证明与计算: 有限状态机(Finite State Machine)
Posted 幻灰龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了证明与计算: 有限状态机(Finite State Machine)相关的知识,希望对你有一定的参考价值。

什么是有限状态机(Finite State Machine)?
什么是确定性有限状态机(deterministic finite automaton, DFA )?
什么是非确定性有限状态机(nondeterministic finite automaton, NDFA, NFA)?
[1] wiki-en: Finite state machine
[2] wiki-zh-cn: Finite state machine
[3] brilliant: finite-state-machines
上面的这3个地址里的介绍已经写的很好了。第3个地址的是一个简约的FSM介绍,比较实用,而且基本上能让你区分清楚DFA和NFA。但是本文还是尝试比较清楚的梳理清楚它们之间的来龙去脉。
0x02 Deterministic finite automaton, DFA
简单说,DFA包含的是5个重要的部分:
- \\(Q\\) = 一个有限状态集合
- \\(\\Sigma\\) = 一个有限的非空输入字符集
- \\(\\delta\\) = 一系列的变换函数
- \\(q_0\\) = 开始状态
- \\(F\\) = 接受状态集合
在有限状态机的图里面,有几个约定:
- 一个圆圈表示非接受状态
- 两个圆圈表示接受状态
- 箭头表示状态转移
- 箭头上的字符表示输入字符
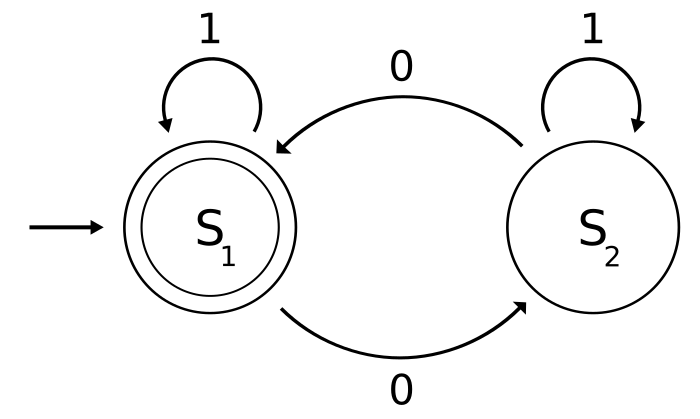
例如下面两个DFA的图示:
DFA图1([3]):https://upload.wikimedia.org/wikipedia/commons/thumb/9/9d/DFAexample.svg/700px-DFAexample.svg.png
{kind=link}
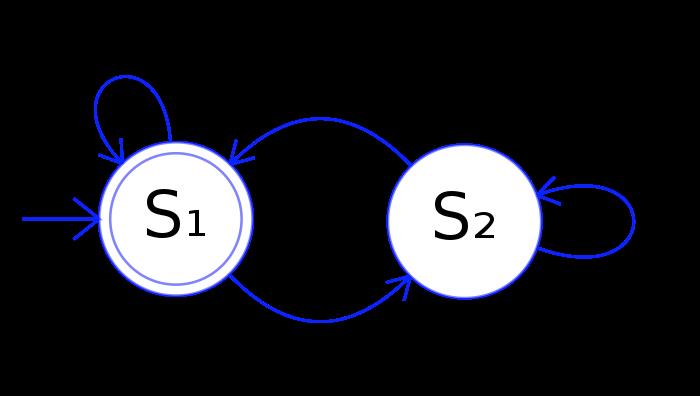
DFA图2:https://swtch.com/~rsc/regexp/fig0.png
{kind=link}

DFA的特征是,每个状态,输入一个新字符,都有一个唯一的输出状态。
例如,DFA图1和图2的每个\\(S_i\\)在遇到0或者1时输出的状态时唯一的。
在DFA图1中,可以详细看下买个参数是什么([3]):
- Q = \\(\\s_1, s_2\\\\)
- \\(\\Sigma\\) = 0,1
- \\(q_0\\) = \\(s_1\\)
- F = \\(s_1\\)
特别的,我们看下转换函数集合,实际上可以用一个表格来表示([3]):
| 当前状态 | 输入状态 | 输出状态 |
|---|---|---|
| s1 | 1 | s1 |
| s1 | 0 | s2 |
| s2 | 1 | s2 |
| s2 | 0 | s1 |
0x03 Nondeterministic finite automaton, NDFA, NFA
那么,NFA和DFA的区别是什么呢?下面两个NFA的图示:
NFA图1:https://ds055uzetaobb.cloudfront.net/brioche/uploads/zgipUhyx8b-ndfa2.png?width=2400
{kind=link}
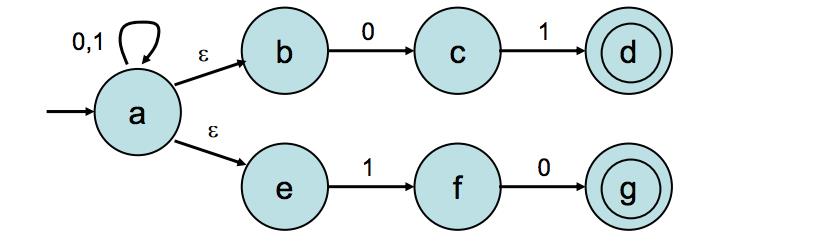
NFA图2:https://swtch.com/~rsc/regexp/fig2.png
{kind=link}

NFA的特征是,和DFA相比:
- 每个状态,输入一个新字符,可能有多个不同的输出状态。
- 每个状态,可以接受空输入字符,用符号\\(\\epsilon\\)表示。
