LRU算法在MySQL/hbase/Caffeine 中的优化
Posted 快乐崇拜234
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LRU算法在MySQL/hbase/Caffeine 中的优化相关的知识,希望对你有一定的参考价值。
正文在下面,先打个广告:

在上一篇文章中介绍了LRU的原理及实现,但是实际企业级应用中不会直接使用如此简单的LRU算法。本文看看各个优秀的中间件是如何优化LRU算法的。
mysql对LRU的优化
大家思考一个问题,在我前面讲到的算法实现中,每次访问的数据都会立刻移动到链表的尾端,这样是否是稳定可靠的?答案显然是否定的。实际的应用场景是比较复杂的,大家考虑这样一个场景,你的系统运行了一段时间,缓存都根据LRU算法正常运行,此时,有一个大的查询,数据量比较大,新查询出来的数据根据LRU算法会插入到队尾,此时缓存的数据超出了容量限制,将队头的数据删除了。由于查询的数据量比较大,就有可能将一些热点数据删除,而留下来的数据其实并不是热点数据。这样,后续应用从缓存中查询数据就会返回空,只能到数据库中查询,如此就造成了缓存命中率低下。
MySQL中的LRU算法,将整个缓存区域分成两块: 占总量5/8的热数据区和占总量3/8的冷数据区,新的数据并不是插入到整个缓存的tail位置,而是插入到3/8的位置。这样做可以避免一些大查询把热点数据给挤出缓存,并且从概率学上来讲,并不是所有新查询出的数据都是热点数据。当冷数据区的数据在1秒内再次被访问,才会将其移动到热数据区的tail位置。然后MySQL还对热数据区的数据移动做了进一步优化,并不是每次访问的热点数据都会移动到tail位置,而是将热区分为4份,只有在热区后3/4区域内的数据被访问到时才会被移动到tail位置。这样做的目的是为了避免频繁数据移动,减少性能损耗。
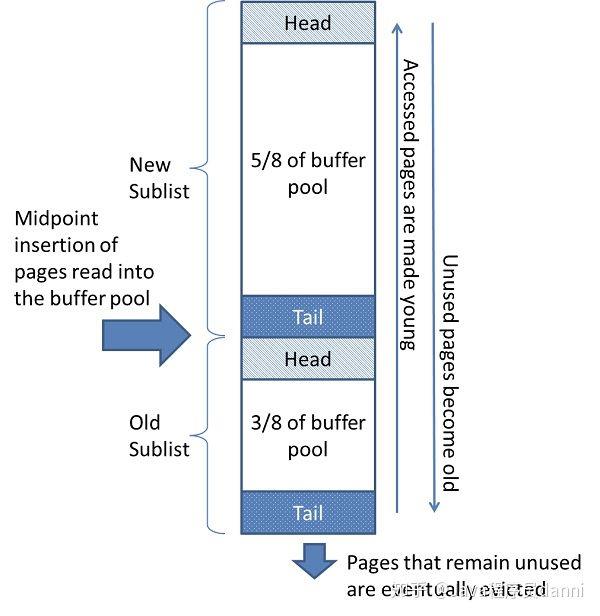
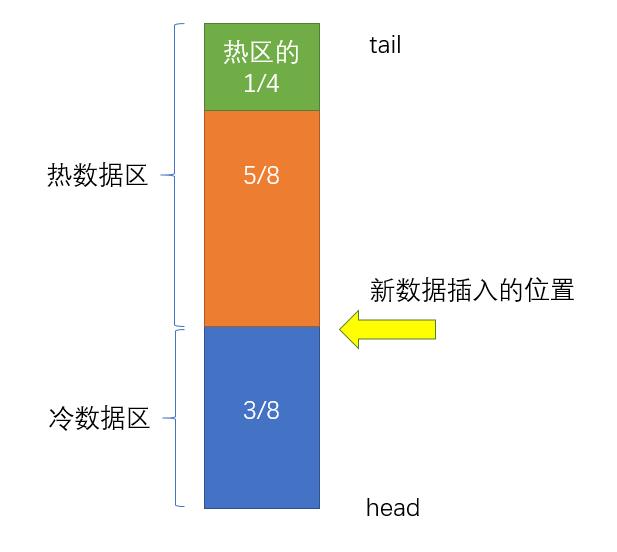
其他的中间件对LRU算法的优化基本也是这个原理,都是讲整个缓存分为多个部分,根据不同的策略进行数据的移动。
hbase对LRU算法的优化
HBase中的blockcache就是使用的LRU算法,不过目前版本(hbase2.X)中blockcache分为了两部分:LRUBlockCache和BucketCache。
