二分查找在RocketMQ和Kafka中的应用
Posted 不识君的荒漠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二分查找在RocketMQ和Kafka中的应用相关的知识,希望对你有一定的参考价值。
二分查找
二分查找是在有序元素中找到目标元素或最终未找到返回。
算法模板如下:
public int indexOf(int[] nums, int target)
int left = 0, right = nums.length - 1;
while (left <= right)
// 实际情况下担心溢出,可以这样写:mid = left + (right - left) / 2;
int mid = (left + right) / 2;
// 找到目标值了,返回该索引
if (nums[mid] == target)
return mid;
// 目标值可能在nums[mid] ~ nums[right] 之间
else if (nums[mid] < target)
left = mid + 1;
else
// 目标值可能在nums[left] ~ nums[mid] 之间
right = mid - 1;
return -1;
二分查找也算是比较基本的查找算法,这里不再赘述了。
在RocketMQ中的应用
RocketMQ的消费队列
在聊之前,还是先简单的看下RocketMQ的存储结构,下面这张图片来自官方文档:https://github.com/apache/rocketmq/blob/develop/docs/cn/image/rocketmq_design_1.png
{kind=link}
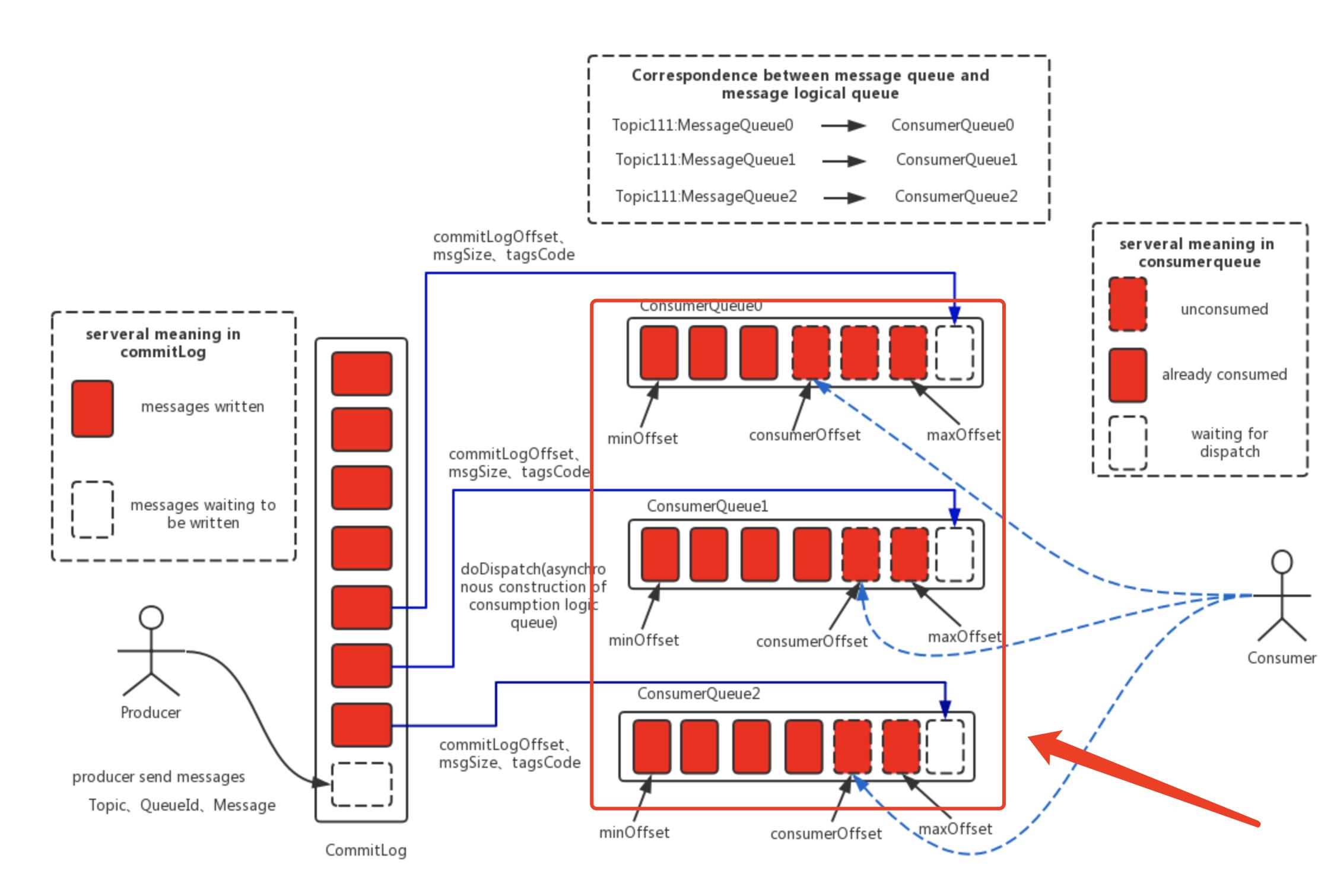
本文关注的重点是消费队列这部分,官方说明如下:
(2) ConsumeQueue:消息消费队列,引入的目的主要是提高消息消费的性能,由于RocketMQ是基于主题topic的订阅模式,消息消费是针对主题进行的,如果要遍历commitlog文件中根据topic检索消息是非常低效的。Consumer即可根据ConsumeQueue来查找待消费的消息。其中,ConsumeQueue(逻辑消费队列)作为消费消息的索引,保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值。consumequeue文件可以看成是基于topic的commitlog索引文件,故consumequeue文件夹的组织方式如下:topic/queue/file三层组织结构,具体存储路径为:$HOME/store/consumequeue/topic/queueId/fileName。同样consumequeue文件采取定长设计,每一个条目共20个字节,分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode,单个文件由30W个条目组成,可以像数组一样随机访问每一个条目,每个ConsumeQueue文件大小约5.72M;
p.s. 其实RocketMQ的源码里的文档很完善的,每次有同学需要了解 rocketmq的时候,我都会推荐他们先去把源码下载下来看下里面的文档。
简而言之,消费队列可以认为存储的是实际消息的索引信息,消息内容实际是存储在commit log里。就有点类似字典的目录,方便在书本里检索想要查找的汉字,和字典不同的是,每一条消息都会在消费队列里有对应的索引信息。
二分查找的使用
RocketMQ在根据时间戳查询消息的时候,采用的是二分查找的算法。
因为消费队列里存储的每条消息的索引信息,都是根据时间有序存储的。
在1个消费队列里,我们可以通过比对索引信息对应消息的时间戳,采用2分查找的算法检索相关的索引信息来找到目标消息的偏移。
源码位置:org.apache.rocketmq.store.ConsumeQueue#getOffsetInQueueByTime
这部分代码我已经加好了注释,如下,感兴趣可以耐心看一下:
public long getOffsetInQueueByTime(final long timestamp)
// 获取最后访问时间小于当前时间戳的消费队列文件,这里我更好奇的是如果把所有消费队列文件清完重新生成,会有什么问题