例如NFA图2里,s2接受输入字符b之后,可能是s1,也可能是s3。而在NFA图1里,初始字符可以接受空输入\\(\\epsilon\\),不消耗任何字符,转换为b或者e状态,并且还是个多路分支。
0x04 Regular Expression
[4] wiki-en: Regex Expression
[5] wiki-zh-cn: Regex Expression
[6] Regular Expression Matching Can Be Simple And Fast
正则表达式和DFA/NFA的关系是什么?我们先看看正则表达式本身。[4]和[5]的wiki里列出了很多正则的表达式符号,但是不如文章[6]简洁实用。
首先,任何通配符都必须有逃逸字符。正则表达式的逃逸字符是\\,例如\\+不表示通配符,而表示的是匹配+字符。
其次,实际上根据[6],正则表达式最重要的通配符就是三个:
e*表示0个或多个ee+表示1个或多个ee?表示0个或1个e
最后,根据[6],正则表达式最基础的组合方式也就是三个:
e1e2表示e1和e2的拼接e1|e2表示e1或者e2e1(e2e3)表示分组,括号里的优先级更高,和括号在四则运算表达式里的作用一样
这里特别提一下,如果上述里的e替换成了一个集合,那么e*会变成e1,e2*,这个叫做集合e1,e2的克林闭包(Kleene closure, Kleene operator, Kleene star),下面的两个wiki介绍了它们的定义:
[7] wiki-en: Kleene closure
[8] wiki-zh-cn: 克林闭包
它的定义是递归方式的,令目标集合是V:
- $V_0=\\epsilon $
- \\(V_1\\) = V
- \\(V_i+1 = wv : w ∈ V_i and v ∈ V for each i > 0.\\)
从而,V的克林闭包如下:
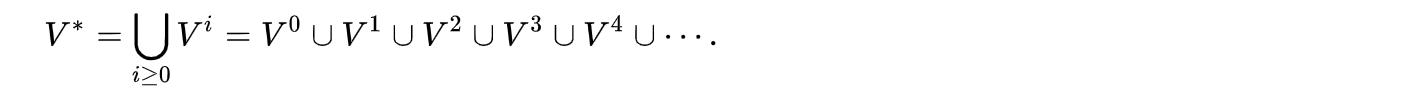
一个克林闭包的例子如下:
"ab", "c"* = ε, "ab", "c", "abab", "abc", "cab", "cc", "ababab", "ababc", "abcab", "abcc", "cabab", "cabc", "ccab", "ccc", ....
从而,也可以定义克林正闭包(Kleene Plus):

一个克林正闭包的例子如下:
"a", "b", "c"+ = "a", "b", "c", "aa", "ab", "ac", "ba", "bb", "bc", "ca", "cb", "cc", "aaa", "aab", ....
0x05 Regular Expression 2 NFA
根据文章[4],正则表达式的三个重要的通配符,可以通过如下的方式转换为对应的NFA,这里用[s]表示非接受状态,用[[s]] 表示接受状态:
表达式 e:
[s]--e-->表达式 e1e2:
[s0]--e1-->[s1]--e2-->表达式 e1|e2:
--e1-->
/
[s]
\\
--e2-->表达式 e?,可以看到它等价于e|\\(\\epsilon\\)
--e-->
/
[s]
\\
------>表达式 e*,上半部分本来有输出箭头,但是既然它能立刻绕回去上一个状态(转N圈),就可以直接从下半部分的箭头出去
--e--
/ |
[s] <---
\\
------>表达式 e+,我们可以看成是它的等价形式ee*,那么就是
--e--
/ |
--e-->[s] <---
\\
------>但是我们可以简化下,把分支上半部分合并到左侧,因为左侧也是表示输入e然后到状态[s]:
----
↓ |
--e-->[s]
\\
------>有了这些基本的转换规则,就可以把正则表达式转换为NFA,这几个图最好自己动手画一下,不动手可能还是没有实际的感觉。
0x06 NFA 2 DFA
由于NFA的定义是DFA的超集,一个DFA可以直接看做是一个NFA。
那么,NFA是否可以转化为DFA呢?
