Elasticsearch:如何将 Strava 数据导入 Elastic Stack
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:如何将 Strava 数据导入 Elastic Stack相关的知识,希望对你有一定的参考价值。
作者:Philipp Kahr

这是后续系列博文中的第一篇。 我将带你完成数据加载、操作和可视化的旅程。
什么是 Strava,为什么它是焦点? Strava 是一个平台,从业余到专业的运动员都可以在这里分享他们的活动。 我的 Apple Watch、Garmin 和 Zwift 的所有健身数据都会自动同步并保存在那里。 可以肯定地说,如果我想大致了解自己的健康状况,从 Strava 获取数据是第一步。
为什么使用 Elastic Stack 这样做? 我想问我的数据问题,而问题只是搜索!
- 今年我骑自行车的次数比去年多吗?
- 平均而言,骑车距离越远,我的心率是否会降低?
- 我是否经常在同一条跑道上跑步、远足和骑自行车?
- 我的心率与骑自行车时的速度相关吗?
[相关文章:我如何使用 Elastic Maps 来规划我的骑行行程并找到独特的道路]
从 Strava 中提取数据并将其发送到 Elasticsearch
在我们回答任何问题之前,我们需要从 Strava 获取数据。 Strava 有一个可以查询的 API。 我不会详细介绍身份验证机制的工作原理,最好阅读 Strava 的文档。
解决了这个问题后,我决定编写一些 python 代码来完成我们需要的所有 API 调用和数据处理。 Elastic 发布了一个官方的 python 语言客户端,这确实减少了我们将数据发送到 Elasticsearch 所需的工作量。
首先,由于没有来自 Elastic 的官方 Strava 集成,我们需要考虑数据架构以及我们可以使用哪些字段类型来存储数据。 这是一项更耗时的任务,了解哪种字段类型比其他字段类型效果最好在这一步至关重要。
让我们看一下来自 Strava 的 Get Activity API 的示例文档:
[
"resource_state": 2,
"athlete":
"id": 75982219,
"resource_state": 1
,
"name": "Zwift - in London",
"distance": 38083.9,
"moving_time": 5223,
"elapsed_time": 5223,
"total_elevation_gain": 272.0,
"type": "VirtualRide",
"sport_type": "VirtualRide",
"id": 8073344712,
"start_date": "2022-11-05T16:16:17Z",
"start_date_local": "2022-11-05T17:16:17Z",
"timezone": "(GMT+01:00) Europe/Vienna",
"utc_offset": 3600.0,
"location_city": null,
"location_state": null,
"location_country": "Austria",
"achievement_count": 2,
"kudos_count": 3,
"comment_count": 0,
"athlete_count": 1,
"photo_count": 0,
"map":
"id": "a8073344712",
"summary_polyline": "gqkyHnnPqCxVk@~HOnFSdWz@fNEnQ?dg@RfIl@rIj@dExBfLxArE~DpH~DtCpCtAh@r@BnAiDvYBb@d@lBg@bDs@tNhAlFbLfb@?ZUj@MbMI^xG`RpIpSxC`GbCnHh@nEPfLvBbUb@nLr@rFx@~D`AxBvFbHhCjFj@@l@_A~@gEn@eGJwC^e@lAg@JYIcETs@v[uFVo@EkB^i@t@J\\\\\\\\fBVRxIiB|OYfIcPd@eDC_Nb@kLdCoXJwCScFuE_c@k@eDo@eBaAeAaEwBgCBmAyBsBiGiA_CkKwIeAi@kC_@kIJoPjBkEJEnAwGIUr@?dDi@tRhDns@Ep@Ud@_DlD]PqACe@l@s@nw@I|@WLYm@CiCx@os@RuCq[keAq@aAmA]Ys@a@aBeC\\\\\\\\WWIeHyIuU@mDAo@JMZR|DlMhJlU|BtAnAW|IqDjHmAzWLdFqA`EKnPiB~IE`Dv@jLvJfA`CpBdGrA|BxBlBtEfC~@rAj@lBn@|DnEzb@FhGkClZe@vLBtMK`B[tAqR|^wF~JIlBc@_@]cBi@GYVBnCg@b@s[vFGp@HzDQ\\\\\\\\qAj@W`@GlCaAbI@lDc@h@c@Fa@a@gCmFaGsHk@yAu@iDaA_I_@KoB_TWgMo@iEgCsHqDgHIoTkFyNBi@NWrMuLXm@iCeJmHXy@mEt@Nd@wCGm@]w@Au@jDsZGe@e@m@eDaBwDoCsDeHyAoEgBaJ_AmGm@iIWmJ@kh@DyP@kNVeXRFv@aKjBoP|AkJnCa@BeCM_Ba@B@gCI@NoDXsCBsES_Du@wF`@_Bn@qA`@[x@AhLhBlVvOL?P]r@kEd@GxGlDRVMlBH^`ClApARxAw@ZiANkBImAWcAAeCKk@r@_MrC^TZBl@W|CBdAr@zCl@pA^Xb@Y`@cATmBHcDh@eB~AaCvAIlAx@fA`B|@rCp@vD\\\\\\\\~FOdSNlAd@lAn@d@p@SdEJl@k@r@AbBpAtAzCP`BDxFVhA|@PtEs@j@Xf@dAb@~Bh@bG\\\\\\\\nPMdGmAhSB~YHhCrBvJJbDMvCkAhDUTmCSeB|@aAE[o@k@mCIyDFcGK]i@@kHtGsLvHkAbAwEbFiEtIcCxD@l@VJVWbGmHbCiBhDkAx@TJh@Kh@WT_E`CA`CgHjPy@zBiBlGWbBAt@T|C\\\\\\\\VbBB|Bo@dFkClCAVRj@rBf@t@tEp@Jt@e@hEdAp@",
"resource_state": 2
,
"trainer": false,
"commute": false,
"manual": false,
"private": false,
"visibility": "everyone",
"flagged": false,
"gear_id": "b10078680",
"start_latlng": [
51.50910470634699,
-0.08103674277663231
],
"end_latlng": [
51.4937711879611,
-0.11508068069815636
],
"average_speed": 7.292,
"max_speed": 18.85,
"average_cadence": 91.2,
"average_watts": 147.7,
"max_watts": 577,
"weighted_average_watts": 158,
"kilojoules": 771.3,
"device_watts": true,
"has_heartrate": true,
"average_heartrate": 152.4,
"max_heartrate": 176.0,
"heartrate_opt_out": false,
"display_hide_heartrate_option": true,
"elev_high": 155.6,
"elev_low": 3.0,
"upload_id": 8641662932,
"upload_id_str": "8641662932",
"external_id": "zwift-activity-1205915282304925728.fit",
"from_accepted_tag": false,
"pr_count": 0,
"total_photo_count": 2,
"has_kudoed": false,
"suffer_score": 133.0
]这是一个相当长和详细的活动。该文档可能与你的不同,因为我订阅了 Strava,因此可以使用诸如 suffer_score 之类的字段。让我们一步一步来确定我们在映射中需要关注的内容。
我可以通过观察直接识别出三件事:
- 地理数据存在,start_latlng,end_latlng
- 数字格式是没有引号的
- 字符串也被格式化(引号)
Elasticsearch 有多个映射选项。字符串可以存储为文本(具有可用的子选项,例如 match_only_text)或关键字。不同的是,text 提供了全文搜索的能力,使用关键字(keyword)进行精确匹配。以活动名称为例:“Zwift - in London”。我不认为我将永远需要搜索功能。做一个 keyword 比 text 字段更有意义,它允许唯一的值计数。如果你想知道你的活动中有多少恰好是 “Zwift - in London”,那么你可以使用 keyword。keyword 的缺点是它们需要完全匹配。我无法提供包含 Zwift 的所有活动。我们可以,但我们需要利用通配符搜索,因此在 Kibana 中你可以键入 *Zwift*,从性能的角度来看这不是最佳选择。不过,你可以问问自己,我多久想知道一次,也许在摄取期间,我可以添加一个允许布尔过滤器启动的特定字段。我认为 keyword 是一种有效的方法;每个字符串都应存储为关键字。如何实现?在我解释了其他两个之后,我们将开始动态映射。
地理数据需要特殊处理以确保 Elasticsearch 正确解释它。地理数据有许多不同的已知格式。显然,除了映射之外,我们无事可做。它将获取数组并从中生成一个地理点。
数字将自动作为双精度、长整数进行处理,Elasticsearch 将在第一次看到包含该字段类型的文档时即时决定什么是最匹配的字段类型。
创建索引和映射
现在有了这个,我们可以继续并开始开发我们的索引和映射架构。 我知道数据的总规模很小,很容易放入一个永久存在的索引中。 如果你不是这种情况,我建议你使用应用了索引生命周期管理的数据流。
我将我的索引简称为 strava,这是创建索引和适当映射所需的命令。 转到 Kibana 中的开发工具(Dev Tools)并试一试!
