文件下载解决方案
Posted ArthurKingYs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文件下载解决方案相关的知识,希望对你有一定的参考价值。
转自
https://www.tuicool.com/articles/JNbUjmu
一、业务背景
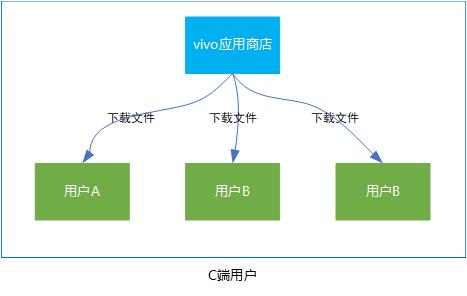
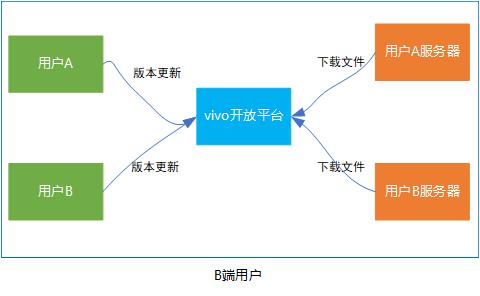
目前,vivo 平台有很多的业务都涉及到文件的下载:譬如说应用商店、游戏中心的C端用户下载更新应用或游戏;开放平台B端用户通过接口传包能力更新应用或游戏,需要从用户服务器上下载apk、图片等文件,来完成用户的一次版本更新。
二、面临的挑战
针对上述C端用户,平台需要提供良好的下载环境,并且客户端需要兼容手机上用户的异常操作。
针对上述B端用户,平台亟需解决的问题就是从用户服务器上,拉取各种资源文件。
下载本身也是一个很复杂的问题,会涉及到网络问题、URL重定向、超大文件、远程服务器文件变更、本地文件被删除等各种问题。这就需要我们保证平台具备快速下载文件的能力,同时兼具有有对异常场景的快速预警、容错处理的机制。
三、业务实现方案
基于前面提到的挑战,我们设计实现方案的时候,引用了行业常用的解决方法:断点下载。
针对B端用户场景,我们的处理方案入下图:
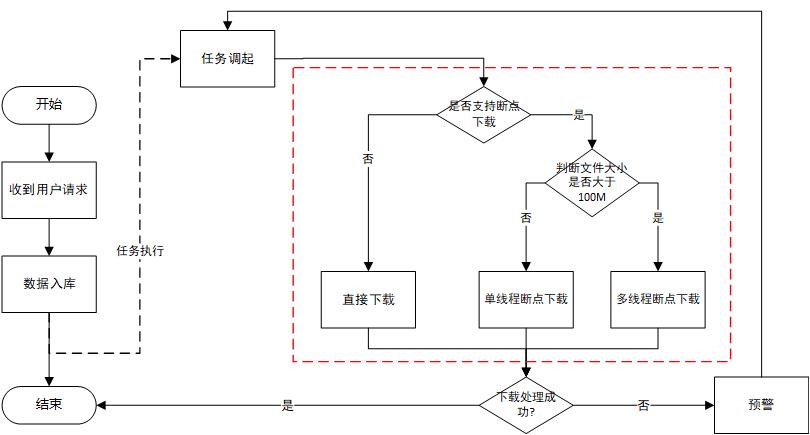
一、极速下载:通过分析文件大小,智能选择是否采用直接下载、单线程断点下载、多线程断点下载的方案;在使用多线程下载方案时,对"多线程"的使用,有两种方式:
-
分组模式:单个文件采用固定最大N个线程来进行下载,分组的好处是能保证服务节点线程数量可控,劣势就是遇到大文件的时候,下载耗时相对会比较长;
-
分片模式:采用单个线程,固定下载N个字节大小空间,分片的好处是遇到大文件的时候,下载耗时仍然会相对短,劣势是会导致服务器节点线程数量突增,对服务节点稳定性有干扰;
在二者之间,我们选择了分组模式。
二、容错处理:在我们处理下载过程中,会遇到下载过程中网络不稳定、本地文件删除,远程文件变更等各种场景,这就需要我们能够兼容处理这些场景,失败后的任务,会有定时任务自动重新调起执行,也有后台管理系统界面,进行人工调起;
三、完整性校验:文件下载完成之后,需要对文件的最终一致性做校验,来确保文件的正确性;
四、异常预警:对于单次任务在尝试多次下载操作后仍然失败的情况,及时发起预警警告。
对于C端用户,业务方案相对更简单,因为文件服务器有vivo平台提供,网络环境相对可控,这里就不再赘述。接下来,我们将对文件下载里面的各种技术细节,进行详尽的剖析。
四、断点下载原理剖析
在进行原理分析前,先给大家普及一下,什么叫断点下载?相信大家都有过使用迅雷下载网络文件的经历吧,有没有注意到迅雷的下载任务栏里面,有一个“暂停”和“开始下载”按钮,会随着任务的当前状态显示不同的按钮。当你在下载一个100M的文件,下载到50M的时候,你点击了“暂停”,然后点击了“开始下载”,你会发现文件的下载竟然是从已经下载好的50M以后接着下载的。没错,这就是断点下载的真实应用。
4.1 HTTP 断点下载之秘密:Range
在讲解这个知识点前,大家有必要了解一下http的发展历史,HTTP(HyperText Transfer Protocol),超文本传输协议,是目前万维网(World Wide Web)的基础协议,已经经历四次的版本迭代:HTTP/0.9,HTTP/1.0,HTTP/1.1,HTTP/2.0。在HTTP/1.1(RFC2616)协议中,定义了HTTP1.1标准所包含的所有头字段的相关语法和含义,其中就包括咱们要讲到的Accept-Ranges,服务端支持范围请求(range requests)。有了这个重要的属性,才使得我们的断点下载成为可能。
| HTTP 版本 | 描述 | 是否支持断点下载 |
| HTTP/0.9 | 单行协议 | 否 |
| HTTP/1.0 | 构建可扩展性 | 否 |
| HTTP/1.1 | 标准化协议 | 是 |
| HTTP/2.0 | 为了更优异的表现 | 是 |
基于HTTP不同版本之间的适配性,所以当我们在决定是否需要使用断点下载能力的时候,需要提前识别文件地址是否支持断点下载,怎么识别呢?方法很多,如果采用curl命令,命令为:curl -I url
CURL验证是否支持范围请求:
如果服务端的响应信息里面包含了上图中Accept-Ranges: bytes,这个属性,那么说该URL是支持范围请求的。如果URL返回消息体里面,Accept-Ranges: none 或者压根就没有 Accept-Ranges这个属性,那么这个URL就是不支持范围请求,也就是不支持断点下载。
前面我们有看到,当使用curl命令获取URL的响应时,服务端返回了一大段文本信息,我们要实现文件的断点下载,就要从这些文本信息里面获取咱们断点下载需要的重要参数,有了这些参数后才能实现我们想要达到的效果。
