软件架构模式
Posted _瞳孔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了软件架构模式相关的知识,希望对你有一定的参考价值。
如果有兴趣了解更多相关内容,欢迎来我的个人网站看看:瞳孔空间
创建软件系统基本结构的原则称为软件体系结构。软件结构由软件元素及其相互关系组成,这些元素起着蓝图的作用,规划了要执行的任务的模式。软件设计团队极大地依赖于这些软件架构模式。应当指出,必须明智地选择软件体系结构,因为一旦实施,就不容易更改。
软件架构模式很重要,因为它们是在架构设计中成功构建和测试的最佳解决方案的示例。有经验的开发人员会使用他们的知识和熟悉程度来包含这些模式,而不是在设计时人为或随机创建模式。此外,通过使用这些模式并突出显示它们,他们可以共享知识并教会新开发人员关键的设计策略。
几种经典的架构模式:
- 系统软件
- 分层(Layer)
- 管道和过滤器(Pipes and Filters)
- 黑板(Blackboard)
- 开发分布式软件
- 经纪人(Broker)
- 客户/服务器(Client/Server)
- 点对点(Peer to Peer)
- 交互软件
- 模型-视图-控制器(Model-View-Controller)
- 显示-抽象-控制(Presentation-Abstraction-Control)
一:4+1视图
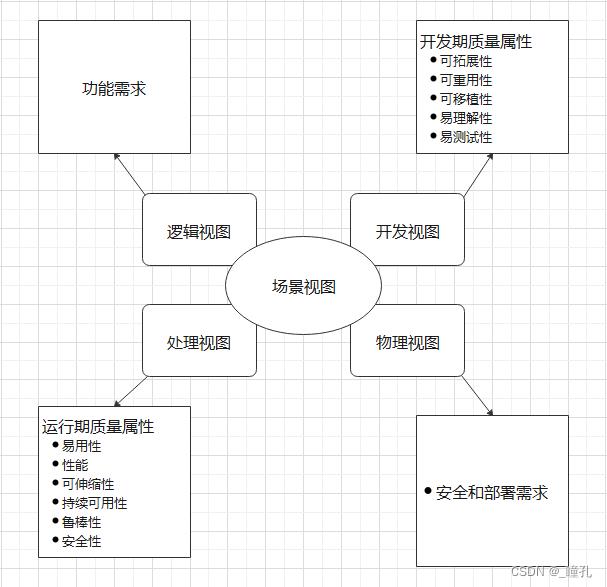
4+1视图”,分别为场景视图、逻辑视图、物理视图、处理流程视图和开发视图。这5种架构视图是从不同角度表示一个软件系统的不同特征,组合到一起作为架构蓝图描述系统架构。
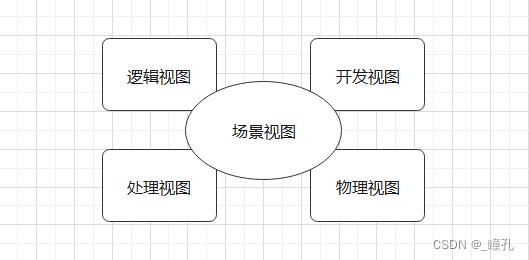
- 逻辑视图。逻辑视图不仅关注用户可见的功能,还包括为实现用户功能而必须提供的"辅助功能模块";它们可能是逻辑层、功能模块等。
- 开发视图。开发视图关注程序包,不仅包括要编写的源程序,还包括可以直接使用的第三方SDK和现成框架、类库,以及开发的系统将运行于其上的系统软件或中间件。开发视图和逻辑视图之间可能存在一定的映射关系:比如逻辑层一般会映射到多个程序包等。
