超异构融合:边缘计算腾飞的契机
Posted 边缘计算社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超异构融合:边缘计算腾飞的契机相关的知识,希望对你有一定的参考价值。

内容来源:2022年11月12日,由边缘计算社区主办的全球边缘计算大会·上海站圆满落幕。我们非常荣幸邀请到了上海矩向科技有限公司CEO黄朝波黄总来分享,黄总发表了主题为《超异构融合:边缘计算腾飞的契机》精彩演讲。
分享嘉宾:矩向科技 黄朝波
整理编辑:东北大学 郑童
出品:边缘计算社区


黄朝波:今天,很荣幸到这里跟大家分享我们对边缘计算和超异构融合的一些看法。首先给大家介绍一下今天分享的内容,分五个部分。第一部分先介绍一些计算和算力的相关概念,然后介绍一下目前计算架构面临的各种挑战,第三部分介绍计算会从异构走向超异构,以及行业TOP公司的一些相关趋势案例,接下来介绍为什么现在发展超异构计算,而不是过去也不是未来,最后介绍超异构融合如何助力边缘计算的发展。
1、
微观计算和宏观算力
第一个就是大家非常熟悉的冯诺依曼架构。说个笑话,怎么把大象装进冰箱?第一步打开冰箱门,第二步把大象放进去,第三步把冰箱门关上。其实计算也是一样,系统由输入、计算、输出三部分组成。
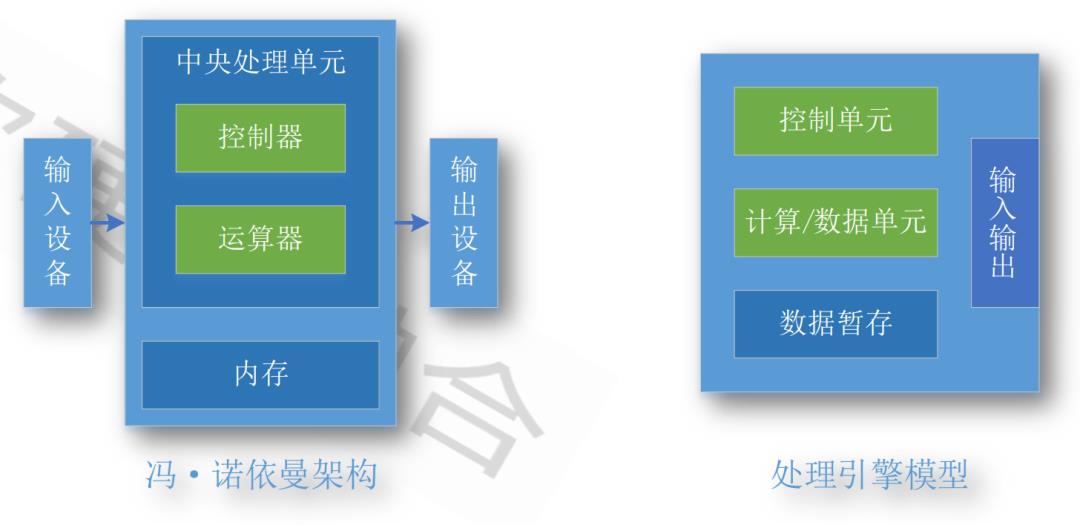
图1-冯诺依曼架构
冯诺依曼架构由控制器、运算器、存储器、输入设备和输出设备五部分组成。所有各类处理引擎都依然遵循冯诺依曼架构的指导思想。
第二个是我们非常熟悉的摩尔定律。上世纪八九十年代,CPU的性能每18个月性能就会翻倍,这就是著名的摩尔定律。
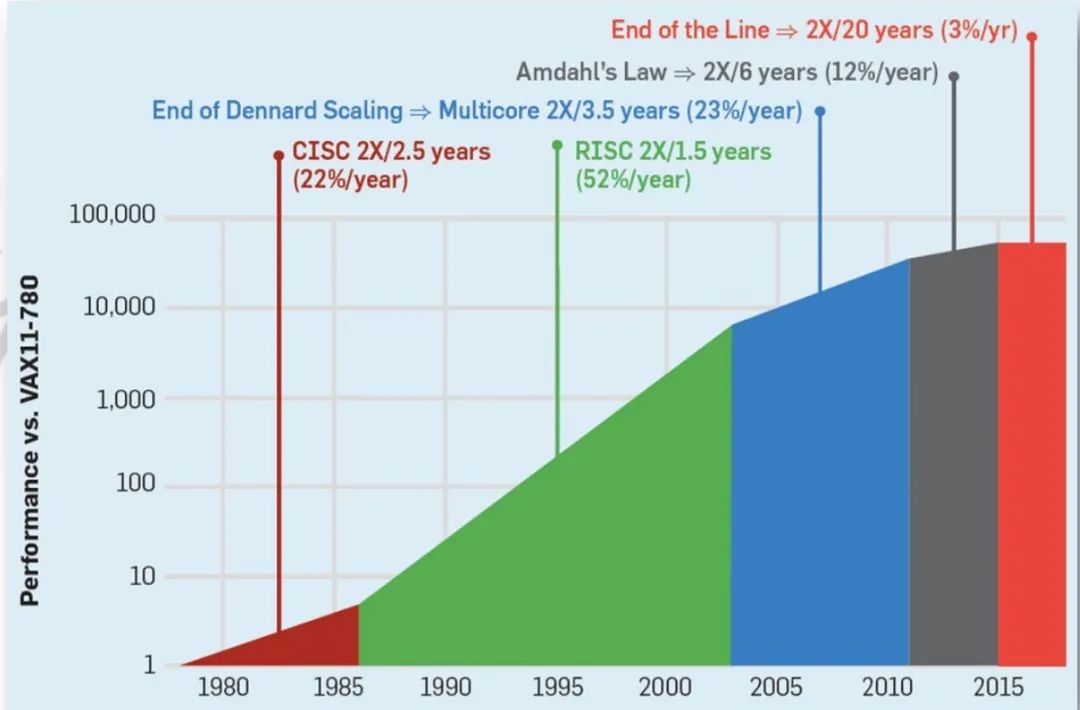
图2-摩尔定律
2015年之后,随着CPU性能走到极限,目前大概每年只能提升3%左右,要想性能翻倍需要20年时间。基于CPU这样的处理器性能的摩尔定律已经失效,但是换一个视角来看,因为我们的计算,我们的业务,我们的场景需求不断推升我们对性能要求的时候,性能的要求是永无止境的。因此,摩尔定律作为一个行业的KPI是永远有效的,它促使行业一直往前发展。如果一个公司或产品能够做得比摩尔定律好,就能够生存,如果做得比摩尔定律差,则只能走向消亡。