当然可以,很显然,对比DFA和NFA的区别,有两点要做到:
- 需要消灭所有的空输入 \\(\\epsilon\\)
- 需要合并那些同一个字符的多路分支为一个分支,为了这点,转换后的DFA的每个状态是由NFA的状态构成的集合,例如a,b作为一个整体构成转换后的DFA的一个状态
[9] nfa-2-dfa example
我们先看一个实际的例子[9],直接手工体验下这个转换过程:
DFA图3:https://www.cs.odu.edu/~toida/nerzic/390teched/regular/fa/figures/nfa-dfa1.jpg
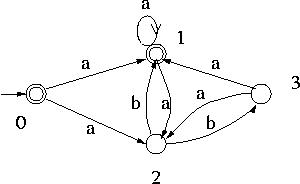{kind=link}
目标是找到NFA对应DFA的5个部分,有2个是现成的,剩下3个:
- 状态集合Q
- x 输入字符集合E,这个保持不变
- x 初始状态q0,对应DFA的初始化状态为 q0
- 转移函数集合\\(\\delta\\)
- 输出状态集合F
第1轮,考虑DFA里的Q第1个元素
- 初始化Q=
- NFA的初始状态是0,我们把
0这个集合,作为一个元素,加入Q,从而:- Q= 0
- NFA里,下一个输入a后可以是状态1,也可以是状态2,也就是\\(\\delta\\)(0, a) = 1, 2。因此,对应的DFA里:
- Q= 0,1,2
- \\(\\delta\\)(0, a) = 1, 2
- NFA里,\\(\\delta\\)(0, b) = ,因此空集被加入到DFA的Q里:
- Q = ,0,1,2
- \\(\\delta\\)(0, a) = 1, 2, \\(\\delta\\)(0, b) =
第2轮,考虑DFA里Q的第2个元素1,2
- 此时1,2在DFA的Q里,考虑从1,2这个元素出发会到哪里
- NFA里,\\(\\delta\\)(1, a) = 1, 2, \\(\\delta\\)(2, a) = ,从而
- DFA里新增 \\(\\delta\\)(1,2, a) = 1,2, Q 则保持不动:
- Q = ,0,1,2
- \\(\\delta\\)(0, a) = 1, 2, \\(\\delta\\)(0, b) = , \\(\\delta\\)(1,2, a) = 1,2
- DFA里新增 \\(\\delta\\)(1,2, a) = 1,2, Q 则保持不动:
- NFA里\\(\\delta\\)(1, b) = , \\(\\delta\\)(2, b) = 1,3,从而
- DFA里新增 \\(\\delta\\)(1,2, b) = 1,3, Q 新增1,3:
- Q = ,0,1,2,1,3
- \\(\\delta\\)(0, a) = 1, 2, \\(\\delta\\)(0, b) = , \\(\\delta\\)(1,2, a) = 1,2, \\(\\delta\\)(1,2, b) = 1,3
- DFA里新增 \\(\\delta\\)(1,2, b) = 1,3, Q 新增1,3:
第3轮,考虑DFA里Q的新增元素1,3
- NFA里,\\(\\delta\\)(1, a) = 1, 2, \\(\\delta\\)(3, a) = 1, 2
- DFA新增\\(\\delta\\)(1,3, a) = 1, 2, Q 则保持不动
- Q = ,0,1,2,1,3
- \\(\\delta\\)(0, a) = 1, 2, \\(\\delta\\)(0, b) = , \\(\\delta\\)(1,2, a) = 1,2, \\(\\delta\\)(1,2, b) = 1,3, \\(\\delta\\)(1,3, a) = 1, 2
- DFA新增\\(\\delta\\)(1,3, a) = 1, 2, Q 则保持不动
- NFA里,\\(\\delta\\)(1, b) = , \\(\\delta\\)(3, b) =
- DFA新增\\(\\delta\\)(1,3, b) = , Q 则保持不动
- Q = ,0,1,2,1,3
- \\(\\delta\\)(0, a) = 1, 2, \\(\\delta\\)(0, b) = , \\(\\delta\\)(1,2, a) = 1,2, \\(\\delta\\)(1,2, b) = 1,3, \\(\\delta\\)(1,3, a) = 1, 2, \\(\\delta\\)(1,3, b) =
- DFA新增\\(\\delta\\)(1,3, b) = , Q 则保持不动
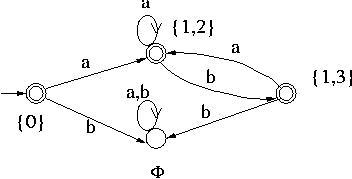
- 没有新的状态,结束,由于0和1是NFA的接受状态,Q里面有含有0和1的状态是DFA的接受状态,也就是F= 0, 1,2, 1,3
至此,整个转换结束,对应的DFA:
- 状态集合:Q = ,0,1,2,1,3
- 转移函数:\\(\\delta\\)(0, a) = 1, 2, \\(\\delta\\)(0, b) = , \\(\\delta\\)(1,2, a) = 1,2, \\(\\delta\\)(1,2, b) = 1,3, \\(\\delta\\)(1,3, a) = 1, 2, \\(\\delta\\)(1,3, b) =