- 处理视图。和开发视图的关系:开发视图一般偏重程序包在编译时期的静态依赖关系,而这些程序运行起来之后会表现为对象、线程、进程,处理视图比较关注的正是这些运行时单元的交互问题。
- 物理视图。和处理视图的关系:处理视图特别关注目标程序的动态执行情况,而物理视图重视目标程序的静态位置问题;物理视图是综合考虑软件系统和整个IT系统相互影响的架构视图。
- 场景视图。从前面的图可以看到,4+1中的4个视图都是围绕着场景视图为核心的。它用于描述系统的参与者与功能用例间的关系,反映系统的最终需求和交互设计。
各个视图内容大概如下:
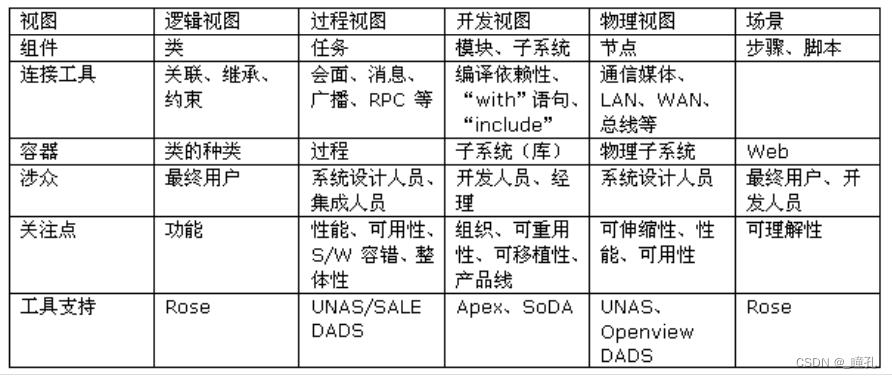
“4+1”视图模型一览表:
二:分层架构模式
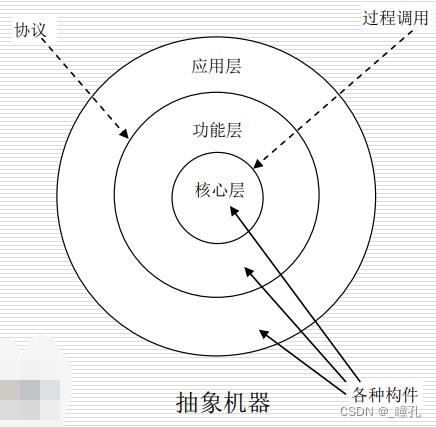
在分层模式中,系统将划分为一个层次结构
- 各层之间的关系是客户/服务器
- 每一层都具有高度的内聚性,包含抽象程度一致的各种构件,支持信息隐藏
- 分层有助于将复杂系统划分为独立的模块,从而简化程序的设计和实现
- 通过分解,可以将系统功能划分为一些具有明确定义的层,较高层是面向特定应用问题的,较低层更具有一般性
- 每层都为上层提供服务,同时又利用了下层的逻辑功能
- 每层只对相邻层可见,层次之间的连接件是协议和过程调用,用以实现各层之间的交互
- 上层通过下层提供的接口来使用下层的功能,而下层却不能使用上层的功能
- 良好的层次结构将有助于对逻辑功能实施灵活的增加、删除和修改
- 利用接口,将下层实现细节隐藏起来,从而有助于抽象设计,形成松散耦合的结构模型
分层架构规则:
- 第n层只依赖于它下方的第n-1层(层桥接可以直接调用下面所有层)
- 一个层不依赖于它的上层
- 只为上一层提供服务
- 通过接口使用服务
类图如下:
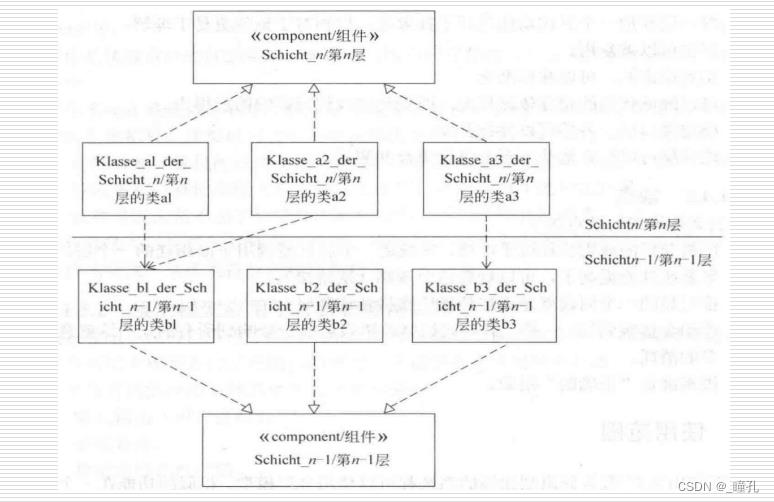
分层系统的实现:
- 为分层定义抽象准则,定义抽象层次
- 给每一层命名并指定它们的任务和提供的服务
- 为每个层定义接口、实现独立的层
- 确定相邻层通信、降低相邻层的耦合程度
- 设计错误处理策略
优点:
- 复杂系统分解为层次结构,抽象化每层,易于理解
- 层是稳定的,可以被标准化
- 减少依赖程度,变更影响的层少
