在线直播性能分析:用3个小时分析一个系统的性能瓶颈(从现象到代码)
Posted zuozewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在线直播性能分析:用3个小时分析一个系统的性能瓶颈(从现象到代码)相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
因为昨天在 7DGroup 的群里有个人一直在问问题,所以约了一个晚上 8 点的会开始直播在线性能分析,针对他的那个系统做一次全面的分析,免得再一直问。
会议从晚上 8 点开始。群里发了一下会议链接,一下子就上来好几十人。
大家做性能分析的人都知道,在实际的分析过程中,哪一步都有卡住的风险,所以直播性能分析,让群友们一起围观是要承担很大风险的。万一卡住,名声不保不说,还有可能让人觉得我自负了。那为什么还要这么做呢?其实我是想让群友们感受一下真实的性能分析过程,就算会卡住,也是真实的。
在前几天发的培训评测中,我看到很多人觉得自己对性能理论、性能分析工具、性能分析逻辑等等还是比较自信的。比如说像这样的:
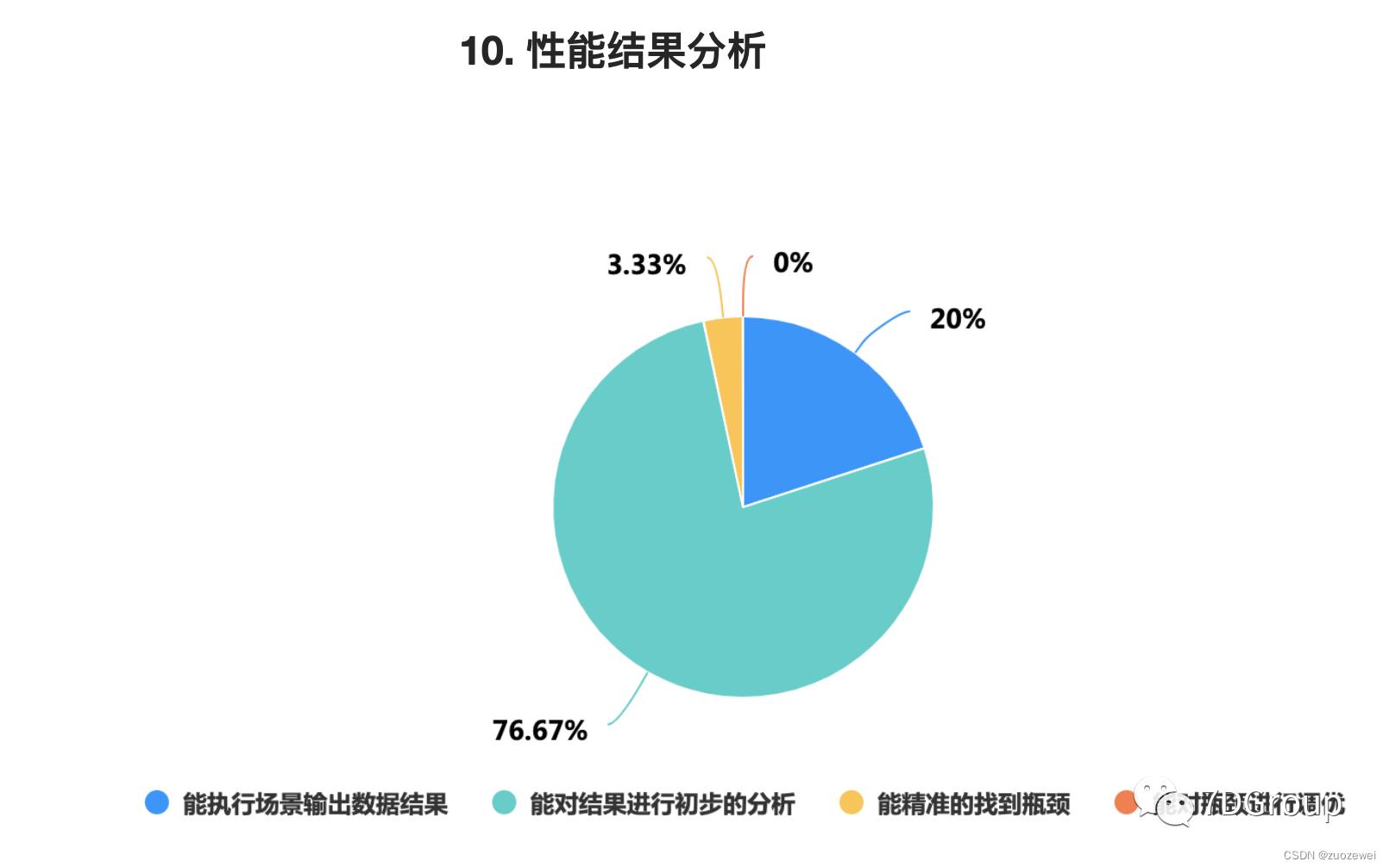
从这个统计结果上来看,觉得自己能对性能结果进行初步分析的占 76.67%。这让我十分惊讶。
从我认识的性能工程师中看来,除了可以对性能结果进行数据的整理和罗列说明之外,我没看到有几个人对性能结果进行分析的。所以我理解,这部分人把对数据的罗列说明理解为“初步分析”了。
这让我觉得性能这个行业如果会越来越没落的话,性能工程师本身的技术素养就成了很重要的一个没落因素。
由此,我觉得直播性能分析过程是有必要的。
