2022华为全球校园AI算法精英赛:季军方案!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2022华为全球校园AI算法精英赛:季军方案!相关的知识,希望对你有一定的参考价值。
Datawhale干货
作者:鲤鱼,西安交通大学,人工智能学院
笔者鲤鱼,是西安交通大学人工智能学院的一名研究生,在2022华为全球校园AI算法精英赛的赛道二取得了季军的成绩。
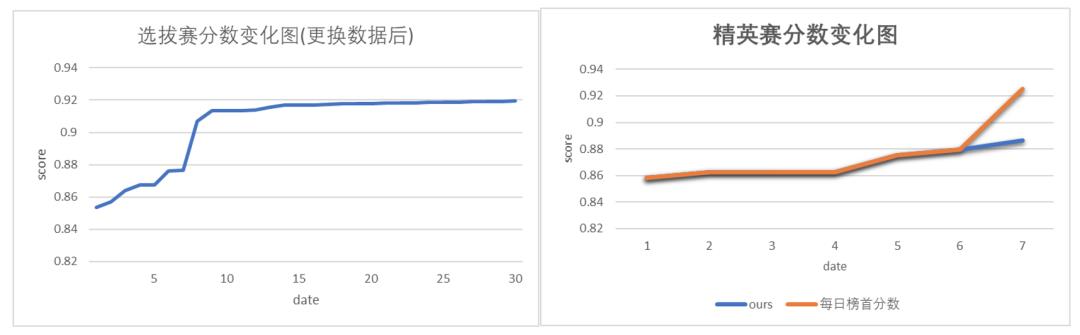
初赛阶段一直名列A榜的榜首,复赛前几天也一直处于A榜榜首。虽然最后一天翻车了,但每次切换测试数据集都能取得稳定的优势,模型的泛化性能应该是比较强的,只是可惜最后输在了一些后处理的trick上,现提供一些思路,仅供参考。
如需作者完整PPT,可在Datawhale后台回复关键词 季军 下载。
赛题理解
本次华为全球校园AI算法精英赛的赛道二——车道渲染数据质量检测赛题。地图数据渲染生成过程中,部分数据会存在诸如缺边少角,异形道路等缺陷,本赛题旨在探索可靠的高精度质检模型。
赛事信息:华为全球校园AI算法精英赛-CV赛题。
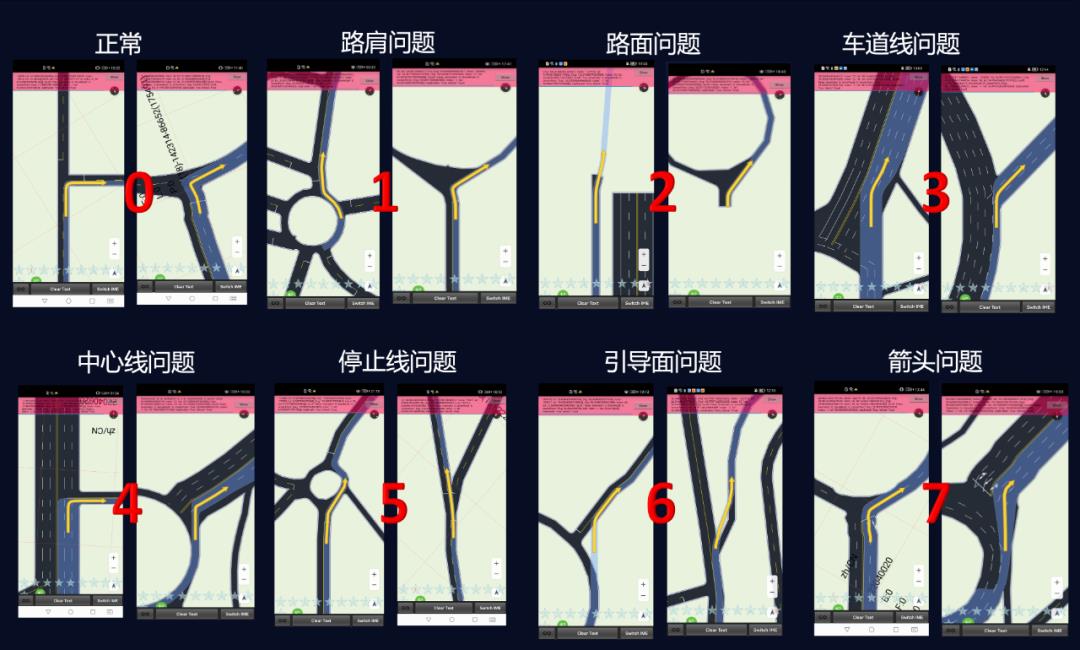
整个问题为经典的图像分类问题,赛题方提供了7种异常类别的细粒度标注,所以整体思路可以建模为“二分类”或者“多分类(8类:正常类别+7个异常类别)”问题。
数据分析
