黄东旭:开发者的“技术无感化”时代,从 Serverless HTAP 数据库开始 | PingCAP DevCon 2022
Posted TiDB_PingCAP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了黄东旭:开发者的“技术无感化”时代,从 Serverless HTAP 数据库开始 | PingCAP DevCon 2022相关的知识,希望对你有一定的参考价值。
12 月 1 日,以"去发现,去挑战"为主题的 PingCAP DevCon 2022 主论坛在线上成功举办,为数万观众带来一场技术盛宴。PingCAP 联合创始人兼 CTO 黄东旭,在大会上分享了“The Future of Database”的主题演讲,分享了他对云原生、开发者生产力的理解,介绍了 Serverless HTAP 的意义以及未来的”技术无感化“发展方向。以下为演讲实录,全文约 7000 字。
首先感谢所有用户,用户的使用是支撑 PingCAP 一直进步的最重要动力,每年看到 TiDB 越来越普及,用户越来越多,就感觉肩上的担子又重了。

在过去一年中,TiDB 有一个最重要的变化——发版节奏和模型发生了变化。今年,TiDB 第一次引入了 LTS 版本,以及形成了以两个月为周期的迭代发版节奏。此外,特别值得一提的是,今年 5 月 TiDB Cloud 正式 GA,去年我提到云的意义在于加速软件的迭代速度,短短大半年时间 TiDB Cloud 已经进行了超过 34 次迭代,增加了上百个功能特性和改进。这个迭代速度比 TiDB 内核本身的迭代速度更快,这也印证了之前我对于云的判断。
数据库的“第一性原理”
埃隆·马斯克有一个很有名的“第一性原理”,这些年我一直也在思考这个问题,对于一个数据库厂商或者数据库产品经理来说,数据库软件的第一性原理是什么?对于数据库来说,一个很本质的问题是 developer 到底需要什么样的数据库。这里说的 developer 并不是指数据库开发者,而是那些真正开发应用的开发者。为什么这么说呢?其实数字化转型也好,各种应用创新也好,其背后的驱动力到最后都是一行一行代码,而这些代码都是开发者写的。对于数据库软件来说,真正的用户其实就是开发者。
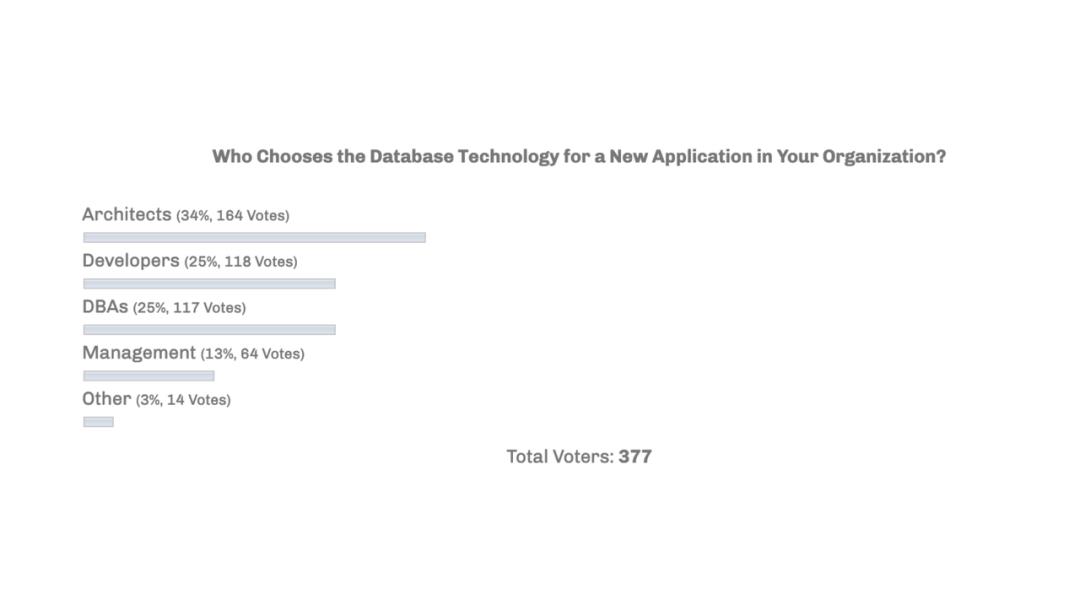
