BEV感知PETR-V1和PETR-V2
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BEV感知PETR-V1和PETR-V2相关的知识,希望对你有一定的参考价值。
参考代码:PETR
1. 概述
介绍:这两篇文章提出了以位置编码转换(PETR,position embedding transformation)为基础的BEV感知方法,按照方法中组件不同可将PETR划分为V1和V2版本。在V1版本中提出了基础版本的PETR,首先使用一种类似LSS的方法构建相机视锥,里面编码了图像中每个点在不同深度下的3D空间位置,这些3D空间位置经过编码网络之后(几层1*1的卷积)得到3D空间位置的embedding编码,embedding编码再与2D相机特征做融合将3D空间位置信息嵌入到2D图像特征中去,最后在生成的特征图上使用DETR方法检测3D目标。V2版本相对V1版本增加了时间序列的支持,特别的是对于时序带来位置空间相对变化导致的位置不匹配问题,对于该问题文章通过pose变换对齐的方式实现特征图对齐。在下游任务中除了3D目标检测任务之外,还引入了分割分支。
2. BEV特征提取
2.1 PETR-V1
在V1版本中数据处理流程见下图所示:
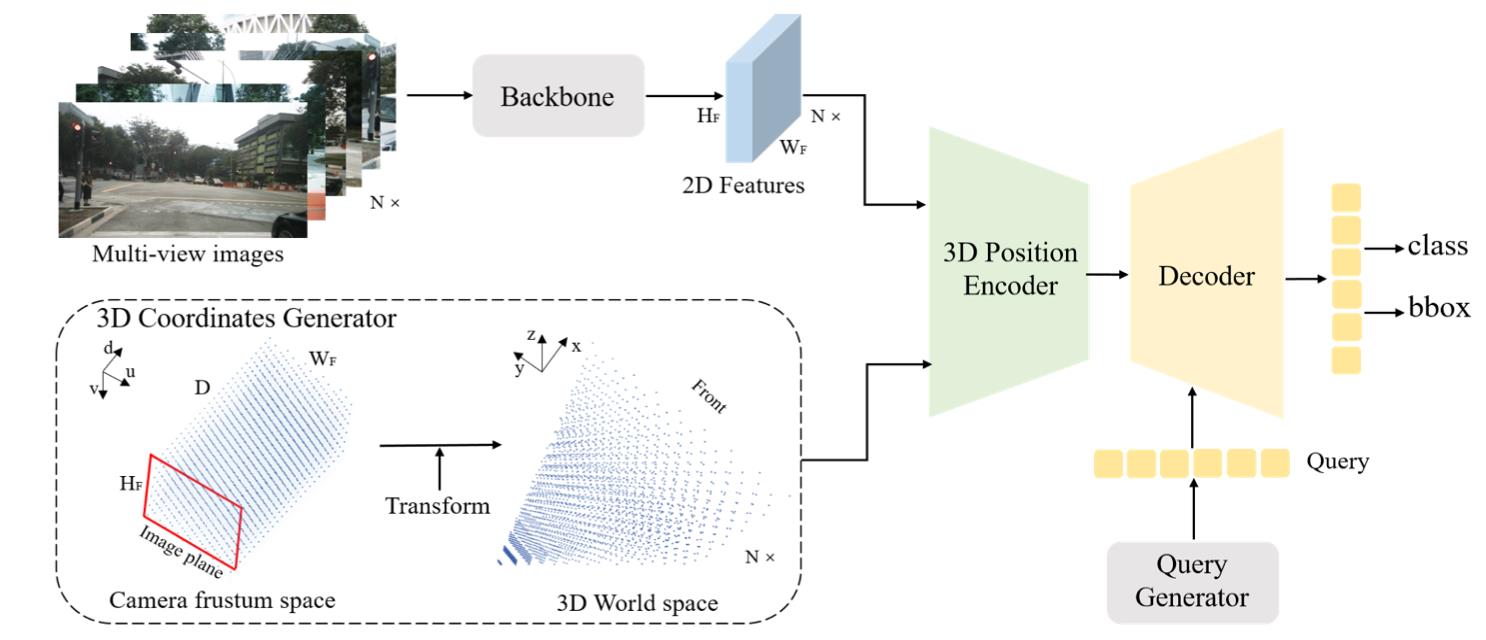
对于2D图像可以根据相机内外参数和假定的3D空间范围内生成相机视锥数据,对应上图中的3D Coordinates Generator部分,3D视锥数据再与图像2D图像特征融合得到具备感知3D位置信息的2D图像特征,之后在接下游检测任务。这里的核心便是如何将3D位置信息如何添加到2D中,与之对应的部分便是上图中的3D Position Encoder。该部分的具体结构见下图所示:
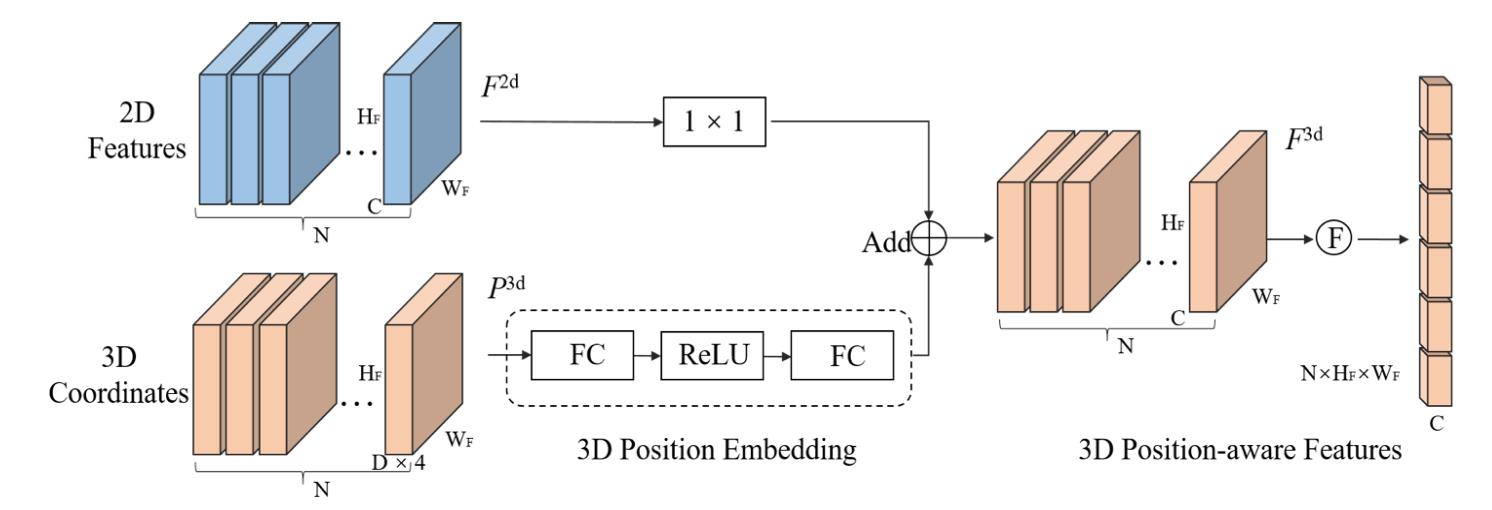
对于图像特征生成的视锥数据维度为
P
3
d
=
P
i
3
d
∈
R
(
D
∗
4
)
∗
H
F
∗
W
F
P^3d=\\P_i^3d\\in R^(D*4)*H_F*W_F\\
P3d=Pi3d∈R(D∗4)∗HF∗WF,其中
W
F
,
H
F
W_F,H_F
WF,HF代表生成视锥时特征图的宽高,
D
D
D代表深度划分的steps。这些数据经过几个
1
∗
1
1*1
1∗1的卷积之后得到3D位置编码,再与图像2D特征相加便使得2D图像特征中嵌入了3D位置信息。对于产生位置编码时使用的操作,以及3D位置编码和2D图像特征融合操作,它们对性能带来的影响见下表:
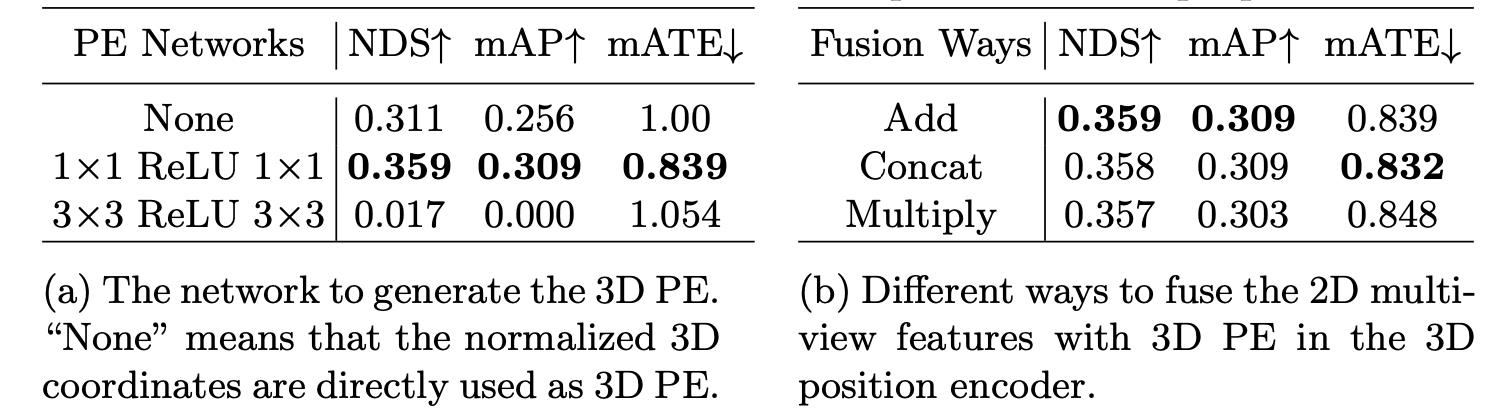
