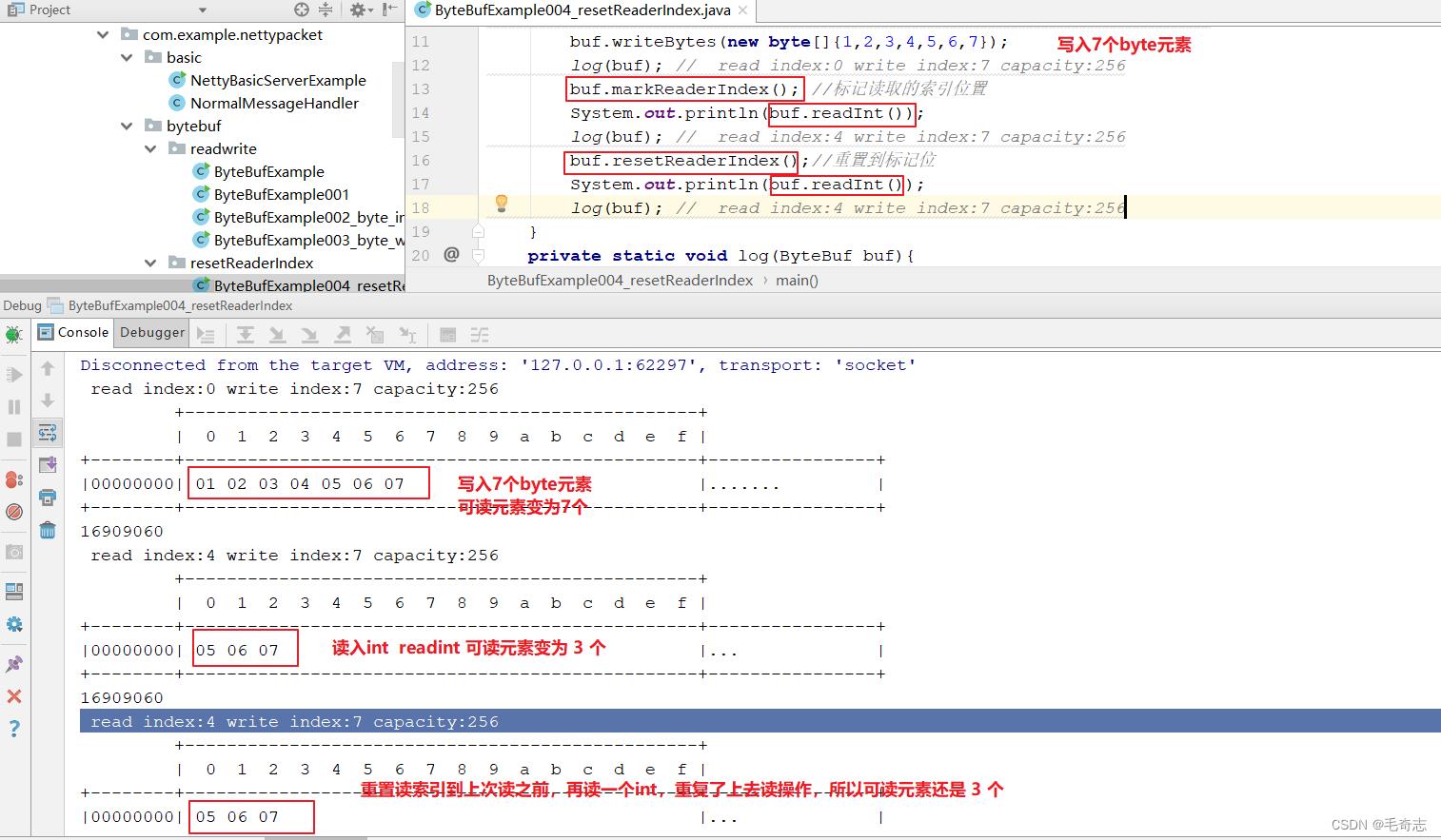
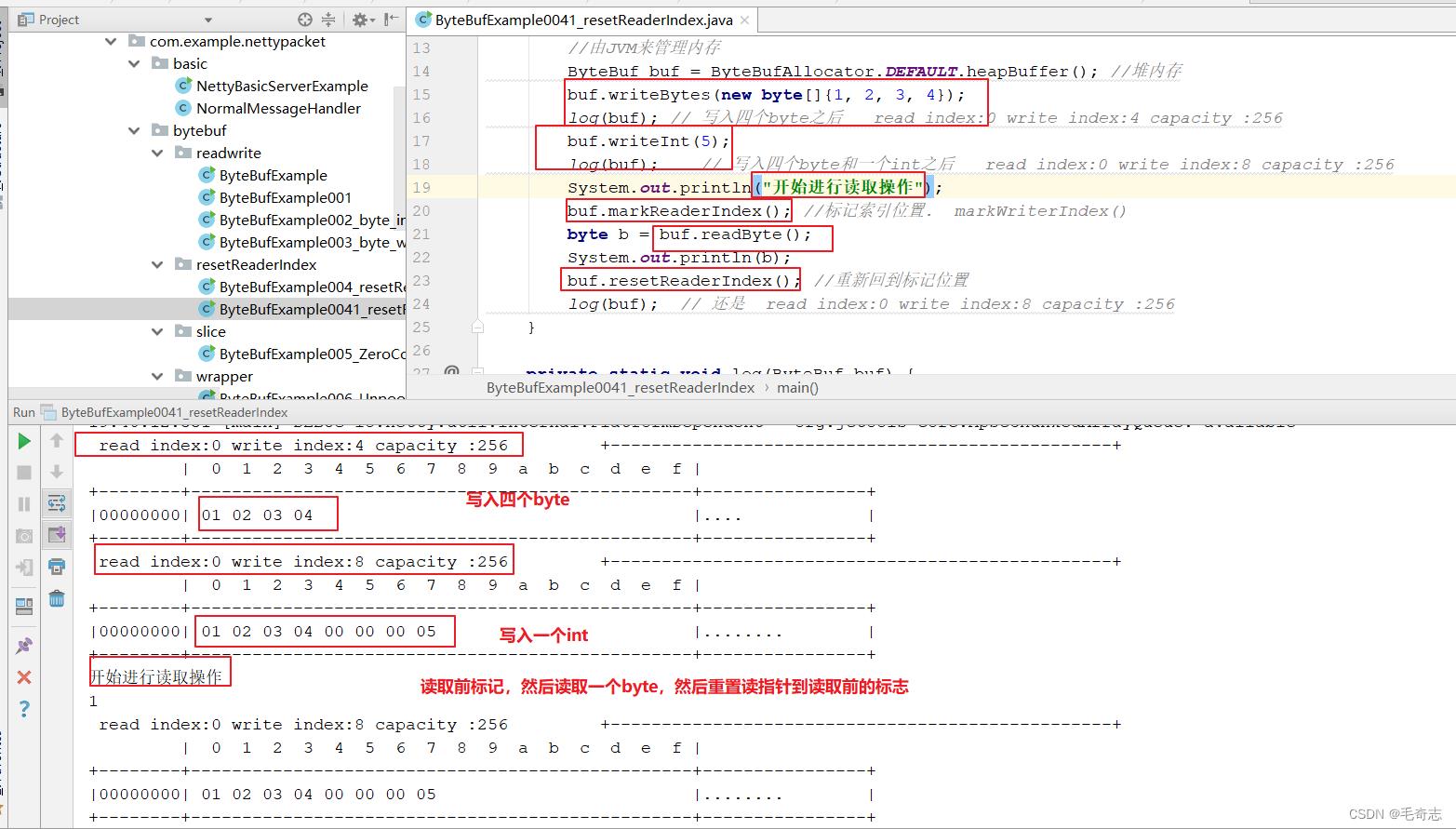
2.3 ByteBuf代码(重置读指针,多次读同一个)
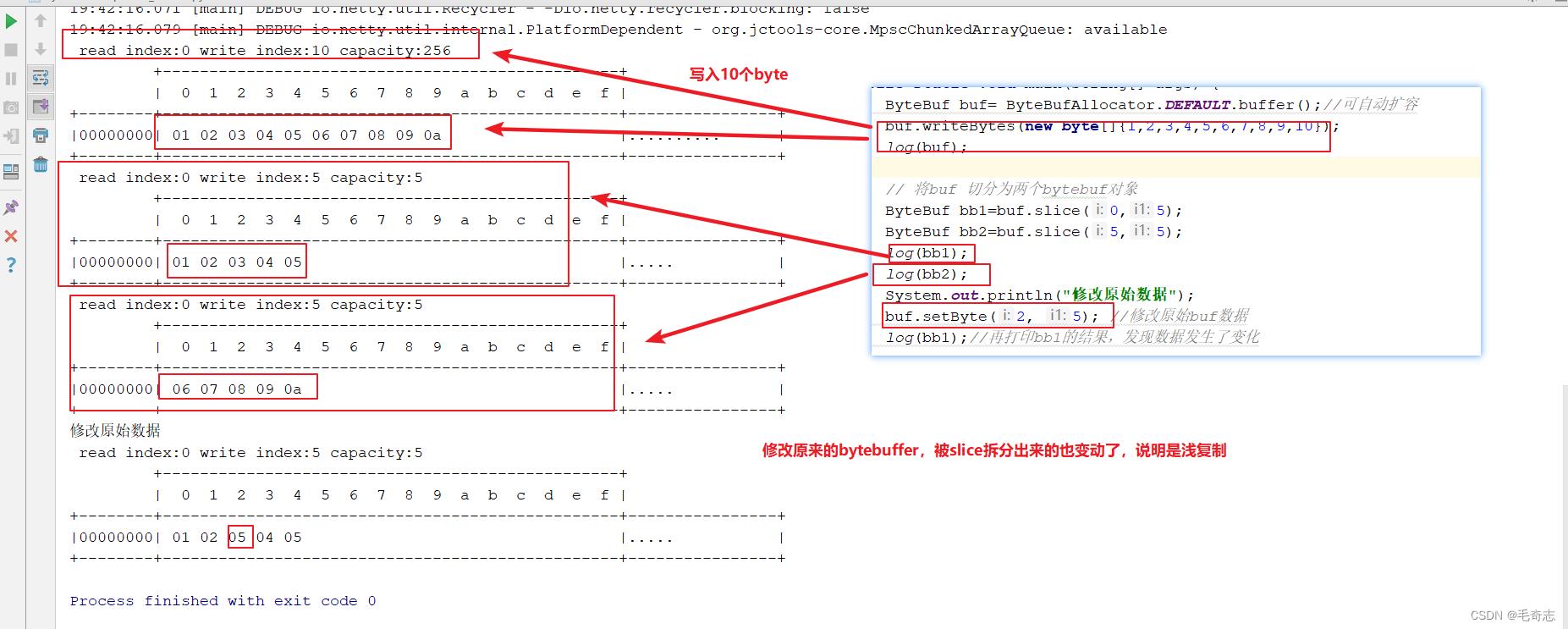
2.4 ByteBuf代码(切分slice)
2.5 ByteBuf代码(组合compositeBuffer和wappedBuffer)
2.5.1 Unpooled.compositeBuffer
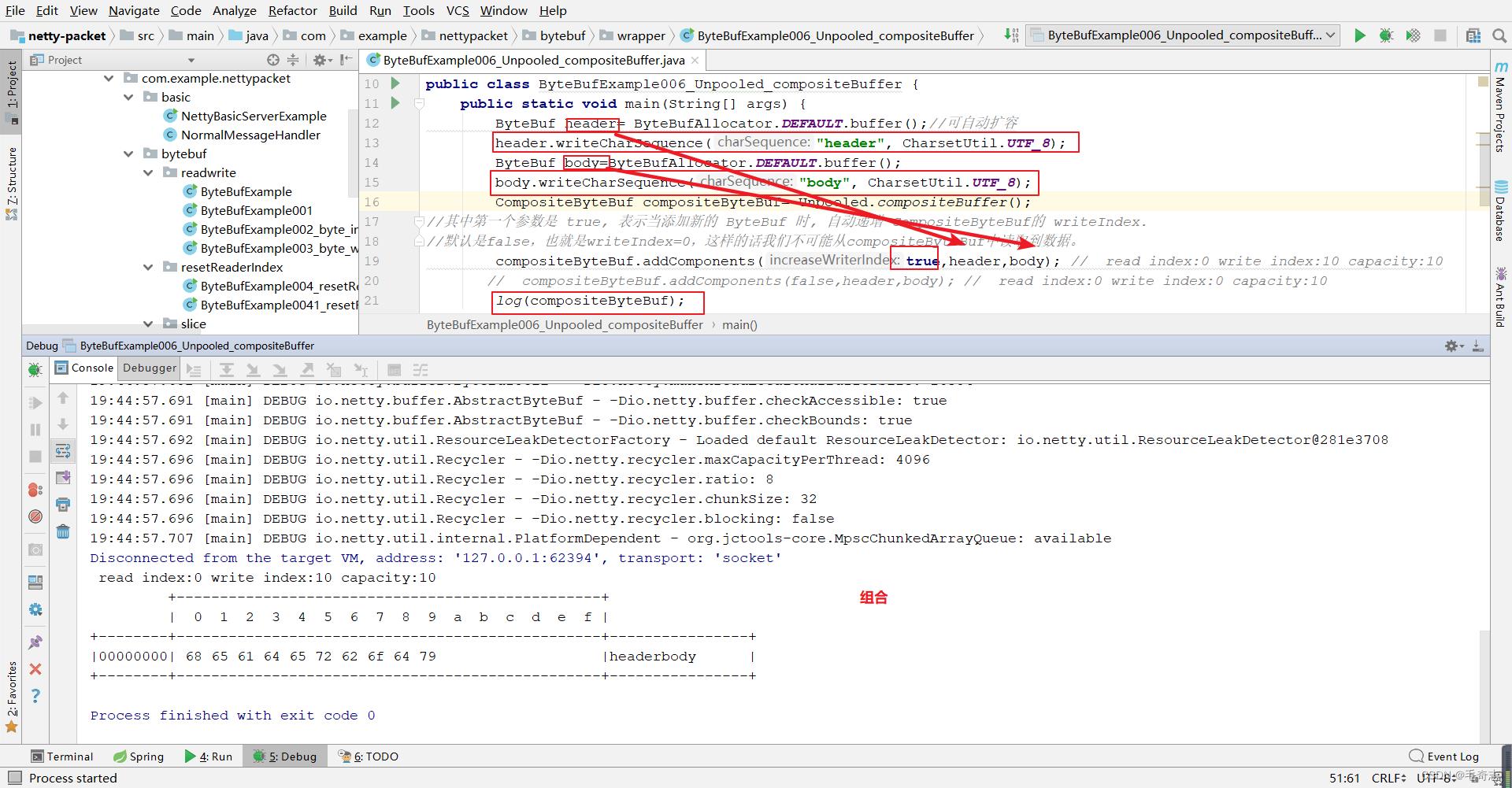