如果看不懂的话,就说明这些看不懂的人离真实的性能项目还有距离。
如果看得懂,但做不了的话,说明至少感觉到了这个过程的重要性。
如果看得懂,也做得了的话,那就很好,完全可以在这个行业中生存。
书还得归正传,我们来看一下这个系统。
二、系统架构图
先看架构图。
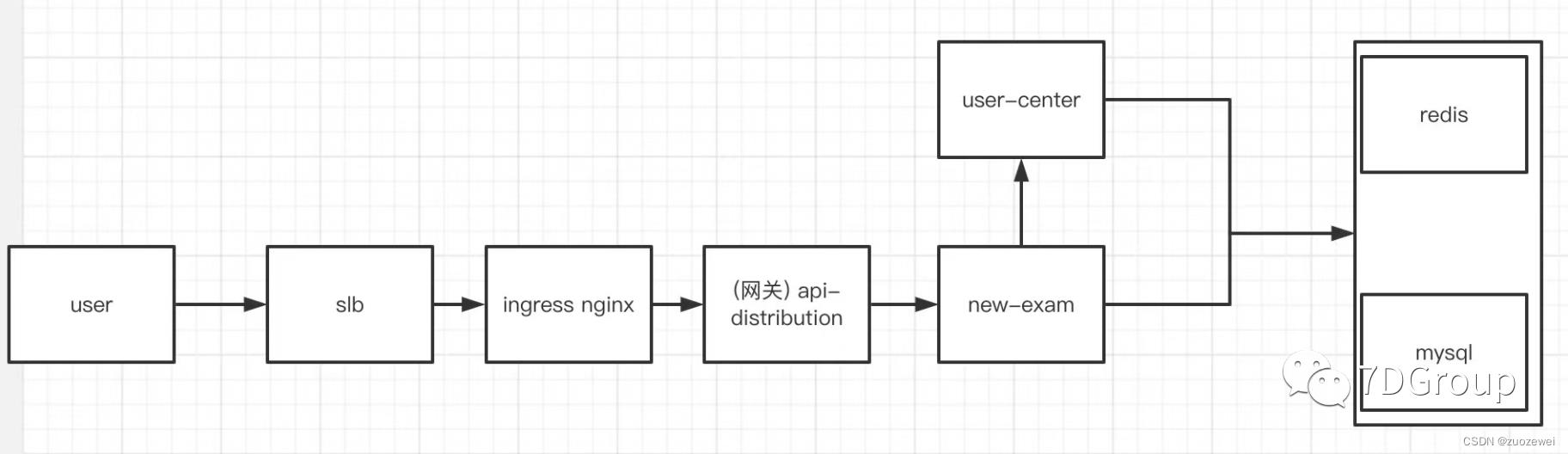
这是这位同学画的一个简单的架构图。看到这样的架构图我真的是心里一凉,但由于是随手的画一下,也不能强求太多。
看架构图是一个性能工程师必须要学会的。像这种可以认为是极为简单的逻辑架构图。还有一种架构图我们是需要的,那就是部署架构图。但是这个同学没有,所以也只能放弃要求了。
看架构图是为了知道:
- 压力的调用路径
- 各服务节点连接关系
- 技术栈的使用
等等信息。