其中感到惊讶的是
3
∗
3
3*3
3∗3的卷积竟然带来这大的负收益-_-||。
2.2 PETR-V2
2.2.1 网络结构
V2版本在V1版本上添加了对时序的支持,但是引入时序信息带来的问题便是在不同时刻下图像物体的3D相对位置是不一致的。这就要求在新版的PETR中对图像中的3D位置信息进行了对齐,对于对齐文中是使用pose变换的形式实现的。同时对于3D位置编码还引入了2D图像特征引导的attention操作用于优化3D位置编码。
在V2版本中算法的流程图见下图所示:
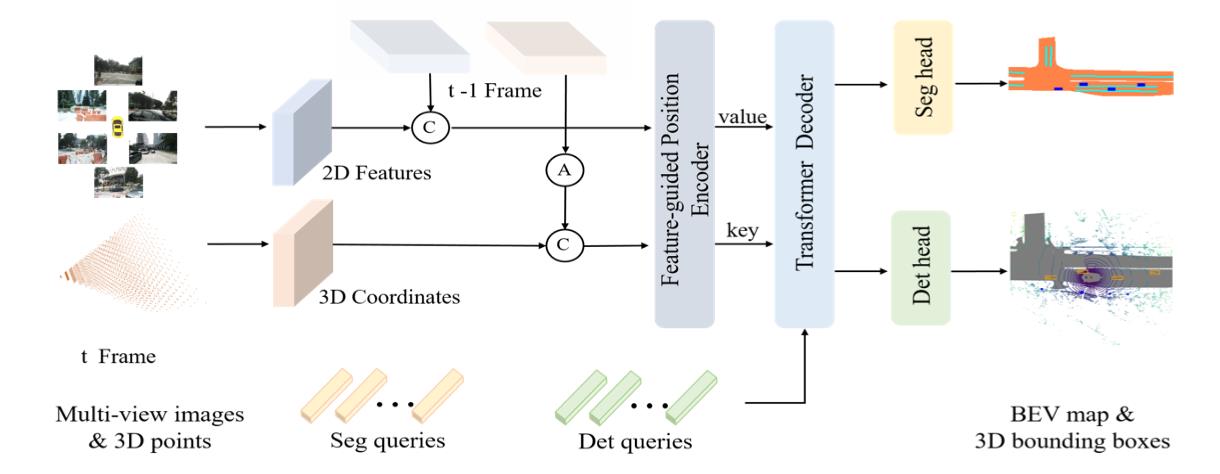
可以看到在图像的数据输入端添加了来自之前时序的数据。对于2D图像域的数据是直接通过concat组合起来,但是对于3D位置编码数据就不是直接这样处理了,其通过pose变换使其在车体坐标下对齐,也就是下图所示的样子:
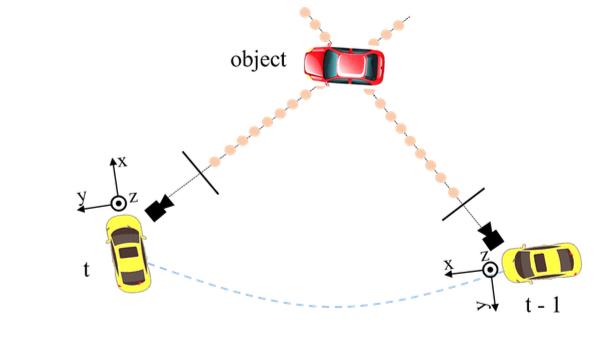
将
t
t
t时刻的相机坐标系记为
c
(
t
)
c(t)
c(t),激光雷达坐标系
l
(
t
)
l(t)
l(t),车体坐标系
e
(
t
)
e(t)
e(t),全局坐标系
g
g
g。对于一个从src到dst的变换记为
T
s
r
c
d
s
t
T_src^dst
Tsrcdst。则从图像坐标系到激光雷达坐标系的变换为:
P
i
l
(
t
)
(
t
)
=
T
c
i
(
t
)
l
(
t
)
K
i
−
1
P
m
(
t
)
P_i^l(t)(t)=T_c_i(t)^l(t)K_i^-1P^m(t)
Pil(t)(t)=Tci(t)l(t)Ki−1Pm(t)
而激光雷达坐标系下
t
−
1
t-1
t−1到
t
t
t的变换描述为:
P
i
l
(
t
)
(
t
−
