机器学习笔记 - 图像搜索的常见网络模型
Posted 坐望云起
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记 - 图像搜索的常见网络模型相关的知识,希望对你有一定的参考价值。
一、图像搜索概述
如何在这些视觉信息丰富的海量图片中快速准确地搜索到用户所需要的图片是计算机视觉领域的研究热点,也极具商业应用价值。图像搜索其应用领域十分广泛,包括电商、医学、公共安全、搜索引擎甚至军事等。
图像搜索常规分为两类,一类是基于文本的搜索,即TBIR(Text Based Image Retrieval);另一类是基于内容的搜索,即CBIR(Content Based Image Retrieval)。
TBIR出现较早,主要利用关键字对图像进行描述,然后进行关键字比对,比对成功后将结果返回给用户,其缺点是给图像标关键字需要人力介入,面对海量数据则费时费力,还面临增量的问题,且人为判断干扰因素难以估计。
CBIR则是利用计算机对图像进行分析,然后使用特征向量(可以简单理解为很多数字)来代表图像,然后对所有的图像都做特征提取并保存在特征库中,最后当要搜索某张图片时,使用同样的特征提取方法提取,再与特征库中的特征作对比,按某种相似指标进行排序并输出相似最好的几张图片,这样达到图像搜索的效果。CBIR将图像的表达以及相似的计算交给计算机处理,克服了TBIR的缺点,可以充分利用计算机的优势,极大地提高了搜索效率,适用于新时代的海量图像搜索场景。
CBIR工程中主要包括图像描述和海量相似计算与排序,图像描述即特征表达,而海量计算与排序则是另一个广阔的领域。
计算机描述图像的传统的方法有SIFT、SURF、ORB、BoW、VLAD和FV,但其缺点是这些方法都是人为设定规则,规则的好坏决定了搜索的效果。而深度学习恰好在这方面有着天然的优势,只要给出正确的样本,计算机就可以尽可能好地去学习某种规则来提取图像特征。
二、用于特征提取的神经网络
1、Siamese Network
Siamese Network的思想也十分简单和朴素,样本表示如下:图像1和图像2相似或图像1和图像3不相似,其中相似和不相似可以分别用1和-1表示。当然不同的论文其具体实现可能不同。
 https://skydance.blog.csdn.net/article/details/110326334
https://skydance.blog.csdn.net/article/details/110326334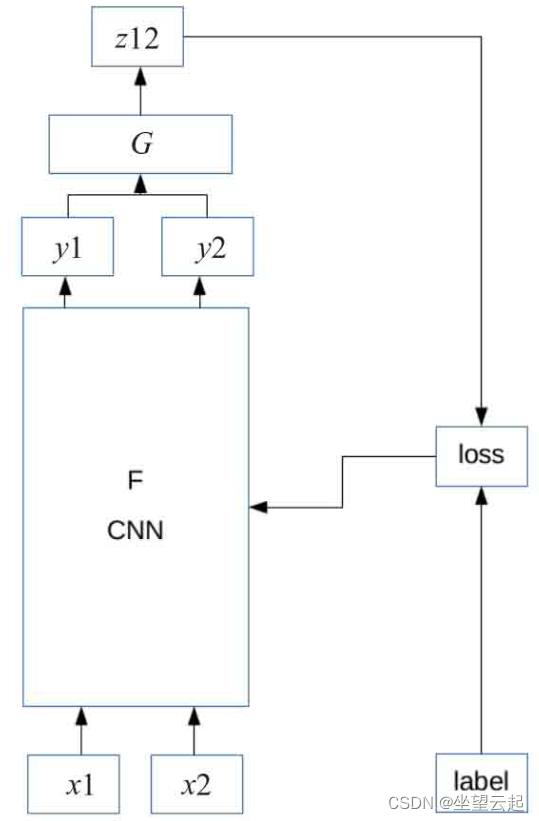
2、Triplet Network
该网络主要源于Google出品的人脸识别论文FaceNet: A Unified Embedding for Face Recognition and Clustering。传统的Siamese Network使用的是二元组数据作为输入,然后进行相似或不相似的2分类判定,而Triplet Network则提出使用三元组作为输入,损失函数则使用Triplet loss,其结构如下图所示。