从上面的架构图中,我们就可以知道,如果是从 user 的位置发起压力的话,那显然在用 RESAR 性能分析七步法中的拆分时间的时候,就得从 slb、ingress、网关、exam…这样一层一层拆下去。
三、分析过程
通过架构图,我们已经了解了这个项目的基本信息。下面就是开始压起来,看看问题在哪了。
一上来这位同学就用了四台压力机,每台压力机 50 个线程,均在 1 秒内启动。这样做的原因,我估计是之前也做过很多次了,觉得这样可以压到瓶颈点,但是根据我的习惯是一定要加 Rampup 的。
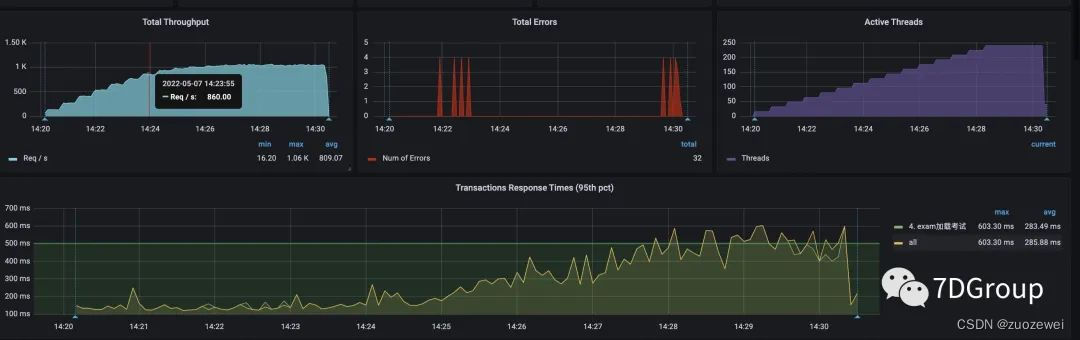
递增压力线程:
非递增压力线程:
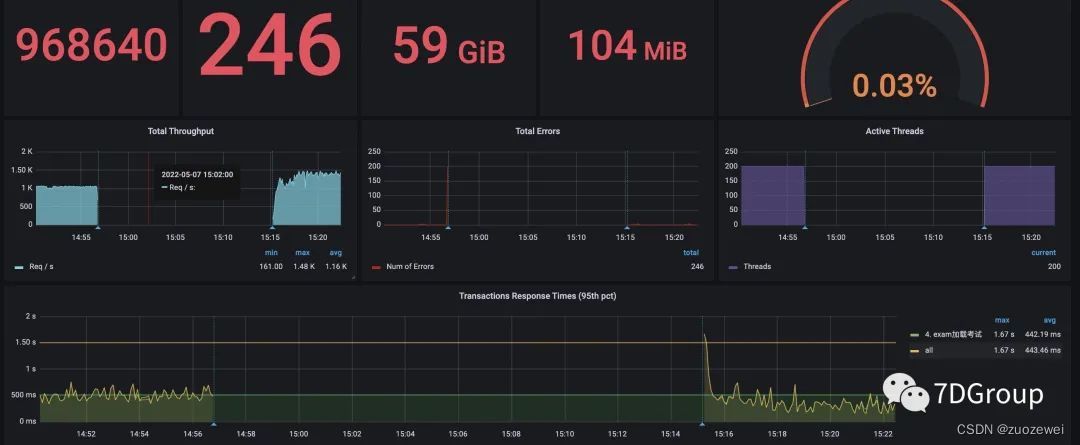
递增和直接上压力线程的图各截了一个。对应的压力线程数、tps、响应时间,大概是上图的样子。