| 属性 | 属性值 | 描述 |
| Accept-Ranges | bytes|none | URL是否支持 断点下载 |
| Content-Length | 数字类型 | 文件的大小 |
| Content-Type | application/octet-stream|image/png等 | 文件类型 |
| Etag | 32位字符串 | 资源版本的标识符,通常是消息摘要 |
| Last-Modified | 时间 | 资源最近修改的时间 |
4.2 HTTP 断点下载之Range语法说明
HTTP/1.1 中定义了一个 Range 的请求头,来指定请求实体的范围。它的范围取值是在 0 - Content-Length 之间,使用 - 分割
| 语法 | 达到效果 |
| 100-200 | 指定区间范围 |
| 100- | 指定开始区间,一直到文件结束 |
| -100 | 无开始区间,说明是只需要最后的100字节的内容信息 |
| 100-200,200-300 | 指定多个范围,分段下载 |
4.2.1 单区间段范围请求
curl https://swsdl.vivo.com.cn/appstore/test-file-range-download.txt -i -H "Range: bytes=0-100"HTTP/1.1 206 Partial ContentDate: Sun, 20 Dec 2020 03:06:43 GMTContent-Type: text/plainContent-Length: 101Connection: keep-aliveServer: AliyunOSSx-oss-request-id: 5FDEBFC33243A938379F9410Accept-Ranges: bytesETag: "1FFD36BD1B06EB6C287AF8D788458808"Last-Modified: Sun, 20 Dec 2020 03:04:33 GMTx-oss-object-type: Normalx-oss-hash-crc64ecma: 5148872045942545519x-oss-storage-class: StandardContent-MD5: H/02vRsG62woevjXiEWICA==x-oss-server-time: 2Content-Range: bytes 0-100/740X-Via: 1.1 PShnzssxek171:14 (Cdn Cache Server V2.0), 1.1 x71:12 (Cdn Cache Server V2.0), 1.1 PS-FOC-01z6n168:27 (Cdn Cache Server V2.0)X-Ws-Request-Id: 5fdebfc3_PS-FOC-01z6n168_36519-1719Access-Control-Allow-Origin: *
4.2.2 多区间段范围请求
curl https://swsdl.vivo.com.cn/appstore/test-file-range-download.txt -i -H "Range: bytes=0-100,200-300"HTTP/1.1 206 Partial ContentDate: Sun, 20 Dec 2020 03:10:27 GMTContent-Type: multipart/byteranges; boundary="Cdn Cache Server V2.0:37E1D9B3B2B94DF2F1D84393694C7E8A"Content-Length: 506Connection: keep-aliveServer: AliyunOSSx-oss-request-id: 5FDEC030BDB66C33302A497EAccept-Ranges: bytesETag: "1FFD36BD1B06EB6C287AF8D788458808"Last-Modified: Sun, 20 Dec 2020 03:04:33 GMTx-oss-object-type: Normalx-oss-hash-crc64ecma: 5148872045942545519x-oss-storage-class: StandardContent-MD5: H/02vRsG62woevjXiEWICA==x-oss-server-time: 2Age: 1X-Via: 1.1 xian23:7 (Cdn Cache Server V2.0), 1.1 PS-NTG-01KKN43:8 (Cdn Cache Server V2.0), 1.1 PS-FOC-01z6n168:27 (Cdn Cache Server V2.0)X-Ws-Request-Id: 5fdec0a3_PS-FOC-01z6n168_36013-8986Access-Control-Allow-Origin: *--Cdn Cache Server V2.0:37E1D9B3B2B94DF2F1D84393694C7E8AContent-Type: text/plainContent-Range: bytes 0-100/740--Cdn Cache Server V2.0:37E1D9B3B2B94DF2F1D84393694C7E8AContent-Type: text/plainContent-Range: bytes 200-300/740