- 确定接口,并行开发,易于集成和测试
- 支持扩展。每一个层至多和相邻的上下层交互,因此功能的改变最多影响相邻的上下层
- 支持重用。定义一组标准接口允许各种不同的实现方法
缺点:
- 层次的划分不太容易
- 很难找到一个合适的、正确的层次抽象方法
- 并非所有系统都能够按照层次来进行划分,即使一个系统的逻辑结构是层次化的,但是出于对系统性能的考虑,需要把不同抽象程度的功能合并到一层,破坏了逻辑独立性
- 很难找到一种合适和正确的层次划分方法,其应用范围受到限制
- 在传输数据时,需要经过多个层次,导致了系统性能下降
- 多层结构难以调试,往往需要通过一系列的跨层次调用来实现
使用范围:
- 基于微内核构建的Windows NT系统:
- 系统服务层:子系统与NT执行程序间的接口层
- 资源管理层:包括对象管理、安全引用监视、进程管理、I/O管理、虚拟存储管理、局部过程调用等模块
- 内核:负责基本功能,如中断和异常处理,多处理器同步,线程调度
- 硬件抽象层:隐藏不同处理器系列机器间硬件的差异
- 硬件层
- 非严格分层结构,内核和I/O管理需要直接访问硬件
三:管道/过滤器架构模式
问题:面向数据流系统时:
- 数据加工过程不应该是一个整体
- 需要易于扩展
- 尽量并行工作
解决方案:
- 根据不同处理阶段,分解为单一小任务
- 每个加工步骤通过一个过滤器实现
- 过滤器间通过管道连接
- 过滤器读取数据,加工转换,变成输出数据
管道/过滤器架构模式主要包括过滤器和管道两种元素:
- 构件被称为过滤器,负责对数据进行加工处理
- 每个过滤器都有一组输入端口和输出端口,
- 从输入端口接收数据,经过内部加工处理之后,传送到输出端口上
- 连接件称为管道
- 数据通过相邻过滤器之间的连接件进行传输
- 连接件看作输入数据流和输出数据流之间的导管
过滤器、管道作用:
- 过滤器对数据加工:
- 提取部分数据
- 补充部分数据,如计算和附加
- 修改部分数据
- 管道
- 传输和缓存数据
- 被动元素,体现数据流的实现
管道/过滤器结构:
- 将数据流处理分为几个顺序的步骤来进行
- 一个步骤的输出是下一个步骤的输入
- 每个处理步骤由一个过滤器来实现
每个过滤器独立,是独立的实体。过滤器之间无需共享状态,无需知道其他过滤器完成自己的任务,不同过滤器之间不需要进行交互。数据输出的最终结果与各个过滤器执行的顺序无关