第三讲一下什么是软件,什么是硬件。指令是软件和硬件的媒介。指令集之下的CPU、GPU、各种加速器是硬件;指令集之上的程序,数据集,文件等是软件。我们可以依据指令的复杂度,把处理器从左往右排一个序。最左边是CPU,最右边是ASIC。最左边最灵活,性能相对来说最差;最右边最不灵活,性能相对来说最好。我们把CPU上的运行称之为软件运行,其他处理器加速引擎上运行的称之为硬件加速运行。
再看一下性能和算力的关系,性能是相对微观的概念,算力是宏观的概念,性能和算力本质上是统一的。所以我们给了一个非常粗略的计算公式,实际的总算力等于单个处理器性能乘以处理器数量再乘以利用率。要想实现算力的提升,仅仅提升单芯片的能力是不够的。还需要让芯片大规模落地,与此同时芯片所组成的算力系统要有非常高的利用率才可以。也基于此,这三个参数形成了我们对算力优化的三个层次,也就是微观、中观和宏观。微观层次要提升性能有三种方法,工艺提升、Chilpet直接封装,还有系统架构和微架构的创新。中观层次,芯片层次怎么去支撑芯片大规模落地,怎么去大规模复制这样一个系统。再往更上面是宏观,怎么驾驭算力,算力如何形成一个非常大、用户好用的算力资源池子,用户能够充分利用算力资源池形成各方面加速化的应用,都是些非常有挑战的事情。
接下里,我们来看万物互联。我们可以把它说得简单一点,只有三个层次,云、边、端。这里把网络忽略了,网络是另外一个相对更复杂的话题。终端是我们物理世界和虚拟世界的一个交互点,所有的东西都通过终端去连接。云端相当于我们的大脑,进行集中式的决策分析。边缘端是代理层,代理云端为终端去提供服务。
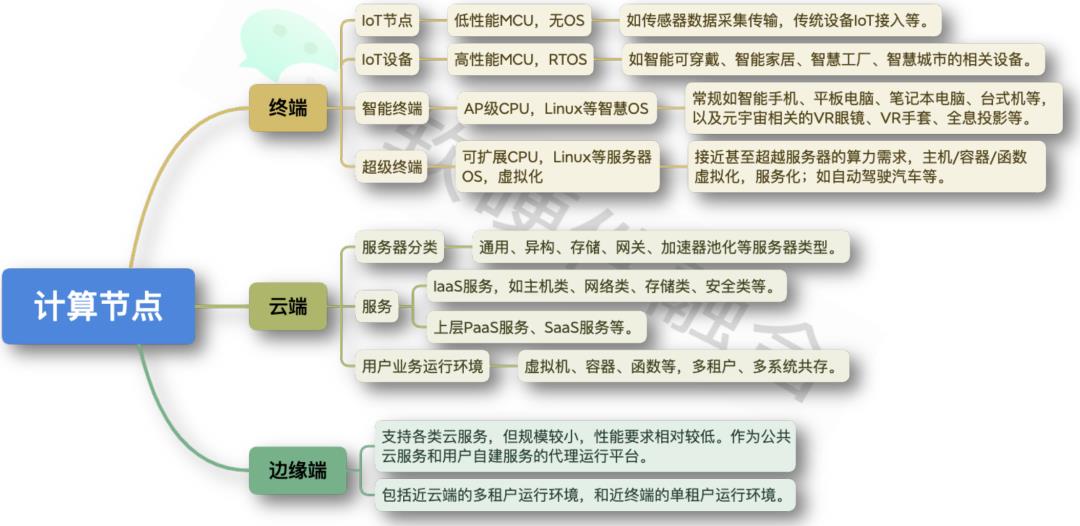
图3:计算节点的分类
我们把计算的节点按照上图3来划分。终端大概有四个层次的节点,最简单的是小规模MCU层次,其不需要安装操作系统。往上是高性能MCU,需要RTOS。再往上就像手机、Pad、平板电脑,需要运行操作系统来跑我们各种各样的应用。再往上,我们需要让很多系统共同地运行同一个平台,目前最典型的场景就是自动驾驶,形成多域融合的一种架构。在云端,服务器会有很多分类,通用的,异构的,存储的,网关的等等。这里需要提一个概念——用户运行环境。因为底层的基础设施做好之后,用户的东西需要在上面运行。当然,边缘也分为两个层次,一个是近云的边缘和近终端的边缘。两者最大的区别就是是否支持多租户运行,是否是多个不同混合系统的运行。