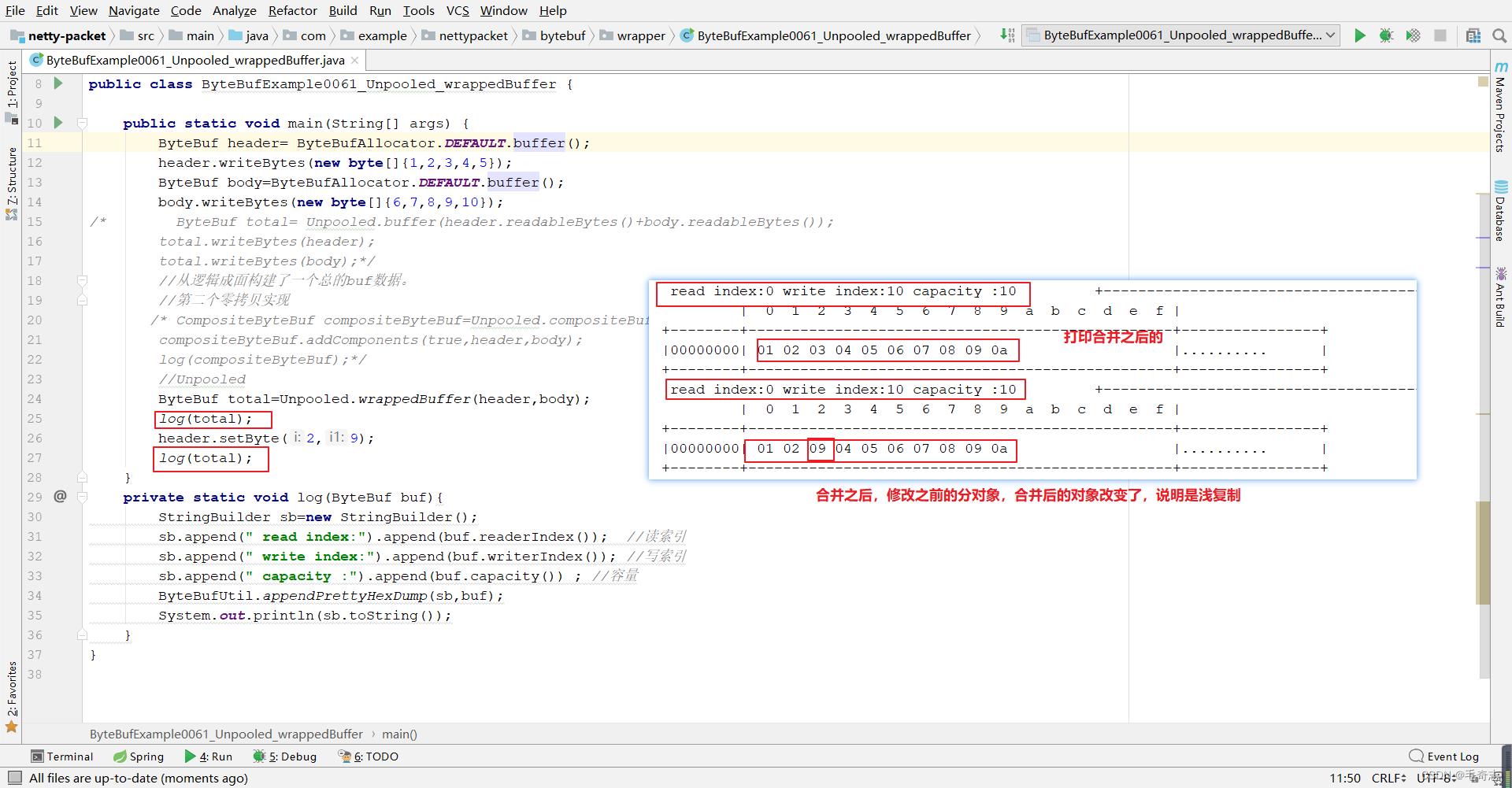
2.5.2 Unpooled.wrappedBuffer
三、网络传输中的拆包粘包问题
3.1 拆包粘包问题
TCP传输协议是基于数据流传输的,而基于流化的数据是没有界限的,当客户端向服务端发送数据时,
可能会把一个完整的数据报文拆分成多个小报文进行发送,也可能将多个报文合并成一个大报文进行发
送。
在这样的情况下,有可能会出现图3-1所示的情况。
- 服务端恰巧读到了两个完整的数据包 A 和 B,没有出现拆包/粘包问题;
- 服务端接收到 A 和 B 粘在一起的数据包,服务端需要解析出 A 和 B;