MappedFile mappedFile = this.mappedFileQueue.getMappedFileByTime(timestamp);
if (mappedFile != null)
// 下面所有的offset表示的是"逻辑"物理位置,打个比方,每条索引信息大小为20个字节,第3条消息的索引位置为(3-1)*20=40,表示的是文件的物理写入位置
// 而不是第几条消息的索引信息,所以这个变量很误导人,消息偏移用offset,文件写入位置用pos多好,这里也用offset
long offset = 0;
// 消费队列文件的命名方式和commit log一样,都是以写入位置命名,所以是一个"逻辑"的物理位置。
// 打个比方,第一个文件,从第一条消息写入,写入位置为0,文件名就是0,写入3条消息后,当前文件满了,开始写入下一个文件
// 下一个文件的名则是60,因为要写入的第4条消息,在逻辑上的物理位置是(4-1)*20,当然的在当前的文件中是从物理位置0开始从头写入的
int low = minLogicOffset > mappedFile.getFileFromOffset() ? (int) (minLogicOffset - mappedFile.getFileFromOffset()) : 0;
int high = 0;
int midOffset = -1, targetOffset = -1, leftOffset = -1, rightOffset = -1;
// 我们是要根据时间戳来查找消息,但是很有可能这个时间点是没有消息的,所以这两个变量是用来标记离查询的时间戳最近的前、后两个时间,到时候谁更接近就返回谁的
long leftIndexValue = -1L, rightIndexValue = -1L;
// 目前commit log中最小的写入位置,其实就是最早那个的commit log文件 的文件名表示的位置
long minPhysicOffset = this.defaultMessageStore.getMinPhyOffset();
SelectMappedBufferResult sbr = mappedFile.selectMappedBuffer(0);
if (null != sbr)
ByteBuffer byteBuffer = sbr.getByteBuffer();
// 表示当前消费队列中,最后一条索引消息的写入位置,比如文件大小为100,可以写入5要索引数据,最后一条的起始位置是80
high = byteBuffer.limit() - CQ_STORE_UNIT_SIZE;
try
while (high >= low)
// 这是计算mid的那条索引的写入的起始物理位置
midOffset = (low + high) / (2 * CQ_STORE_UNIT_SIZE) * CQ_STORE_UNIT_SIZE;
byteBuffer.position(midOffset);
// 每一个条目共20个字节,分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode
// 下面拿到该索引的消息的在commit log中的逻辑位置
long phyOffset = byteBuffer.getLong();
int size = byteBuffer.getInt();
// 这说明该消息对应的commit log文件可能已经过期删除了,所以该消息已经不存在了
if (phyOffset < minPhysicOffset)
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
continue;
// 根据索引里的逻辑位置,可以计算出在哪个commit log及物理位置,根据大小,获取这条消息,然后得出存储的时间戳
long storeTime =
this.defaultMessageStore.getCommitLog().pickupStoreTimestamp(phyOffset, size);
if (storeTime < 0)
// 如果找不到或者错误,返回的是-1,这里就直接返回了