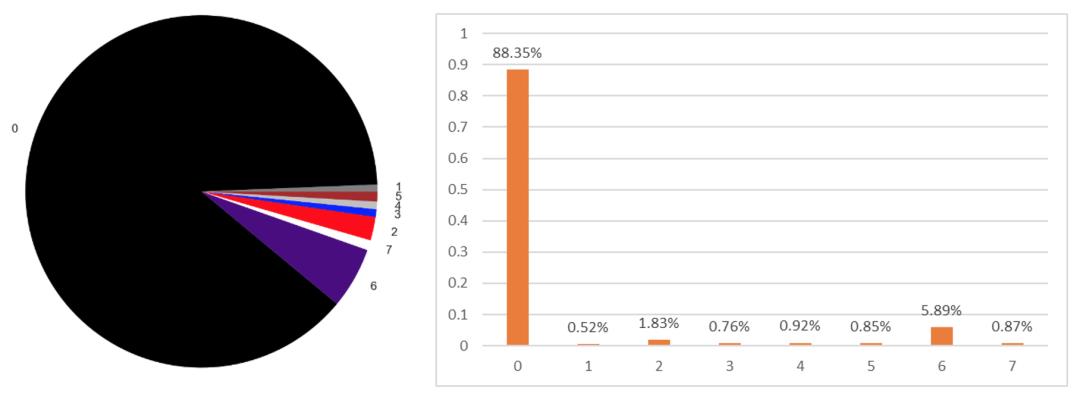
我们统计了有标签训练集的样本分步,如图1所示,可以看出存在以下两个特点:
长尾分布比较明显,各个类别样本严重不均衡。
在异常的类别中,第6类“引导面”的占比最大。(说句题外话:本赛题复赛最后的第一名就是针对第六类单独统计了一些像素值,最后通过这些像素值的统计特征将第6类摘出来了,正好第六类占比比较大,弯道超车,属实佩服👍🏻)
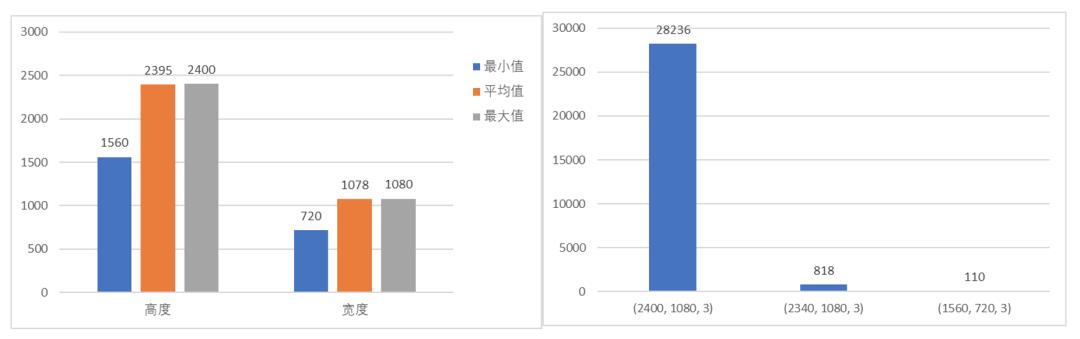
此外,我们还统计了有标注数据集的尺寸大小,发现主要是2400*1080的尺寸,长宽比悬殊但比较固定,且尺寸较大。我们尝试过resize成方形的方式进行训练,发现效果不如等比例缩放来的好。所以最终我们将长宽都缩小到了原来的四分之一,在保证训练效果的同时,也节省了显存开销。
数据增强
对于大部分比赛而言,合适的数据增强都有奇效,但一般很难吃准什么增强有效,所以大家只能盲目尝试。但笔者一直认为高端的食材只需要简单的烹饪,所以我们只采用了比较基础的数据增强方式(对比度、水平翻转这些)。这里不太适合做那种几何变换的数据增强,否则很容易破坏掉原图的语义结构。
当然,我们观察训练集的标注,发现存在一张照片同属于多个异常类别这个问题,这表明图像可能同时存在多个异常,所以我们采用mixup的增强方式来提升模型分辨不同问题图片的能力。
模型设计