- 服务端收到完整的 A 和 B 的一部分数据包 B-1,服务端需要解析出完整的 A,并等待读取完整的 B
数据包; - 服务端接收到 A 的一部分数据包 A-1,此时需要等待接收到完整的 A 数据包;
- 数据包 A 较大,服务端需要多次才可以接收完数据包 A。
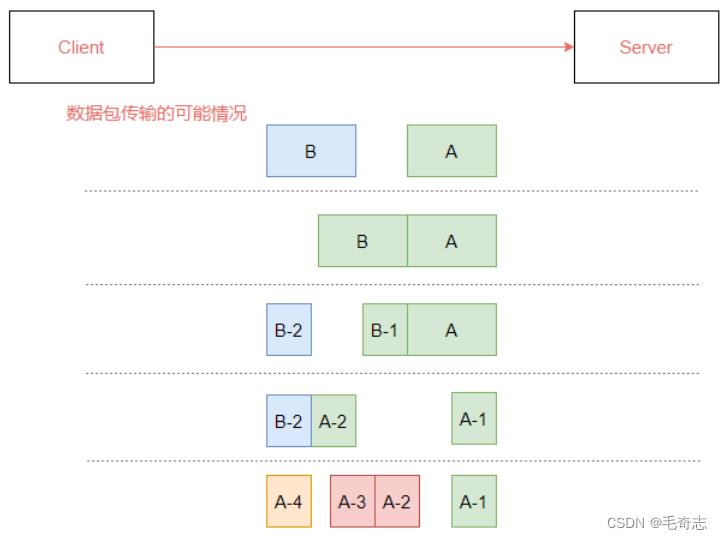
图3-1 粘包和拆包问题
由于存在拆包/粘包问题,接收方很难界定数据包的边界在哪里,所以可能会读取到不完整的数据导致
数据解析出现问题。
3.2 应用层定义通信协议
如何解决拆包和粘包问题呢?
