用PS的照片申请理赔,保险公司能过吗?
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用PS的照片申请理赔,保险公司能过吗?相关的知识,希望对你有一定的参考价值。

摘要:保险作为当今风险保障的重要手段,已然成为众多企业、个人的选择。作为风险保障的主体,保险公司在承保、理赔等各类业务处理中,都离不开影像资料。影像资料已然成为保险公司大数据浪潮中不容忽视的重要数据要素。如何做好影像资料的自动识别、真假判定等成为保险公司降本增效、风险防范的重要课题。本文就保险行业的影像资料技术和应用给出探讨。
作者 | 周咸立 刘平 责编 | 杨阳
出品 | 《新程序员》编辑部
近来,车联网、云计算、大数据、人工智能、区块链这些新技术将给保险业带来新一轮变革已成为共识。随着这些新技术逐渐成熟,行业内对这些技术应用前景既充满期待又存在担忧。如何把握这些新技术使其助力公司业务发展,及时掌控新技术引起的商业模式变化,避免企业错失新技术应用带来的新商机,这些促使各保险公司在新技术应用上不断地努力尝试和创新。
影像资料在保险行业中扮演着重要的角色,尤其在核保、核赔环节,需要查阅并判断其真实性。例如,对于提供的出险照片检查是否为PS加工或翻拍的照片。随着业务的发展,人工审核显得力不从心,如何控制影像风险,实现降本增效,提升风控能力,是保险公司高质发展中需要新技术来赋能助力的。
面对海量的非结构化影像资料快速检索与智能识别的需求,传统的影像处理模式无法满足当前业务对功能和效率的要求。影像处理的业务内容已不限于文字和少量图片,而是大量影像资料(包括静态图片、音频、视频资料等)。在系统功能上,不限于查看图片,而是要对大量影像资料进行快速检索、对不符合规范的图像进行加工处理和识别;在反欺诈上,不限于人工对比查看,而是要对大量影像文件进行相似图像识别;在系统访问上,全国的频繁、大数据量访问,传统方式对网络带宽需求很高、加上带宽使用费用高,种种局限与不足亟待解决。
原有影像方案中,着重解决的是海量影像的采集、存储、传输、查看等问题,主要使用大数据和云计算的技术,对于影像本身的深层次处理还有许多不足,不能通过系统高可靠地智能处理以下场景:识别不清晰照片、识别翻拍照片、图像篡改检测、相似图像识别、自动分类等。在当期技术下,人工智能技术的发展使得这些成为现实,同时图像篡改检测等AI技术提高了影像本身的可靠性,AI+OCR的智能识别模式也就有了更高的业务价值。

影像系统的智能识别应用
如图1所示,在影像系统中,智能识别主要应用在的几种服务中:

图1 智能识别在影像中的应用
图像质量识别:主要识别图像是否清晰,是否为翻拍处理图片。
图像篡改识别:检查图片是否被局部修改,并标记修改位置。
图像分类识别:用于识别图像类型,例如证件、银行卡、发票、医疗单据等,根据识别结果完成单证自动分类。
相似影像识别:识别图像的相似性,在上传影像文件时,系统对图像文件进行归一化处理,提取图像本身的颜色、形状、纹理等底层特征,进行相似度计算,将识别结果反馈给影像系统。可以用于车险、农险等核赔、核保环节,对场景过程影像进行自动甄别,智能风险提示,保证影像文件的真实性,及时拦截虚假赔案,提升了风险控制能力,节省人力成本,降低理赔赔付率。
OCR服务:提供对自然场景下的文字、单据、证明、复杂表格及各种混合模式的图片进行文字识别,可以供周边系统调用,通常用于辅助录入、人工双录等场景。
合同对比识别:提供pdf、doc/docx、wps、xls和图片等主流格式文件对比,支持以全篇幅、整段落的方式进行比对,支持跨页、跨行的文字比对。
医疗票据识别:医疗票据的特点就是种类多。医疗票据识别实现对电子病历的自动标签标注、智能分类、快速梳理以及复杂电子病历的半自动阅读。提供全方位智能风控引擎,实现基于保险产品的过程分控管理,支持高风险案件自动预警的机制。
有了业务需求,考虑应用场景,下一步考察的就是合适的技术支撑。目前影像处理在各主要场景下各有一些可供选择的技术。