上图是一项关于“在你的组织内部到底是谁在选择 Database”的调查,可以看到排名第一的是架构师、第二是开发者、第三是 DBA,三者加起来达到了超过 80% 的占比。这些人都是广义上的开发者,对于数据库软件来说真正的用户其实就是这些人。

数据库里另外一个大的趋势是 Cloud。我觉得今年已经不用再强调 Cloud is the future,从 Gartner 的报告可以看出,今年全球企业在 Cloud 上的投入已经超过了私有化数据中心的投入,并且每年的增速都非常快。
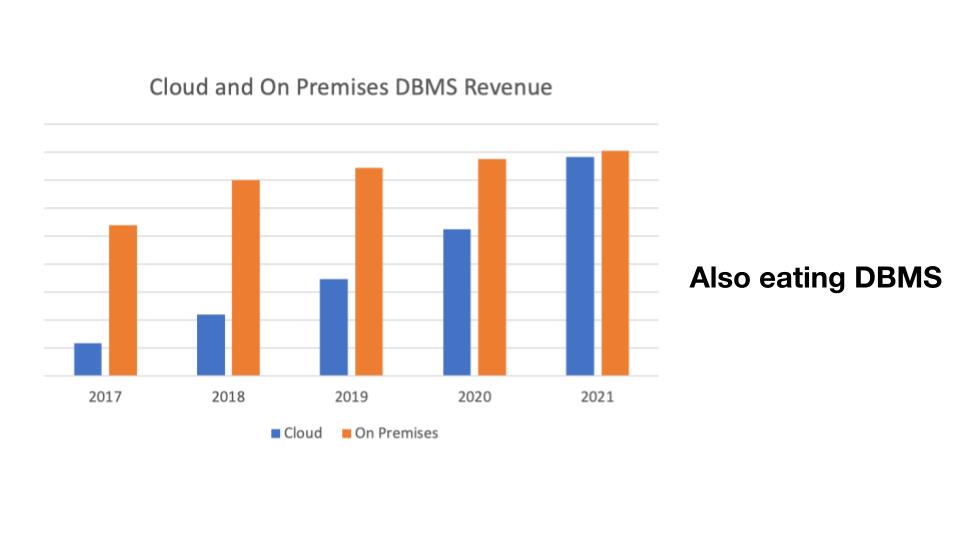
在数据库领域中也有着同样的趋势,上图是云数据库和私有化部署的数据库软件的占比趋势。大家可以看到,2019年时,云上的数据库服务(Database as a Service)还不到传统数据库的一半,但今年几乎接近一样,可以预见明年一定会超过。所以,云是毋庸置疑的趋势,在未来的数据库产品中,Cloud 一定会变成数据库服务的承载平台。
如何解放开发者的生产力?
这次分享的主题依然是“The Future of Database”,要讲的是数据库的未来会是什么产品形态。谈到这个话题,我的思考习惯是先关注现在数据库到底有哪些痛点,开发者到底在为什么烦恼。
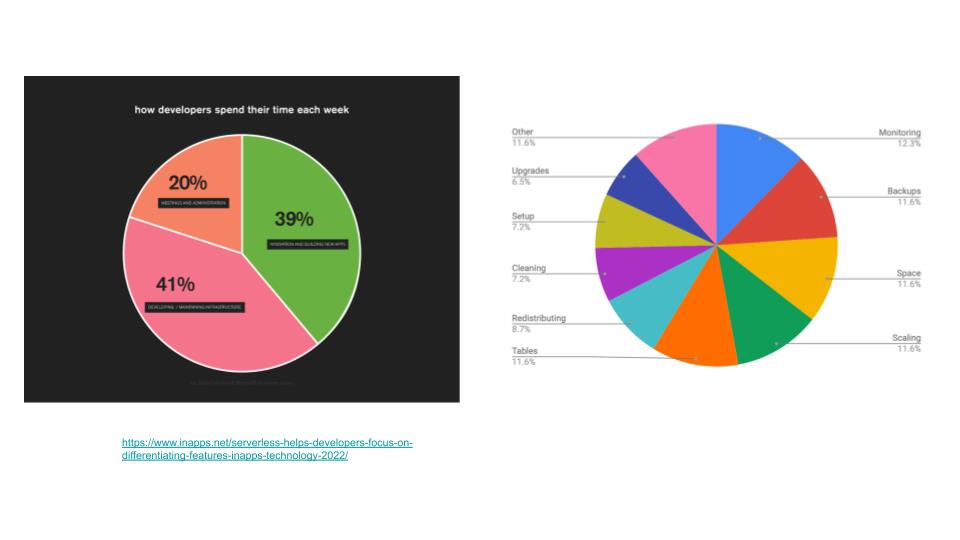
从这张图可以看出,开发者、程序员、DBA 日常的时间都花在了什么地方。你会发现他们 39% 的时间在做业务创新、在 Coding,41% 的时间在做基础设施维护,如买服务器、部署服务器、运维等等。这其实非常符合一个开发者的日常体感。有时候作为一个程序员,我想要雄心勃勃地做一个新的东西、新的应用时,会发现真正开发那个应用的时间可能只占整个时间的 10%-20% 左右,大量时间都花费在买服务器、部署数据库、数据的备份恢复、CI/CD 搭建上,而不是在开发应用上面。

这张图来自 a16z(美国一个特别著名的投资机构)在 2020 年底出的一份报告,他们提出了一套包治百病的数据架构“Unified Data Infrastructure”。当时看到这个架构的时候,我觉得它确实包含了我们遇到的各种各样的问题,这个架构确实能解决问题。但另一方面,图中每个框其实都是一套非常复杂的软件,这个架构的问题是框特别多、特别复杂,而且这些框之间互相的连接会把事情变得更加复杂。想象一下刚才提到的小例子,我在开发一个应用时要花很多时间去处理这些基础设施的问题,在这张图里,刚才这些不爽的体验要再乘十或二十倍,因为这些组件之间的连接会带来更多的复杂性。所以这个架构看起来很美,但实际上我们会花更多的时间去保障系统稳定运行。