上图在非递增压力线程的图上的后半段之所以TPS会高一些,是因为他们关了日志。关日志显然是对性能有很明显的影响的。
四、问题分析
1、问题一
我们来看看接下来的问题。
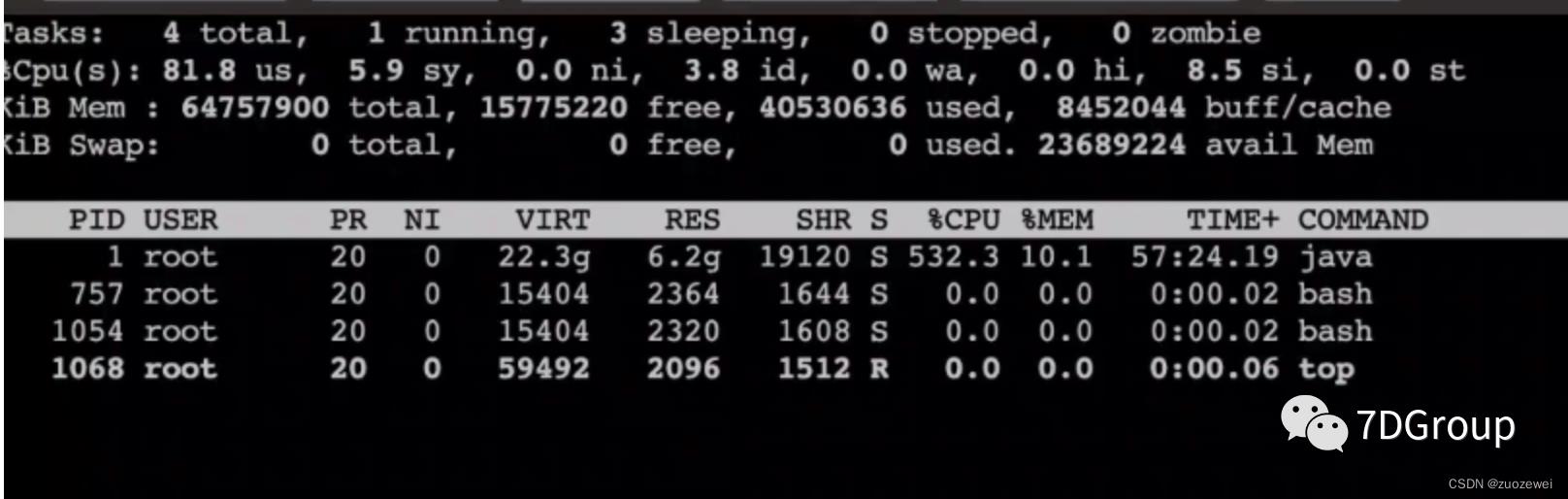
从 top 的命令看,在应用节点的主机上,资源已经用光了。
接着往下看 vmstat。
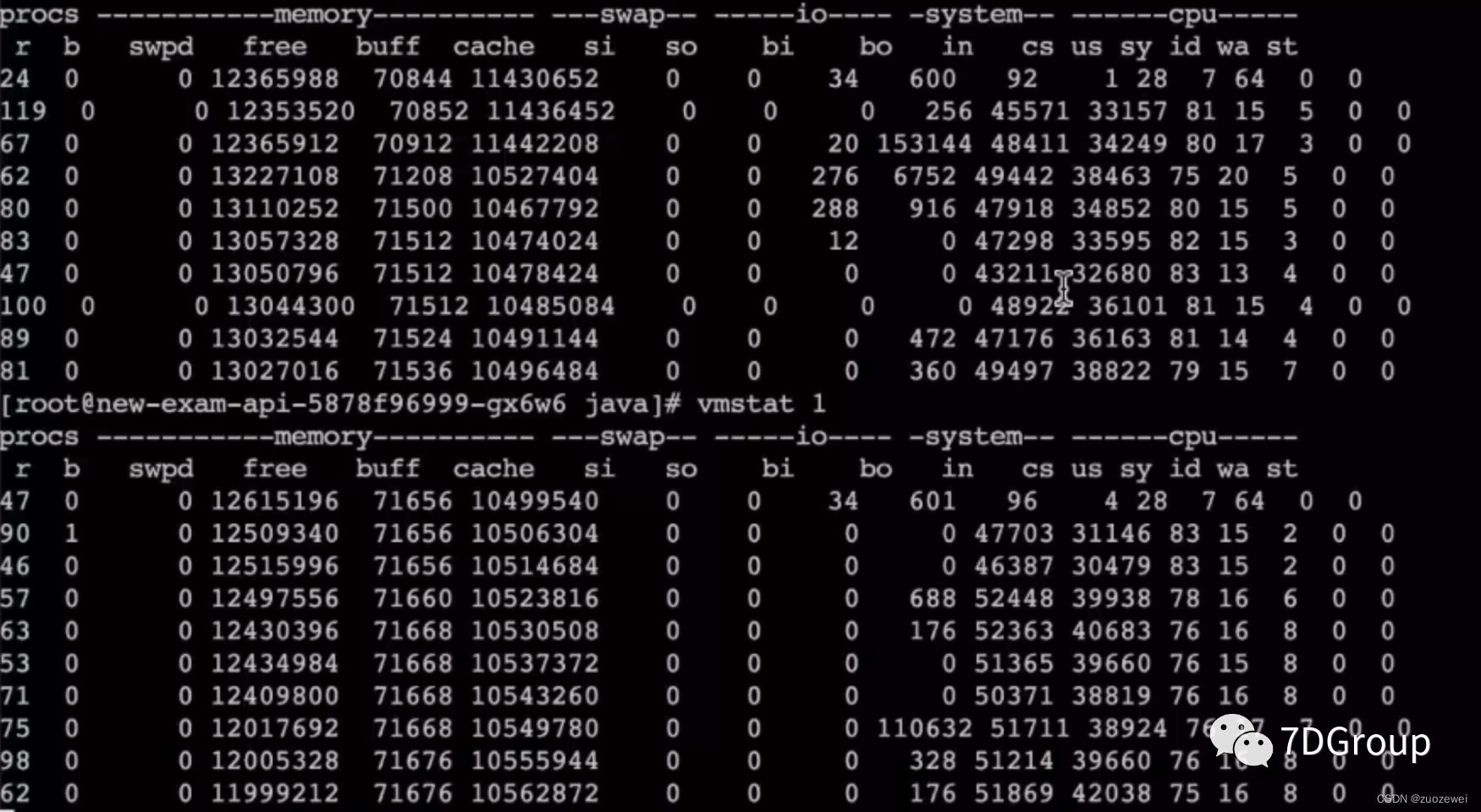
从这个数据和后面的一个数据应该结合一起来看。上面的这个 vmstat 是在200压力线程下的结果,下面这个图是在 400 压力线程下的结果。
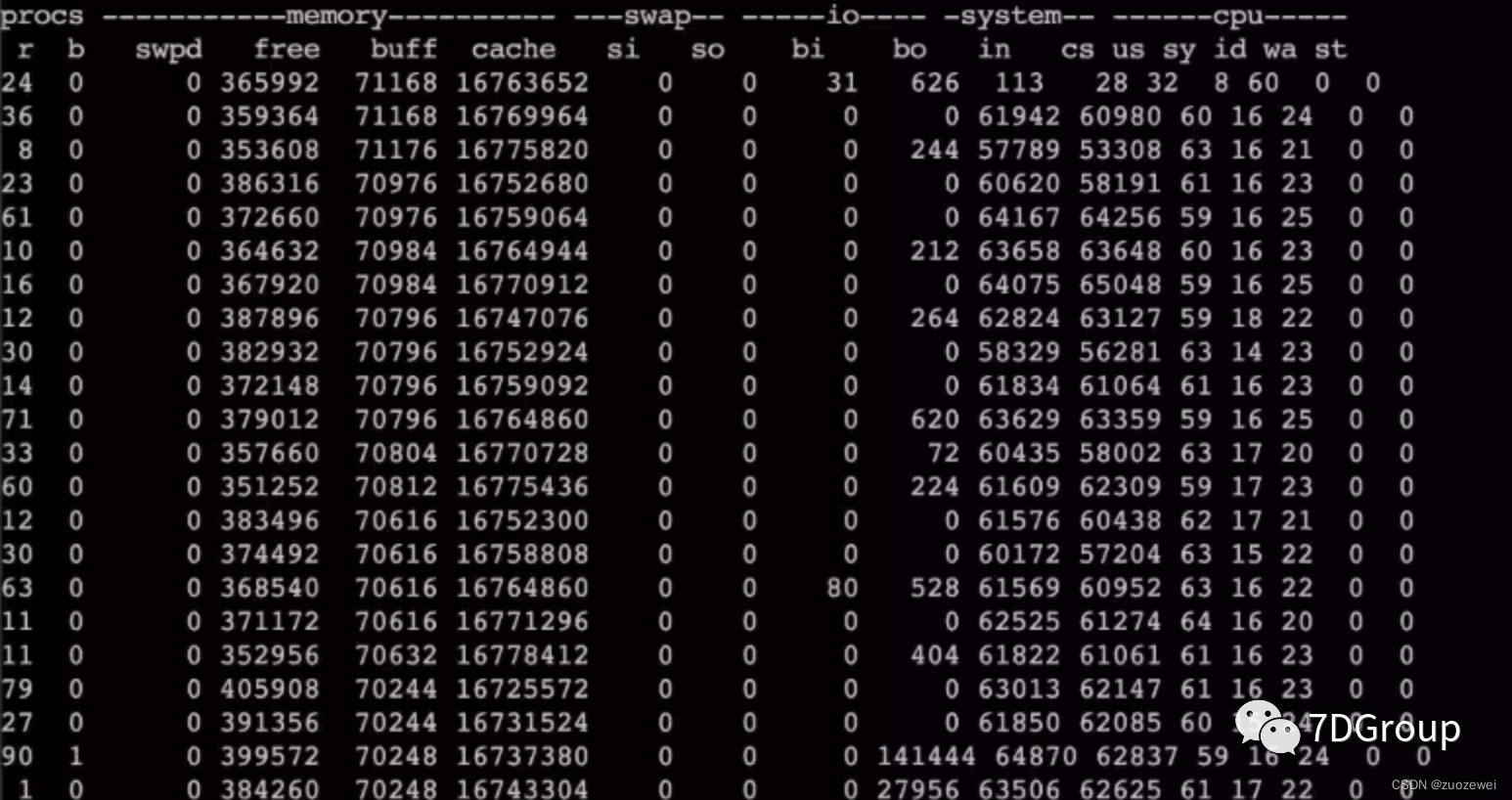
看 CS 已经增加了近一倍了。
(在这里留一个疑问:为什么这时候的cpu反而有空闲的了呢?)
