自然语言处理-拼写检查
Posted 学习康ing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理-拼写检查相关的知识,希望对你有一定的参考价值。
今天给大家发布一篇我新学的自然语言处理-拼写检查
原理:
拼写检查则是根据预设的编辑距离阈值,从英文词库中搜索最小编辑距离不超过阈值的所有单词,将其罗列出来作为候选项或是从所有符合条件的词中输出一个最有可能的词。
最小编辑距离的含义为使一个字符串变成另外一个字符串而进行的插入、删除、更新或相邻字符交换位置而进行的最少操作次数。

最小编辑距离:
(1)增加:对于字符串A:abc 和 字符串B:abcde,我们只需要在字符串A的末尾增加符d和e就能变成字符串B了,所以A和B的最短编辑距离为2。
(2)删除:对于字符串A:abcd 和字符串B:abc,我们只需要在字符串a的末尾删除字符d就能变成字符串b了,所以A和B的最短编辑距离为1。
(3)替换:对于字符串A:abcd 和 字符串B:abce,我们只需要把字符串A的d替换成e就可以了,此时他们的最短编辑距离是1。
我们在实际使用中会将三个串联起来使用。
步骤:
1 分步计算最小编辑距离
1.1 初始化数据
import numpy as np#导库
#创建两个字符串,其中w1为输入字符串,w2为目标字符串
w1 = 'hollw'
w2 = 'hello'
m = len(w1)
n = len(w2)
L1 = m+1
L2 = n+1
print('L1:',L1)
print('L2:',L2)
#创建一个L1xL2全为0的矩阵,赋值给变量matrix,用于动态计算最小编辑距离
matrix = np.zeros((L1, L2))
print(matrix)
for i in range(6):
matrix[i][0]=i
print(matrix)
for i in range(6):
matrix[0][i]=i
print(matrix)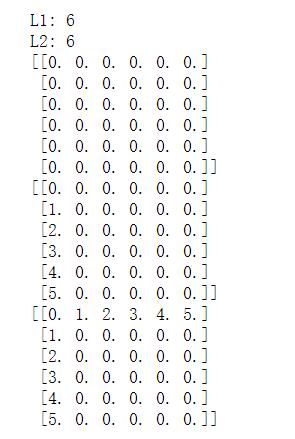
1.2 动态计算最小编辑距离
理论逻辑
w1 = 'hollw' # 定义输入字符串
w2 = 'hello' # 定义目标字符串

通过上述推导,可以发现D[i][j]只与D[i][j-1],D[i-1][j-1],D[i-1][j]相关。而且,若w1[i]与w2[j]相同,则D[i][j] = D[i-1][j-1];若不相同,则D[i][j] = mid(D[i][j-1],D[i-1][j-1],D[i-1][j])+1。
编程逻辑
(1)首先通过两层for循环依次计算D[1][1]至D[L1][L2]的编辑距离,即需要的步骤数。在上述说明中,矩阵matrix的第一列是输入字符串的数值形式,第一行是目标字符串的数值形式。故i的取值为[1,L1),j的取值为[1,L2)。
(2)在能够遍历每个字符后,需判断当前输入字符串的字符与目标字符串的字符是否相等。创建一个delta变量,用于存储判断结果。若相等,则赋值为0;反之则为1。
(3)最后计算最小编辑距离,公式为matrix[i][j] = min(matrix[i - 1][j - 1] + delta,matrix[i - 1][j] + 1, matrix[i][j - 1] + 1)。
for i in range(1,L1):
for j in range(1,L2):
if w1[i-1]==w2[j-1]:
delta = 0
else:
delta = 1
matrix[i][j] = min(matrix[i - 1][j - 1] + delta,matrix[i - 1][j] + 1, matrix[i][j - 1] + 1)
h = matrix[i][j]
print('将变换成需要进行步操作,即最小编辑距离为'.format(w1[i-1],w2[j-1],h,h))
print(matrix)
前面是理解,接下来就是进行实践了
2实现英文单词拼写检查
2.1 加载数据
from nltk.corpus import words#通过nltk.corpus库导入word词库
#通过set函数将words.words()转换为集合剔除重复词组,赋值给变量words
words = list(set(words.words()))
print(len(words))
words[:10]-这里涉及到了一个库import nltk
nlt库的安装
安装-所有应用-anaconda-
我用的是这个
pip install nltk
安装好了就可以用了
words包的导入
第二个就是这个包的导入,首先这个包words需要的是压缩文件,其次我们要将其放在指定的文件夹,并且在其文件夹下放入一个子文件夹corpora然后将其压缩包放入这个文件
我们下载好后用
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
print(stop_words)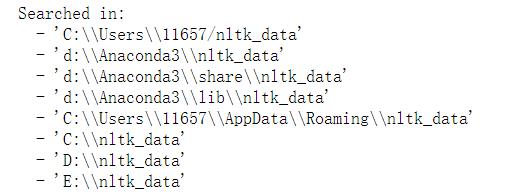
我们找到一个文件后如下图,直接创建就好了

后面就能运行了

2.2 封装函数
将分步计算最小编辑距离的方法封装为edit_distance(w1, w2)函数,内设置两个参数分别接收输入字符串和目标字符串。
就是按照第一,二步的步骤照着葫芦画瓢
def edit_distance(w1, w2):
matrix=np.zeros((len(w1)+1,len(w2)+1))
for i in range(len(matrix)):
for j in range(len(matrix[0])):
if i==0:
matrix [i][j]=j
elif j==0:
matrix [i][j]=i
elif w1[i-1]==w2[j-1]:
matrix[i][j]=matrix[i-1][j-1]
else:
matrix[i][j] = min(matrix[i - 1][j - 1] + delta,matrix[i - 1][j] + 1, matrix[i][j - 1] + 1)
return matrix[-1][-1]2.3 函数调用
1、通过while关键字创建一个循环。
2、通过input()函数获取键盘输入值并赋值给变量w1。
3、在input()函数后通过strip()函数设置一个输入框。
4、通过if语句判断当前输入值如果为‘end’则结束程序。
5、通过if语句判断当前输入值是否为合法单词,若是则输出‘合法单词’;反之则对words进行遍历,筛选所有符合预设编辑距离(<2)的词组。
6、通过join()函数,将所有符合条件的词间插入空格进行连接,赋值给变量suggestion并输出。
while True:
w1 = input('当前输入字符串:')
if w1 == 'end':
print('程序结束')
break
if w1 in words:
print('合法单词')
else:
suggsetion = ' '.join([i for i in words if edit_distance(i,w1)<2])#[i for i in words]列表解析式
print(suggsetion)
总的来说比较简单,唯一难搞的地方就是那个words的导入导了半天
以上是关于自然语言处理-拼写检查的主要内容,如果未能解决你的问题,请参考以下文章