综上所述,当今把开发者拖慢的最核心原因是开发者的生产力,如果开发者的生产力提高了,业务创新、应用创新的速度就会变得更快。
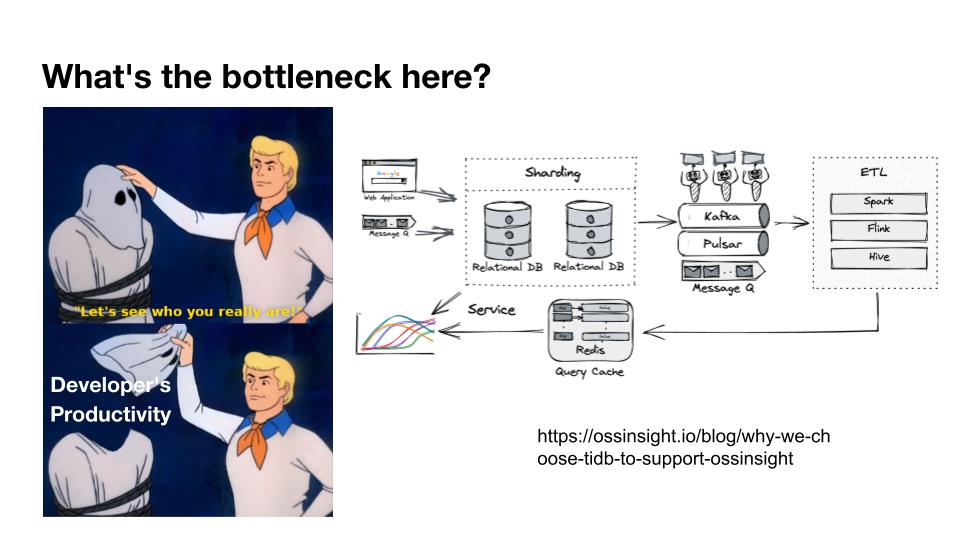
OSS Insight 是 PingCAP 自己开发的一个很好玩的 GitHub 数据分析工具,它抓取了 GitHub 上所有的信息和实时的数据,提供一些数据的洞察服务。这样一个看起来很简单、很有意思的小应用,如果用传统的思路去构建系统,你就会发现要用一大堆不同的技术栈串联在一起才能实现,并且每一个技术栈还有着自身复杂的运维成本。
过去 20 年我们发明了太多的技术,太多不同的 Database,每一种 Database 都有着自己复杂的概念与运维。作为一个开发者,要想把它用好,就需要把这些东西都学习一遍。业界有一句特别真实的笑话:别发布了,别做新的东西了,我真的学不动了……这些复杂的概念现在都没有被隐藏起来,反而全都透传给了开发者。举一个简单的例子,如果你想在云上选择机型,就会发现不同的公有云厂商会有好多机型推荐给你,如 i3.xlarge、i3.2xlarge、i3.4xlarge 等等,这些机型代号背后到底意味着什么?这都是系统架构的复杂性。
更不要说背后的成本,如果你在云上选错了机型或者选错了服务,就会发现最后的账单和你选了正确的机型或者服务有着天壤之别。最近很火的 FinOps,说白了就是如何科学地利用云去省钱。这意味着什么呢?意味着就连计费方式以及筛选的策略对于用户来说都是非常复杂的事情,复杂到需要用另外一套工具来去做优化,以帮助用户作出正确的决策。

**我们再往前看一下,今天的开发者到底是怎么去思考开发应用的?**这里我想分享一个最近特别喜欢的公司——Vercel,是一个非常偏向于开发者开发流程和体验的平台,在它的首页有三个英文单词:Develop(开发)、Preview(预览)和 Ship(上线),这其实就是一个开发者的视角。用过的同学就会知道,在 Vercel 这个平台上,一个应用开发者只需要关注网站怎么做,只需要去写 code。其他的事情,包括发布、部署、CDN、流量全都由 Vercel 帮忙封装好了,开发者只需要将 100% 的时间都放在业务逻辑开发上就可以了。这是一个很好的方向,这意味着应用的开发门槛在降低。未来,应用开发者对数据库的关注点会从数据库变成 API,甚至在更长远的的未来只需要关注 web 前端开发就好了。
用“抽象”解决复杂性