2、
计算架构的发展现状和面临的挑战
接下来介绍第二部分,目前计算的架构的现状和我们面临的挑战。我们大家都知道,最开始处理器CPU是单核的,宏观来看指令都是串行执行的,后来有了多核,所以有了并行计算。同构的并行也不够,因为它的性能还是存在一些问题,就有了异构并行。异构并行目前有三个典型的类型,一个是基于GPU的异构,一个是基于FPGA的异构,一个是基于DSA的异构。异构计算目前更多地应用在弹性的应用层次异构的场景,弹性体现在哪里?首先体现在一个硬件的加速引擎,能在很多场景,很多领域去用。另外一个弹性的点是指一个硬件的加速引擎,我可以给用户A用,可以给用户B用,也可以给用户C用,可以是分时的甚至是同时的,对弹性要求非常高。当然,异构可以是独立的异构芯片也可以是集成的异构处理器。
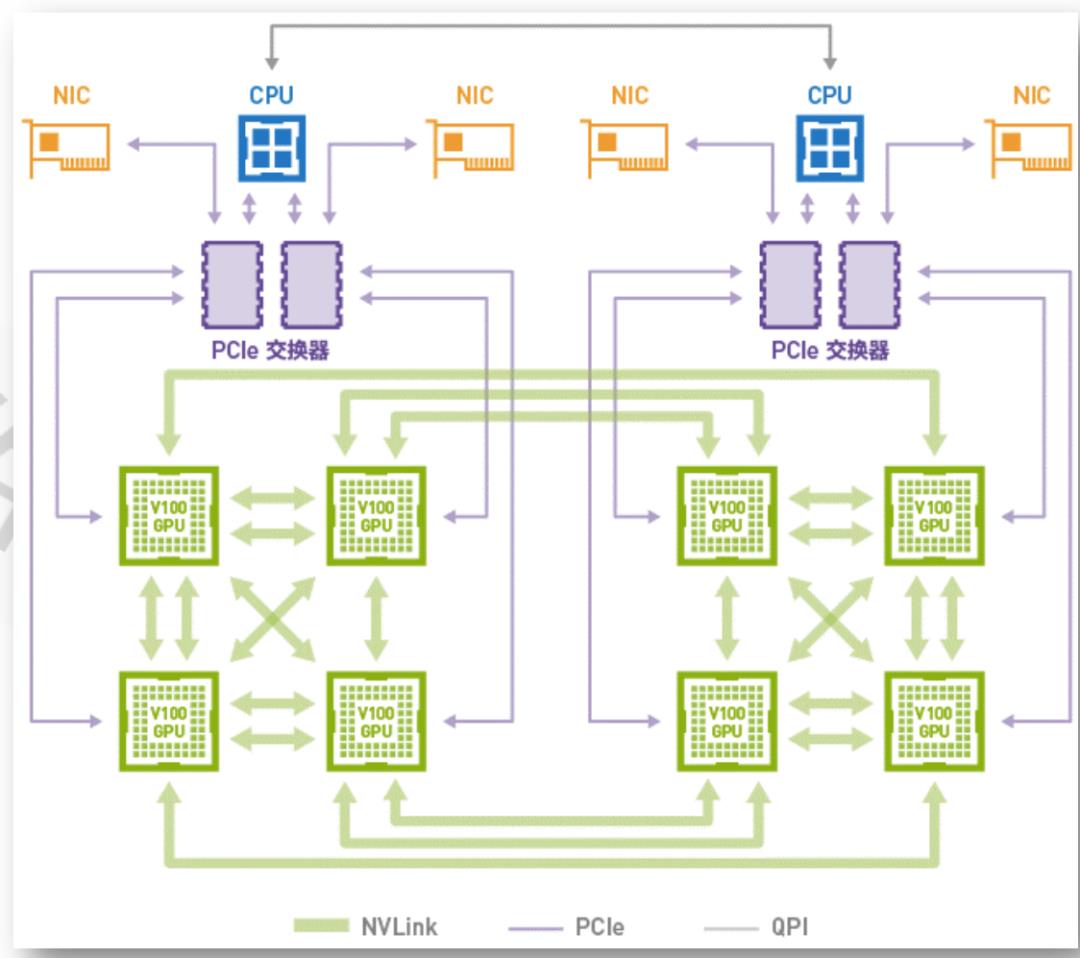
图4-GPU服务器
异构的案例最经典的就是用于AI场景、各种大数据分析的GPU服务器。异构还有很多其他典型的案例,比如国防科大的天河巨型机,首次把异构计算用在超算领域;还有各种AI处理器。现在的GPU的优势是它的灵活性非常地好。在目前最典型的AI场景来说,GPU是最合适的计算平台。它的劣势在哪里呢?它的性能效率还不是最优的,还有更优的,但是更优的也有它的问题所在,所以GPU目前是最合适的。
基于此,目前遇到的最大的问题其实是CPU的问题,是从CPU性能瓶颈开始引发的连锁反应。这里提一个复杂计算的概念,通俗易懂地讲,复杂计算就是需要支持虚拟化,需要支持多租户多系统运行的计算场景。在我们的工作中发现,在云计算、边缘计算以及超级终端的复杂计算场景,对灵活性的要求远高于对性能的要求。举个最直接的例子,如果CPU的性能够用,大家绝对不喜欢用各种加速。CPU通用灵活性是最好的,但是如果CPU性能不够,就不得不去运行各种加速。实践证明了在提升性能的同时,一定不能损失系统的灵活性。言下之意就是目前很多芯片的优化方案,特别是AI芯片等加速芯片的优化方案损失了灵活性,这也是目前行业的痛点之所在。