一般我们会在应用层定义通信协议。其实思想也很简单,就是通信双方约定一个通信报文协议,服务端
收到报文之后,按照约定的协议进行解码,从而避免出现粘包和拆包问题。
其实大家把这个问题往深度思考一下就不难发现,之所以在拆包粘包之后导致收到消息端的内容解析出
现错误,是因为程序无法识别一个完整消息,也就是不知道如何把拆包之后的消息组合成一个完整消
息,以及将粘包的数据按照某个规则拆分形成多个完整消息。所以基于这个角度思考,我们只需要针对
消息做一个通信双方约定的识别规则即可。
3.2.1 消息长度固定
每个数据报文都需要一个固定的长度,当接收方累计读取到固定长度的报文后,就认为已经获得了一个
完整的消息,当发送方的数据小于固定长度时,则需要空位补齐.
如图3-2所示,假设我们固定消息长度是4,那么没有达到长度的报文,需要通过一个空位来补齐,从而
使得消息能够形成一个整体。
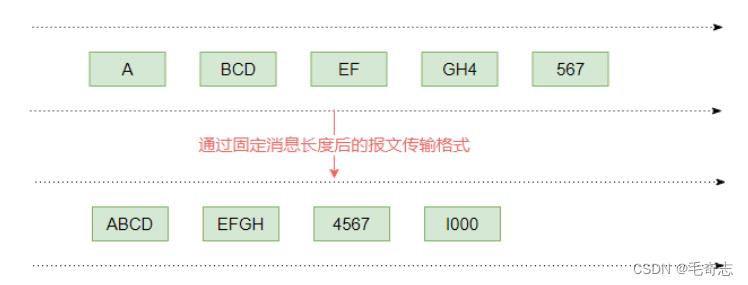
图3-2
这种方式很简单,但是缺点也很明显,对于没有固定长度的消息,不清楚如何设置长度,而且如果长度
设置过大会造成字节浪费,长度太小又会影响消息传输,所以一般情况下不会采用这种方式。
3.2.2 特定分隔符
既然没办法通过固定长度来分割消息,那能不能在消息报文中增加一个分割符呢?然后接收方根据特定
的分隔符来进行消息拆分。比如我们采用\\r\\n来进行分割,如图3-3所示。

图3-3
对于特定分隔符的使用场景中,需要注意分隔符和消息体中的字符不要存在冲突,否则会出现消息拆分
错误的问题。
3.2.3 消息长度加消息内容加分隔符
基于消息长度+消息内容+分隔符的方式进行数据通信,这个之前大家在Redis中学习过,redis的报文协
议定义如下。
*3\\r\\n$3\\r\\nSET\\r\\n$4\\r\\nname\\r\\n$3\\r\\nmic
可以发现消息报文包含三个维度
- 消息长度
- 消息分隔符
- 消息内容
这种方式在项目中是非常常见的协议,首先通过消息头中的总长度来判断当前一个完整消息所携带的参
数个数。然后在消息体中,再通过消息内容长度以及消息体作为一个组合,最后通过\\r\\n进行分割。服
务端收到这个消息后,就可以按照该规则进行解析得到一个完整的命令进行执行。
四、Netty解决网络传输中的拆包粘包问题(编码解码)
4.1 三种编码解码
为什么需要编码解码?