return 0;
// 下面这一部分就是2分查找了,和我们学习的简单2分查找的区别只是,这里的步长是一个索引的长度,20个字节
else if (storeTime == timestamp) // 刚好找到了
targetOffset = midOffset;
break;
else if (storeTime > timestamp)
high = midOffset - CQ_STORE_UNIT_SIZE;
rightOffset = midOffset;
rightIndexValue = storeTime;
else
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
leftIndexValue = storeTime;
if (targetOffset != -1)
// 不是-1,这是找到了
offset = targetOffset;
else
// 下面是没有找到,就获取离目标时间最近的那个时间的偏移
if (leftIndexValue == -1)
offset = rightOffset;
else if (rightIndexValue == -1)
offset = leftOffset;
else
offset =
Math.abs(timestamp - leftIndexValue) > Math.abs(timestamp
- rightIndexValue) ? rightOffset : leftOffset;
return (mappedFile.getFileFromOffset() + offset) / CQ_STORE_UNIT_SIZE;
finally
sbr.release();
return 0;
在这里再说几句题外话,其实上面这段代码我很早之前第一次看的时候,对于里面的变量名,感觉是很懵的。
在rocketmq里消息偏移有不少地方都用的是offset之类表示的(看得多了,我潜意识就这样认为了),而消息的物理(逻辑)文件位置用的是position之类的变量名,在这个地方计算的都是逻辑或物理写入位置,但变量名上都带个offset,第一次差点看蒙了。
还有个问题是,这次在写这篇博文时,我给代码加注释的时候,想起我很早之前提到过的一个issue,有兴趣可以自己看下:getOffsetInQueueByTime return the max offset when time greater than the storetime of last message #2661
因为下面还有Kafka部分的内容,为了和kafka形成对比,就再说明下,如何根据消费偏移检索消息。
一条消费队列内的索引是连续有序(写入顺序)的,类似一个数组,直接通过索引信息的大小乘以对应的偏移量,便可以得到对应的索引位置获取索引数据,进而得到实际的消息信息。
获取消费队列的索引代码如下,很简单,就不加注释说明了:
public SelectMappedBufferResult getIndexBuffer(final long startIndex)
int mappedFileSize = this.mappedFileSize;
long offset = startIndex * CQ_STORE_UNIT_SIZE;
if (offset >= this.getMinLogicOffset())
MappedFile mappedFile = this.mappedFileQueue.findMappedFileByOffset(offset);
if (mappedFile != null)
SelectMappedBufferResult result = mappedFile.selectMappedBuffer((int) (offset % mappedFileSize));
return result;
return null;
在Kafka中的应用
Kafka的索引
关于kafka的存储结构看官方文档:Apache Kafka,官方文档这里因为不涉及对索引部分的详细说明,我就简单说下,下图来自官方文档:
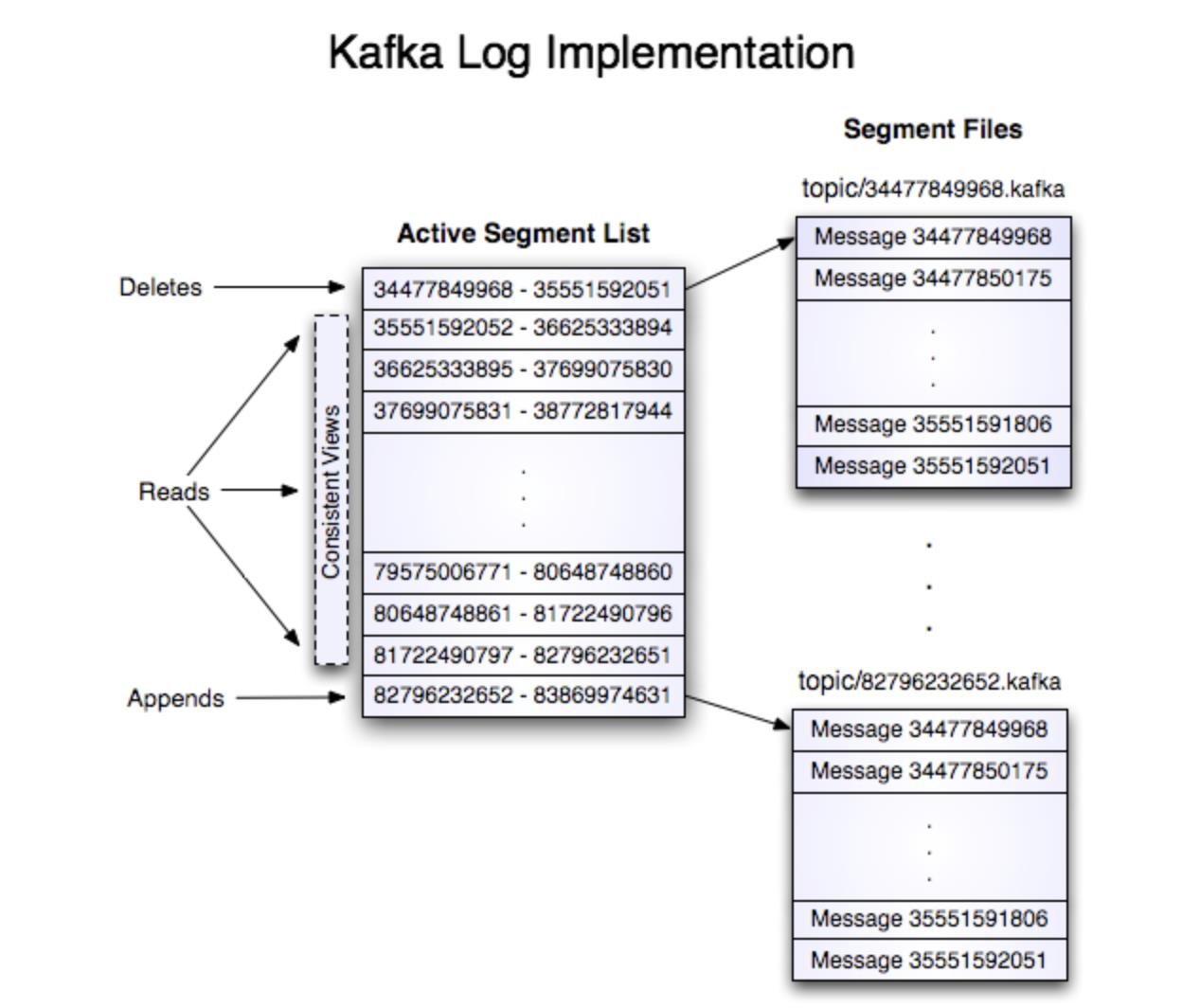
kafka每个topic的每个分区目录下有单独的存储消息数据的log文件和对应的索引文件。