综上所述,从开发者的角度,或者新一代开发框架的角度来说,开发门槛正在变得越来越低,应用开发者变得越来越多,那数据库、数据技术、数据处理技术栈,怎么解决复杂性带来的矛盾呢?
我觉得解决这个问题的思路可以用一个词来描述——Abstraction(抽象)。为什么抽象如此重要?抽象怎么帮我们解决问题?
对于基础软件或者软件开发来说,概念的抽象程度提高,会带来什么样的结果?第一,架构的复杂性会变得越来越低。我们想象一下云,原来没有云的情况下你可能还要去考虑一下硬件、网络、磁盘、存储、数据中心的租赁,但有云了之后架构本身的复杂性是降低的,你不需要了解这么多东西,因为云底下的东西已经被隐藏掉了。这意味着作为一个开发者来说,他的心智负担在降低。就像用 Vercel 开发应用的时候你不需要关注 CDN,Vercel 已经解决了 CDN 的问题。心智负担降低意味着开发者能更快地开发出应用,能花更多的时间专注于业务创新,这就是商业的迭代速度。所以为了解决刚才说的矛盾,我们在数据技术上应该进一步去做抽象。

在聊数据库的 Abstraction 前,我们可以看另外一个例子——计算能力的抽象。上面这个二维图示中,竖轴是技术的抽象程度,横轴是商业创新的迭代速度(Go-to-Market Speed),我们用它来看一下刚刚这个理论是不是成立。
图中左下角是 On-Prem,意味着 20 年前要做一个网站,还要关心买服务器、租机房、网络租用等,抽象程度很低,开发者要花大量时间在这些与业务无关的事情上,这也就意味着迭代速度是慢的。
后来人们是怎么解决的?公有云的概念出现了,把刚才那些复杂的硬件、部署、网络等数据中心的复杂性抽象掉了。你拿到就是一台机器,它到底是不是真实的机器你不用关心。这时,你要再开发一个应用,只需要在公有云上开个账号,把应用部署上去,按月给钱就行了。这比起自己去折腾数据中心来说,迭代速度又快了一步。
再往上看,云原生的概念出现了。云原生的核心计算单元是 Container,Container 是更高层次的抽象。在虚拟机时代,你依然要去考虑 VM 挂了怎么办,但是在 Container 世界里,Container 以及底下云的调度器都不用你管,意味着迭代速度更快。
