房屋价格数据采集与分析
Posted 大愚若智_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了房屋价格数据采集与分析相关的知识,希望对你有一定的参考价值。
随着互联网的发展,可供分析的信息越来越多,利用互联网上的信息来对生活中的问题做一些简单的研究分析,变得越来越便利了。本文就从数据采集、数据清洗、数据分析与可视化三部分来看看新的一年里房市的一些问题。
数据采集:
数据采集即从网页上采集我们需要的指定信息,一般使用爬虫实现。当前开源的爬虫非常多,处于简便及学习的目的,在此使用python的urllib2库模拟http访问网页,并BeautifulSoup解析网页获取指定的字段信息。本人获取的链家网上的新房和二手房数据,先来看看原始网页的结构:
首先是URL,不管是新房还是二手房,链家网的房产数据都是以列表的方式存在,比较容易获取,如下图:
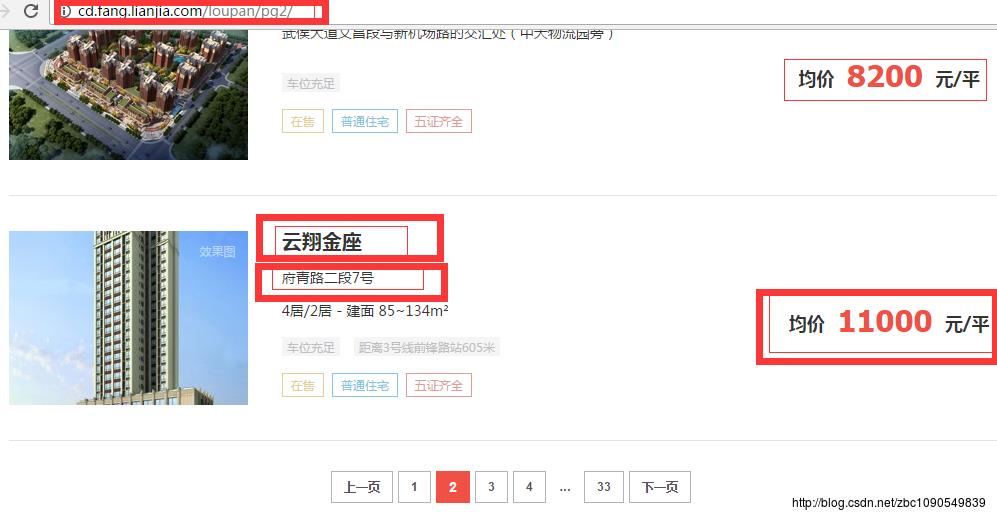