总结一下异构计算存在的问题。刚提到的复杂计算矛盾点在于,一方面系统越复杂越需要灵活性,另一方面对性能要求越高,反而要定制的专用的加速器。矛盾的本质核心在哪里呢?我们认为是在单一的处理器无法兼顾性能和灵活性,要么是优先考虑灵活性,要么优先考虑性能,两者之间很难做到兼顾,只能去平衡它。要想兼顾它,怎么办?是要多异构混合,也就是大家相互协同。举一个案例,我们的异构计算核心的整个特征是由异构的处理器决定的。GPU性能不够,DSA的灵活性差了一些,FPGA功耗和成本高,ASIC在复杂计算场景完全不可用,还有计算孤岛的问题。
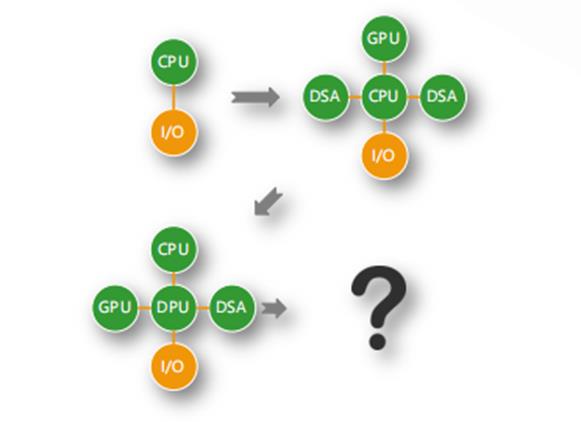
图5:服务器的架构演进示意图
如图5所示,最开始都在CPU里面算,除了性能之外没有其他问题。后来有了各种加速,最后发现CPU成为问题的瓶颈。最后有了DPU,部分解决了问题,因为DPU可以做I/O的加速。但是DPU没有本质地解决问题,需要整个系统更充分地互联,每个处理器跟别的处理器都能够更加充分高效地交互。在后面我们会给出一个答案。
3、
计算从异构走向超异构及相关趋势案例
第三部分,给出我们的观点,计算需要从异构走向超异构。与此同时,我们也介绍了一下英特尔和英伟达相关趋势的案例。
第一步,我们首先在思考,为什么超异构这件事情能够成立呢?
①因为现在计算超大的规模,因为有了规模之后很多东西会沉淀下来。②复杂的系统其实是由分层分块的东西组成,分层分块之后,底层相对更加通用一些。③这里就会呈现出二八定律。
基于此,我们把系统分为三个层次,一个是最底层的基础设施层,一个是上层的应用层。基础设施层是相对最确定的,应用层是相对最不确立的。中间的就是应用层可以剥离出来的可加速的部分。我们分为这三个层次。
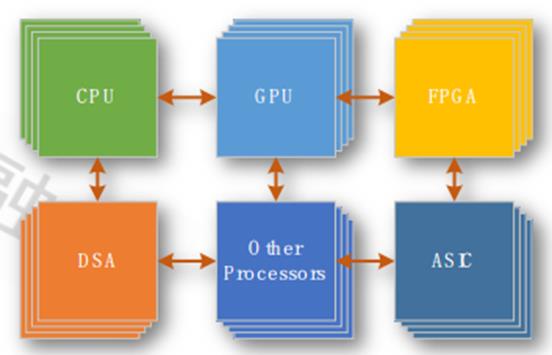
图6:超异构计算有机整体
计算就开始从异构走向超异构。我们再来看计算的四个阶段。第一个阶段是单系统串行,第二个阶段是同构并行,第三个阶段是异构并行,第四个阶段是超异构并行。图3是一个示意图,把这些东西充分地互联在一起。每一个处理引擎之间都是可以点对点互联的、充分的数据交互的。
