Spark性能优化第四季
Posted 靖-Drei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark性能优化第四季相关的知识,希望对你有一定的参考价值。
一:Spark性能调优之序列化
1,之所以进行序列化,最重要的原因是内存空间有限(减少GC的压力,最大化的避免Full GC的产生,因为一旦产生Full GC则整个Task处于停止状态!!!)、减少磁盘IO的压力、减少网络IO的压力;
2,什么时候会必要的产生序列化或反序列化呢?发生磁盘IO和网络通讯的时候会序列化和反序列化,更为重要的考虑序列化和反序列化的时候有另外两种情况:
A)Persist(Checkpoint)的时候必须考虑序列化和反序列化,例如说cache到内存的时候只能使用JVM分配的60%的内存空间,此时好的序列化机制就至关重要了
B)编程的时候!使用算子的函数操作如果传入了外部数据就必须序列化和反序列化;
conf.set(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)
conf.registerKryoClasses(Array(classOf[Person]))
val person = new Person()
Rdd.map(item => person.add(item))
3,强烈建议使用Kryo序列器进行序列化和反序列化;Spark默认情况下不是使用Kryo而是Java自带的序列化器ObjectIntputStream和ObjectOutputStream(主要是考虑了方便性或者是通用性),如果自定义了RDD中数据元素的类型则必须实现Serializable接口,当然你也可以实现自己的序列化接口Externalizable来实现更加高效的Java序列化算法;采用默认的ObjectIntputStream和ObjectOutputStream会导致序列化后的数据占用大量的内存或者磁盘或者大量的消耗网络,并且在序列化和反序列化的时候比较消耗CPU;
4,强烈推荐大家采用Kryo序列化机制,Spark下使用Kryo序列化机制会比Java默认的序列化机制更加节省空间(减少近10倍的空间)以及更少的消耗CPU,个人强烈建议大家在一切情况下尽可能的使用Kryo序列化机制!
5,使用Kryo的两种方式:
A)在spark-defults.conf中配置,例如:
spark.serializer org.apache.spark.serializer.KryoSerializer
B)在程序的SparkConf中配置,例如:
conf.set(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)
Ps:使用Kryo可以更加快速,更低存储空间占用量以及更高性能的方式进行序列化
6,Spark中Scala常用的类型自动的通过AllScalaRegistrar注册给Kryo进行序列化管理;
7,如果是自定义的类型必须注册给序列化器,例如:
conf.set(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)