其中包含的信息有楼盘名称、地址、价格等信息,回到原始网页,看看在html中,这些信息都在什么地方,如下图:
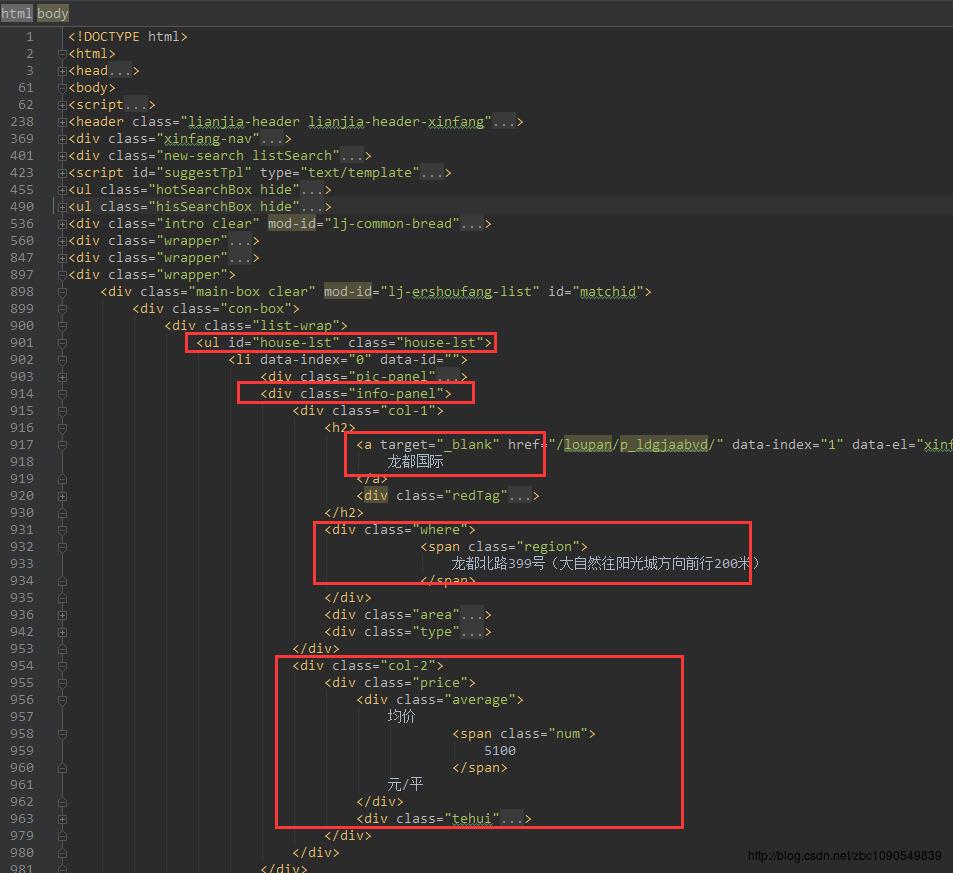
值得注意的是,原始的html为了节省传输带宽一般是经过压缩的,不太方便分析,可以借助一些html格式化工具进行处理再分析。知道这些信息后,就可以模拟http请求来拉取html网页并使用BeautifulSoup提取指定的字段了。
fw = open("./chengdu.txt","a+")
index = [i+1 for i in range(32)]
for pa in index:
try:
if pa==1:
url = "http://cd.fang.lianjia.com/loupan/"
else:
url = "http://cd.fang.lianjia.com/loupan/pg%d/"%(pa)
print "request:"+url