结构如下:
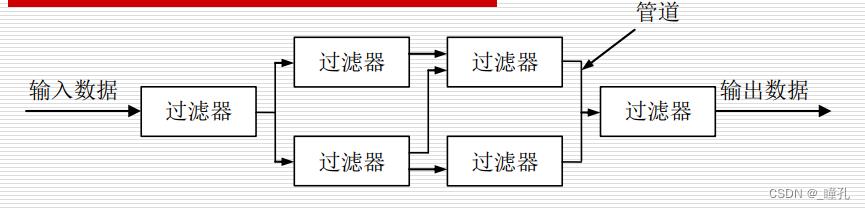
通用结构:
- 管线(pipelines):限制系统的拓扑结构只能是过滤器的线性序列
- 有界管线(Bounded Pipes):限制了在管道中能容纳的数据量
- 类型定义管道(Type Pipes):明确定义在两个过滤器间的数据类型
管道和过滤器的实现:
- 将系统任务分成几个独立的处理阶段
- 定义每个管道传输的数据格式
- 决定管道的连接
- 设计和实现过滤器
- 设计出错处理
- 建立处理流水线
管道/过滤器风格具有以下优点:
- 简单性:允许将系统的输入和输出看作是各个过滤器行为的简单组合,独立的过滤器能够减小构件之问的耦合程度
- 重用性:支持功能模块的重用;过滤器并不知道它的上游和下游的过滤器的特性;它的设计和实现不会对与它相连的过滤器加以限制
- 系统容易维护和扩展:新过滤器可加入,旧过滤器可替代
- 并发性
管道/过滤器风格也存在着一定的问题:
- 系统处理过程是批处理方式,过滤器具有很强的独立性,对于每一个过滤器,设计者必须考虑从输入到输出的转换过程,这种方式会造成过滤器对输入数据的批量转换处理
- 不适合用来设计交互式应用系统
- 兼容性相对弱;维持两个相对独立但又存在某种关系的数据流之间的通信可能比较困难
- 有名管道:在过滤器之间通过有名的管道来进行数据传送,增加了解析或反馈工作,从而降低系统的效率
四:插件架构模式
在现有软件开发中,业务越来越复杂,代码规模越来越大,依赖的人力也越来越多。为了降低系统模块内部耦合度,减少开发难度,也为了能够支持多团队的并行开发,插件式开发架构变得愈加流行,尤其是在桌面软件、移动端应用中。Eclipse, Visual Studio, VSCode等,都是插件式开发架构的典型案例。
使用插件的意义
- 支持特性扩展
- 支持第三方开发
- 降低应用程序大小
需求:
- 体现一个适配系统,方便第三方扩展程序
- 软件应保持稳定
- 需要具有扩展性,以便长期使用
- 现有软件不允许修改,同时具有灵活性
- 符合开闭原则
解决方案:
- 按插件架构模式设计并实现
- 扩展点用接口表示
- 插件实现这些接口