这时去查了 springboot 线程池的配置,是使用的默认值2 00,而实际使用的线程数大概是70-80左右。在我的经验中,其实我不建议这么配置,线程池只要配置得够用就好,太多会导致切换变多。我还见过一个 tomcat 在 16 C32G的机器上配置 4000 个线程的,其结果就是大量的 cs 和sy cpu消耗。
所以这第一个问题就是,建议把线程池调小,调到够用即可,也不能太小。像在这个项目中,我会建议调到90-100的样子。
2、问题二
接着往下看。
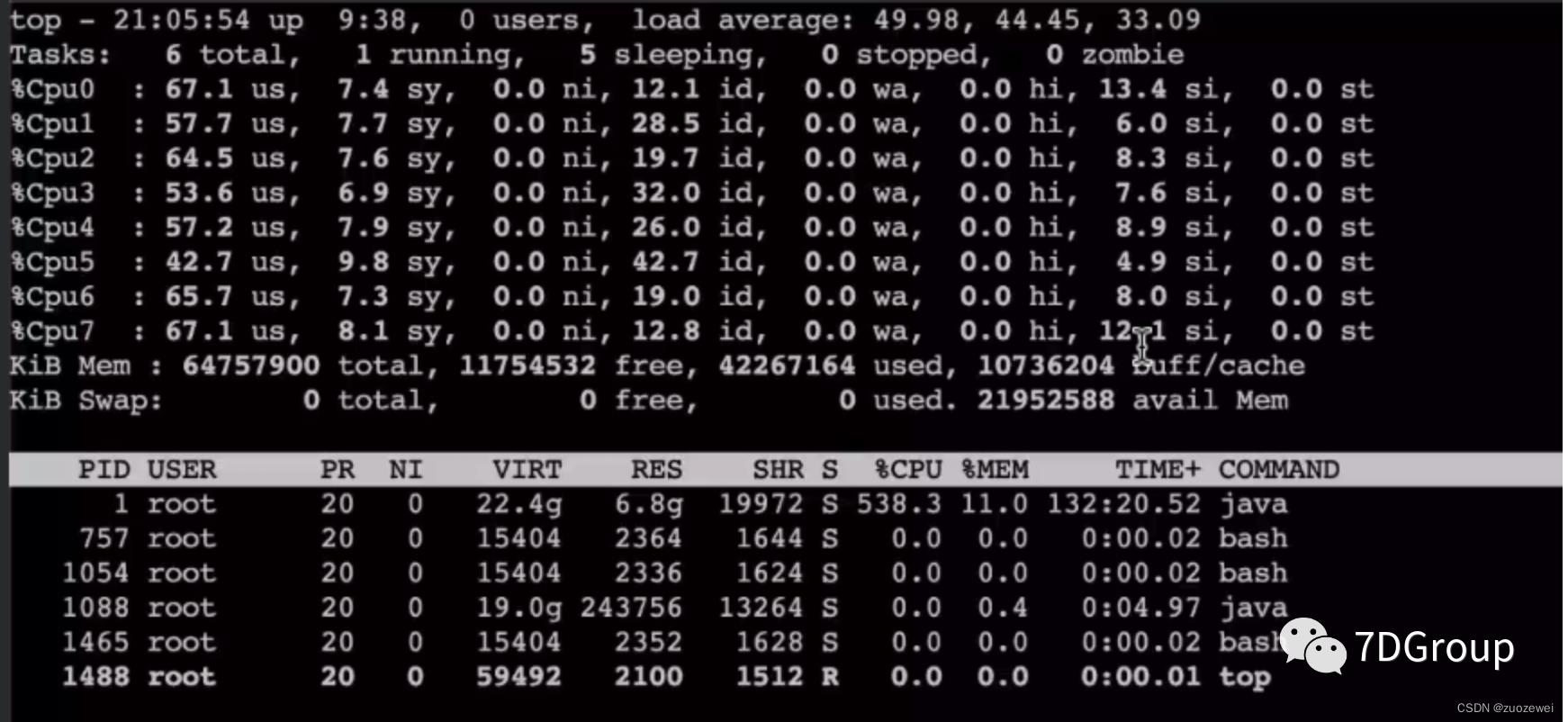
从上面的si cpu消耗可以看出软中断还是偏高的。在这种虚拟机上使用k8s+docker的技术栈中,基本上si cpu都会比纯硬件的高。