有了编码解码才有是真正的将netty通信搞好了,没有编码解码都不稳,可能会有拆包粘包问题
Netty中,默认帮我们提供了一些场景的编码解码器用来解决拆包粘包问题,一共三种,都是Netty自定义类
4.1.1 FixedLengthFrameDecoder解码器
固定长度解码器FixedLengthFrameDecoder的原理很简单,就是通过构造方法设置一个固定消息大小
frameLength,无论接收方一次收到多大的数据,都会严格按照frameLength进行解码。
如果累计读取的长度大小为frameLength的消息,那么解码器会认为已经获取到了一个完整的消息,如
果消息长度小于frameLength,那么该解码器会一直等待后续数据包的达到,知道获得指定长度后返
回。
使用方法如下,在3.3节中演示的代码的Server端,增加一个FixedLengthFrameDecoder,长度为10。
ServerBootstrap serverBootstrap=new ServerBootstrap();
serverBootstrap.group(bossGroup,workGroup)
.channel(NioserverSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>()
@Override
protected void initChannel(SocketChannel ch) throws Exception
ch.pipeline()
.addLast(new FixedLengthFrameDecoder(10)) //增加解码器
.addLast(new SimpleServerHandler());
);
4.1.2 DelimiterBasedFrameDecoder解码器
特殊分隔符解码器: DelimiterBasedFrameDecoder,它有以下几个属性
- delimiters,delimiters指定特殊分隔符,参数类型是ByteBuf,ByteBuf可以传递一个数组,意
味着我们可以同时指定多个分隔符,但最终会选择长度最短的分隔符进行拆分。
比如接收方收到的消息体为
hello\\nworld\\r\\n
此时指定多个分隔符 \\n 和 \\r\\n ,那么最终会选择最短的分隔符解码,得到如下数据
hello | world | - maxLength,表示报文的最大长度限制,如果超过maxLength还没检测到指定分隔符,将会抛出