对于分类问题来说,笔者一直觉得大道至简,各种花里胡哨的attention操作有时候还比不上简单纯粹的分类网络,只是需要掌握合适的烹饪手法,才能做出美味的佳肴。这里给出了笔者采用的网络架构。
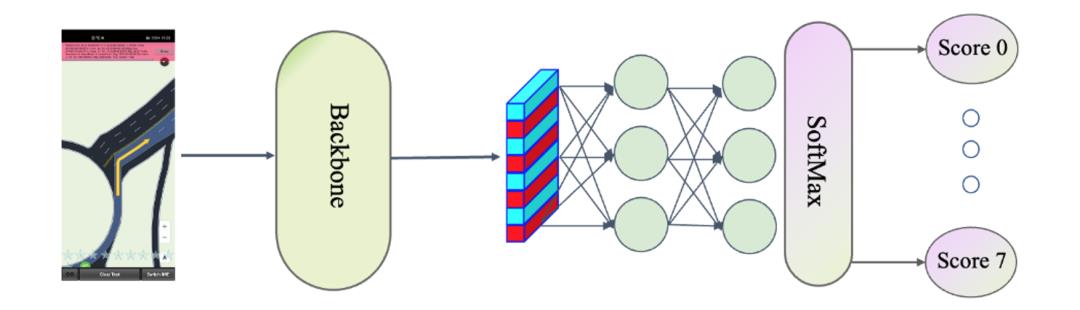
当然,由于这个比赛比较特殊,存在大量的无标注数据,充分利用大量的无标注数据对模型性能的提升影响很大,所以我们的模型最终采用了三阶段的训练方式。
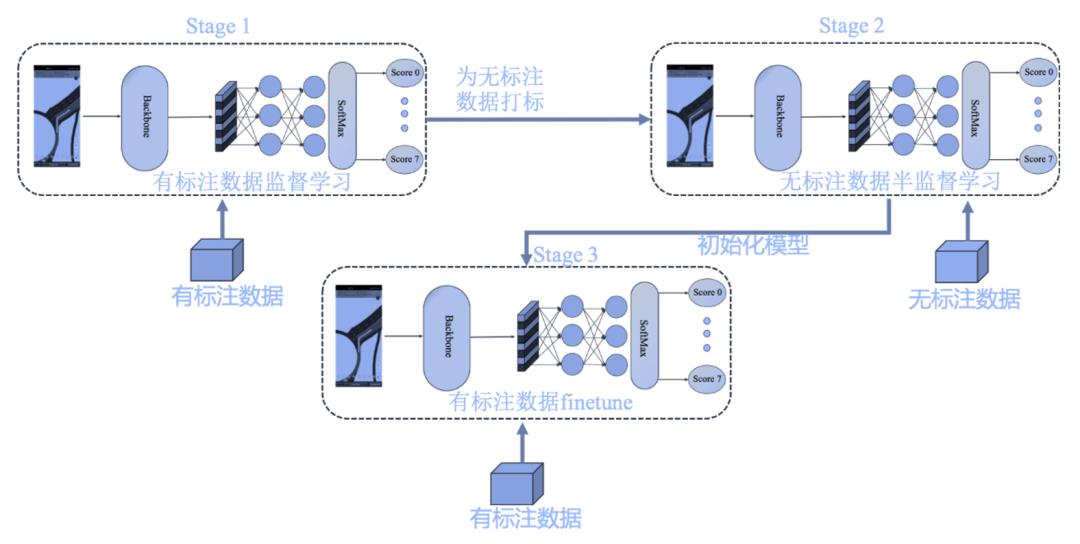
训练方式如下:
Step1:即先通过有标注数据进行监督训练,然后为大量的无标注数据打标签;
Step2:接着利用无标注数据进行半监督预训练;
Step3:最后将预训练模型拿来初始化监督网络,利用有标注数据进行finetune。
当然,我们也尝试过将二三阶段合并在一起,但效果不太好。主要是由于无标注数据样本太多,有标注数据太少,有标注数据很容易淹没在无标注数据中。
当然有余力的同学可以尝试通过MAE的方式预训练一个模型拿来初始化,但笔者受限于算力环境,不太容易训收敛,所以没采用这种方式,不过这也是一个很好的预训练方式。
实践证明,合理的利用无标注数据进行预训练对泛化性和AUC提升很大。经过分析,发现主要原因可能在于无标注数据的规模比较大,测试集的分布更加接近无标注数据集的分布,故而利用好无标注数据就是一把大杀器。
记得初赛阶段切换过一次数据,在原有4000张测试样本的基础上增加了6000张测试样本,我们发现切换数据后大家的模型性能都遇到了显著的下降,这里我们统计了增加前四千张和增加的六千张的概率分布图,发现差异还比较大。