LRUBlockCache中主要存储Index Block和Bloom Block,而将Data Block存储在BucketCache中。
LRUBlockCache的三段缓存架构:
- 第一段single-access占用25%的比例,也即单次读取区,block被读出后先放到这个区域,当被读到多次后会升级到下一个区域。
- 第二段multi-acsess占用50%的比例,也即多次读取区,当一个被缓冲到单次读取区后又被访问多次,会升级到这个区。
- in-memory占用25%的比例,这个区域跟Block被访问几次没有什么关系,它只存放那些被设置了IN-MEMORY=true的列族中读取出来的block。
可以看到,hbase对LRU缓存区域的管理多了一个级别。分为了三个区域。不过核心原理没有变,还是分区处理。
Caffeine
spring5以后,使用Caffeine来替代了guava。可见Caffeine的强大,有必要学习。
Caffeine 因使用 Window TinyLfu(W-tinyLFU) 回收策略,提供了一个近乎最佳的命中率。W-TinyLFU 就是结合 LFU 和LRU,前者用来应对大多数场景,而 LRU 用来处理突发流量。
W-tinyLFU 数据结构
caffeine结合使用LRU和LFU来管理缓存。它有3个AccessOrderDeque来存储缓存,分别是accessOrderEdenDeque,accessOrderProbationDeque,accessOrderProtectedDeque。三者占比分别是1%(可自适应调整),99%*20%,99%*80%。
accessOrderEdenDeque也就是下图最左侧的window cache(左侧的LRU部分);SLRU主缓存区分为两个段:Probation(试用期)和Protected(受保护)的两个区域.
window cache中记录的是新到的数据,防止突发流量由于之前没有访问频率,而导致被淘汰
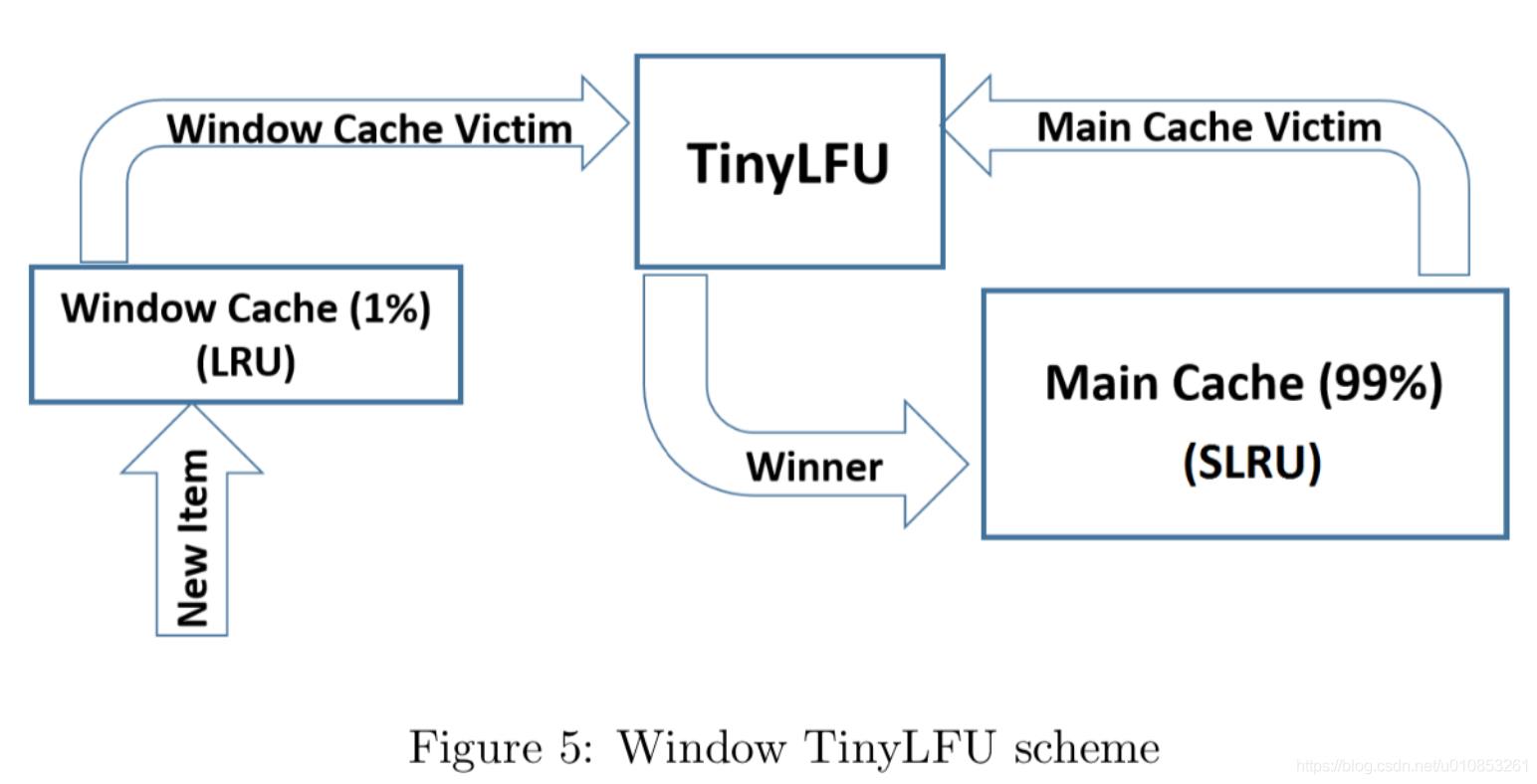
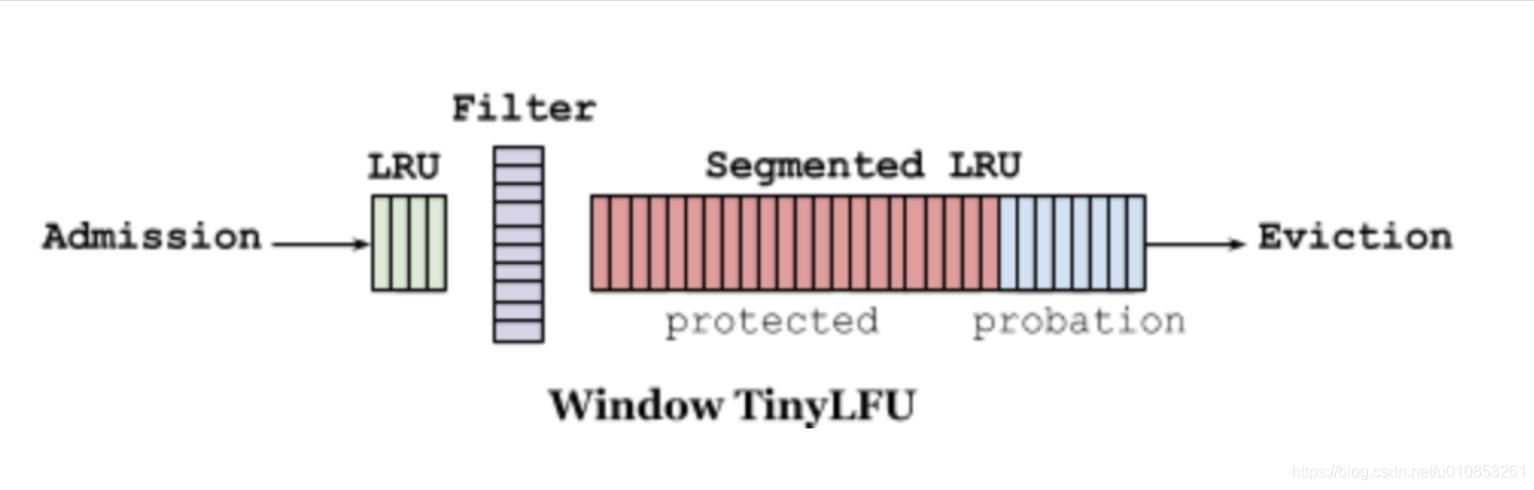
过期策略
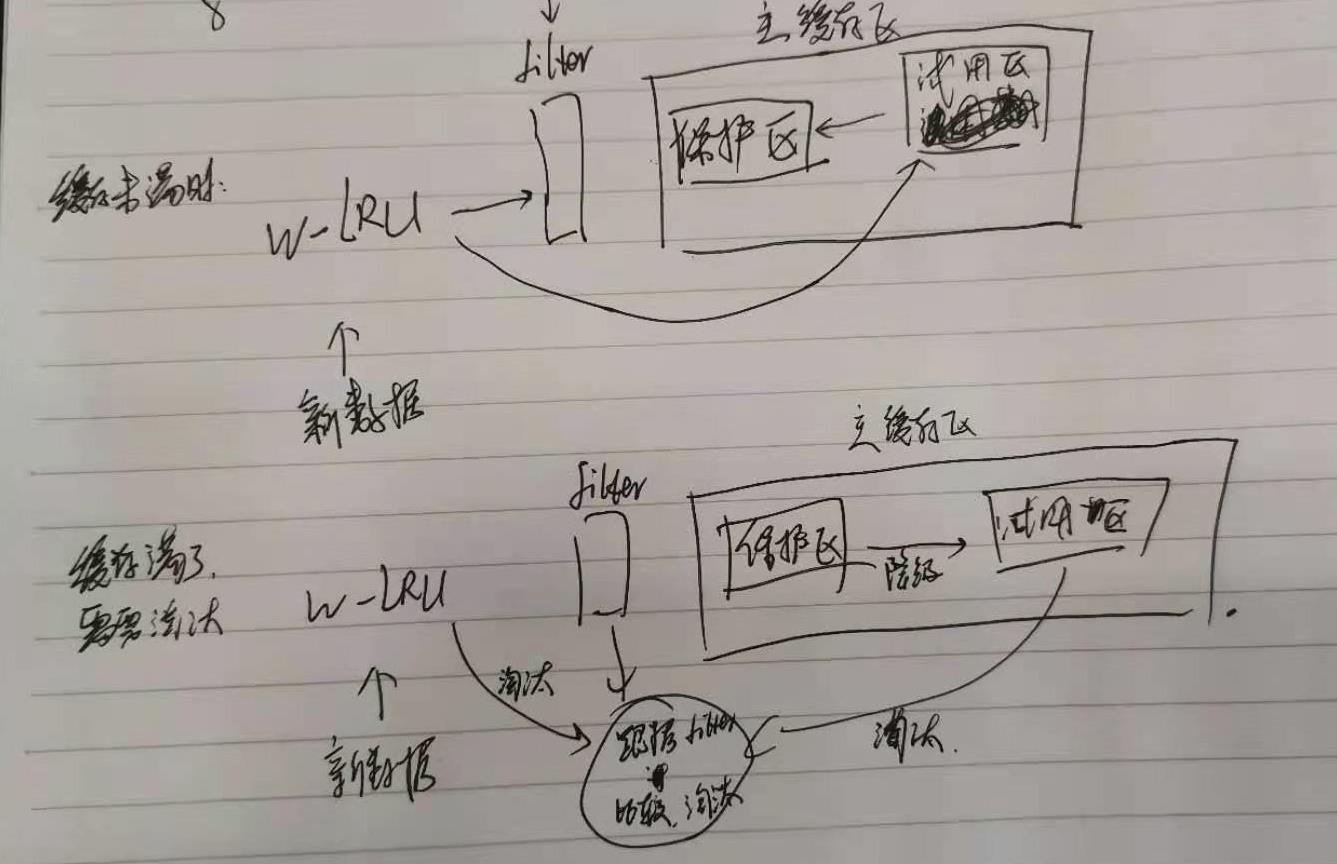
LFU 算法需要额外记录访问次数,最简单的做法就是用一个大的 hashmap 存储每个数据的访问次数,但是当数据量非常大的时候,hashmap 占用的空间也非常大。在W-TinyLFU中,数据首先会进入到 Window LRU.