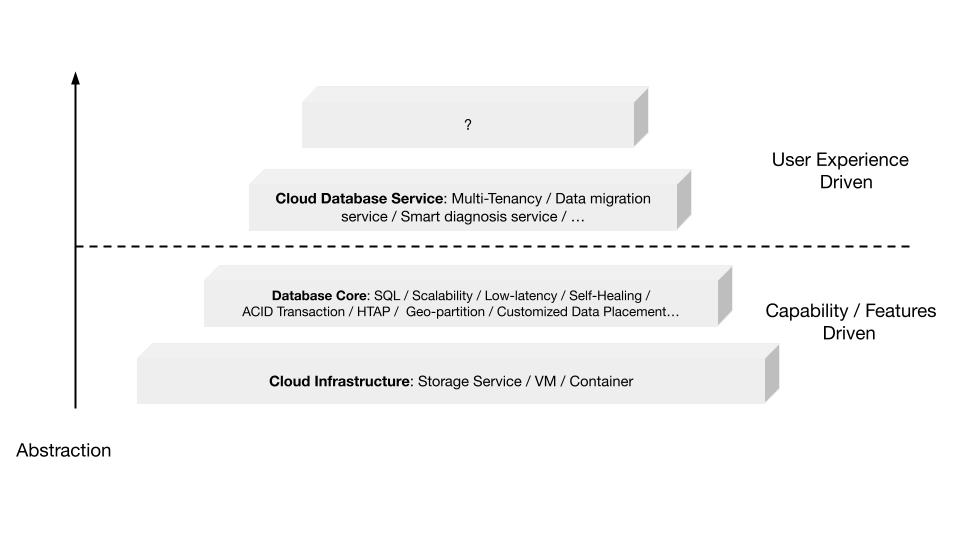
在数据库的世界里“抽象”是如何去体现的?抽象程度最低的是云本身的基础设施,比如你要在云上私有化部署一个数据库,你需要自己去维护 mysql 或者 VM。这时候你看到的是云的基础设施,它的抽象程度很低。再往上一层,比如 PingCAP 几年前要基于云提供的基础设施如虚拟机、S3、容器,去开发出一个叫 TiDB 的数据库。TiDB 提供了 SQL 能力,Scalability 能力,以及低延迟、高可用、分布式事务、HTAP、Geo-partition 等等一大堆数据库内核层面的能力。在这个阶段已经有很多用户说,“哇,TiDB 挺好用的”。
过去一年中,PingCAP 一直在把这个数据库技术变成一个数据库的云服务,也就是我们在做的 TiDB Cloud。技术和服务的区别是什么呢?TiDB 技术本身就像一辆车里的发动机,或者一个火箭里的引擎。但是一个发动机跟一辆车肯定不一样,尤其在云上。对于一个在云上想要使用数据库服务的用户来说,他需要数据的导入、数据的导出、备份、智能诊断、多租户各种各样周边的东西,把它们拼装在一起才是一个服务,而不是给用户一个发动机让你自己拼出一辆车。
这张图里有一条虚线,虚线之下作为一个数据库开发者或者一个数据库厂商来说,关注点其实是能力或者 feature ,就好比说发动机是不是稳定、是不是快、是不是省油,这些是能力驱动为主的一个抓手,但是在这条虚线之上整个驱动力会变成怎么去提升用户体验。你想要提供服务,就要从用户使用服务的全生命周期去考虑。比如他刚进来注册的环节、绑定信用卡的环节、数据导入的环节、使用、调优、备份的环节,同步到其他数据源的环节,每一个环节都要去考虑,这里面考虑的点就是用户体验,用户体验是指引这个产品做得更好用的方向。
下一级别的“抽象”是什么?
“抽象”再往前一步是什么?我们给出的答案是“Serverless”。一个月前 PingCAP 已经发布了 TiDB 的 Serverless 云服务。如果刚才那个理论是 OK 的,“抽象程度越高,开发的效率越高”,Serverless 就会变成在云原生之后新的“抽象”。对于数据库来说 Serverless HTAP 是一个更高级别的“抽象”,它意味着更高的开发效率。
可能大家第一次听到 Serverless HTAP ,这到底是什么东西?意味着什么?