图像清晰度识别(Image Blur Detection)
在影像收集过程中,会出现拍摄物品不清晰,文字模糊的现象,影响业务判断,对于不清晰的图像需要及时拒绝上传。
图像清晰度评价算法有很多种,在空域中,主要思路是考察图像的领域对比度,即相邻像素间的灰度特征的梯度差;在频域中,主要思路是考察图像的频率分量,对焦清晰的图像高频分量较多,对焦模糊的图像低频分量较多。
实现清晰度评价的3种方法[1]:Tenengrad梯度方法、Laplacian梯度方法和方差方法。
Tenengrad梯度方法利用Sobel算子分别计算水平和垂直方向的梯度,同一场景下梯度值越高,图像越清晰。
Laplacian梯度是另一种求图像梯度的方法。
方差是概率论中用来考察一组离散数据和其期望(即数据的均值)之间的离散(偏离)程度的度量方法。方差较大,表示这一组数据之间的偏差就较大,组内的数据有的较大,有的较小,分布不均衡;方差较小,表示这一组数据之间的偏差较小,组内的数据之间分布平均,大小相近。对焦清晰的图像相比对焦模糊的图像,它的数据之间的灰度差异应该更大,即它的方差应该较大,可以通过图像灰度数据的方差来衡量图像的清晰度,方差越大,表示清晰度越好。

翻拍检测:摩尔纹识别(Moire Pattern Recognition)
翻拍图像是经过扫描、印刷或者其他具有拍摄功能的设备对真实图像进行翻拍,考虑到对真实图像进行翻拍的过程中,显示媒介自身的特性以及翻拍过程的场景区别,使得翻拍图像与真实图像存在差异,如翻拍图像变形等,翻拍图像表面梯度值与真实图像相比会产生非线性变化,这使翻拍图像表面梯度值产生异常,进而导致翻拍图像中存在的初始直线分布发生变化。因此,提取边缘图像中的初始直线,以便后续在初始直线提取更加准确翻拍像素特征。
翻拍检测实现方法
边缘检测。边缘检测本质上就是一种滤波算法,区别在于滤波器的选择,滤波的规则是完全一致的。基本的边缘算子如Sobel求得的边缘图存在很多问题,如噪声污染没有被排除、边缘线太过于粗宽等。比较先进的边缘检测算子包括Canny算子、Marr-Hildreth算子等。
通过直线检测算法对边缘图像进行直线提取,得到初始直线(直线检测算法包括Hough(霍夫变换)直线检测算法、Freeman(链码)直线检测算法或者尺蠖蠕行算法)。
提取翻拍直线。翻拍直线是指满足直线密集算法判别准则的直线,即直线密集集中且平行,该判别准则包括两条直线的斜率差值小于1°(度),且相邻的平行的两条直线的距离小于预设的距离阈值。直线密集算法中,初始直线需要满足“平行”和“密集集中”这两个条件。对于“平行”这一条件,即两条初始直线的斜率值写入初始直线像素点后,如果斜率差值小于1°(度),则初始直线平行,即满足“平行”的条件。对于“密集集中”这一条件,即计算两条平行直线(初始直线)之间的距离,将满足该距离小于预设的距离阈值的两条直线确定为满足“密集集中”这一条件,也即翻拍直线。