看完上述请求的响应结果信息,我们发现使用单范围区间请求时:Content-Type: text/plain,使用多范围区间请求时:Content-Type: multipart/byteranges; boundary="Cdn Cache Server V2.0:37E1D9B3B2B94DF2F1D84393694C7E8A",并且在尾部信息里面,携带了单个区间片段的Content-Type和Content-Range。另外,不知道大家有没有发现一个很重要的信息,咱们的HTTP响应的状态并非我们预想中的200,而是HTTP/1.1 206 Partial Content,这个状态码非常重要,因为它标识着当次下载是否支持范围请求。
4.3 异常场景之资源变更
有一种场景,不知道大家有没有思考过,就是我们在下载一个大文件的时候,在未下载完成的时候,远程文件已经发生了变更,如果我们继续使用断点下载,会出现什么样的问题?结果当然是文件与远程文件不一致,会导致文件不可用。那么我们有什么办法能够在下载之前及时发现远程文件已经变更,并及时进行调整下载方案呢?解决方法其实上面有给大家提到,远程文件有没有发生变化,有两个标识:Etag和Last-Modified。二者任意一个属性均可反应出来,相比而言,Etag会更精准些,原因如下:
-
Last-Modified只能精确到秒级别,如果一秒内文件进行了多次修改,时间不会发生更新,但是文件的内容却已经发生了变更,此时Etag会及时更新识别到变更;
-
在不同的时间节点(超过1秒),如果文件从A状态改成B状态,然后又重B状态改回了A状态,时间会发生更新,但是相较于A状态文件内容,两次变更后并没又发生变化,此时Etag会变回最开始A状态值,有点类似咱们并发编程里面常说的ABA问题。
如果我们在进行范围请求下载的时候,带上了这两个属性中的一个或两个,就能监控远程文件发生了变化。如果发生了变化,那么区间范围请求的响应状态就不是206而是200,说明它已经不支持该次请求的断点下载了。接下来我们验证一下Etag的验证信息,我们的测试文件:ETag: "1FFD36BD1B06EB6C287AF8D788458808",然后我们将最后一个数值8改成9进行验证,验证如下:
文件未变更:
curl -I --header 'If-None-Match: "1FFD36BD1B06EB6C287AF8D788458808"' https://swsdl.vivo.com.cn/appstore/test-file-range-download.txtHTTP/1.1 304 Not ModifiedDate: Sun, 20 Dec 2020 03:53:03 GMTContent-Type: text/plainConnection: keep-aliveLast-Modified: Sun, 20 Dec 2020 03:04:33 GMTETag: "1FFD36BD1B06EB6C287AF8D788458808"Age: 1X-Via: 1.1 PS-FOC-01vM6221:15 (Cdn Cache Server V2.0)X-Ws-Request-Id: 5fdeca9f_PS-FOC-01FMC220_2660-18267Access-Control-Allow-Origin: *
文件已变更:
curl -I --header 'If-None-Match: "1FFD36BD1B06EB6C287AF8D788458809"' https://swsdl.vivo.com.cn/appstore/test-file-range-download.txtHTTP/1.1 200 OKDate: Sun, 20 Dec 2020 03:53:14 GMTContent-Type: text/plainContent-Length: 740Connection: keep-aliveServer: AliyunOSSx-oss-request-id: 5FDEC837E677A23037926897Accept-Ranges: bytesETag: "1FFD36BD1B06EB6C287AF8D788458808"Last-Modified: Sun, 20 Dec 2020 03:04:33 GMTx-oss-object-type: Normalx-oss-hash-crc64ecma: 5148872045942545519x-oss-storage-class: StandardContent-MD5: H/02vRsG62woevjXiEWICA==x-oss-server-time: 17X-Cache-Spec: YesAge: 1X-Via: 1.1 xian23:7 (Cdn Cache Server V2.0), 1.1 PS-NTG-01KKN43:8 (Cdn Cache Server V2.0), 1.1 PS-FOC-01vM6221:15 (Cdn Cache Server V2.0)X-Ws-Request-Id: 5fdecaaa_PS-FOC-01FMC220_4661-42392Access-Control-Allow-Origin: *
结果显示:当我们使用跟远程文件一致的Etag时,状态码返回:HTTP/1.1 304 Not Modified,而使用篡改后的Etag后,返回状态200,并且也携带了正确的Etag返回。所以我们在使用断点下载过程中,对于这种资源变更的场景也是需要兼顾考虑的,不然就会出现下载后文件无法使用情况。
4.4 完整性验证
文件在下载完成后,我们是不是就能直接使用呢?答案:NO。因为我们无法确认文件是否跟远程文件完全一致,所以在使用前,一定要做一次文件的完整性验证。验证方法很简单,就是咱们前面提到过的属性:Etag,资源版本的标识符,通常是消息摘要。带双引号的32位字符串,笔者验证过,该属性移除双引号后,就是文件的MD5值,大家知道,文件MD5是可以用来验证文件唯一性的标识。通过这个校验,就能很好的识别解决本地文件被删除、远程资源文件变更的各类非常规的业务场景。
五、实践部分
5.1 单线程断点下载
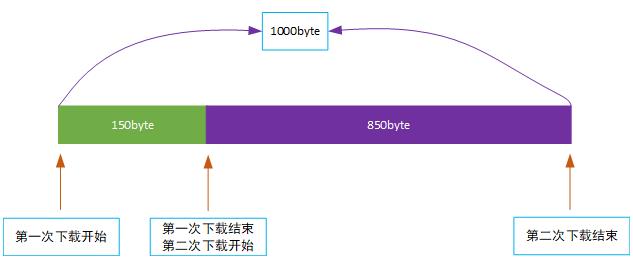
假如我们需要下载1000个字节大小的文件,那么我们在开始下载的时候,首先会获取到文件的Content-Length,然后在第一次开始下载时,会使用参数:
httpURLConnection.setRequestProperty("Range", "bytes=0-1000");
当下载到到150个字节大小的时候,因为网络问题或者客户端服务重启等情况,导致下载终止,那么本地就存在一个大小为150byte的不完整文件,当我们服务重启后重新下载该文件时,我们不仅需要重新获取远程文件的大小,还需要获取本地已经下载的文件大小,此时使用参数:
httpURLConnection.setRequestProperty("Range", "bytes=150-1000");
来保证我们的下载是基于前一次的下载基础之上的。图示:
5.2 多线程断点下载
多线程断点下载的原理,与上面提到的单线程类似,唯一的区别在于:多个线程并行下载,单线程是串行下载。
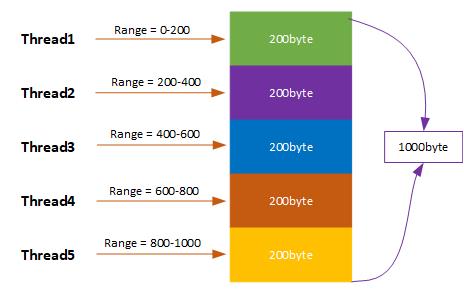
5.3 代码示例
5.3.1 获取连接
在下载前,我们需要获取远程文件的HttpURLConnection 连接,如下:
/*** 获取连接*/private static HttpURLConnection getHttpUrlConnection(String netUrl) throws ExceptionURL url = new URL(netUrl);HttpURLConnection httpURLConnection = (HttpURLConnection) url.openConnection();// 设置超时间为3秒httpURLConnection.setConnectTimeout(3 * 1000);// 防止屏蔽程序抓取而返回403错误httpURLConnection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");return httpURLConnection;
5.3.2 是否支持范围请求
在进行断点下载开始前,我们需要判断该文件,是否支持范围请求,支持的范围请求,我们才能实现断点下载,如下:
/*** 判断连接是否支持断点下载*/private static boolean isSupportRange(String netUrl) throws ExceptionHttpURLConnection httpURLConnection = getHttpUrlConnection(netUrl);String acceptRanges = httpURLConnection.getHeaderField("Accept-Ranges");if (StringUtils.isEmpty(acceptRanges))return false;if ("bytes".equalsIgnoreCase(acceptRanges))return true;return false;
5.3.3 获取远程文件大小