第一,想象一下如果有这么一个数据库,它的启动或者创建,你不需要关心任何部署细节,也不用管有几个节点,而且它是召之即来,挥之即去的,几十秒之内就能准备好,一键就能创建出来;
第二,这个系统虽然看不见底下的基础设施,但是它会跟着业务的负载变化而自动匹配。比如说你的吞吐大到一定程度,不用再停下来加服务器,系统会自动进行扩展。当你的业务峰值降下来了,比如说双十一过后业务流量下来了,这个系统还能够自动地缩回来,甚至缩到 0。能缩到 0 其实很重要,在没有业务负载的情况下,系统能变成 0 意味着系统不再收钱,而且当有业务流量再过来的时候它也能在很短的时间内又恢复提供服务;
第三,HTAP Database。提供了一栈式的 SQL 能力,这是 HTAP 本身的能力;
第四,Pay-as-you-go。有的人可能会说公有云不是也是 Pay-as-you-go 吗?Serverless 跟云有什么区别?我觉得二者当然都是 Pay-as-you-go,但是能不能以一个更细的粒度去提供 Pay-as-you-go 的能力?过去我们其实还是按照服务器、虚拟机这样的资源来去看待一个月多少钱,这个服务能不能粒度更细一些,只收业务流量的钱?尤其是对于偏分析的场景来说,有很多时候我们做大数据分析,比如每天半夜要去跑个报表,可能需要一千个虚拟机算,20 秒钟算完,然后再缩回来。每天可能就凌晨需要这么多 OLAP 的服务器,但是我不可能白天也买这么多服务器,就为了晚上算那一下,能不能更细粒度的 Pay-as-you-go,只算 20 秒的钱非常重要。
第五,也是长期以来被各种硬核数据库开发商忽略的一点,但未来会越来越重要,一个 Serverless 的 HTAP Database 一定要跟现代的开发者开发应用的过程体验深度整合。举个例子,比如我们在笔记本上开发应用,现在如果有一个召之即来、挥之即去的数据库,我的开发体验其实是贯穿于整个开发流程里的。所以,过去我们其实一直在把数据库与开发者分开来看。数据库关注性能、稳定性,各种各样特别硬核的跑分,但是未来将是从开发者的角度考虑如何去使用数据库,让这个数据库帮助开发者更快、更流畅地构建应用。我觉得对于 Serverless 数据库来说,很重要的一个课题是从用户角度看,它应该融入到每天的、现代的开发体验中。
TiDB Serverless Tier

听起来很美好,Does it even possible?经过大半年的时间,我们终于把这个东西的第一个原型做出来了,并在 11 月 1 号上线公测,这就是刚才说的 TiDB Serverless Tier。
我自己写了一个小程序,在一个全新的环境下,通过代码启动一个 TiDB 的 Serverless Tier 实例。在这个过程里,我只是告诉这个程序,要启动一个集群,这个集群叫什么名字,然后把密码一输,20 秒之后可以直接拿一个 MySQL 客户端连上去了,这个时间未来会进一步缩短。想象一下,如果缩短到三五秒钟,这会极大地改变开发应用的使用流程和体验。而且你不用关心它的扩展性,即使上线以后,业务流量变得巨大无比的时候,它也能够很好地扩容上去,没有流量的时候,它还能缩回来。

当然它背后其实有很多很多的技术细节,本文我们就不一一细说了。其中我们有一个原则,就是怎么利用好云提供的不同的服务,比如 Spot Instances、S3、EBS、弹性的 Load Balancer。TiDB 的 Serverless Tier 背后对于云上所有的弹性资源都进行了很好的整合,以及巧妙的调度,提供了一个极致弹性的用户体验。这个用户体验比原来的云原生数据库更往前跨越了一步,细节更少,抽象程度更高。
这是系统的设计图,就不展开太多了,给大家展示一下这个东西还是挺厉害的。
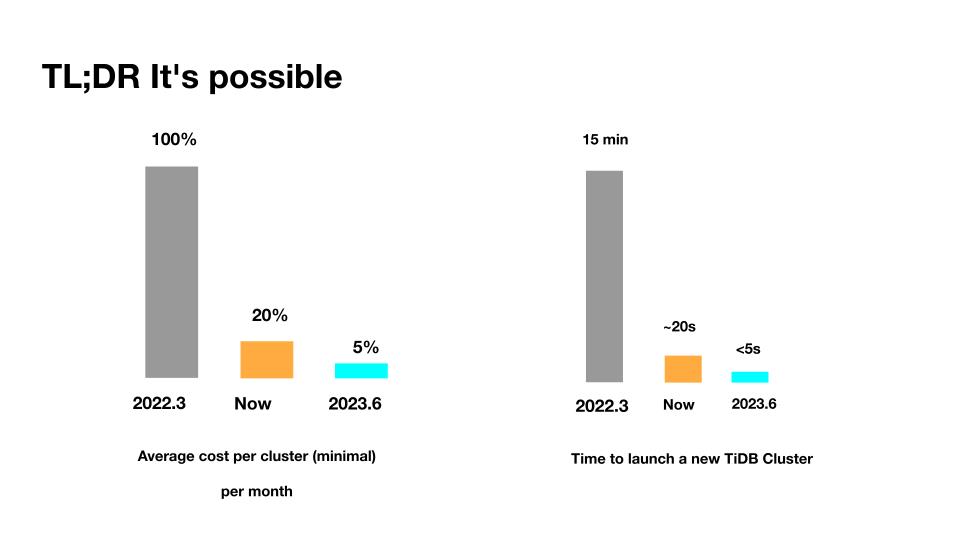
所以,TL;DR 是存在的,也是有可能被做出来的。当 TiDB Serverless Tier 上线以后,我们发现它一上线就把整个 TiDB 在云上的 cost 降低了。拿最小集群来说,现在对比今年年初,成本降低到 1/5。而且在可见的未来,这个成本会变得更低;第二就是启动的时间,在今年 3 月份的时候,在云上启动一个新的 TiDB 集群需要 15 分钟,如果自己部署时间可能更长。现在只要 20 秒钟,不远的未来这个时间会缩短到更短。
云端 Serverless HTAP 数据库服务,意味着什么?