req = urllib2.Request( url )
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36")
req.add_header("Accept","*/*")
req.add_header("Accept-Language","zh-CN,zh;q=0.8")
data = urllib2.urlopen( req )
res = data.read()
#print res
#res = res.replace(" ","")
#print res
#objects = demjson.decode(res)
soup = BeautifulSoup(res)
houseLst = soup.findAll(id='house-lst')
resp = soup.findAll('div', attrs = 'class': 'info-panel')
for i in range(len(resp)):
name = resp[i].findAll('a', attrs = 'target': '_blank')[0].text
privice = resp[i].findAll('span', attrs = 'class': 'num')
privice = privice[0].text
region = resp[i].findAll('span', attrs = 'class': 'region')
address = region[0].text.split('(')[0]
##解析获得经纬度
location,city,district = getGdLocation(name)
if not location:
location = getBdLocation(address)#自定义函数
if not location:
continue
formatStr = "%s,%s,%s,%s,%s\\n"%(city,district,name,location,privice)
print formatStr
fw.write(formatStr)
except:
pass
fw.close()数据清洗:
数据清洗,顾名思义就是将不合规的数据清理掉,留下可供我们能够正确分析的数据,至于哪些数据需要清理掉,则和我们最终的分析目标有一定的关系,可谓仁者见仁智者见智了。在这里,由于是基于地理位置做的一个统计分析,显然爬取的地理位置必须是准确的才行。但由于售房者填写的地址和楼盘名称可能有误,如何将这些有误的识别出来成为这里数据清洗成败的关键。我们清洗错误地理位置的逻辑是:使用高德地图的地理位置逆编码接口(地理位置逆编码即将地理名称解析成经纬度)获得楼盘名称和楼盘地址。对应的经纬度,计算二者对应的经纬度之间的距离,如果距离值超过一定的阀值,则认为地址标注有误或者地址标注不明确。经过清洗后,获取到的成都地区的在售楼盘及房屋数量总计在3000套的样子。
经过清洗后的数据格式为:
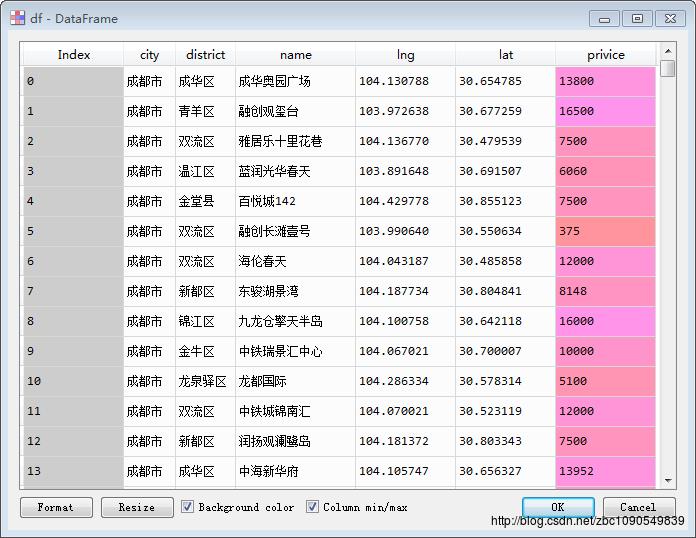
包括市、区、楼盘/房屋名称、经纬度、价格四个维度。
数据分析与可视化:
首先是新推楼盘挂牌价格与销售价格
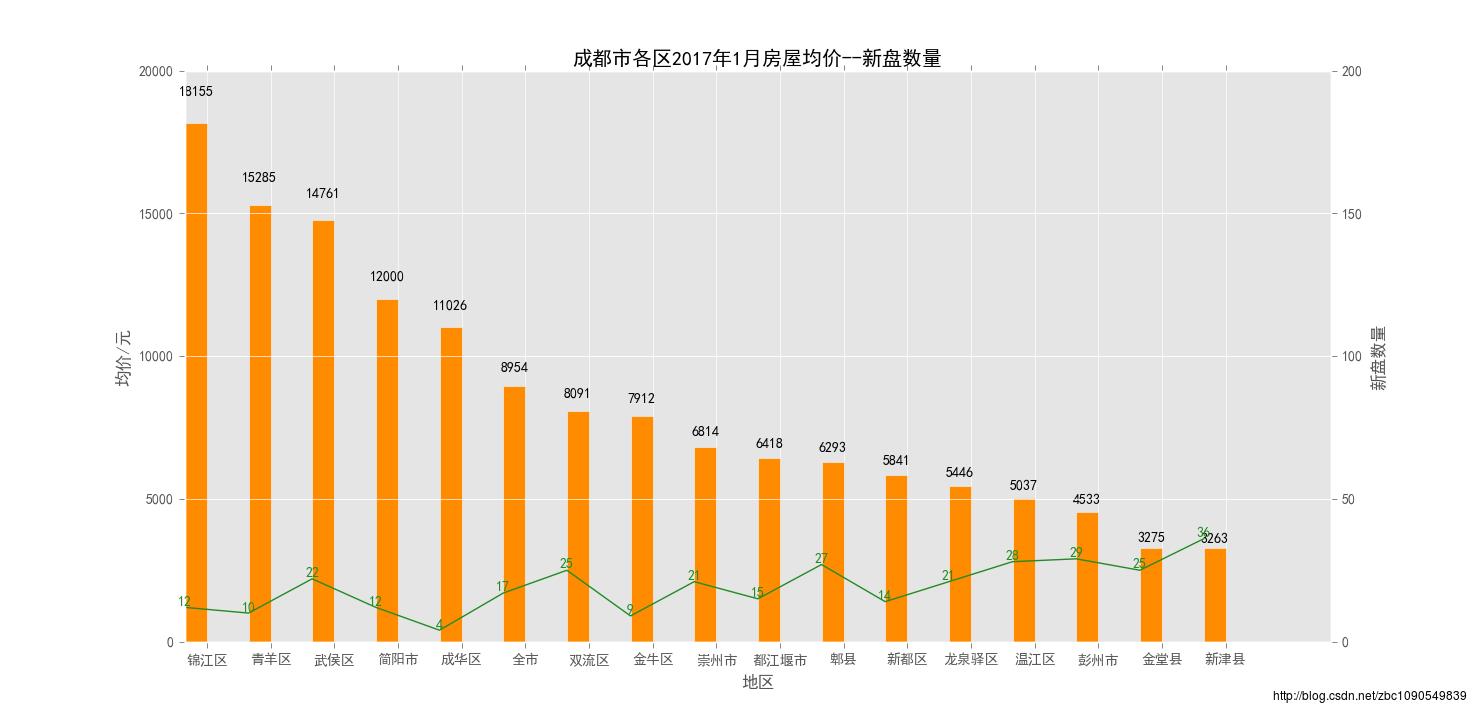
市中心依然遵循了寸独存金的原则,销售价格远远高于郊县,一方面原因是位置地段、配套的独特性,一方面也是由于可供销售的土地面积、楼盘数量极为有限。
二手房销售价格和挂牌数量
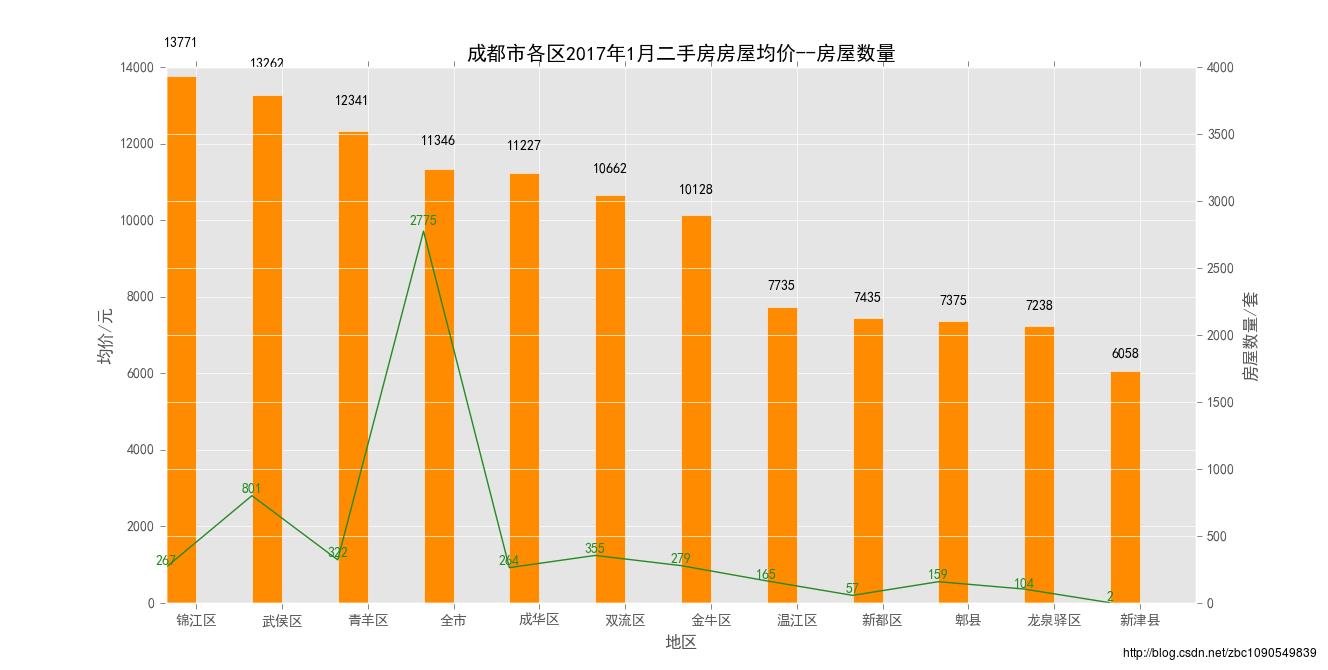
二手房交易重要集中在市区及一些经济比较发达的郊县,不同区县的价格分化并不大,可能原因是老城区销售的二手房存在一部分老房子、同时二手房的价格卖家写的比较随意。
二手房数据的箱型图
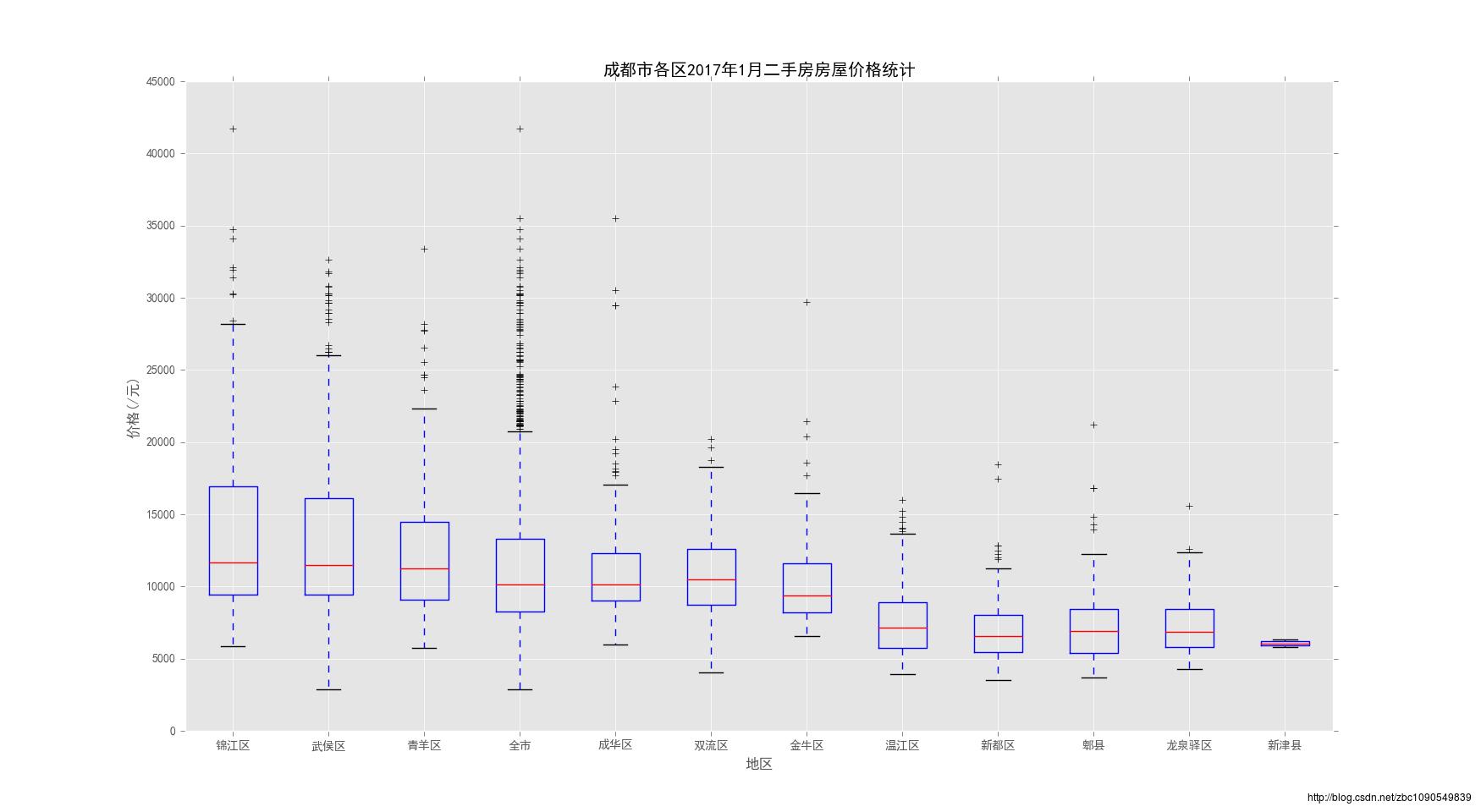
这个就更为明显的印证了上面的结论,主城区的二手房存在一部分价格远低于市场均价的(即老房子),也有一部分价格昂贵的(新房、豪宅)出售,郊县的价格均方差则会低很多。