TooLongFrameException。 - failFast,表示容错机制,它与maxLength配合使用。如果failFast=true,当超过maxLength后会
立刻抛出TooLongFrameException,不再进行解码。如果failFast=false,那么会等到解码出一个
完整的消息后才会抛出TooLongFrameException - stripDelimiter,它的作用是判断解码后的消息是否去除分隔符,如果stripDelimiter=false,而
制定的特定分隔符是 \\n ,那么数据解码的方式如下。
hello\\nworld\\r\\n
当stripDelimiter=false时,解码后得到
hello\\n | world\\r\\n
4.1.3 LengthFieldBasedFrameDecoder解码器
LengthFieldBasedFrameDecoder是长度域解码器,它是解决拆包粘包最常用的解码器,基本上能覆盖
大部分基于长度拆包的场景。其中开源的消息中间件RocketMQ就是使用该解码器进行解码的。
首先来说明一下该解码器的核心参数
- lengthFieldOffset,长度字段的偏移量,也就是存放长度数据的起始位置
- lengthFieldLength,长度字段锁占用的字节数
- lengthAdjustment,在一些较为复杂的协议设计中,长度域不仅仅包含消息的长度,还包含其他
数据比如版本号、数据类型、数据状态等,这个时候我们可以使用lengthAdjustment进行修正,
它的值=包体的长度值-长度域的值 - initialBytesToStrip,解码后需要跳过的初始字节数,也就是消息内容字段的起始位置
- lengthFieldEndOffset,长度字段结束的偏移量, 该属性的值=lengthFieldOffset+lengthFieldLength
上面这些参数理解起来比较难,我们通过几个案例来说明一下。
消息长度+消息内容的解码
假设存在图3-6所示的由长度和消息内容组成的数据包,其中length表示报文长度,用16进制表示,共
占用2个字节,那么该协议对应的编解码器参数设置如下。
lengthFieldOffset=0, 因为Length字段就在报文的开始位置
lengthFieldLength=2,协议设计的固定长度为2个字节
lengthAdjustment=0,Length字段质保函消息长度,不需要做修正