目标检测(Object Detection)
在 计 算 机 视 觉 技 术 领 域中,目标 检 测(Object Detection)是一项非常基础的技术,图像分割、物体追踪、关键点检测等都依赖目标检测。
使用TensorFlow构建YOLO V3目标检测模型[3],相比RCNN构建的自动分类模型,不仅能识别出图像上的多个分类以及更高的准确率,而且能定位分类对应的位置。YOLO V3模型相比其他模型识别速度更快。它在 Pascal Titan X显卡上处理COCO test-dev数据集的图片,速度能达到30 FPS, mAP可达57.9% 。如图2所示,YOLOv3的检测速度非常快,比R-CNN快1000倍,比Fast R-CNN快100倍。在 IoU=0.5的情况下,其mAP值与Focal Loss相当,但检测速度快了4倍。此外,你可以根据你的需要,在只需改变模型的大小而不需要进行重新训练的情况下,就可以轻松地权衡检测速度和准确度。
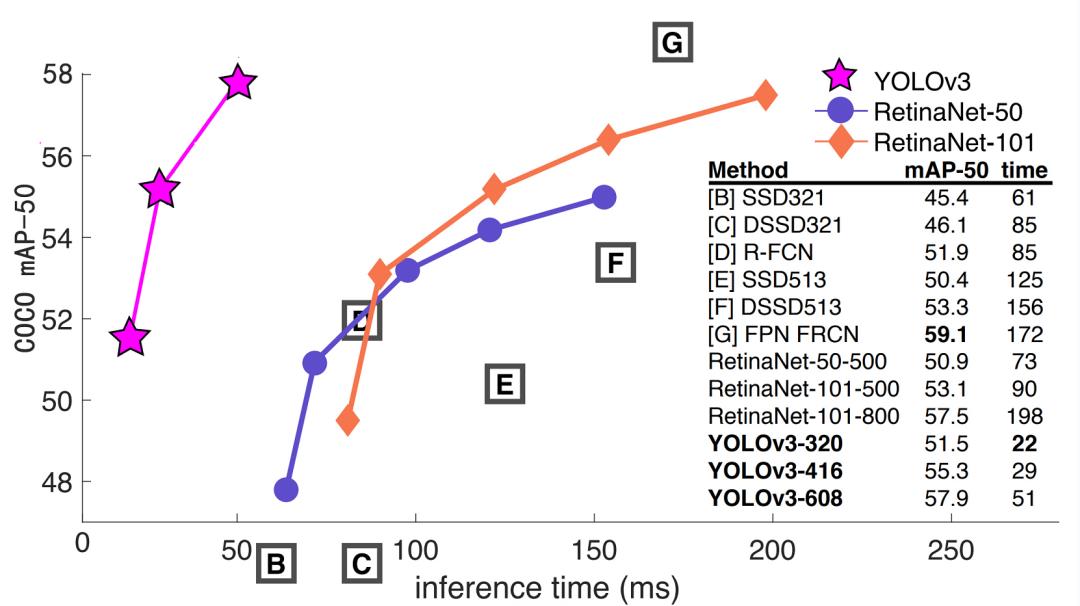
图2 YOLOv3与其他目标检测算法效率对比
即使图片的拍摄质量低、拍摄的角度不同,依然可以准确地识别相应的类别以及对应的位置。

基于内容的图像检索(Content-Based Image Retrieval)
基于内容的图像检索,即CBIR(Content-based image retrieval)[4],是计算机视觉领域中关注大规模数字图像内容检索的研究分支。如图3所示,影像检索系统的图像识别功能主要基于CBIR原理,在上传影像文件时,系统对图像文件进行归一化处理,提取图像本身的颜色、形状、纹理等底层特征,从图像视觉特征出发,在图像大数据库中通过搜索引擎找出与之匹配的图像,并根据检索结果进行相似度计算。

图3 CBIR识别原理
利用CBIR技术识别图像的真实性,识别内容主要包括:
识别图片是否被重复使用。
识别图片是否被PS后重复使用。
上传照片是否为翻拍或裁切图片。
同一批事故车照片是否被使用在不同批次的理赔案件中 。
农险的验标图片是否存在使用相同标的分批拍摄的情况。
如图4所示,二次理赔时,将图片进行PS处理,然后进行理赔申请,通过图像内容检索技术,可以找到原始图片,并标记差异部位。