PUT strava
"mappings":
"dynamic_templates": [
"stringsaskeywords":
"match_mapping_type": "string",
"match": "*",
"mapping":
"type": "keyword"
],
"properties":
"data":
"properties":
"latlng":
"type": "geo_point"
,
"segment":
"properties":
"segment":
"properties":
"dest":
"properties":
"geo":
"type": "geo_point"
,
"source":
"properties":
"geo":
"type": "geo_point"
更进一步,我提到我想将任何文本视为 keyword。 这是通过使用 dynamic_template 实现的,我们在其中匹配任何可能的字段,验证它是否为字符串,然后将其映射为关键字。 我们需要启用的第二种映射类型是 geo_point。
用户和角色
我们创建了一个名为 strava 的索引,并定义了映射的内容。 在这篇博文的后面,我们要开始摄取数据,为此我们需要一个具有正确权限的用户!
Elasticsearch 中的角色定义了用户可以做什么。 创建数据、删除数据、修改映射、读取某些字段,甚至读取与查询匹配的文档。 在我们的例子中,我们想要一个允许用户将文档写入索引的角色。
PUT _security/role/strava
"cluster": [
"monitor"
],
"indices": [
"names": [
"strava"
],
"privileges": [
"create"
],
"field_security":
"grant": [
"*"
],
"except": []
,
"allow_restricted_indices": false
],
"applications": [],
"run_as": [],
"metadata": ,
"transient_metadata":
"enabled": true
顺便说一句,我们需要一个使用 strava 角色的用户。 有一个用户 API 可以为我们创建用户。
PUT _security/user/strava
"username": "strava",
"roles": [
"strava"
],
"full_name": "",
"email": "",
"password": "HERESOMETHINGSECURE",
"metadata": ,
"enabled": true
如果你想了解如果使用 UI 界面来创建用户及角色,请阅读文章 “Elasticsearch:用户安全设置”。
索引第一个文档
我们希望保持简单,因此我们将索引我之前展示的活动文档。 为此,我将使用 Python 脚本。 此脚本将在下一篇博文中重复出现,因此请注意任何更改。
from elasticsearch import Elasticsearch, helpers
from datetime import datetime, timedelta
import requests
import json
ELASTIC_PASSWORD = "password_for_strava-User"
CLOUD_ID = "Cloud_ID retrieved from cloud.elastic.co"
client = Elasticsearch(
cloud_id=CLOUD_ID,
basic_auth=("strava", ELASTIC_PASSWORD)
)
ES_INDEX = 'strava'
stravaBaseUrl = "https://www.strava.com/api/v3/"
payload = ""
headers =
"Authorization": "Bearer _authorization_token_acquired_from_strava"
def GetStravaActivities():
url = stravaBaseUrl + "athlete/activities"
querystring = "per_page": "2", "page": "1"
#### ^^^above the `per_page` can be changed to 100
#### You can have 100 requests per 15 minutes, that would give you 1500 activities to retrieve in 15 minutes.
#### Maximum of 1.000 requests per day.
#### after ever run don't forget to increase the page number.
activities = json.loads((requests.request(
"GET", url, data=payload, headers=headers, params=querystring).text))
for activity in activities:
doc =
"_index": ES_INDEX,
"_source":
"@timestamp": datetime.strptime(activity['start_date'].replace('Z','')+activity['timezone'][4:10], '%Y-%m-%dT%H:%M:%S%z').strftime('%Y-%m-%dT%H:%M:%S%z'),
"strava": activity,
"data":
yield doc
helpers.bulk(client, GetStravaActivities())代码本身非常简单。 我们正在尝试执行以下任务:
- 从 Strava 获取活动
- 将它们变成单独的文档
- 使用批量上传机制索引所有文档
helpers.bulk() 是一个很好的帮手,因为它负责创建批量请求,你可以将任何数据生成函数放入其中。
确保批量请求有效所需的唯一代码是创建文档并设置 _index 和 _source。 此代码中的所有其他内容都用于从 Strava 检索文档。
总结
我们现在在 Elasticsearch 中有我们的活动数据。 这很棒,因为它允许我们做比你在 Strava 中做的更多的可视化和向下钻取。 另外,如您所见,上手超级容易!