房屋销售热度的空间可视化
房屋销售热度以该区域的房屋销售数量和房屋销售价格综合来衡量,计算方式以该区域销售的房屋数量及销售价格进行加权。
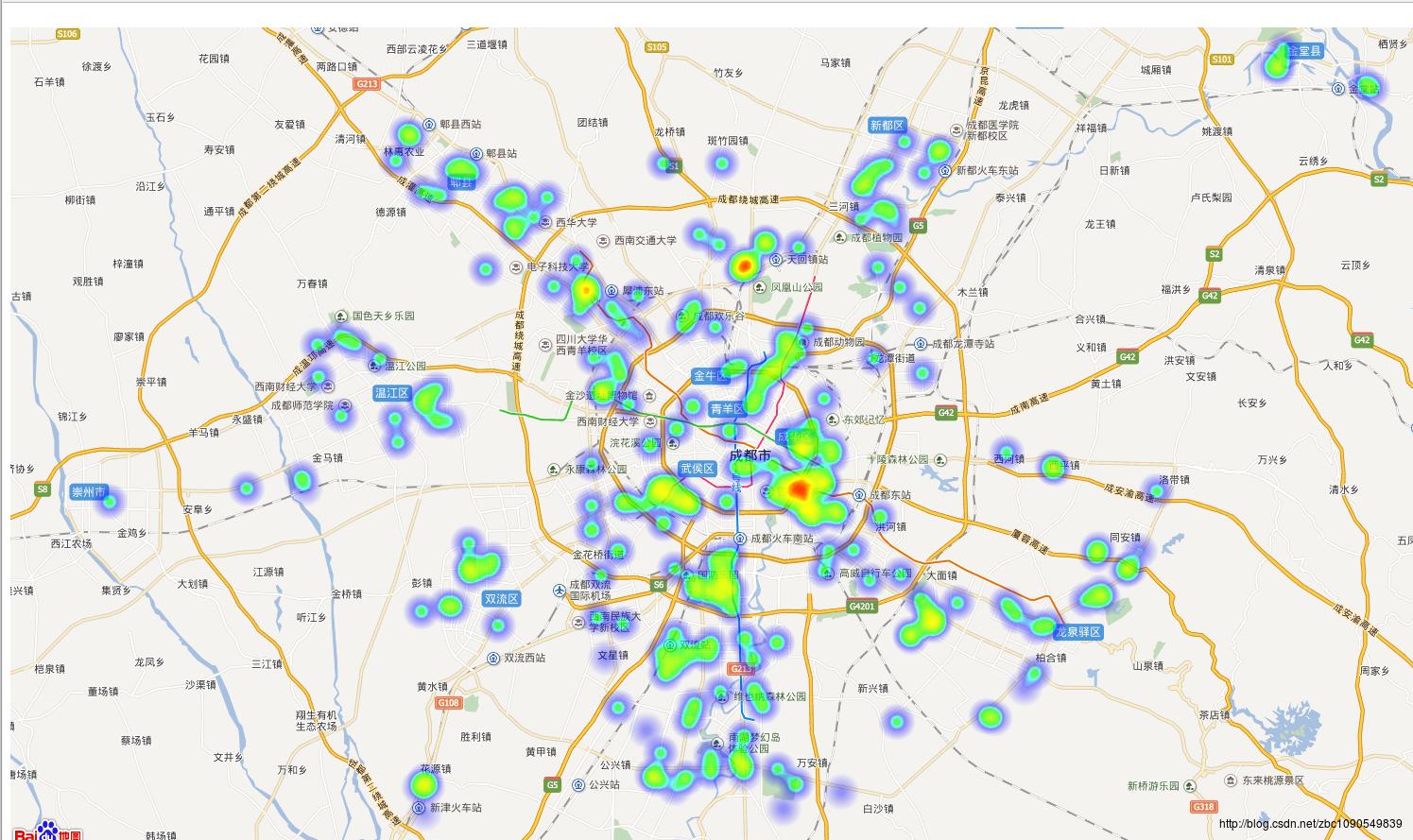
新房销售热度
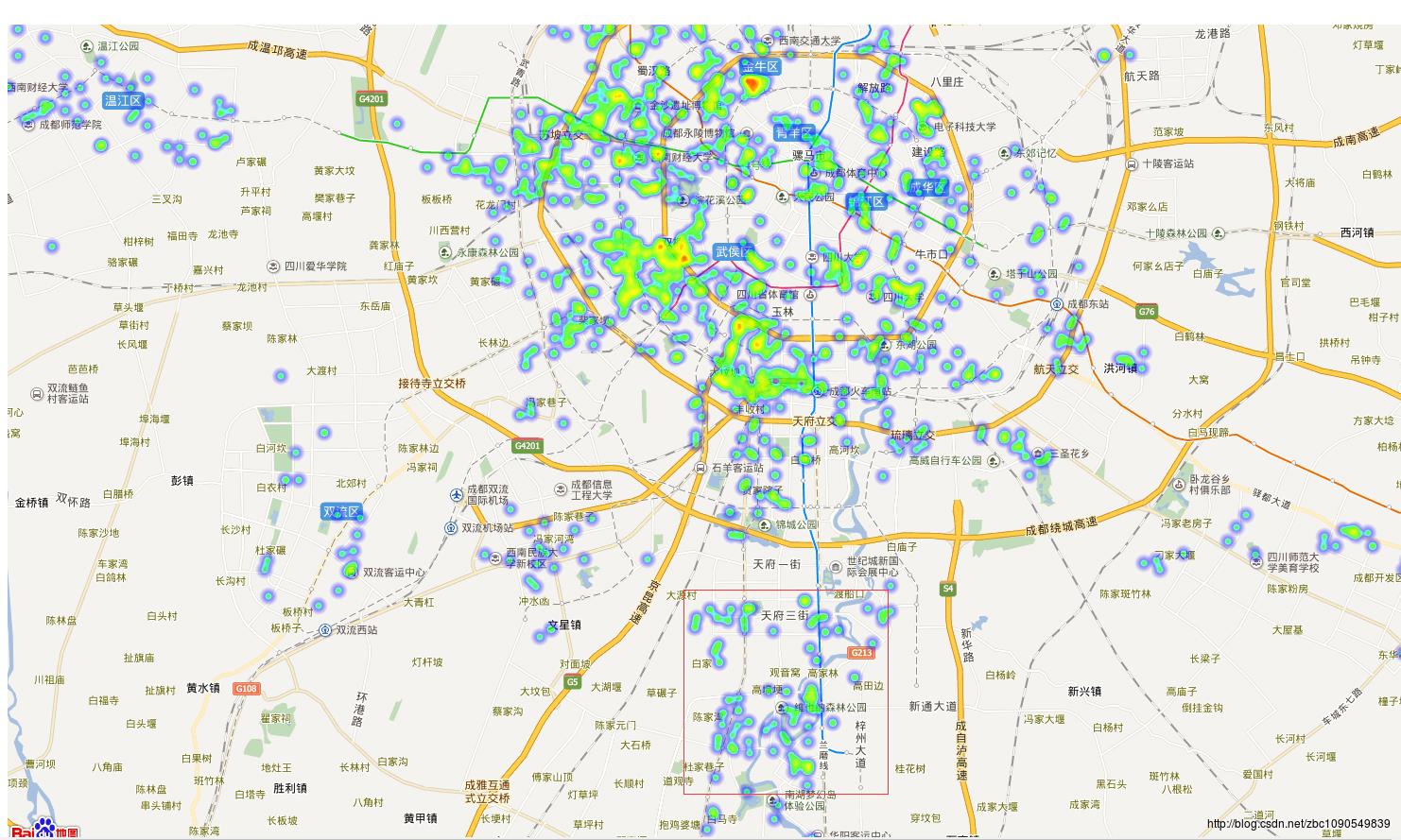
二手房销售热度
主城区没什么好说的了,人口密度大、买房售房的都多。在南边有一块远离市区的地方、新房和二手房的交易热度都很高,即成都市天府新区,目前配套和各项设施都不太完善,去这里花高价买房安家的老百姓想必不会太多,猜测是去年炒房热过年,这些人现在开始出售房屋了。
相关项目代码已整理至本人github(https://github.com/LambdaWx/housePriceSpider),欢迎一起学习研究数据分析及其方法论。
以上是关于房屋价格数据采集与分析的主要内容,如果未能解决你的问题,请参考以下文章