- 输出状态集合:F= 0, 1,2, 1,3
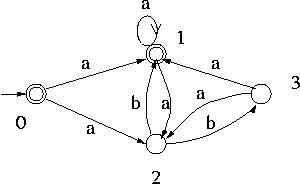
则转换后的DFA如图:https://www.cs.odu.edu/~toida/nerzic/390teched/regular/fa/figures/dfa1.jpg
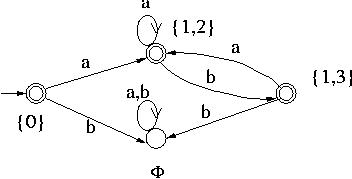{kind=link}
有了这个手工操作的经验,上面这个例子里面,反复做一个动作:
- 得到一个新的DFA元素,例如1,2
- 考虑它接受一个输入,例如b,分别
- 考虑状态1接受b的转移状态集合,
- 考虑状态2接受b的转移状态集合, 1,3
- 因此,1,2接受b后,转换到1,3
太啰嗦了,我们做一些简化:
- 把转换后的DFA的元素标记为大写字母,例如T=1,2, U=1,3;
- 把上面这个操作过程写成一个函数:move(T,b)
- 那么上面这个过程就是:
move(T,b)=U - 这个过程就是表示找到所有T里的元素在NFA里经过输入b后能直接到达的状态的集合U
进一步,如果在NFA里,某个s状态经过空转换\\(\\epsilon\\)能到达的集合,我们标记为\\(\\epsilon\\)-closure(s)。
例如:
-----> [1]
/
[0]
\\
------> [2]那么,\\(\\epsilon\\)-closure(0) = 1,2
进一步
---->[3]
/
-----> [1]----->[4]
/
[0]
\\
------> [2]那么,\\(\\epsilon\\)-closure(0) = 1,2,3,4
这么看来,\\(\\epsilon\\)闭包是不是很形象。
有了\\(\\epsilon\\)-closure(s),我们当然可以对DFA里的T的每个元素做\\(\\epsilon\\)-closure,于是就可以定义:
- \\(\\epsilon\\)-closure(T) = T里所有元素ti的\\(\\epsilon\\)-closure(ti)的并集。
那么,我们上面手工操作move(T,b),之后,如果对应的NFA里也有\\(\\epsilon\\),我们要达到最开始的转换NFA到DFA的两个目标之一:
- 需要消灭所有的空输入 \\(\\epsilon\\)
我们就需要对上面讨论过的这个过程做升级:
- 找到所有T里的元素在NFA里经过输入b后能直接到达的状态的集合U
也就是去掉直接两个字,升级成:
- 找到所有T里的元素在NFA里经过输入b后能到达的状态的集合U
实际上,通过上面的讨论,经过烧脑,是可以理解到这个过程就是一个复合动作:
- \\(\\epsilon\\)-closure(move(T,b))
于是,再经过烧脑,我们可以得到NFA转换成DFA的算法:
算法: 子集构造法(subset construction):
- T0=\\(\\epsilon\\)-closure(q0); DFAState=, DFAState[T0]=false; DFATransitioin=;
- 其中q0是NFA的初始状态
- 赋值为false,表示它还没有被标记
- 开始循环
- 取出Q里的一个没有标记的元素,例如T。DFAState[T]=true立刻标记它,表示处理过了。
- 如果都标记了,退出循环
- 对输入的每个字符a
- 计算U=\\(\\epsilon\\)-closure(move(T,a))
- 如果U不在DFAState里面,就加入:DFAState[U]=false;
- 加入转换函数:DFATransitioin[T,a]=U
- 继续循环
- 取出Q里的一个没有标记的元素,例如T。DFAState[T]=true立刻标记它,表示处理过了。
从而,正则表达式可以转成NFA,再进一步转成DFA,实际上NFA转成DFA最糟的情况是,原来NFA需要n个状态,DFA需要\\(2^n\\)个状态。
注:这是因为,由n个状态构成的集合s1,s2,...,它的所有子集组成的集合叫做幂集,幂集里的每个集合,都可能是DFA的状态,而幂集里的集合的个数是\\(2^n\\)(可以计算下)。
为了加深印象,可以在这个在线工具里输入正则表达式直接看到对应的NFA和DFA的结果:
[10] Regex => NFA => DFA - CyberZHG
0x07 Use State Machines
由于从Regex Expression到NFA到DFA,里面有一个地方是输入是用字符串的字符表示。会让人以为只有正则表达式需要DFA和NFA。
而实际上,我们可以在任何需要使用状态转换的地方用NFA和DFA。很自然的,需要考虑这些概念:
- 有哪些状态?应该定义哪些状态?例如一个操作最简单的有Init/UnInit两种状态。
- 输入是什么?程序里的输入是「行为」,可能是用户点击,也可能是某个事件到达,在这些场景,你需要抽象这些输入,可以看成不同的「字符」,也可以根据它们需要转换的状态,看成是同一个「字符」。
- 输出是什么?当然是另外一个状态了。
- 跟正则表达式什么关系?