1
)
=
T
l
(
t
−
1
)
l
(
t
)
P
i
l
(
t
−
1
)
(
t
−
1
)
P_i^l(t)(t-1)=T_l(t-1)^l(t)P_i^l(t-1)(t-1)
Pil(t)(t−1)=Tl(t−1)l(t)Pil(t−1)(t−1)
其中的变换矩阵是借用了车体坐标系和全局坐标系作为中间变量迭代得到的:
T
l
(
t
−
1
)
l
(
t
)
=
T
e
(
t
)
l
(
t
)
T
g
e
(
t
)
T
g
e
(
t
−
1
)
−
1
T
e
(
t
−
1
)
l
(
t
−
1
)
−
1
T_l(t-1)^l(t)=T_e(t)^l(t)T_g^e(t)T_g^e(t-1)^-1T_e(t-1)^l(t-1)^-1
Tl(t−1)l(t)=Te(t)l(t)Tge(t)Tge(t−1)−1Te(t−1)l(t−1)−1
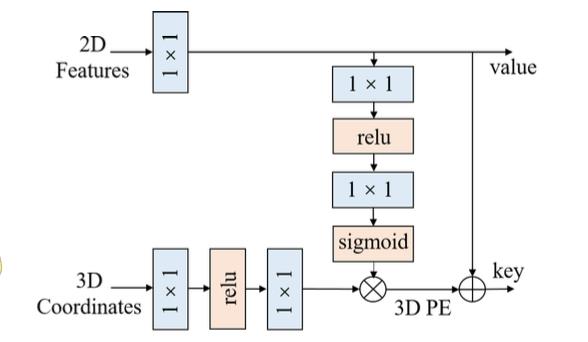
在V2版本中通过2D特征给3D位置编码做attention优化,也就是使用下图中的结构实现:
2.2.2 鲁棒性分析
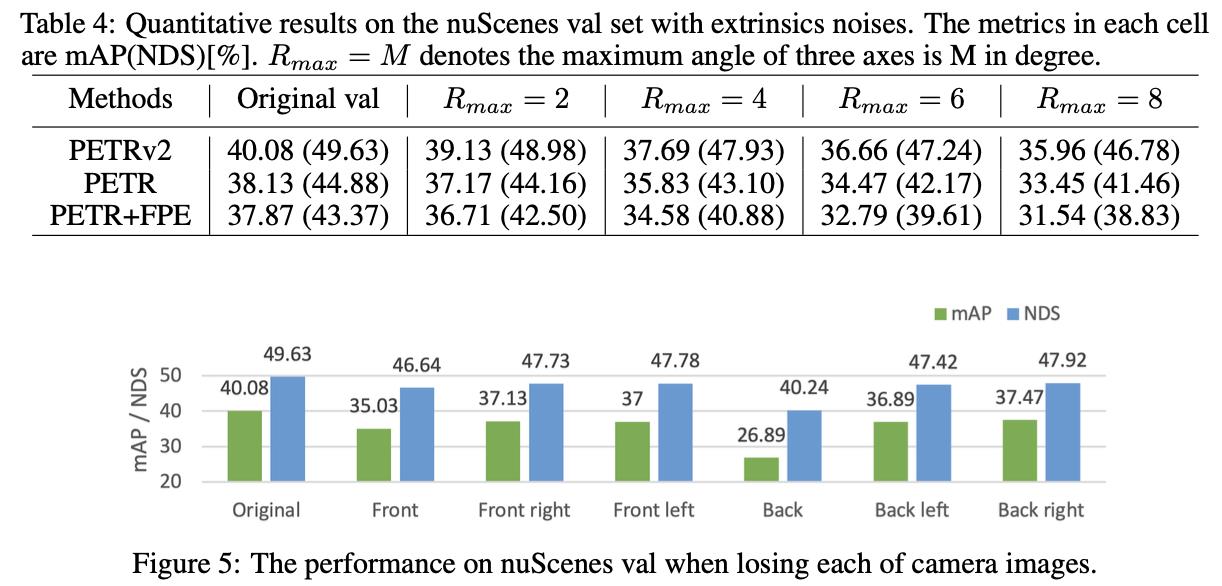
此外,文章还分析了相机外参、相机缺失、时序对齐异常情况进行分析,从下表中可以观察网络的鲁棒性:

3. 下游任务
3.1 PETR-V1
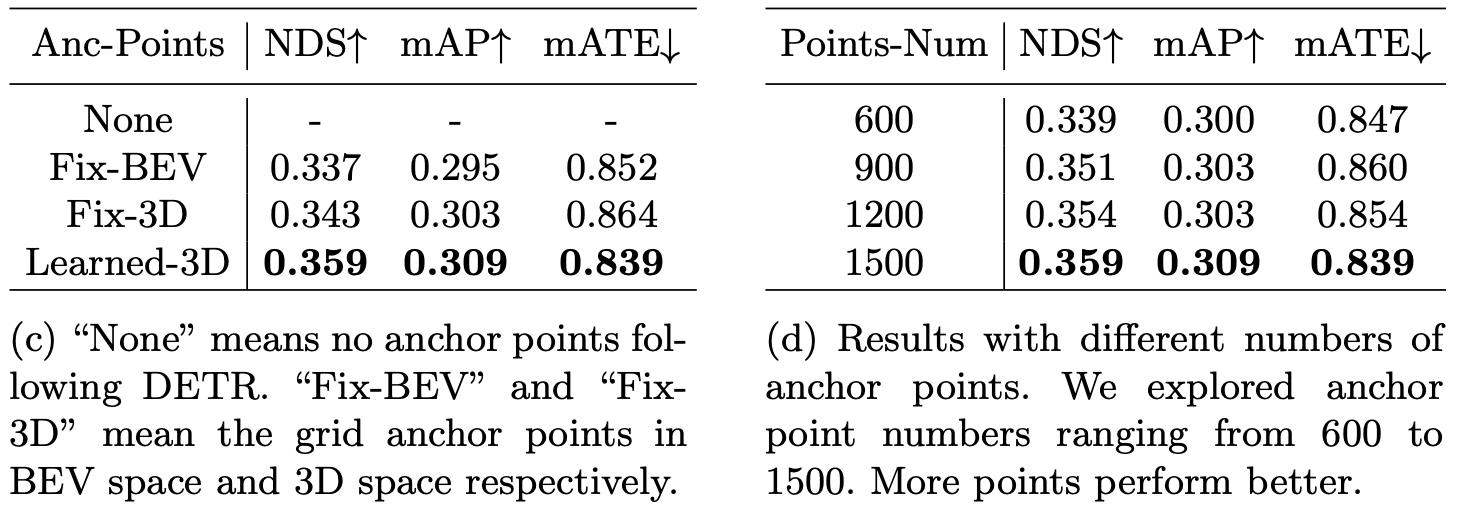
在V1版本中下游检测任务DETR的anchor point类型和transformer decoder中points-num对向能的影响:
PETR收敛性和速度分析:
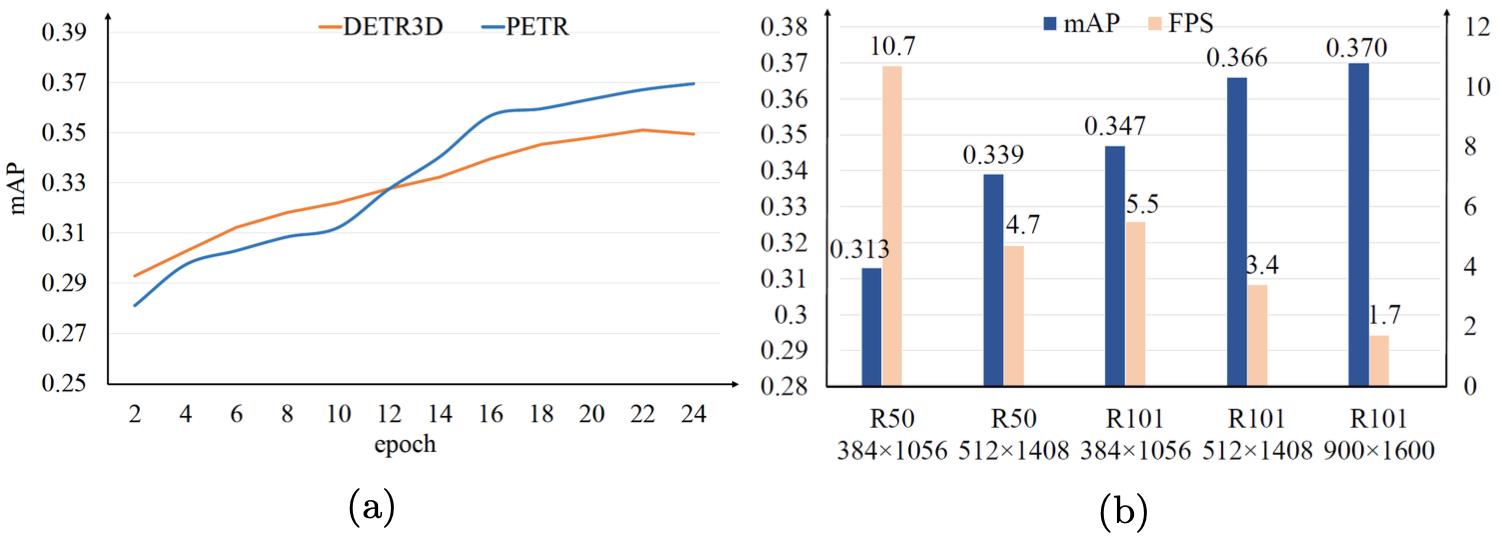