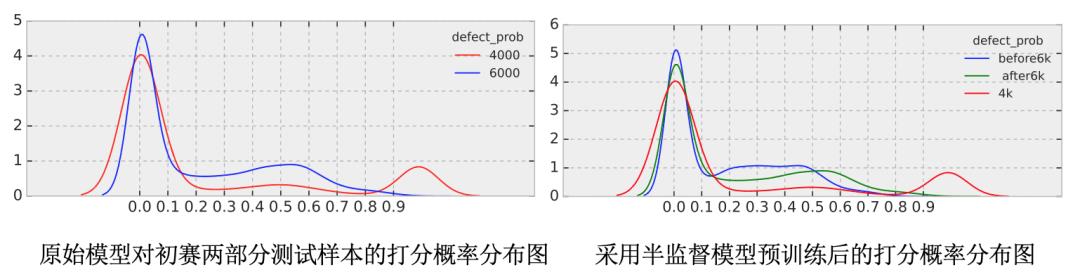
通过我们半监督预训练的方式,增加的六千张的概率分布图由蓝线变成绿线,和红线更靠近,从而缩小了两部分的差异,大幅提升了分数。所以模型训练的关键就在于合理地利用无标注数据进行预训练,利用测试集与无标注数据的相似性进行调参炼丹。
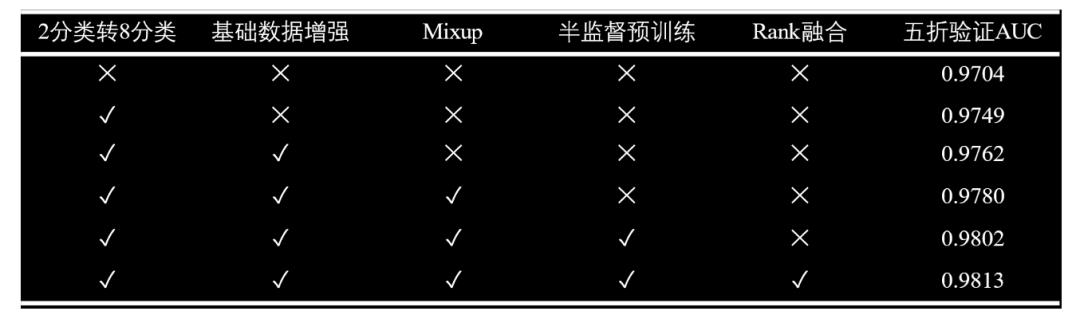
消融实验
我们也做了一些消融实验,发现存在一些特点
二分类转8分类问题,监督信号变强,使得模型性能有了较大的提升
半监督预训练,虽然线下分数变化不大,但线上提升巨大,与其他选手拉开了差距
方案优势
综上所述,我们的方案主要有以下几方面的优势:
对于无标注数据的高效利用(使用半监督标注手段对无标注数据进行标注)
多阶段建模(创新性的使用半监督方式预训练模型,再利用真实标注进行finetune)
较强的模型泛化能力(从初赛开始,每一次换数据或者切榜都能取得稳定优势)

整理不易,点赞三连↓
以上是关于2022华为全球校园AI算法精英赛:季军方案!的主要内容,如果未能解决你的问题,请参考以下文章
华为开启2022全球校园AI算法精英大赛 百万奖金等你来挑战算法极限
华为开启2022全球校园AI算法精英赛道 百万奖金等你来挑战算法极限
近200万奖金!仅限在校生!DIGIX全球校园AI算法大赛来了