- 看法1: 没有关系,我们只关心状态转换是否是在允许的操作内,如果不是就是程序出现某种「未定义」行为,直接报错。这是消除Bugly的良方。
- 看法2: 一个由某些输入字符构成的字符串,表示了由UI操作、事件构成的操作序列,如果匹配,则表示这些操作集合是合法的,否则就是中间某个步骤是「未定义的」。
如何更好的写一个DFA构成的状态机代码?这里有一个Unity3D框架里的状态机的开发解释,很清晰的构架:
[11] Unity3D里的FSM(Finite State Machine)有限状态机
下面我们看一个例子,在实践上,如何设计状态机的转换。
首先,经过考虑,设计一组状态:
- S=INIT,STARTING, PLAYING, STOP, ERROR
其次,考虑每个状态可以到达哪些状态:
- INIT -> [ STARTING ], 初始状态可以到达开始中
- STARTING -> [PLAYING, ERROR],开始中状态可以到达游玩中或者出错
- PLAYING -> [STOP, ERROR], 游玩中可以到达停止或出错
- ERROR -> [STOP],出错状态,做好出错处理后停止
- STOP -> [INIT],结束状态应该可以重置成初始化状态
因此,考虑初始和停止状态:
- 初始状态:INIT
- 停止状态集合:[STOP]
那么,可以逆向计算每个状态允许的前置状态集合(enableStates):
- INIT: [STOP]
- STARTING: [INIT]
- PLAYING: [STARTING]
- STOP: [PLAYING, ERROR]
- ERROR: [STARTING, PLAYING]
练习题1:在这个状态转换中, Q, \\(\\Sigma\\), \\(\\delta\\), \\(q_0\\), F 分别是什么?练习题2:它是DFA,还是NFA?练习题3:如果是NFA,它有空输入转换么?练习题4:如果是NFA,试下转成DFA?练习题5:画出NFA/DFA的转换图。
实践中,我们会按需写如下的状态转换函数,代码只是示例:
function EnterState(toState, onPreEnter, onAction, onPostEnter)
const fromState = this.state;
if(enableStates[fromState].includes(toState))
onPreEnter(fromState, toState);
this.state = toState;
onPreEnter(fromState, toState);
return true;
else
// log
return false;
实际上,如果考虑输入字符后,可以做一个更完备的版本:
function enableToState(fromState, context)
// 把context转换成抽象的字符
const c = convertToAplha(fromState, context);
// 根据fromState和c找到对应的可能输出集合
const toState = DFATransitioin(fromState, c);
return toState;
function EnterState(toState, onPreEnter, onPostEnter)
const fromState = this.state;
if(enableToState(fromState, context).includes(toState))
onPreEnter(fromState, toState);
this.state = toState;
onPostEnter(fromState, toState);
return true;
else
// log
return false;
0x08 Another Case
再来一个,考虑一个游戏点播系统,经过一些思考后设计如下的状态,理论上任何两个状态之间都可以有转换关系,实践上我们要设计出「合理」的转换,保证程序的「正确」,程序可以在任何两个状态之间转换,但那不是我们需要的,我们需要在考虑合理性,设计出预期的允许转换的关系。
- IDLE: 空闲状态
- NEW_SESSION: 用户扫码付费后,获得一个时间片,开始一个会话