图4 CBIR识别结果与原图对比
在影像系统中存在一些银行卡、客户身份证件、纸质文件的电子扫描件等图像,而这些类型的图像在多个业务中允许重复出现且该类型文件本身相似度极高,通常不需要进行影像重复使用识别。针对这些类型的影像和应用场景,通过图像主体检测技术,辨识图像是否需要排除识别,从而提高图像内容检索的精准度和效率,确保检索识别的精准度可达到96%以上。

向量搜索(Vector Search)
如图5所示,相似图像检索本质是向量检索技术,影像存储的非结构化数据通过人工智能算法,将数据进行抽象处理,变成多维的向量[5]。这些向量如同数学空间中的坐标,标识着各个实体和实体关系,通过向量搜索,从而找到对应的实体。
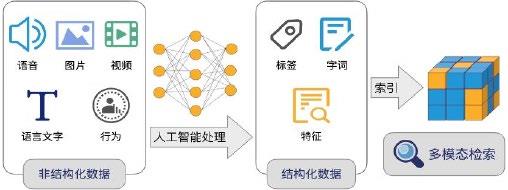
图5 向量检索技术实现过程
向量搜索主要的应用领域如人脸识别、推荐系统、图片搜索、视频指纹、语音处理、自然语言处理、文件搜索等。
随着AI技术的广泛应用,以及数据规模的不断增长,向量检索也逐渐成了AI技术链路中不可或缺的一环,更是对传统搜索技术的补充,并且具备多模态搜索的能力。

图像篡改检测(Image Manipulation Detection)
近年来数字媒体已经成为我们日常生活的一部分,数字媒体内容真伪鉴别的重要性日渐凸显。论文Image Manipulation Detection by Multi-View Multi-Scale Supervision[6]提出了一种新的基于多视角(multi-view)、多尺度 (multi-scale)监督的图像篡改检测模型MVSS Net,可通过检查照片像素、光线、纹理来判断照片是否被修改过。
通常将容易造成视觉误解的图像篡改划分为Copy-move(在同一张图内,复制并移动某一区域), Splicing(从一个图像复制区域到另一图像)和 Inpainting(删除图片内不必要的元素)三种类型, MVSS-Net的目标是自动检测这些类型的操作图像,区分出真实和被篡改图像,并且在像素水平上精确地定位被篡改的区域。
MVSS-Net 首次结合了篡改区域的边界特征和噪声特征以学习泛化性更强的语义无关特征,并使用多尺度监督方式提高对篡改区域的敏感度和对真图的特异度MVSS-Net 在 DEFACTO 数据集上进行了消融实验,在 CASIA,COVERAGE , COLUMBIA ,NIST16和DEFACTO五个公开数据集上进行了实验验证。如图6所示,给出 MVSS-Net 和 SOTA方法在公开数据集上的部分检测结果,前三行依次为:copy-move,splicing,inpainting三类篡改,后三行为真实图片,MVSS-Net在真实图片和篡改图片间取得了好的平衡。实验表明,MVSS-Net在图像级和像素级均达到了state-of-the-art,在获得对篡改区域高精度定位的同时兼顾了对真图更少的误判,是贴合实际应用需求的图像篡改检测方法。