接下来看一下案例,超异构这个概念是英特尔提出来的。我们在网上找到的最早的资料是2019年Intel中国研究院院长宋继强先生提出来的,但是目前Intel还没有超异构相关的产品出来,或者说目前都是偏组件的产品。其提出XPU和oneAPI,XPU包括CPU、GPU、FPGA和其他的加速器,然后在XPU上通过oneAPI把应用跨不同的平台去运行。
再就是Intel所做的IPU基础设施处理器,对应英伟达的DPU。它的最核心特点是支持P4可编程包处理DSA、RoCEv2,在IPU基础上做了一个IPDK框架,它是一个完全open的接口,完全开源的框架,因此形成了一个超异构的生态,非常有价值。基于此Intel跟Linux基金会成立了OPI联盟。这里面有一个非常重要的点,如果超异构由底层的DSA中间的GPU和上层的CPU共同组成的话,其中CPU生态和GPU生态已经存在,最关键的点在于底下的DSA,即基础设施层生态。因此,谁把握了这个生态,谁就是未来最大的赢家。我们对Intel的超异构进行了分析。首先其各类引擎是成熟的,只是缺乏整合。接下来怎么把这个东西整合成一个超异构,跨平台已经有了XPU和OneAPI,可编程是Intel提出的可编程网络,我们把这个概念扩展一下,网络可编程、计算可编程、存储可编程,一切皆可编程,这是Intel的整体战略。
对于英伟达的一些做法,其在9月份刚刚发布了Thor芯片,终端的自动驾驶芯片,达到了2000 TFLOPS算力,这个算力非常恐怖,能把多个域控制器的能力集中到一起,单芯片解决问题。在自动驾驶终端目前最大的趋势是从数以百颗的ECU到数十颗的DCU,再到功能融合的超级单芯片,该趋势很明显。图7为Atlan架构示意图,Thor是Atlan的升级版。大家可以清晰地看到里面就是CPU、GPU和DPU共同组成的,而且这个架构和云端的架构一模一样,区别只是规格有所不一样而已。这不是一个SOC,SOC是单系统,而Thor是多系统混合的平台,而且它的算力灵活性、弹性能力远高于SOC。NVIDIA在数据中心目前已经有CPU加GPU的集成芯片,也将有DPU加GPU的集成芯片,在终端已经完成了整合的过程,在数据中心这个事情也是可预见的。
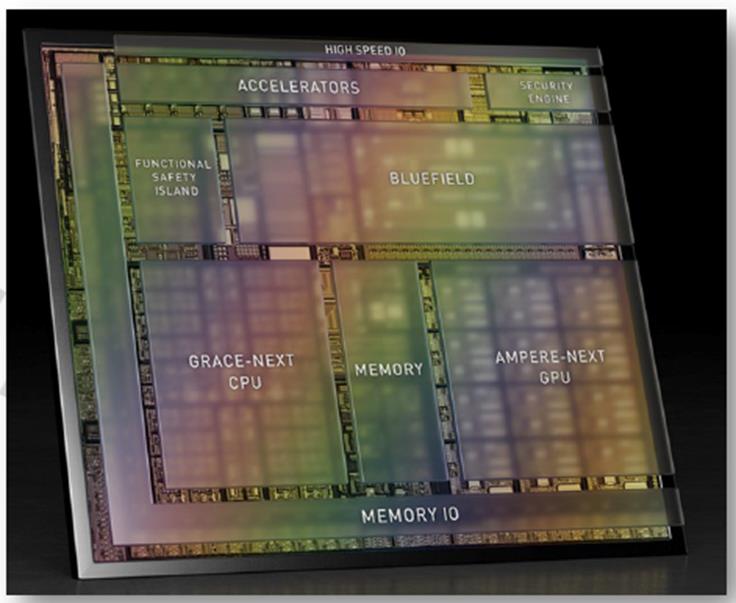
图7:Atlan架构示意图