第一,我们一开始花了很长时间去构建了一个稳定的数据库内核,可以弹性扩展、自动 Failover、ACID Transaction 等非常硬核的基础能力。但这些都是基础能力,这些东西应该隐藏在发动机里。作为一个开车的人,不用关心变速箱里有哪些特性;
第二,HTAP 能够提供实时的一栈式数据服务。用户不需要关心什么是 OLAP,什么是 OLTP。一套系统可以支撑所有负载,也不用担心 OLAP 负载影响 OLTP 的正常服务;
第三,基础设施层面,Serverless 部署的成本变得极低,极致的 Serverless 不用关心任何运维的细节。你可以通过代码和 open API 控制这些集群的起停。在拥有更大规模的基础设施时,这点是非常重要的。Serverless 在处理更复杂或更大系统的时候,能显著减低复杂性;
第四,真正的按需计费。Serverless 能够真正按照资源的消耗量来去计费。对于开发者来说,想用数据库的时候,只要招手它就来,不用的时候,也不用给钱,任何时候去访问它,数据都在那儿,也能对外提供服务。
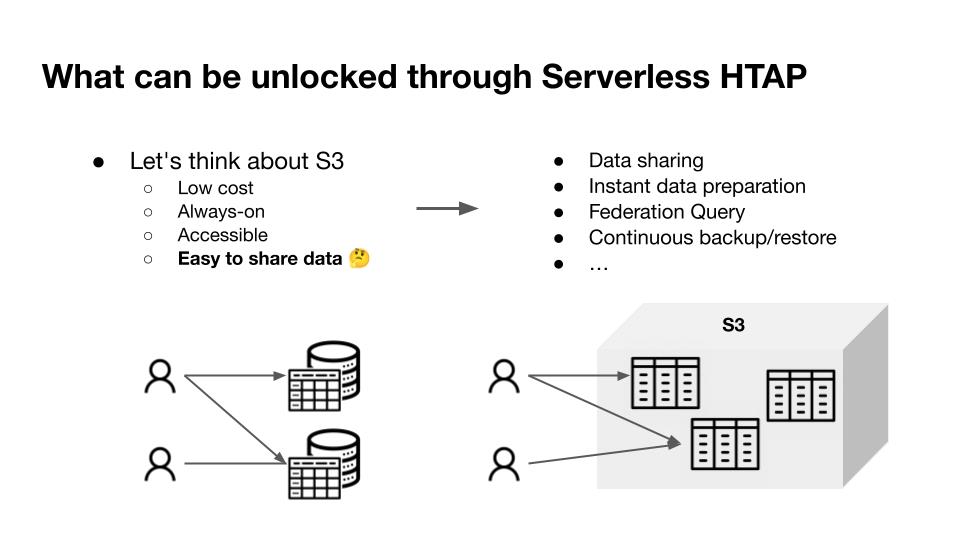
在这样的 Serverless 架构下,我们其实还能解锁更多的能力、更多的可能性。
举个例子,S3 是 TiDB Serverless Tier 底下重度依赖的云对象存储服务。用过 S3 的肯定都知道它便宜,可用性很高。更重要的一点是数据共享,比如大家都在用 AWS,A 用户用 S3,B 用户部分数据也在 S3 上,比如说我想把我的数据共享给另外一个用户的时候,既然都在 S3 上,那共享就变得很简单。以前在私有环境下,你还需要把数据下载出来拷给他,再上传进去,然后才能做分析。如果是在数据量比较大的情况下,这几乎是不可想象的。这种新架构的一种可能性就是真正能够做到 Data Sharing,当然这里面肯定还涉及到包括隐私计算,各种各样的安全性问题。但从技术底层来说,这种产品形态并非不可能了。