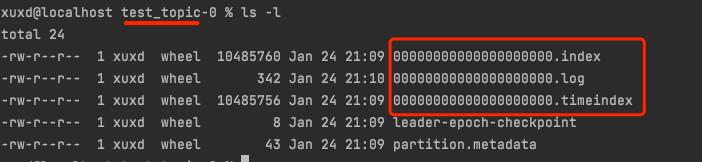
- 0.log存储当前分区实际的消息数据
- 0.index是位移索引
- 0.timeindex是时间戳索引
位移索引里每条数据的格式大概是这样:<消息相对位移值,消息在物理文件上的写入位置>
时间戳索引第条数据的格式是:<时间戳,消息相对位移值>
所以根据时间戳检索消息的时候,是先找到该时间对应的消息位移,再读取具体的消息内容。
p.s. 因为我没启用事务,所以上面没事务索引文件。
下面的所有说明都是来自我几个月前下载的trunk分支的代码,当时版本是3.1.0-SNAPSHOT,kafka代码变动太快,所以这里注明一下。
二分查找的使用
和rocketmq不同的是,无论是根据位移还是时间戳,kafka的消息检索都是采用二分查找,而且调用的是同一个方法,看一下方法调用关系:
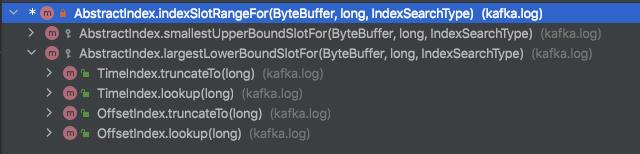
这个方法的源码在:kafka.log.AbstractIndex#indexSlotRangeFor
这部分代码我也加了注释,感兴趣可以耐心看下:
private def indexSlotRangeFor(idx: ByteBuffer, target: Long, searchEntity: IndexSearchType): (Int, Int) =
// 索引项是空的
if(_entries == 0)
return (-1, -1)
// 二分查找
def binarySearch(begin: Int, end: Int) : (Int, Int) =
// binary search for the entry
var lo = begin
var hi = end
while(lo < hi)
// >>> 无符号右移一位,我估计是为了避免溢出吧。(lo + hi + 1)可能溢出,这应该是lo + (hi - lo) / 2的替代方案吧
val mid = (lo + hi + 1) >>> 1
// parseEntry在位移索引和时间戳索引中是不同的实现
val found = parseEntry(idx, mid)
val compareResult = compareIndexEntry(found, target, searchEntity)
if(compareResult > 0)
hi = mid - 1
else if(compareResult < 0)
lo = mid
else
return (mid, mid)
// 如果是最后一条,hi是-1,不要多想,没太多深意,就是一个标记,上层调用这个方法的时候,看见-1,知道是没有比它更大的条目了
(lo, if (lo == _entries - 1) -1 else lo + 1)
// kafka在这里做了个冷热分区的查找优化,_warmEntries=8192/(index entry size),这个索引大小,位移索引应该是8,时间戳索引应该是12
// 关于为什么选择8192也就是8KB大小作为热区,看代码最上面的注释,写的比较清楚了
val firstHotEntry = Math.max(0, _entries - 1 - _warmEntries)
// check if the target offset is in the warm section of the index
// 在热区查找
if(compareIndexEntry(parseEntry(idx, firstHotEntry), target, searchEntity) < 0)
return binarySearch(firstHotEntry, _entries - 1)
// check if the target offset is smaller than the least offset
if(compareIndexEntry(parseEntry(idx, 0), target, searchEntity) > 0)
return (-1, 0)
// 冷区查找
binarySearch(0, firstHotEntry)
关于kafka的这个二分查找,比较突出的就是这个冷热分区查找的优化。