最后讲一下英伟达目前对未来走势的看法,这个观点是很多英伟达多位技术专家的看法整理而来。他们认为计算和网络不断融合,计算的许多挑战需要网络的协同,网络同时也是计算机,其加入到计算集群成为计算的一部分。数据是在网络中流动,计算设备是网络中的一个数据处理的节点而已,这样所有设备都是DPU。以DPU为基础,不断融合CPU和GPU的能力,就变成了我们所认为的超异构处理器。这个观点说明,英雄所见都是略同的。
4、
为什么是现在
我们从几个大的背景来说明为什么是现在来做这件事。
第一个就是新应用层出不穷,前几年的自动驾驶、区块链,现在的元宇宙,AI已经是很多年前的概念了。两年一个新热点,已有的热点仍在不断演进。也因此,系统对我们而言,一直处于变化中。面对变化,我们需要开发高度灵活的,并且还需要性能数量级提升的芯片系统。
再然后就是算力需求永无止境,永远不会有够用的时候。任何时候,都是硬件制约了软件的想象力。Intel一位VP说,元宇宙需要千倍的算力提升。这里举两个案例,一个是VR头盔,如果要实现沉浸感的16K效果,需要280Gbps的带宽,目前的网络、计算、存储基础设施都无法处理这么高的数据量。还有一个就是智能AI,现在AI模型越来越大,单个AI的算力要求也是迅猛增加,并且元宇宙对数字人的数量要求也很庞大,这对算力的要求是及其恐怖的,目前的算力基础设施还很难达到。
还有工艺和封装的进步,像最新的Chiplet技术,可以让计算规模成数量级的提升。Chiplet和超异构可以说是天生一对,超异构需要成规模提升的算力,刚好Chiplet提供了这样的能力。反过来,Chiplet需要更高的价值去变现,现在Chiplet只能百分比或者线性地提升性能,而超异构可以指数级地提升性能,让Chiplet价值最大化。。
还有超异构驾驭的问题,异步编程很难,超异构编程是难上加难。可以利用软件融合方便地提高灵活性、可编程及易用性、产品弹性。通过软硬件融合驾驭超异构,可以实现超异构的顺利落地。
5、
超异构融合,助力边缘计算腾飞
最后,呼应我们今天的主题,边缘计算。这里谈一下我们对边缘计算的看法,可能有不对之处,请大家多指正。我们认为边缘计算和CDN很像,区别在于CDN是只读的。边缘计算不是,数据到本地之后需要计算,然后再同步的云端,导致的数据一致性和冲突问题会非常恐怖。