借助一点 Kibana 的魔力,这个仪表板显示了我去年几个月的痛苦分数(suffer score)、我最喜欢的运动是什么以及我每周进行了多少活动。 这不是很棒吗?
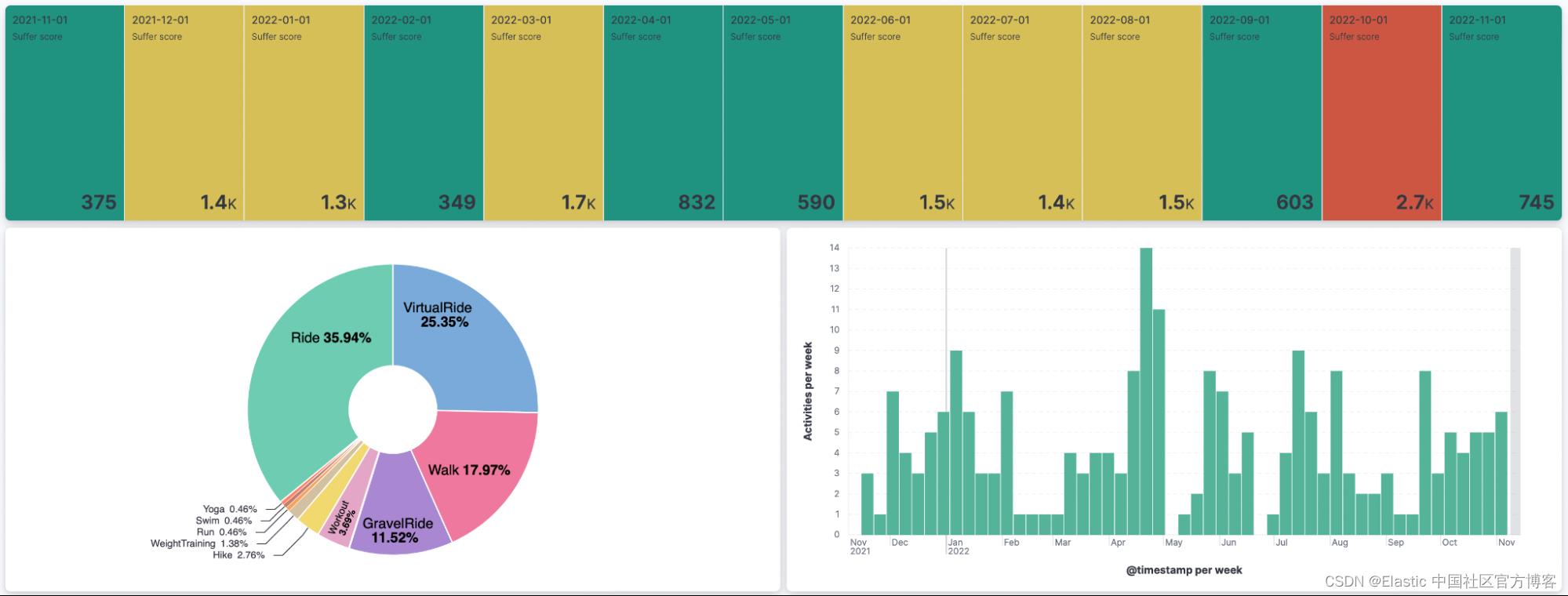
以上是关于Elasticsearch:如何将 Strava 数据导入 Elastic Stack的主要内容,如果未能解决你的问题,请参考以下文章
使用 Strava 提供程序进行 Firebase 身份验证
使用 Google Apps 脚本创建 Strava Webhook 订阅时出现问题