输入为三元组,分别为anchor、positive和negative,anchor表示参考图像,positve表示与anchor相同或相似的图像,而negative表示与anchor不相同或不相似的图像。
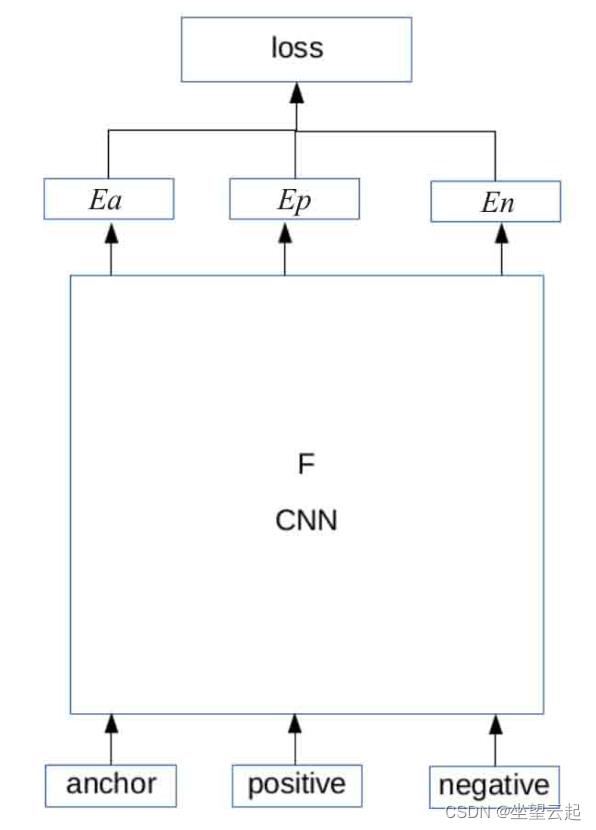
3、Margin Based Network
在2018年Chao-Yuan Wu发表了Sampling Matters in Deep Embedding Learning,这里将这篇文章所用的方法称作为Margin Based Network。
文章主要提出了两个点,一是关于采样方式的重要性,二是改变了损失函数的计算方式。
 https://github.com/chaoyuaw/incubator-MXNet/tree/master/example/gluon/embedding_learning
https://github.com/chaoyuaw/incubator-MXNet/tree/master/example/gluon/embedding_learning
三、相似度计算排序工具
1、faiss
Faiss 是一个用于高效相似性搜索和密集向量聚类的库。它包含在任意大小的向量集中搜索的算法,直到那些可能不适合 RAM 的向量。它还包含用于评估和参数调整的支持代码。Faiss 是用 C++ 编写的,带有 Python/numpy 的完整包装器。一些最有用的算法是在 GPU 上实现的。它主要由Facebook AI Research开发。
 https://github.com/facebookresearch/faiss
https://github.com/facebookresearch/faiss2、elasticsearch
诸如亚马逊、阿里云都有基于cnn提取特征向量+knn+elasticsearch的向量搜索方案。它允许您在向量空间中搜索点,并通过欧几里得距离或余弦相似度为这些点找到“最近邻”。用例包括推荐(例如,音乐应用程序中的“您可能喜欢的其他歌曲”功能)、图像识别和欺诈检测。
给定数据点的空间,k-NN 插件会查找距离查询数据点最近的数据点数 (k)。通过 k-NN 的新字段类型,您能够将 k-NN 搜索与 Elasticsearch 的各种功能(如聚合和筛选)无缝集成,以进一步提高搜索结果的精确度。Elasticsearch 的分布式架构使 k-NN 插件能够摄取和处理大型数据集,支持增量更新,从而为您提供具有快速推理功能的高性能相似度搜索引擎。
以上是关于机器学习笔记 - 图像搜索的常见网络模型的主要内容,如果未能解决你的问题,请参考以下文章