initialBytesToStrip=0,解码内容是Length+content,不需要跳过任何初始字节。

图3-6
截断解码结果
如果我们希望解码后的结果中只包含消息内容,其他部分不变,如图3-7所示。对应解码器参数组合如
下
lengthFieldOffset=0,因为Length字段就在报文开始位置
lengthFieldLength=2 , 协议设计的固定长度
lengthAdjustment=0, Length字段只包含消息长度,不需要做任何修正
initialBytesToStrip=2, 跳过length字段的字节长度,解码后ByteBuf只包含Content字段。

图3-7
长度字段包含消息内容
如图3-8所示,如果Length字段中包含Length字段自身的长度以及Content字段所占用的字节数,那么
Length的值为0x00d(2+11=13字节),在这种情况下解码器的参数组合如下
lengthFieldOffset=0,因为Length字段就在报文开始的位置
lengthFieldLength=2,协议设计的固定长度
lengthAdjustment=-2,长度字段为13字节,需要减2才是拆包所需要的长度。
initialBytesToStrip=0,解码后内容依然是Length+Content,不需要跳过任何初始字节
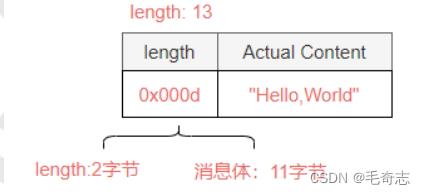
图3-8
基于长度字段偏移的解码
如图3-9所示,Length字段已经不再是报文的起始位置,Length字段的值是0x000b,表示content字段
占11个字节,那么此时解码器的参数配置如下:
lengthFieldOffset=2,需要跳过Header所占用的2个字节,才是Length的起始位置
lengthFieldLength=2,协议设计的固定长度
lengthAdjustment=0,Length字段只包含消息长度,不需要做任何修正
initialBytesToStrip=0,解码后内容依然是Length+Content,不需要跳过任何初始字节
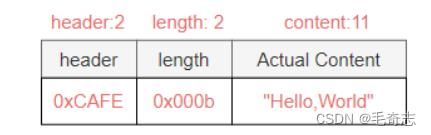
图3-9
基于长度偏移和长度修正解码
如图3-10所示,Length字段前后分别有hdr1和hdr2字段,各占据1个字节,所以需要做长度字段的便
宜,还需要做lengthAdjustment的修正,相关参数配置如下。