另一种场景,比如说我想做一个区块链的数据分析应用,但做这样的应用,第一步你得把数据准备好。区块链的数据其实也不小,经常是大几百 GB 或几个 TB 的数据。但如果在 S3 上有一个公共的数据集已经准备好了,那在云上 Serverless 用户只需要在启动的时候,加载这部分数据就好了。这些能力在云下是根本不可能完成的任务。
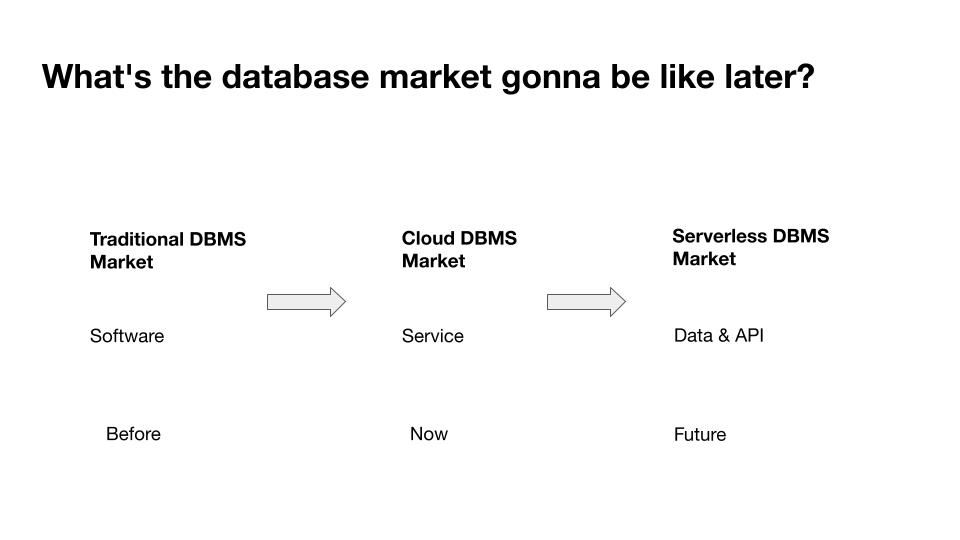
这些能力具备后,数据库的商业模式会变成什么样子?在去年的 DevCon 上,我提出了一个猜想,“数据库作为一个软件形态本身会消亡,而数据库的平台化、微服务化会取代原来的数据库软件形式”。这个理论正在变成现实,今天,我们可以看到几乎所有的数据库厂商,都在云上提供服务。
更进一步
未来再往前一步,会发展成什么样子?
Serverless 其实是云上 Database Service 更进一步产品形态的体现。现在我可能还需要去关注买多少个数据库节点,买多少个集群,但是在未来,真正从开发者的角度来说,他所关心的应该只有数据操作的 API ,这一层才是离业务更近的东西。另一方面,当 Serverless 在云上被提供后,数据共享、交换就变成了一个很自然或者很简单的事情,那时候我觉得会出现一个叫做 Data market 的新商业模式。
记得我在上大学学数据库课程的时候,我的老师告诉我,这个东西很简单,你只要会写 SQL 就 OK 了。但我工作以后,发现还有 OLTP、OLAP、时序数据库、图数据库,以及各种各样稀奇古怪的数据库,你得学习一大堆东西,这些东西里面有无数的细节。
我们想把它做得很简单,把开发者的体验带回从前。数据库本来就应该是很简单的东西,我们应该花更多的时间关注于业务的创新、关注于真正重要的事情,这些复杂的东西,就让它简单起来好了。
未来真正重要的东西是什么?是流畅的开发体验。这就是我们终极的前进方向,也是作为一个基础软件提供商的担当。虽然前面说了这么多很技术的东西,但其实 Serverless 很简单,现在它已经变得触手可及,大家可以通过 TiDB Cloud 就可以立刻体验它。
以上是关于黄东旭:开发者的“技术无感化”时代,从 Serverless HTAP 数据库开始 | PingCAP DevCon 2022的主要内容,如果未能解决你的问题,请参考以下文章