我们现在用的大部分操作系统,page cache的置换策略大多是LRU或它的变体。对于冷热分区的这个优化,注释里有一个示例进行了说明,如下:
For example, in an index with 13 pages, to lookup an entry in the last page (page #12), the standard binary search algorithm will read index entries in page #0, 6, 9, 11, and 12. page number: |0|1|2|3|4|5|6|7|8|9|10|11|12 | steps: |1| | | | | |3| | |4| |5 |2/6| In each page, there are hundreds log entries, corresponding to hundreds to thousands of kafka messages. When the index gradually growing from the 1st entry in page #12 to the last entry in page #12, all the write (append) operations are in page #12, and all the in-sync follower / consumer lookups read page #0,6,9,11,12. As these pages are always used in each in-sync lookup, we can assume these pages are fairly recently used, and are very likely to be in the page cache. When the index grows to page #13, the pages needed in a in-sync lookup change to #0, 7, 10, 12, and 13: page number: |0|1|2|3|4|5|6|7|8|9|10|11|12|13 | steps: |1| | | | | | |3| | | 4|5 | 6|2/7| Page #7 and page #10 have not been used for a very long time. They are much less likely to be in the page cache, than the other pages. The 1st lookup, after the 1st index entry in page #13 is appended, is likely to have to read page #7 and page #10 from disk (page fault), which can take up to more than a second. In our test, this can cause the at-least-once produce latency to jump to about 1 second from a few ms.
可能有的同学,也没耐心看这个,我简单说下,写入的最新消息等待副本同步,消费者拉取消费,这些最新消息的索引会经常访问,肯定是在操作系统的缓存里,所以把最新消息的8KB索引信息作为热区,其它的索引信息是在冷区,因为不经常访问的可能被操作系统置换出去了,如果查找的时候,会出现缺页错误,操作系统要重新从磁盘加载到缓存里。
所以查找索引数据的时候先看下有没有在热区,就是这个索引是不是最新的那几百条索引里,如果在热区,就对热区进行二分查找。
如果在冷区,可能这些索引在进行二分查找的时候,需要重新从磁盘加载到操作系统的page cache,比较影响性能。
一般情况下,最新的消息同步或者是没有积压,消费最新的消息,这些消息的索引都是在热区的。
p.s. kafka这个冷热分区的方案,让我在参加去年的天池大赛时,对于冷热数据处理上提供了一个很好的idea。
以上是关于二分查找在RocketMQ和Kafka中的应用的主要内容,如果未能解决你的问题,请参考以下文章