lengthFieldOffset=1,需要跳过hdr1所占用的1个字节,才是Length的起始位置
lengthFieldLength=2,协议设计的固定长度
lengthAdjustment=1,由于hdr2+content一共占了1+11=12字节,所以Length字段值(11字节)加
上lengthAdjustment(1)才能得到hdr2+Content的内容(12字节)
initialBytesToStrip=3,解码后跳过hdr1和length字段,共3个字节
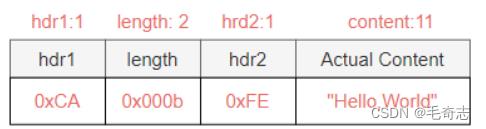
图3-10
4.2 解码器实战
4.2.1 需求
对于客户端,发送的时候确定消息的编码解码格式,如下:

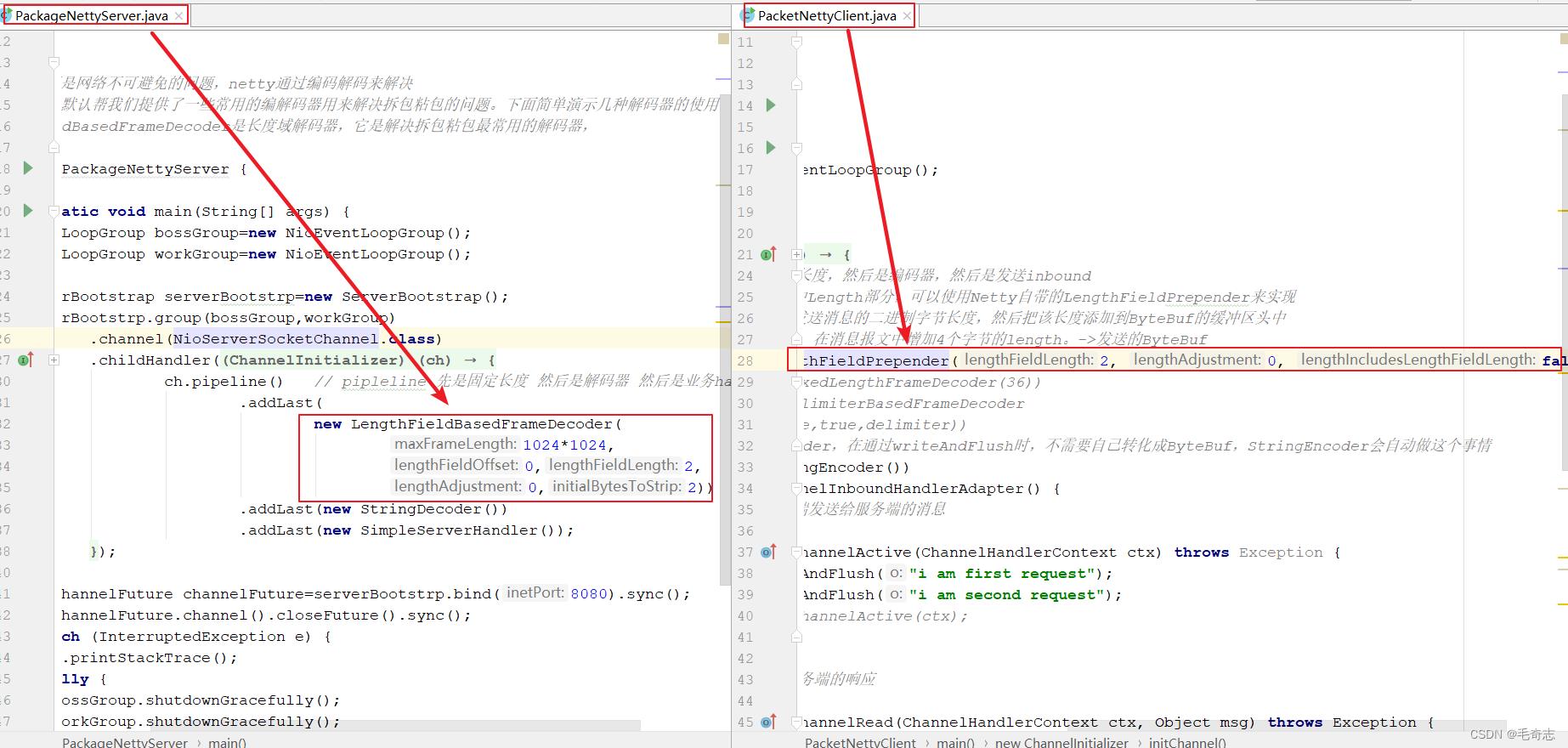
其中Length部分,可以使用Netty自带的LengthFieldPrepender来实现,它可以计算当
前发送消息的二进制字节长度,然后把该长度添加到ByteBuf的缓冲区头中,则发送两条具体消息如下:

对于Server端的代码,增加LengthFieldBasedFrameDecoder解码器,其中有两个参数的值如下
lengthFieldLength:2 , 表示length所占用的字节数为2
initialBytesToStrip: 2 , 表示解码后跳过length的2个字节,得到content内容
4.2.2 程序运行演示
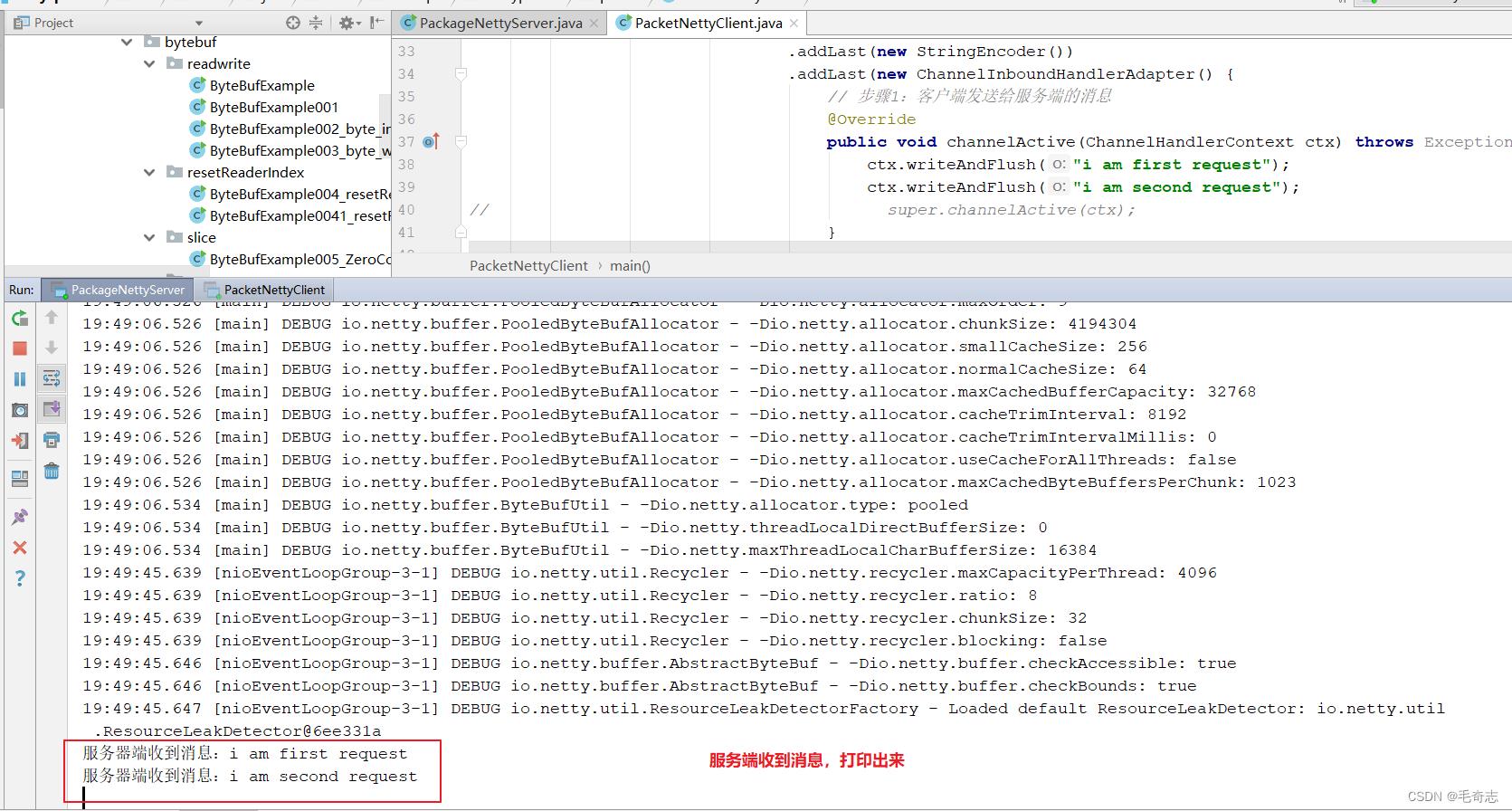
服务端启动,如下:

启动客户端,如下:
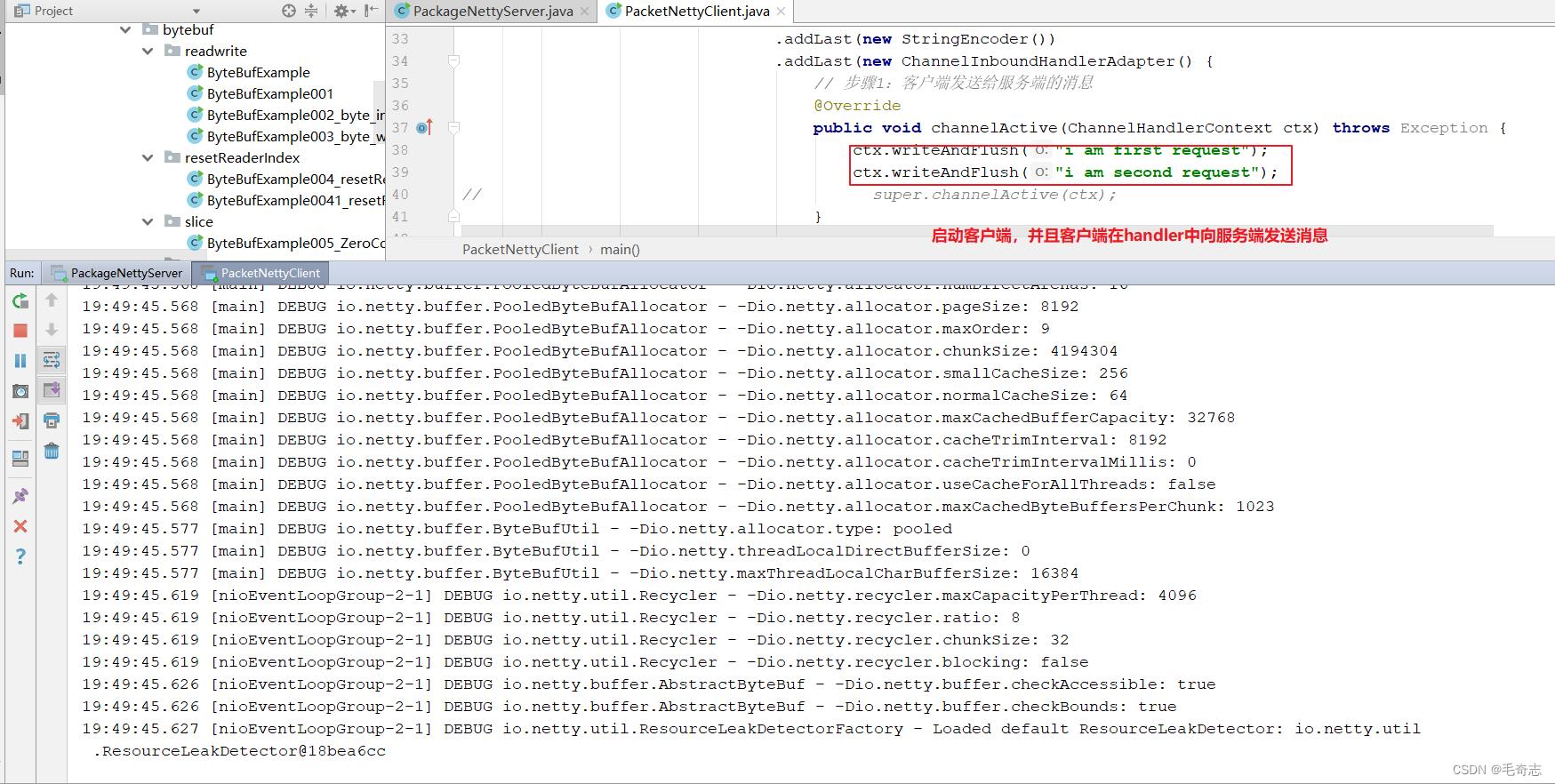
客户端启动后,向服务端发送了两条消息,然后服务端收到并打印这两条消息,如下:
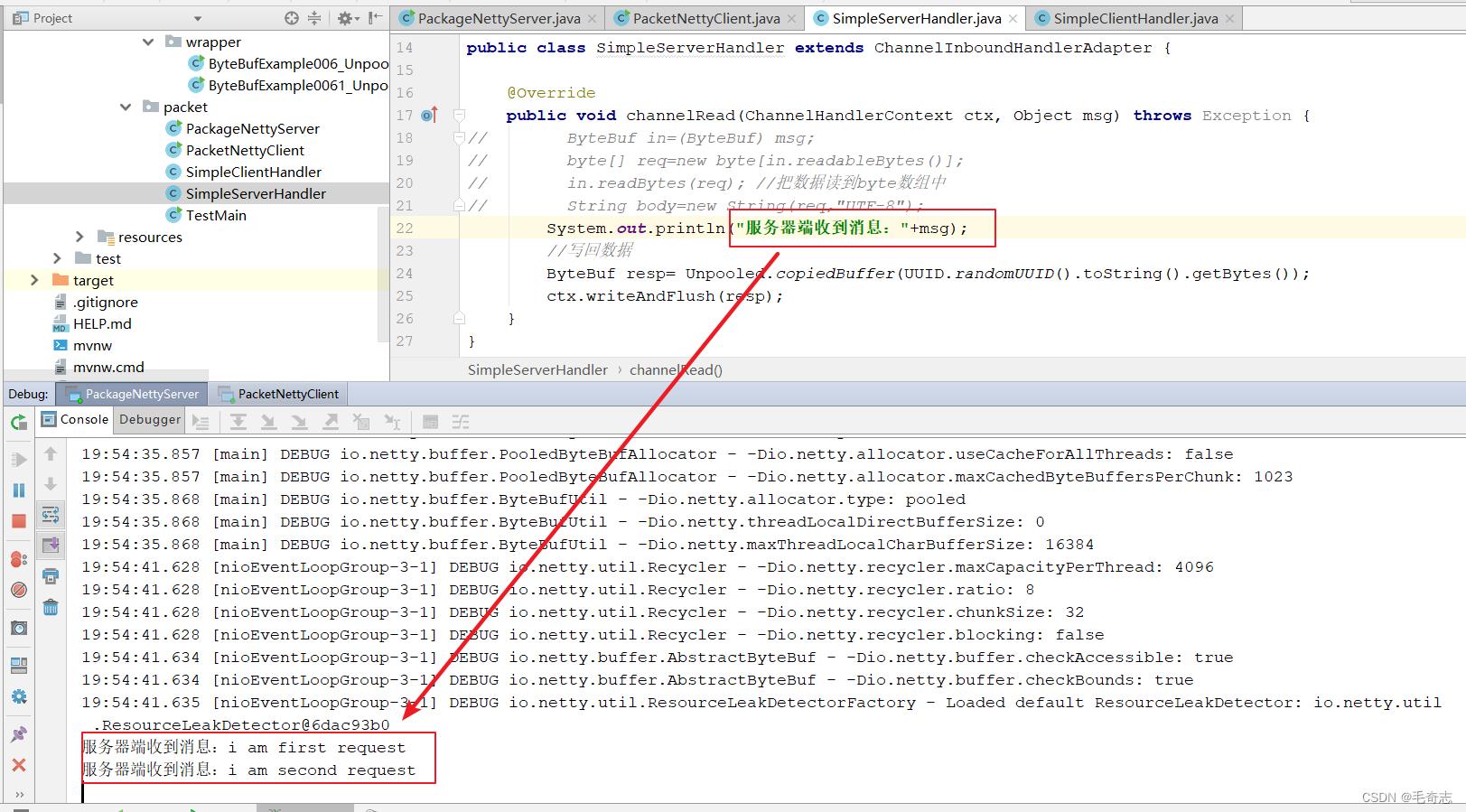
服务端向客户端发送了一条消息,如下:
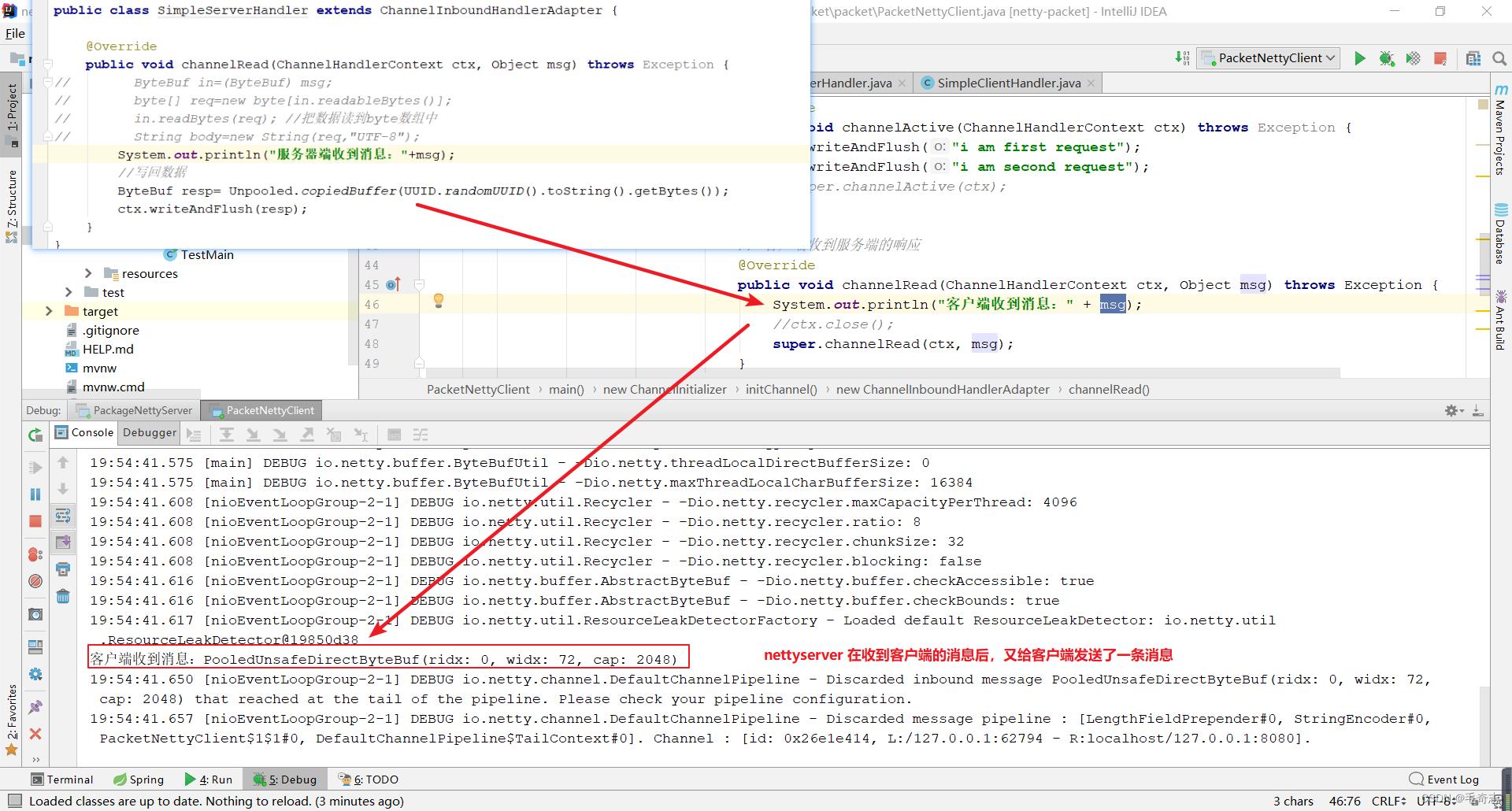
这个代码里面使用到了编码解码器,客户端和服务端要使用同一个编码解码类,如下:
源码下载:https://www.syjshare.com/res/1PGT166S
五、小结
源码下载:https://www.syjshare.com/res/1PGT166S
以上是关于Netty_03_ByteBuf和网络中拆包粘包问题及其解决的主要内容,如果未能解决你的问题,请参考以下文章