新添加的数据首先放入窗口缓存 Window LRU中,如果窗口缓存满了,则把窗口缓存淘汰的数据转移到主缓存Probation区域中。如果这时主缓存也满了,则从主缓存的Probation区域淘汰数据,把这条数据称为受害者,从窗口缓存淘汰的数据称为候选人。接下来候选人和受害者进行一次pk,来决定去留。pk的方式是通过TinyFLU记录的访问频率来进行判断,具体过程如下:
- 首先获取候选人和受害者的频率
- 如果候选人大于受害者,则淘汰受害者
- 如果候选人频率小于等于5,则淘汰候选人
- 其余情况随机处理。
W-TinyLFU 使用 Count-Min Sketch 算法作为过滤器,该算法 是 布隆过滤器 的一种变种。
这里简单回顾一下,布隆过滤器的思想是,创建一个数组(同理,也可以是bytes),针对每一个数据进行多次hash,最终将hash后的数组位置置为1(array[hash%length] = 1),并不直接存储数据,由此来判断数据是否可能重复。Count-Min Sketch 算法也是类似的,根据不同的hash算法创建不同的数组,针对每一个数据进行多次hash,并在该hash算法的对应数组hash索引位置上+1,由于hash算法存在冲突,那么在最后取计数的时候,取所有数组中最小的值即可。
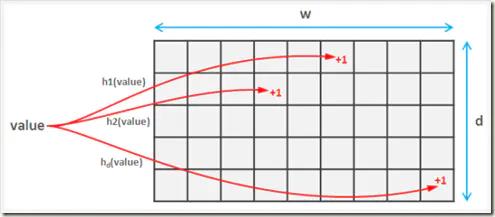
在Caffeine的实现中,会先创建一个Long类型的数组,数组的大小为 2,数组的大小为数据的个数,如果你的缓存大小是100,他会生成一个long数组大小是和100最接近的2的幂的数,也就是128。另外,Caffeine将64位的Long类型划分为4段,每段16位,用于存储4种hash算法对应的数据访问频率计数。
众所周知,caffeine提供了三大类淘汰策略,分别是基于数量权重,基于时间,基于引用,这里就不再赘述各种淘汰策略。但要牢记,不能同时使用基于数量和基于权重的淘汰策略。
参考
- HBase LRUBlockCache与BucketCache二级缓存机制原理剖析与参数调优-OLAP商业环境实战
- MySQL是如何对LRU算法进行优化的?又该如何对MySQL进行调优?
- Caffeine高性能缓存设计
- 缓存之路-Caffeine的原理
- 动手实现 LRU 算法,以及 Caffeine 和 Redis 中的缓存淘汰策略
以上是关于LRU算法在MySQL/hbase/Caffeine 中的优化的主要内容,如果未能解决你的问题,请参考以下文章