接着看一下网络,可以看到进出加到一起都能达到1G。
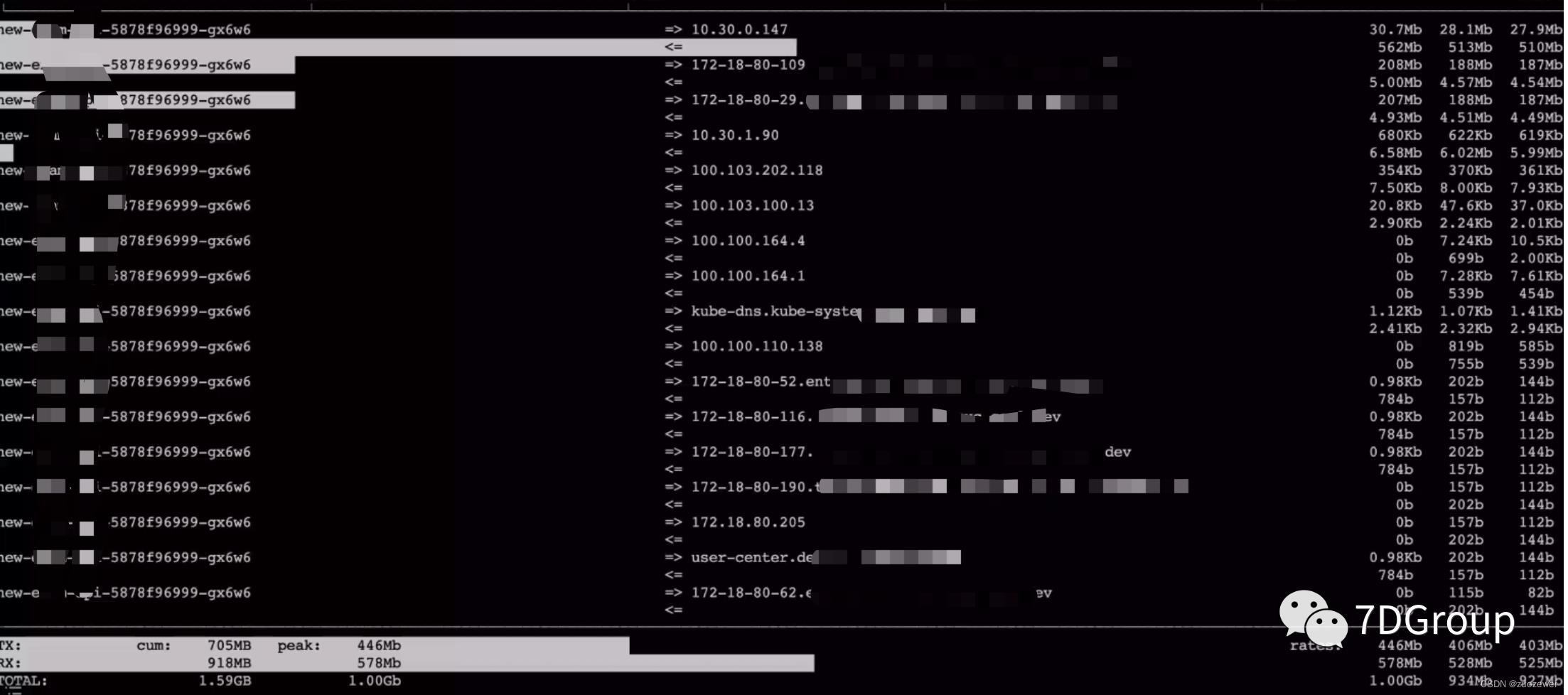
接着去查网络队列。
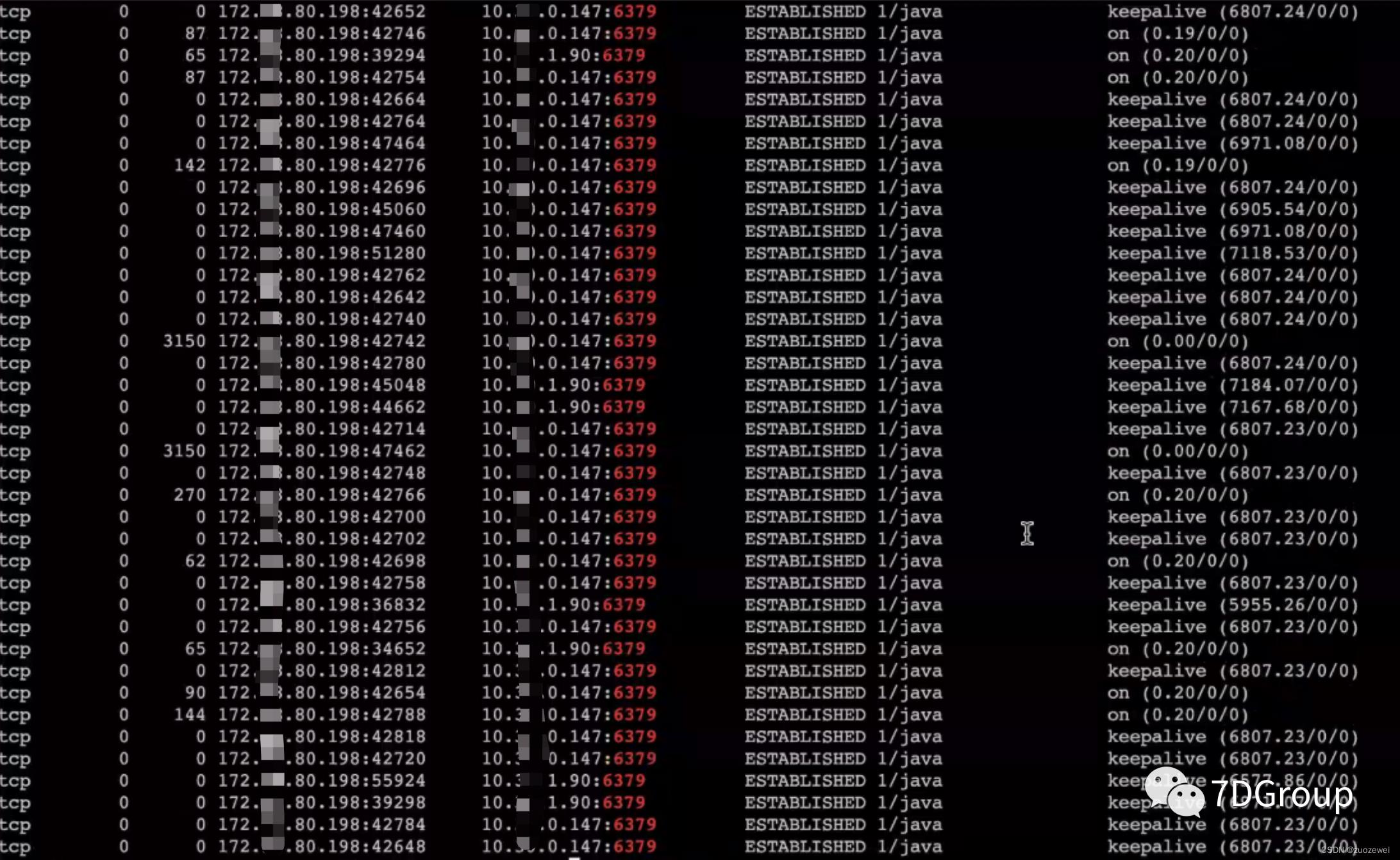
从上面的数据可以看到 send_Q 也一直有值。并且是和 redis 的交互过程中。
接着又登录了 redis 的管理界面,看到redis的最大带宽是 384M。由于使用的是阿里云的 redis 服务,无法登录主机的 shell 查看更细的数据,只能从以上的数据做出判断,redis 机器是有阻塞的,是网络阻塞还是其他资源的阻塞,暂时未知。如果只从网络交互的数据量来判断的话,大概率是在网络带宽上。