- GAME_STARTING: 启动一个游戏
- GAME_PLAYING: 启动成功,游玩中
- NO_GAME: 没有启动游戏
- GAME_RESTARTING: 游戏重启中
- WAIT_RENEWAL: 时间到,给一个90秒的等待续费时间
- TIME_OVER: 没有续费,时间消耗完毕
这些状态,如何设计出严密的转换关系呢?简单粗暴地,我们可以使用「表格」这种看似原始的方式:
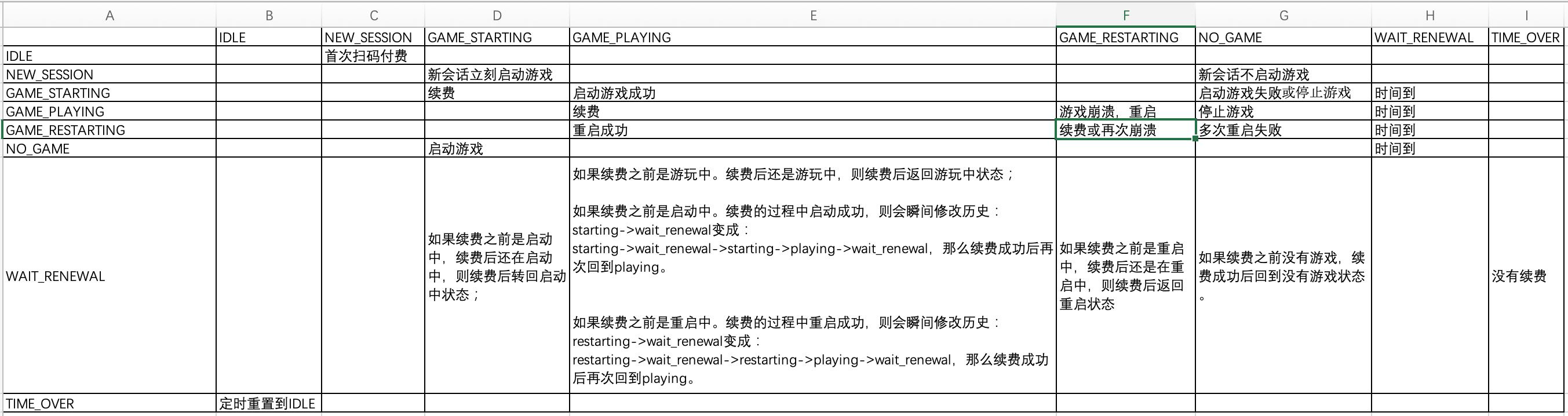
表格,是的,程序里的很多复杂状态转换,如果你愿意画表格的话,是可以非常清楚地画出它们之间的正确关系。实际上,表格背后的思想是向量的叉乘,例如一组状态V1和另一组状态V2,它们共同决定另结果状态V3,那么所有的状态组合就是V1 叉乘 V2。也就是笛卡尔乘积。多维度的情况也是这样的,只是通常我们写程序的时候不会以这种「向量」思维去考虑。但是如果你是在一个「向量化」思维为一等公民的编程语言里写程序的话,就会习惯这种思维,例如R语言等。但即使我们不以向量化来写代码,也可以在分析时使用「向量化分析」。
从数学上来说,上述游戏状态的自叉乘,得到的是一个「稀疏矩阵」。也就是有很多单元格是0的矩阵。表示这两种状态之间不会有任何「转换函数」使得它们之间发生转换。那么我们的状态转换里就可以对这类转换严格给予拒绝,并报错。程序如果出现问题,我们只要分析这些错误日志,就很容易定位出问题的原因。
注意,上述表格里,一个状态S1能否转换到另一个状态S2,并不仅仅取决于S0和S1之间是否有一条路径,还取决于S1之前的状态是什么?例如对于WAIT_RENEAL来说,它要符合如下的「转换模式」才允许:
// S1之前是S0,加上输入字符是p(例如p代表续费,paid),才允许从S1再次回到S0
S0->S1->S0;但是,仅仅只有这个模式还不能解决所有问题。在上面的表格里,从GAME_STARTING, GAME_RESTARTING进入到WAIT_RENEWAL之后,如果WAIT_RENEWAL的过程中,字符p(paid)先到,那么就直接使用上述的S0->S1->S0模式,否则如果出现游戏启动成功先完成,假设用字符g(game live)代表这个行为,那么由于g比p先到,这个时候我们如果不能忽略字符g,:
- 本来期待收到字符g(game),使得转换
S0---g--->S3发生 - 但是由于时间耗完先发生,用字符z(zero time)表示,先发生了:
S0---z--->S1 - 此时,g(game live)来到,但是由于我们期待S1应该有一个90秒的时间片去获得一个字符p(paid),此时应该瞬间做一个跳转:
[S0]---z--->[S1]---g--->[S3]---(e)--->[S1]---p---->[S3]注意到:这里面,S3到S1这个步骤,并没有任何的输入字符,所以这是一个空输入字符。实际上,NEW_SESSION这里,根据是否有首发游戏,会选择进入GAME_STARTING或者NO_GAME状态。这里也并没有一个合适的输入字符,启动游戏用的是s(start game),没启动游戏就是空输入(e),直接进入NO_GAME状态。完整的状态转换图如下:

考虑状态转换图的特征:
- WAIT_RENEWAL含有空输入e的转换路径
- WAIT_RENEWAL在输入p之后,可以到达多个分支(GAME_STATING, GAME_PLAYING, GAME_RESTARTING)
因此,这是一个NFA确定无疑。完整的5个要素如下:
- Q: IDLE, NEW_SESSION, GAME_STARTING, GAME_PLAYING, GAME_RESTATING, NO_GAME, WAIT_RENEWAL, TIME_OVER
- \\(\\Sigma\\): p, g, s, f,c, z1, z2, z3,e
- \\(\\delta\\): 见上面的表格
- \\(q_0\\): IDLE
- \\(F\\): IDLE
0x09 AutoMata Theory