当文件支持断点下载,我们需要获取远程文件的大小,来设置Range参数的范围区间,当然,如果是单线程断线下载,不获取远程文件大小,使用 Range: start- 也是能完成断点下载的,如下:
/*** 获取远程文件大小*/private static int getFileContentLength(String netUrl) throws ExceptionHttpURLConnection httpUrlConnection = getHttpUrlConnection(netUrl);int contentLength = httpUrlConnection.getContentLength();closeHttpUrlConnection(httpUrlConnection);return contentLength;
5.3.4 单线程断点下载
不管是单线程断点下载还是多线程断点下载,片段文件下载完成后,都无法绕开的一个问题,那就是文件合并。我们使用范围请求,拿到了文件中的某个区间片段,最终还是要将各个片段合并成一个完整的文件,才能实现我们最初的下载目的。
相较而言,单线程的合并会比较简单,因为单线程断点下载使用串行下载,在文件断点写入过程中,都是基于已有片段进行尾部追加,我们使用commons-io-2.4.jar里面的一个工具方法,来实现文件的尾部追加:
5.3.4.1 文件分段
单线程-范围分段
/*** 单线程串行下载** @param totalFileSize 文件总大小* @param netUrl 文件地址* @param N 串行下载分段次数*/private static void segmentDownload(int totalFileSize, String netUrl, int N) throws Exception// 本地文件目录String localFilePath = "F:\\\\test_single_thread.txt";// 文件我们分N次来下载int eachFileSize = totalFileSize / N;for (int i = 1; i <= N; i++)// 写入本地文件File localFile = new File(localFilePath);// 获取本地文件,如果为空,则start=0,不为空则为该本地文件的大小作为断点下载开始位置long start = localFile.length();long end = 0;if (i == 1)end = eachFileSize;else if (i == N)end = totalFileSize;elseend = eachFileSize * i;appendFile(netUrl, localFile, start, end);System.out.println(String.format("我是第%s次下载,下载片段范围start=%s,end=%s", i, start, end));File localFile = new File(localFilePath);System.out.println("本地文件大小:" + localFile.length());
5.3.4.2 文件追加
单线程-文件尾部追加
/*** 文件尾部追加* @param netUrl 地址* @param localFile 本地文件* @param start 分段开始位置* @param end 分段结束位置*/private static void appendFile(String netUrl, File localFile, long start, long end) throws ExceptionHttpURLConnection httpURLConnection = getHttpUrlConnection(netUrl);httpURLConnection.setRequestProperty("Range", "bytes=" + start + "-" + end);// 获取远程文件流信息InputStream inputStream = httpURLConnection.getInputStream();// 本地文件写入流,支持文件追加FileOutputStream fos = FileUtils.openOutputStream(localFile, true);IOUtils.copy(inputStream, fos);closeHttpUrlConnection(httpURLConnection);
单线程下载结果
远程文件支持断点下载远程文件大小:740我是第1次下载,下载片段范围start=0,end=246我是第2次下载,下载片段范围start=247,end=492我是第3次下载,下载片段范围start=493,end=740本地文件和远程文件一致,md5 = 1FFD36BD1B06EB6C287AF8D788458808, Etag = "1FFD36BD1B06EB6C287AF8D788458808"