- 安装在接口位置
- 没有添加插件进行扩展是,也可正常运行
- 插件
- 为系统提供了新功能,扩展现有功能
- 不能独立运行
- 不依赖应用程序内部流程
插件的概念
- 是一个软件的组件,用于扩展新功能
- 实现用于扩展的接口
- 接口的定义被标记为扩展点
- 插件管理者负责运行时加载插件
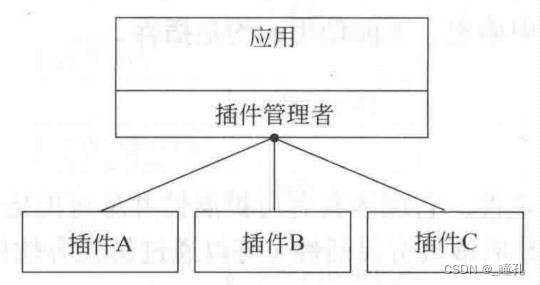
优点:
- 每个插件有自己的职责范围(关注点分离)
- 便于第三方扩展
- 保持系统的精简
- 支持多版本同时运行
- 插件的独立测试
缺点
- 初始过程消耗较高
- 执行过程中管理开销不断提高
- 扩展时必须通过接口,插件和接口有依赖关系
五:Borker架构模式
也称为分布式系统架构模式
需求:
- 大型软件系统必须可以“成长”
- 单机系统很快达到极限
- 组件必须分配到多台计算机
- 系统不需要重新设计
- 系统架构必须易于扩展,适应性能变化
- 系统分解为组件(静态),相互协作(动态)
- 必须考虑组件间的解耦
- 组件间需要相互通信,不可能完全没有依赖
解决方案:
- 服务器组件
- 客户组件
- 角色不是静态不变,既是服务器,又是客户
- 服务器提供的服务在Broker登记
- 客户需要服务,向Broker询问,转交服务器
- 提供服务的地方对客户透明
- 优点是客户/服务器不需要相互了解物理属性
- 序列化和反序列化
Broker在客户和服务器间建立一个连接,对客户隐藏服务器的物理位置。Broker 必须了解服务器,服务器提供的服务必须向它登记
类图如下:
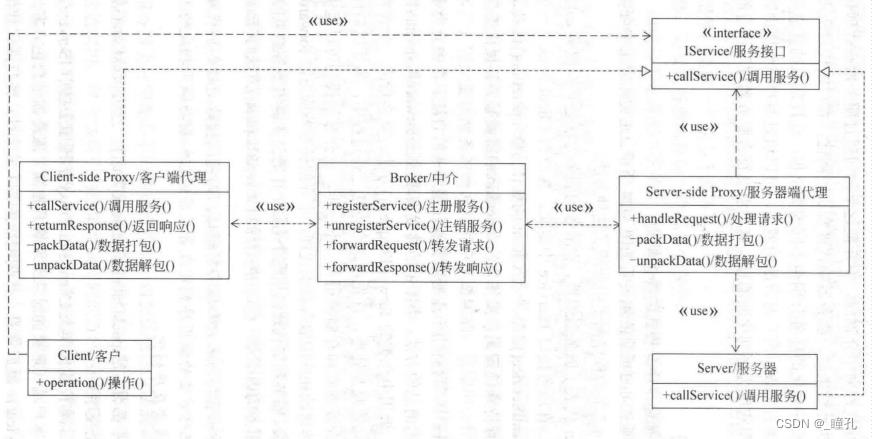
参与者:
- Client/客户:实现需求,调用服务
- Client-side Proxy/客户端代理:
- 对于客户,代表服务器
- 接收客户请求,序列化,传递到Broker
- Borker/经纪人:
- 负责C/S间的通信
- 管理服务提供者和服务之间的对应关系
- Server-side Proxy/服务端代理:
- 对于服务器,代表客户
- 客户端代理请求反序列化,生成服务方法调用信息
- Server/服务器:提供服务的类或组件
优点:
- C/S的通信和功能分析(关注点分离)
- 服务接口不变,更改服务器的实现