实际上,具体实现时,使用了一个stack来保存状态转换的历史,并且在处理WAIT_RENEAL的过程中,状态转换使用了改stack里前面转换过的状态做决策。如果发生start->wait_renewal,在wait_renwal的状态下,start完成,具体实现利用stack做了简化,直接修改历史为start->playing->wait_renewal。因此已经不是严格意义的「有限状态机」,因为有限状态机有一个要求是每次只使用当前状态和tansition函数来做状态转移,如果再利用了历史状态stack,并进行了push/pop,那么它算是一个「下推自动机」,也就是PushDown State Machine,简单说就是给有限状态机配上了「内存」的能力。有限状态机和下推自动机都属于自动机的一种,wiki上有具体的说明AutoMata Theory。下面这个图说明了不同能力自动机的包含关系,这只是大类划分,具体细分此处不再展开。
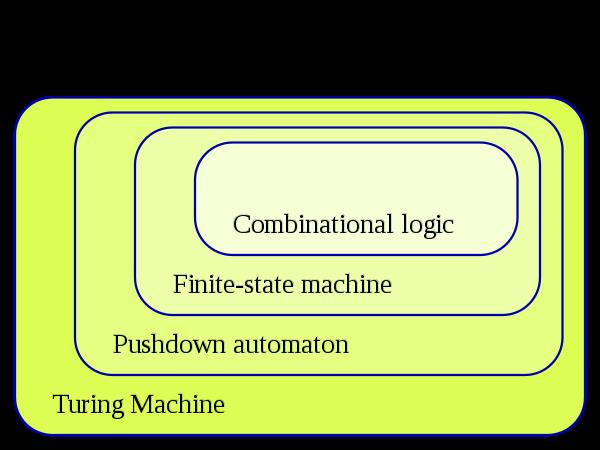
下面这个图展示了这些自动机之间更精细的能力包含关系:

简单解释下:
- Finite State Machine(FSM):DFA和NFA的能力是等价的。
- FSM可以处理的语言是正则表达式,也就是所谓的正则语言(Regular laguage)
- PushDown Automata(PDA)就是在FSM的基础上增加了一个能够记住历史的Stack。因此PDA的能力比FSM强。
- PDA也分确定性和非确定性,取决于同样的输入字符,是否有分支输出,以及是否能用空输入。
- 非确定性PDA能力比确定性PDA强。
- PDA可以处理的是上下文无关语言(Context-free Language)
- 上面我们说的PDA只能使用一个Stack,严格描述是:PDA with one push down store
- 这个时候,它有一个缺点:如果从stack里pop一个状态出来,我们就「忘记了」这个pop掉的状态。
- 弥补这个缺点的方式是:再增加一个stack,这样被pop出来的状态可以push到另外一个stack里。需要查询这些信息的时候,可以在两个stack之间来回倒腾。
- 增加了外挂后,严格的名字就是:PDA with two push down store
- PDA with two push down store也分确定性和非确定性的,这倆的能力就一样了。
- 实际上, PDA with two push down store的能力就已经等价于 Turing Machine 了。
- 当然,Turing Machine也有确定性和非确定性之分,再往下就是各种天马行空的变种了,不必理会。
- Turing Machine就是假设纸带是无限长,任意可读写。
- PDA with two push down store和Turing Machine可以处理的语言就是递归可枚举语言: Recursively enumerable language
- 在此之间,比PDA能力更强的,比图灵机弱一点的是一个叫做线性有界自动机: Linear bounded Automata, LBA
- 简单说,LBA就是在图灵机的基础上,做了一些限制:
- Turing Machine的纸带是可任意读写,但是LBA每次只能读写输入字符的一个线性函数的有限部分数据。
- LBA可以处理的语言是上下文敏感语言:Context-sensitive language
于是,这样我们就能看得懂上面这个不同自动机之间的包含关系到底是什么了。上面每一种自动机都对应一种形式语言,这些形式语言之间也就自然而然有了下面的包含关系:
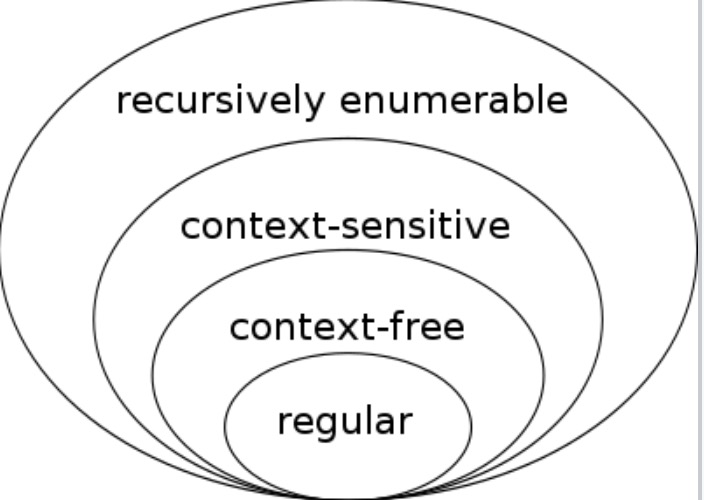
这四种语言都属于乔姆斯基形式语言分层(Chomsky hierarchy)里的一类,分别是:
- Type-0:递归可枚举语言( Recursively enumerable language )
- Type-1:上下文敏感语言( Context-sensitive language )
- Type-2: 上下文无关语言( Context-free language )
- Type-3: 正规语言( Regular language)
乔姆斯基在1950年发明了乔姆斯基形式文法描述它们。再下去就属于编译原理相关的部分,不再展开。
0x0A Why Developers Never Use State Machines