5.3.5 多线程断点下载
多线程的文件合并方式与单线程不一样,因为多线程是并行下载,每个子线程下载完成的时间是不确定的。这个时候,我们需要使用到java一个核心类:RandomAccessFile。这个类可以支持随机的文件读写,其中有一个seek函数,可以将指针指向文件任意位置,然后进行读写。什么意思呢,举个栗子:假如我们开了10个线程,首先第一个下载完成的是线程X,它下载的数据范围是300-400,那么这时我们调用seek函数将指针拨动到300,然后调用它的write函数将byte写出,这时候300之前都是NULL,300-400之后就是我们插入的数据。这样就可以实现多线程下载和本地写入了。话不多说,我们还是以代码的方式来呈现:
5.3.5.1 资源分组
多线程-资源分组
/*** 多线程分组策略* @param netUrl 网络地址* @param totalFileSize 文件总大小* @param N 线程池数量*/private static void groupDownload(String netUrl, int totalFileSize, int N) throws Exception// 采用闭锁特性来实现最后的文件校验事件CountDownLatch countDownLatch = new CountDownLatch(N);// 本地文件目录String localFilePath = "F:\\\\test_multiple_thread.txt";int groupSize = totalFileSize / N;int start = 0;int end = 0;for (int i = 1; i <= N; i++)if (i <= 1)start = groupSize * (i - 1);end = groupSize * i;else if (i > 1 && i < N)start = groupSize * (i - 1) + 1;end = groupSize * i;elsestart = groupSize * (i - 1) + 1;end = totalFileSize;System.out.println(String.format("线程%s分配区间范围start=%s, end=%s", i, start, end));downloadAndMerge(i, netUrl, localFilePath, start, end, countDownLatch);// 校验文件一致性countDownLatch.await();validateCompleteness(localFilePath, netUrl);
5.3.5.2 文件合并
多线程-文件合并
/*** 文件下载、合并* @param threadNum 线程标识* @param netUrl 网络文件地址* @param localFilePath 本地文件路径* @param start 范围请求开始位置* @param end 范围请求结束位置* @param countDownLatch 闭锁对象*/private static void downloadAndMerge(int threadNum, String netUrl, String localFilePath, int start, int end, CountDownLatch countDownLatch)threadPoolExecutor.execute(() ->tryHttpURLConnection httpURLConnection = getHttpUrlConnection(netUrl);httpURLConnection.setRequestProperty("Range", "bytes=" + start + "-" + end);// 获取远程文件流信息InputStream inputStream = httpURLConnection.getInputStream();RandomAccessFile randomAccessFile = new RandomAccessFile(localFilePath, "rw");// 文件写入开始位置指针移动到已经下载位置randomAccessFile.seek(start);byte[] buffer = new byte[1024 * 10];int len = -1;while ((len = inputStream.read(buffer)) != -1)randomAccessFile.write(buffer, 0, len);closeHttpUrlConnection(httpURLConnection);System.out.println(String.format("下载完成时间%s, 线程:%s, 下载完成: start=%s, end = %s", System.currentTimeMillis(), threadNum, start, end));catch (Exception e)System.out.println(String.format("片段下载异常:线程:%s, start=%s, end = %s", threadNum, start, end));e.printStackTrace();countDownLatch.countDown(););