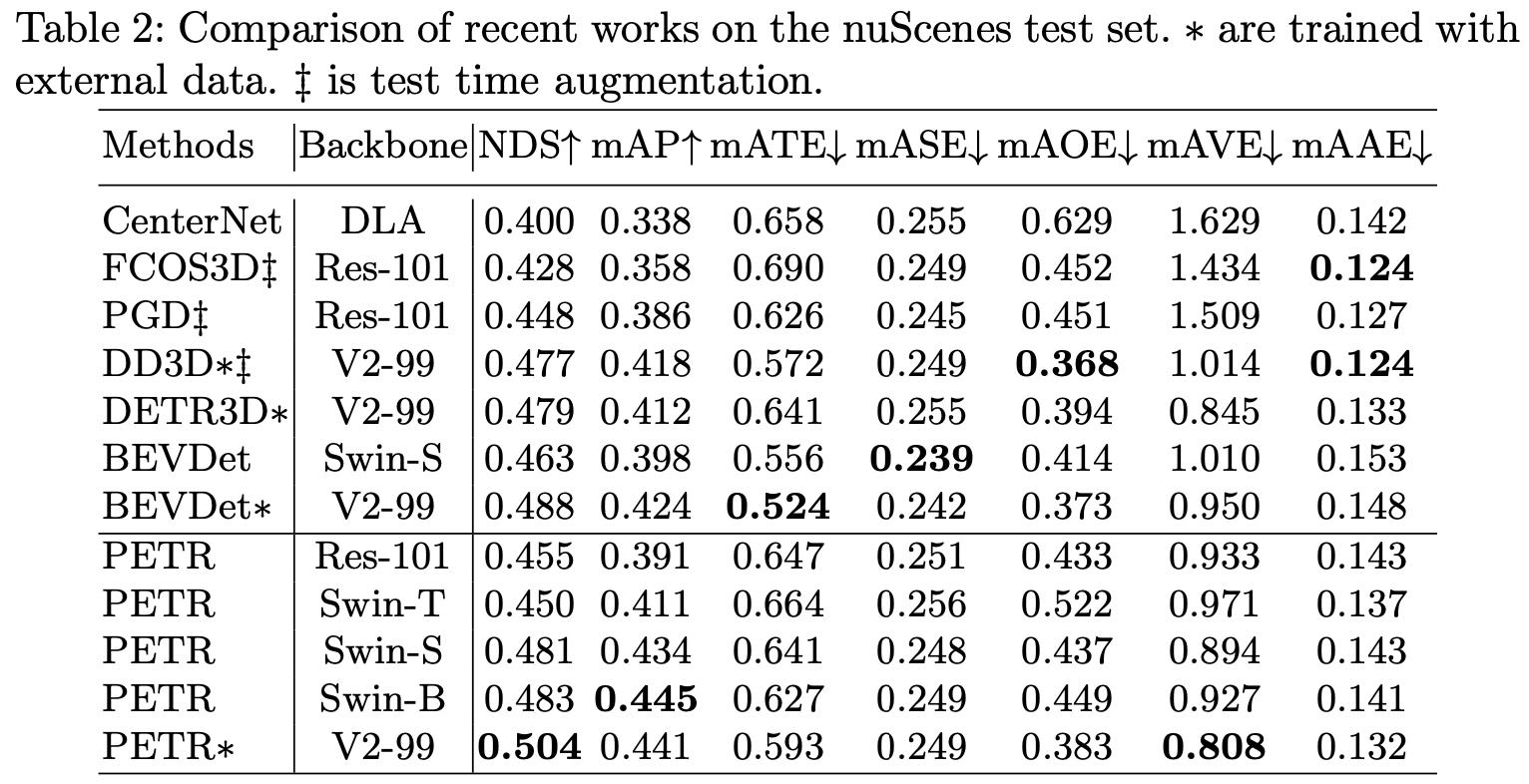
在nuScenes test下的性能比较:
3.2 PETR-V2
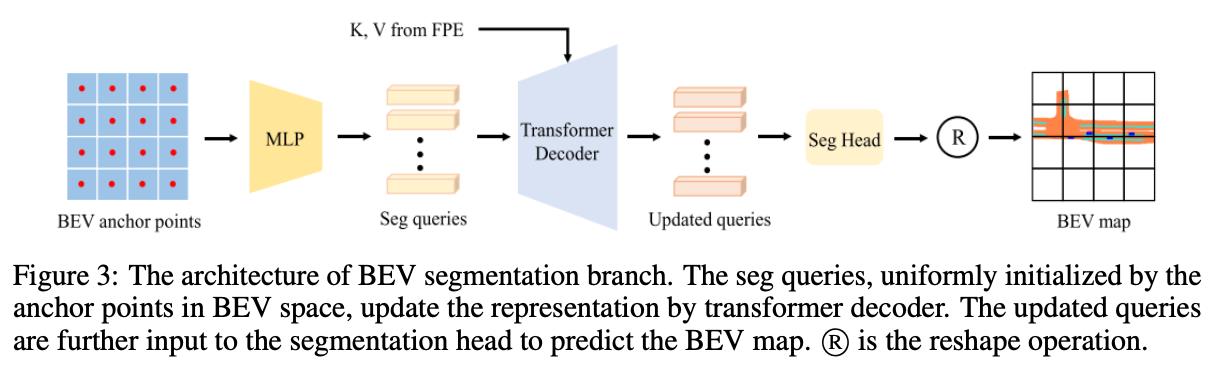
V2的版本在V1基础上添加了分割分支,这里为了减少计算量对分割query的数量进行限制,使用一个query代表一个
16
∗
16
16*16
16∗16大小的网格,之后这个query负责这个区域的分割任务,其流程见下图所示:
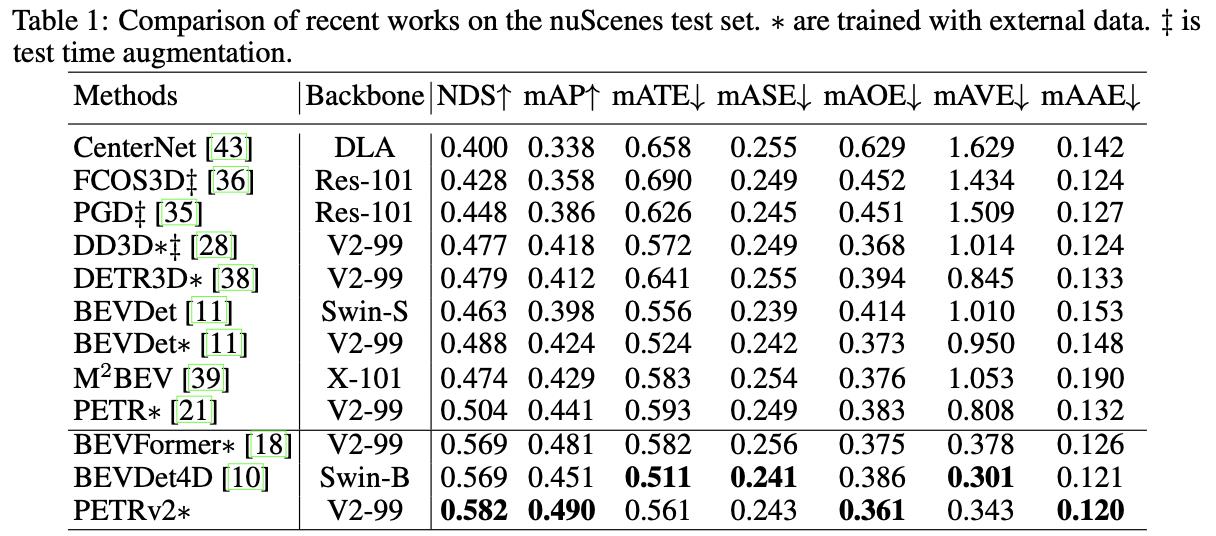
nuScenes下检测检测性能比较:
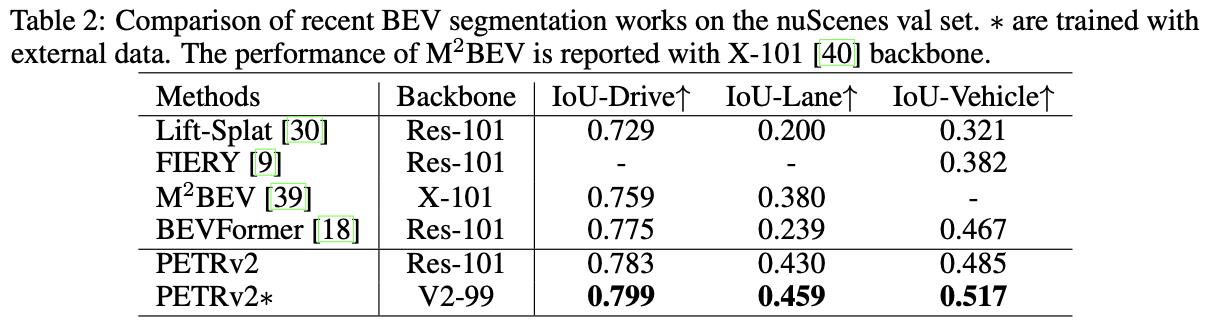
nuScenes下分割性能比较:
以上是关于BEV感知PETR-V1和PETR-V2的主要内容,如果未能解决你的问题,请参考以下文章