根据实际需要,可以做的简单,也可以做的细致,不同层度上保证程序的正确性。但是实际上,状态机在网络协议的开发中比较常见,例如经典的TCP状态转换图:
[13] rfc-793:TRANSMISSION CONTROL PROTOCOL
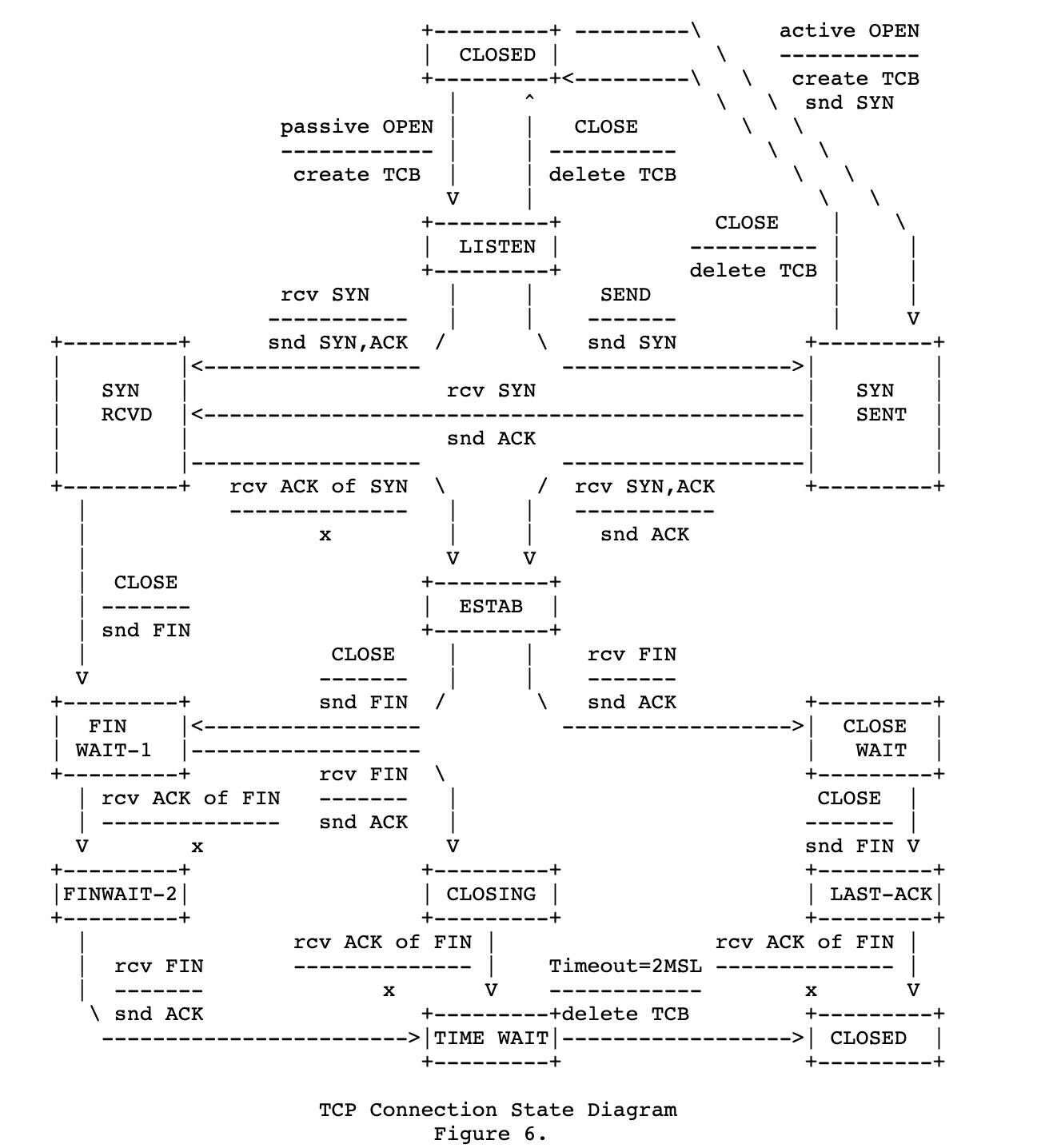
有限状态机很有用,可是为什么大部分程序员平常写程序没用到它呢?
[12] Why Developers Never Use State Machines
We seem to shy away from state machines due to misunderstanding of their complexity and/or an inability to quantify the benefits. But, there is less complexity than you would think and more benefits than you would expect as long you don’t try to retrofit a state machine after the fact. So next time you have an object that even hints at having a “status” field, just chuck a state machine in there, you’ll be glad you did.
这篇文章分析了可能的原因:「高估了它的复杂,以及低估了它的好处」,我觉的很有道理,特别是我发现在UI项目里使用严格的状态机管理状态后,程序的问题更容易被trace,也更能保证程序正确之后,我发现状态机确实好用。
0x0B How using good theory leads to good programs?
而在这篇介绍Thompson NFA的文章里,作者的两段话很有意思:
[6] Regular Expression Matching Can Be Simple And Fast
Historically, regular expressions are one of computer science's shining examples of how using good theory leads to good programs. They were originally developed by theorists as a simple computational model, but Ken Thompson introduced them to programmers in his implementation of the text editor QED for CTSS. Dennis Ritchie followed suit in his own implementation of QED, for GE-TSS. Thompson and Ritchie would go on to create Unix, and they brought regular expressions with them. By the late 1970s, regular expressions were a key feature of the Unix landscape, in tools such as ed, sed, grep, egrep, awk, and lex.
Today, regular expressions have also become a shining example of how ignoring good theory leads to bad programs. The regular expression implementations used by today's popular tools are significantly slower than the ones used in many of those thirty-year-old Unix tools.
这值得我们思考,程序是什么?
--end--
以上是关于证明与计算: 有限状态机(Finite State Machine)的主要内容,如果未能解决你的问题,请参考以下文章