多线程下载运行结果
远程文件支持断点下载远程文件大小:740线程1分配区间范围start=0, end=74线程2分配区间范围start=75, end=148线程3分配区间范围start=149, end=222线程4分配区间范围start=223, end=296线程5分配区间范围start=297, end=370线程6分配区间范围start=371, end=444线程7分配区间范围start=445, end=518线程8分配区间范围start=519, end=592线程9分配区间范围start=593, end=666线程10分配区间范围start=667, end=740下载完成时间1608443874752, 线程:7, 下载完成: start=445, end = 518下载完成时间1608443874757, 线程:2, 下载完成: start=75, end = 148下载完成时间1608443874758, 线程:3, 下载完成: start=149, end = 222下载完成时间1608443874759, 线程:5, 下载完成: start=297, end = 370下载完成时间1608443874760, 线程:10, 下载完成: start=667, end = 740下载完成时间1608443874760, 线程:1, 下载完成: start=0, end = 74下载完成时间1608443874779, 线程:8, 下载完成: start=519, end = 592下载完成时间1608443874781, 线程:6, 下载完成: start=371, end = 444下载完成时间1608443874784, 线程:9, 下载完成: start=593, end = 666下载完成时间1608443874788, 线程:4, 下载完成: start=223, end = 296本地文件和远程文件一致,md5 = 1FFD36BD1B06EB6C287AF8D788458808, Etag = "1FFD36BD1B06EB6C287AF8D788458808"
从运行结果可以出,子线程下载完成时间并没有完全按着我们for循环指定的1-10线程标号顺序完成,说明子线程之间是并行在写入文件。其中还可以看到,子线程10和子线程1是在同一时间完成了文件的下载和写入,这也很好的验证了我们上面提到的RandomAccessFile类的效果。
5.3.6 完整性判断
完整性校验
/*** 校验文件一致性,我们判断Etag和本地文件的md5是否一致* 注:Etag携带了双引号* @param localFilePath* @param netUrl*/private static void validateCompleteness(String localFilePath, String netUrl) throws ExceptionFile file = new File(localFilePath);InputStream data = new FileInputStream(file);String md5 = DigestUtils.md5Hex(data);HttpURLConnection httpURLConnection = getHttpUrlConnection(netUrl);String etag = httpURLConnection.getHeaderField("Etag");if (etag.toUpperCase().contains(md5.toUpperCase()))System.out.println(String.format("本地文件和远程文件一致,md5 = %s, Etag = %s", md5.toUpperCase(), etag));elseSystem.out.println(String.format("本地文件和远程文件不一致,md5 = %s, Etag = %s", md5.toUpperCase(), etag));
六、写在最后
文件断点下载的优势在于提升下载速度,但是也不是每种业务场景都适合,比如说业务网络环境很好,下载的单个文件大小几十兆的情况下,使用断点下载也没有太大的优势,反而增加了实现方案的复杂度。这就要求我们开发人员在使用时酌情考虑,而不是盲目使用。
以上是关于文件下载解决方案的主要内容,如果未能解决你的问题,请参考以下文章