- 客户无需知道服务器的物理地址
- 通过服务器的逻辑名称,实现了隐藏
- 不依赖平台,可由不同编程语言实现
- 可把十分大型系统分布在多台计算机上
缺点:
- 本地中介为中心查询处,容错性
- 间接调用增加了调用的通信开销
- 中介可能形成拼接
- 代理依赖中介,更换中介必须重新适应
使用范围:
- 客户组件和服务器组件互相解耦
- 通过逻辑名称调用服务,不需要物理地址
- 运行时没有服务被调用,组件可以修改
- 服务的实现对客户组件隐藏
- 实例
- Internet / DNS
- CORBA
六:MVC架构模式
问题:
- 系统用户接口(界面)经常改变
- 不需要更改其余程序
- 界面上统一信息可以以不同形式展示
- 数据更改同时体现到期所有展示形式上
解决方法:
- MVC架构模式,交互系统的重要事项
- 相互分离的组件中实现:
- 数据管理和数据加工(Model)
- 表示逻辑(显示)(View)
- 用户输入(Controller)
- 程序开发总体趋势(关注点分离)
参与者:
- 模型:核心功能,封装系统数据和对数据的加工
- 视图:把数据展示给用户,含有模型要展示的数据
- 控制器:负责接收用户的输入,对输入的内容进行解释

MVC组件的依赖关系:
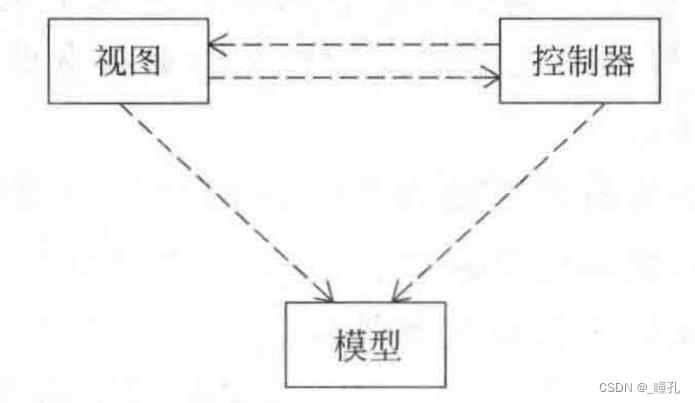
模型
- 任务
- 就是执行业务流程
- 不包括输入输出
- 存储所有业务数据
- 其实现不需要考虑视图和控制器的实现
- 提高架构灵活性
- 封装系统基本数据
- 模型中的反馈可以调用存储的数据,加工和处理
- 控制器调用模型中的方法
- 通知视图
- 被动模式(控制器通知视图数据的改动)
- 主动模式(推和拉)
视图
- 展示模型中的数据
- 通常包含交互系统的控制元素
- 不对时间做解释,转交控制器
通过模型更新两个视图:
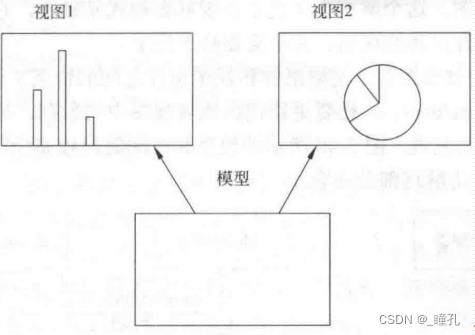
控制器
- 控制模型,根据用户输入控制视图状态
- 任务
- 视图接收的事件和用户输入的数据转化为模型方法的调用
- 对用户行为进行解释,决定调用哪个模型方法
- 控制模型状态变化和数据改变
优点:
- 模型类和用户界面分别设计
- 修改界面无需更改模型
- 模型单独测试