conf.registerKryoClasses(Array(classOf[Person]))
val person = new Person()
rdd.map(item => person.add(item))
Ps:另一种方式是Person实现Serializable接口。
8,Kryo在序列化的时候缓存空间默认大对象是2MB,可以更具体的业务模型调整改变大小,具体方式:设置spark.kyroserializer.buffer为10MB等;
9,在使用Kyro强烈建议注册时写完整的包名和类名,否则的话每次序列化的时候都会保存一份整个包名和类名的完整信息,这就减少不必要的消耗内存空间;
二:Spark JVM性能调优
1,好消息是Spark的钨丝计划是用来专门解决JVM性能问题的,不好的消息是至少在Spark 2.0以前钨丝计划功能不稳定并且不完善只能在特定的情况下发生作用,也就是说包括Spark 1.6在内的Spark及其以前的版本我们大多数情况下没有使用钨丝计划的功能,所以此时就必须关注JVM性能调优;
2,JVM性能调优的关键是调优GC!!!,为什么GC如此重要?主要是因为Saprk热衷于RDD的持久化!!!GC本身的性能开销是和数据量成正比的;
3,初步可以考虑是尽量多的使用Array和String,并且在序列化机制方面尽可能的Kyro,让每个partition都成为字节数组;
4,监视GC的基本方式有两种:
A)配置
spark.executor.extraJavaOptions=-verbose:gc -XX:+PrintGCDetails -XX:+ PrintGCDateTimeStamps
B)SparkUI
5,Spark在默认情况下使用60%的空间来进行Cache缓存RDD的内容,也就是说Task在执行的时候只能使用剩下的40%;如果空间不够用就会触发(频繁的)GC
可以设置spark.memory.fraction参数来进行调整空间的使用,例如降低Cache的空间,让Task使用更多的空间来创建对象和计算;
再一次,强烈建议进行RDD从Cache的时候使用Kyro序列化机制,从而给Task可以分配更大的空间来顺利完成计算(避免频繁的GC)
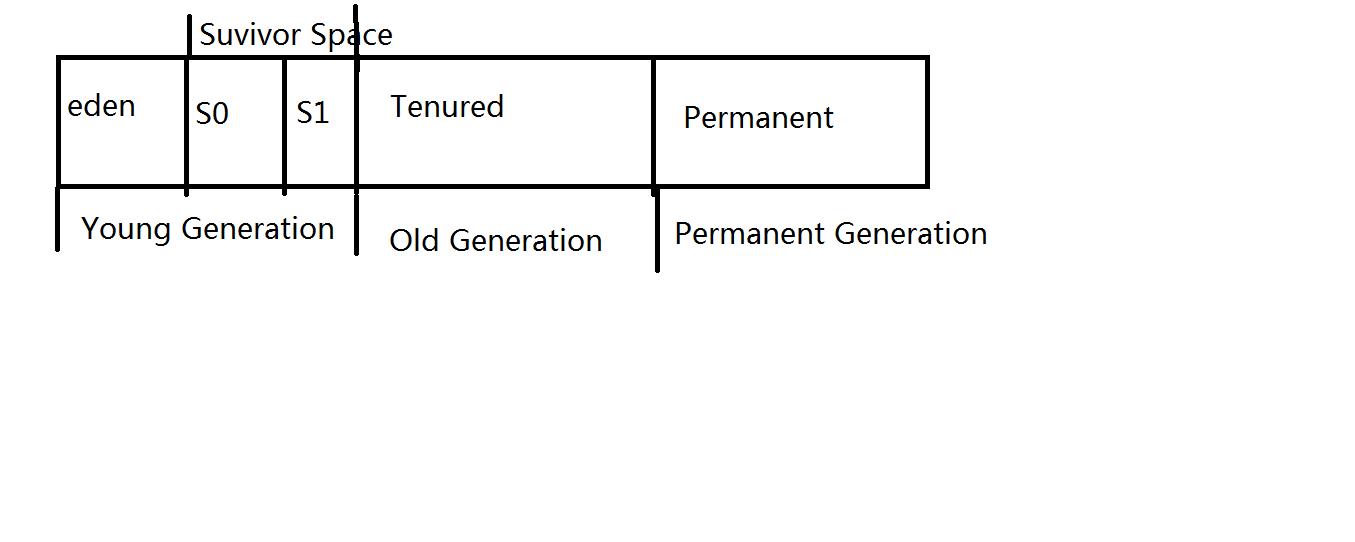
6,因为在老年代空间满的时候会发送FullGC操作,而老年代空间中基本是活的比较久的对象(经历数次GC依旧存在),此时会停下所有程序线程,进行Full GC,对老年代中的对象进行整理,严重影响性能;此时可以考虑:
A) 可以设置spark.memory.fraction参数来进行调整空间的使用来给年轻代更多的空间用于存放短时间的存活的对象;
B) -Xmn调整Eden区域;对RDD中操作的对象和数据进行大小评估,如果在HDFS上解压后一般体积可能会变成原有体积的3倍左右;根据数据的大小设置Eden;如果有10个Task,每个Task处理的HDFS上的数据是128M,则需要设置Xmn为10*128*3*4/3的大小;
C) -XX:SupervisorRatio;
D) -XX:NewRatio;
以上是关于Spark性能优化第四季的主要内容,如果未能解决你的问题,请参考以下文章