Focal loss分析
Posted mazinkaiser1991
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Focal loss分析相关的知识,希望对你有一定的参考价值。
1)Class imbalance问题的提出
Focal loss的提出就是问了解决Class imbalance问题,在两阶段目标检测算法中,这一问题是通过两阶段级联与启发式采样策略解决的(Class imbalance is addressed in R-CNN-like detectors by a two-stage cascade and sampling heuristics)。在proposal阶段,候选物体位置被快速的降低到一个较小的数量(例如1-2K),筛选掉大部分的背景采样(The proposal stage (e.g., Selective Search [35], EdgeBoxes [39], DeepMask [24, 25], RPN [28]) rapidly narrows down the number of candidate object locations to a small number (e.g., 1-2k), filtering out most background samples)。在第二阶段,启发式的采样方法,例如固定的前景与背景比例(1:3)或者在线难例挖掘,用于保持前景与背景物体数量的平衡。(In the second classification stage, sampling heuristics, such as a fixed foreground-to-background ratio (1:3), or online hard example mining (OHEM) [31], are performed to maintain a manageable balance between foreground and background)。
正相反,单阶段检测器必须处理一个大得多的物体位置候选集,这个候选集通常是在整副图片上采样得到的(In contrast, a one-stage detector must process a much larger set of candidate object locations regularly sampled across an image)。通常,单阶段检测器可能给出~100K个候选位置,这些位置非常密集同时包含不同的空间位置、尺度与比例。(In practice this often amounts to enumerating ∼100k locations that densely cover spatial positions, scales, and aspect ratios)然而,类似的启发式采样方法可能也会被应用,但他们是效率低下的,因为训练过程仍然被容易分类的背景物体主导(While similar sampling heuristics may also be applied, they are inefficient as the training procedure is still dominated by easily classified background examples.)。这一效率低下的问题是目标检测中的典型问题,通常使用bootstrapping或难例挖掘等技术解决(This inefficiency is a classic problem in object detection that is typically addressed via techniques such as bootstrapping [33, 29] or hard example mining [37, 8, 31])。
类别不平衡问题导致两个问题:(This imbalance causes two problems:)(1)训练过程效率低下,因为大部分是简单反例(easy negatives),简单反例对于学习过程没有作用;((1) training is inefficient as most locations are easy negatives that contribute no useful learning signal;)简单反例可能压垮(overwhelm)训练过程并且导致模型的退化。((2) en masse, the easy negatives can overwhelm training and lead to degenerate models.)
上面论文中的几段内容其实主要提出两方面问题
1)类别不平衡问题是单阶段检测器的问题,两阶段检测器没有这个问题。
2)简单反例(easy negatives)才是影响训练过程的主要因素。
因此《Focal Loss for Dense Object Detection》这篇文章针对单阶段检测器中的类别不平衡问题提出一种新的损失函数Focal loss,当然Focal loss不仅能解决单阶段检测器中的类别不平衡,类别不平衡问题均可以尝试采用这一方法解决。
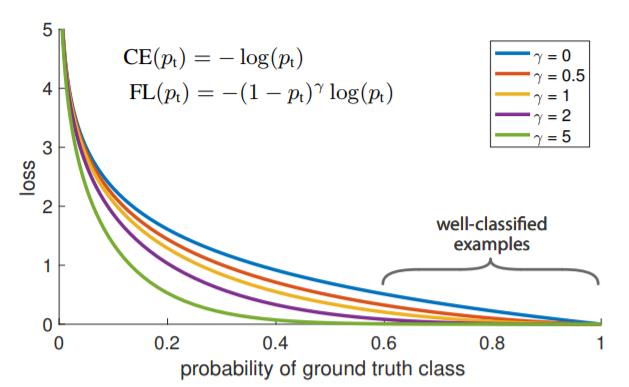
直接借用文章中的图片,可以看到如果γ等于0,则与cross entropy相等,随着γ的增加,loss随之下降。此处的下降有两方面作用:
1)当某个物体分类错误并且pt较小时,调制因子接近于1,损失函数并没有什么影响,这也就意味着被错误分类的物体的损失函数基本保持不变,仍能有效的用于网络训练。当pt趋近于1时,调制因子接近于0,较为容易分类的物体的损失函数也就基本趋近于0。
2)参数γ可以有效地降低被明确分类的物体的权重。这也就意味着被错误分类的物体的重要性在提高。
以上是关于Focal loss分析的主要内容,如果未能解决你的问题,请参考以下文章