- 同一应用设计不同用户界面
缺点
- 经常更新影响系统性能
- 小的应用系统,细分多个类增加实现开销
使用范围:交互式软件
七:SOA架构模式
面向服务的架构模式
问题:
- 基于业务流程,
- —个应用场景代表了系统的一个功能
- 一个业务流程可以只包含一个应用场景,但通常包含多个应用场景
- 一个应用场景是一个业务流程(或一部分)
- 业务流程会影响系统的整体架构
- 业务流程的修改(很大程度上)引起计算机系统的改变
- 系统难以维护
- 程序的不稳定,成本急剧增加
解决方案:
- 面向服务的架构模式(SOA)
- 把一个业务流程直接构建为一个计算机系统
- 应用场景被分配给设计的组件,易于修改
- 中心概念就是服务
- 一个应用场景的目标就是实现一个服务
- —个业务流程会使用这个服务(应用服务)
对服务的要求:
- 分布式(distribution)
- 完整性(component appearance)
- 无状态(stateless)
- 松耦合(loosely coupled)
- 互换性(exchangeability)
- 位置透明性(location transparency)
- 平台独立性(platform independence)
- 接口(interface)
- 服务目录(service directory)
服务的层次:业务流程→应用场景→基本服务
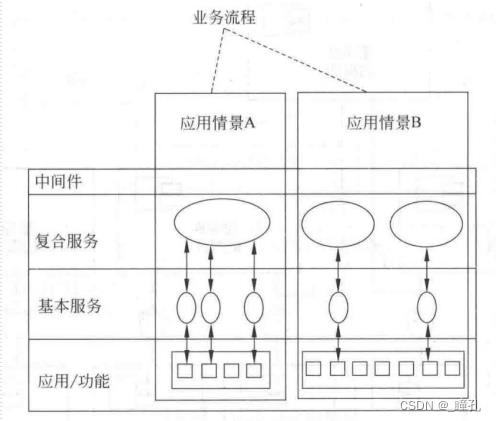
角色合作:
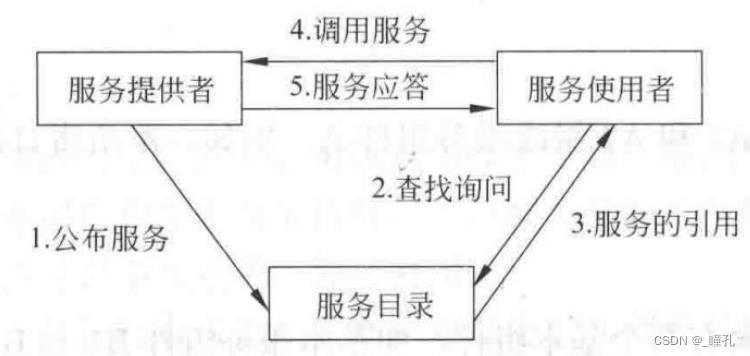
类图和参与者:
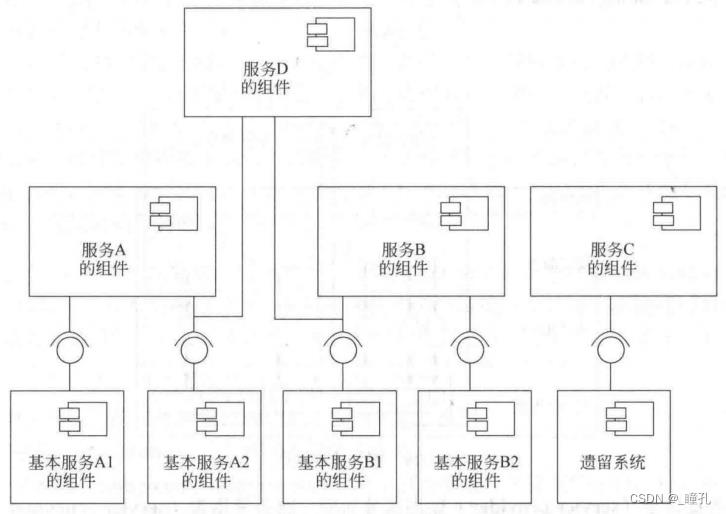
优点:
- 根据业务流程构成服务组件,总体了解服务和接口
- 分解服务组件和基本服务组件,减小系统复杂性
- 可复用
- 接口不变,服务的实现可动态更换
缺点:
- 过于细分服务组成复杂的结构
- 多个层次之间通信增加额外开销
- 网络传输速率要求高
- 业务流程需要明确定义和做好文档工作
使用范围:
- 所有C/S系统,特别是复杂系统,SOA简化
- 遗留系统通过封装
- 供应商和客户通过SOA实现业务流程对接
以上是关于软件架构模式的主要内容,如果未能解决你的问题,请参考以下文章