图6 MVSS-Net和SOTA模型在公共数据集中的部分结果

AI-OCR智能识别
传统的OCR已经能够提供精准的文字检测和识别服务,但是其基础是建立在图像本身的可靠上。通过上面介绍的相关技术,AI能够帮助进行翻拍检测、图像篡改检测等,提高了图像本身的可靠性。
AI-OCR智能识别系统采用模型迁移、对抗网络数据生成和FSL技术,结合自身海量的图像资料、标注数据和硬件GPU高性能的运算,搭建深度学习全流程的技术框架闭环,并构建出完整的OCR识别结果方案。包括对各类常规证件信息,例如:身份证、银行卡、行驶证、护照、营业执照、增值税发票、车辆合格证等;非常规证件,例如:银行卡的行内票据、保险业的保单、合同、理赔申请书等的全文本信息识别输出和结构化,简化业务流程,提升工作效率以实现商业化价值最大化。
目前的应用场景主要集中在四十种常用证件类型、各类票据、各类表单文档等模块的识别,整体字符识别率在99%以上,在医疗票据识别和合同对比识别中应用广泛。
医疗票据识别
通过医学自然语言处理、文本挖掘、医学信息词库,实现了对电子病历的自动标签标注、智能分类、快速梳理等技术,实现对复杂电子病历的半自动阅读。并且实现了多项医学信息评估算法和技术,建立了专业的医学知识图片,能够对体检报告等数据进行单病种预测及中和医学数据评估。
业务人员在影像系统采集和分拣医疗票据后把影像文件送给AI-OCR识别系统进行识别、单证分拣和单证脱敏,然后在数据清洗模块对数据进行处理和清洗,最后输出由标准编码确定的、经过清洗的信息和做了对应关系的别名和标准名。
合同对比识别
合同一般使用制式合同,为了防止合同被另一方修改或者篡改,制式合同的出具方需要对合同的全部文字条款审核确认,为此就需要法务人员多次审阅,人工审核合同耗时长,不仅准确率无法保证,而且风险还高,合同智能比对系统可为企业提供有效的技术支撑和安全保障。
合同比对基于OCR智能识别技术,将定稿合同和用印前(或单方用印)的合同进行文字级别的自动比对,实现计算机替代人工审核比对,解决合同审核工作中人工审核时间成本高、人力成本高和风险高三大难题。

结语
数据处理链路“采”“存”“通”的目的都是为了“用”,有了业务需求和技术支撑,提升“用”的水平就是水到渠成的事。从智能理赔的实践来看,如何发掘数据的价值,目前主要还是依靠人工智能技术。图像清晰度识别,能够从源头上对图像质量提出要求,避免干扰业务的判断;翻拍检测和图像篡改检测技术,能够及时发现细节的证据,减少骗赔的发生;目标检测技术,有利于进行影像的自动归类;基于内容的图像检索和向量搜索技术,有利于发现重复赔案。基于以上AI技术能够有效提高影像本身的可靠性,在可靠的影像上进行OCR得到的结果更有业务价值。
此外,技术的提升带来了新的改变,影响的不仅是技术本身直接解决的问题(如图像篡改识别),也能带动其他现有技术的深入应用(AI+OCR等)。
作者介绍

周咸立,中科软科技股份有限公司技术架构团队负责人、资深架构师。持续专注于当期IT技术在保险行业的落地应用,在分布式处理、多云架构、影像处理、智能应用等方面有深刻的理解。目前致力于多云平台下技术资源的整合和应用。

刘平,中科软科技股份有限公司 影像产品团队负责人、资深架构师。在大数据、分布式系统、人工智能和向量搜索方面有深入研究,目前致力于使用AI、大数据等技术,构建保险行业的图像数据库,全面挖掘影像数据价值。
参考资料:
[1]OpenCV 图像清晰度评价 https://blog.csdn.net/
dcrmg/article/details/53543341
[2]Gnuey lup:论文和专利笔记:翻拍检测算法https://
zhuanlan.zhihu.com/p/80381412
[3]Joseph Redmon, Ali Farhadi University of
Washington,YOLOv3: An Incremental Improvement
https://pjreddie.com/media/fifiles/papers/YOLOv3.pdf
[4]Shiv Ram Dubey: A Decade Survey of Content
Based Image Retrieval using Deep Learning
[5]达摩院|达摩院自研向量检索引擎 Proxima 公开https://
developer.aliyun.com/article/783110
[6]Xinru Chen, Chengbo Dong, Jiaqi Ji, Juan Cao,
Xirong Li:Image Manipulation Detection by Multi
View Multi-Scale Supervision https://arxiv.org/
abs/2104.06832

以上是关于用PS的照片申请理赔,保险公司能过吗?的主要内容,如果未能解决你的问题,请参考以下文章