还有云网边端融合挑战,一切皆服务,未来云端也好,边缘端也好,终端也好,网络端也好,微服务都可以随意运行。这样,计算的资源就形成庞大的统一计算池。云网边端,面临的算力是异质的,架构形态不一样、尺寸也不一样,这些都是需要去打通的。
总结一下边缘计算的特征。边缘计算是典型的复杂计算场景,其需要支持轻量的IaaS,需要支持容器,更关键的是边缘计算是一个Serverless,并且服务具有显著的可移动性,比如无论汽车开到哪里,提供的服务都一定是跟以前一模一样。还有一个更核心的问题,就是边缘侧对性能和成本更加敏感。
基于此,我们认为服务器的架构演进,如图8,复杂计算场景,其架构演进趋势是:从合到分,再从分到合。最终要形成的是网状的超异构算力。图的右边是详细的服务器架构演进,左边是一个示意图。未来,数据中心会重新走向融合型单芯片解决方案,即超异构处理器。
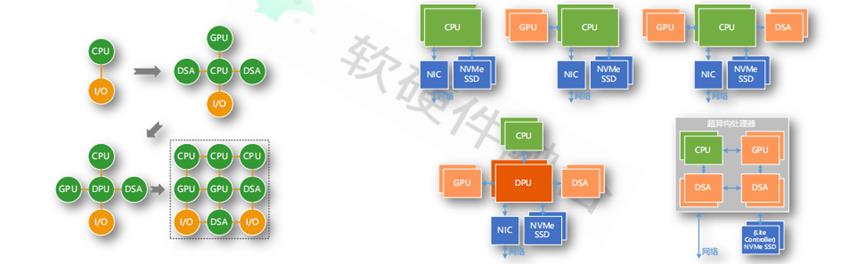
图8:服务器的架构演进
那么,超异构芯片大概有哪些功能,通俗地来说就是现在的DPU、GPU和CPU功能的集合。如图9所示,最底下是一些服务,上面是虚拟化的管理、弹性存储、弹性网络还有安全。再往上弹性计算,AI,其他的加速。这就是支撑VM、容器、函数计算的一个平台,并且计算过程中,一些敏感性能的东西也能够放到底下的弹性加速里面对它进行加速。

图9:超异构融合芯片的主要功能
目前来说,GP-HPU主要适合于一些轻量级场景,比如相对云端计算更轻量的边缘计算,同时对性能价格比也更加敏感。有过测算,边缘计算服务器数量会占到服务器数量的80%。GP-HPU把很多芯片能力融合到一块,让性能显著提升一个数量级,让成本降低一倍以上。
单DIE芯片的GP-HPU,可以用在一些轻量级的场景,通过Chiplet集成实现的GP-HPU则可以覆盖重量级服务器的场景。两个芯片规格可以实现服务器类型的全覆盖。
展望一下,超异构既可以放在边缘侧,也可以放在云端,甚至可以放在超级终端,想象空间很大。通过各类功能的超异构融合,实现综合最优的单芯片解决方案。
我的介绍就到这里,请大家多多指正,谢谢!

全球边缘计算大会讲师演讲材料已出,欢迎戳下方链接查看现场精彩回放!



以上是关于超异构融合:边缘计算腾飞的契机的主要内容,如果未能解决你的问题,请参考以下文章