所以问题二就是网络带宽不足导致队列出来,in和si cpu高。这显然是要增加了网络带宽之后,再复测一下,看是否判断正确。
3、问题三
由于这个系统中没有日志可以拆分时间,也没有 apm 工具可用。但从资源使用率上可以看到应用所在的主机CPU使用率是很高的。

又因为压力脚本中只访问了一个接口。所以直接到这台主机上去跟踪方法的调用时间。
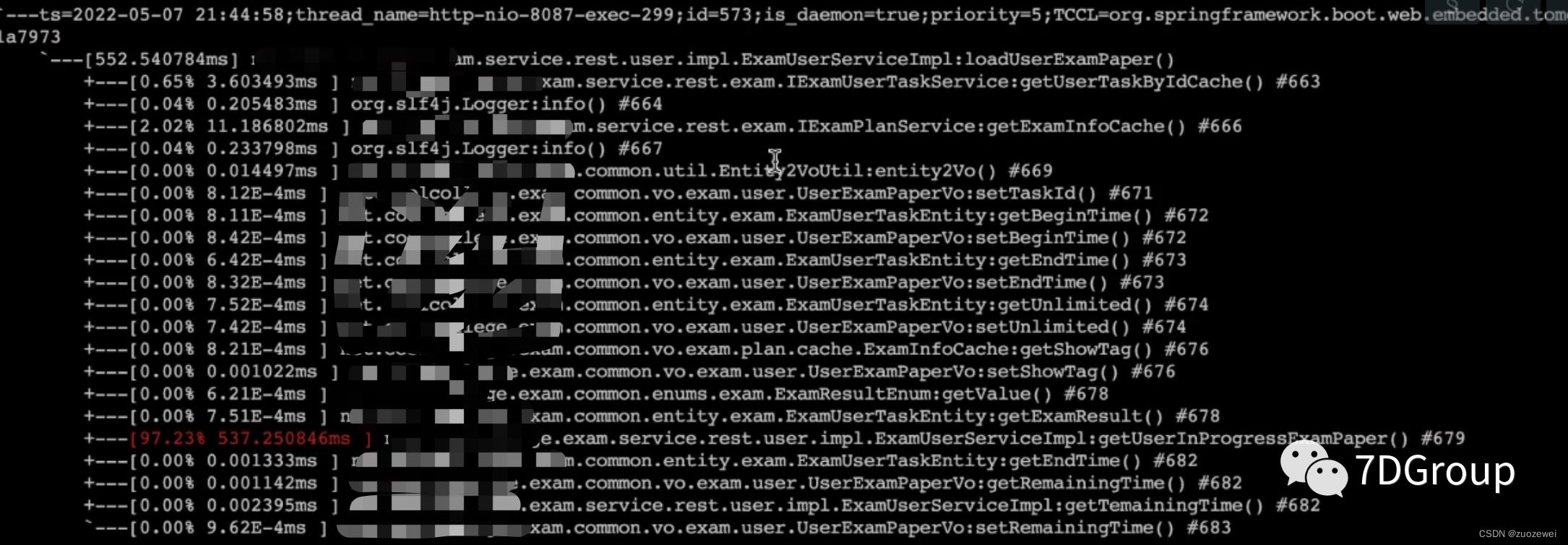
跟着入口一层层跟踪下去,发现几个问题:
- AOP 切片消耗了近 100 ms的时间。
- 代码中的循环调用消耗了近 100 ms的时间。
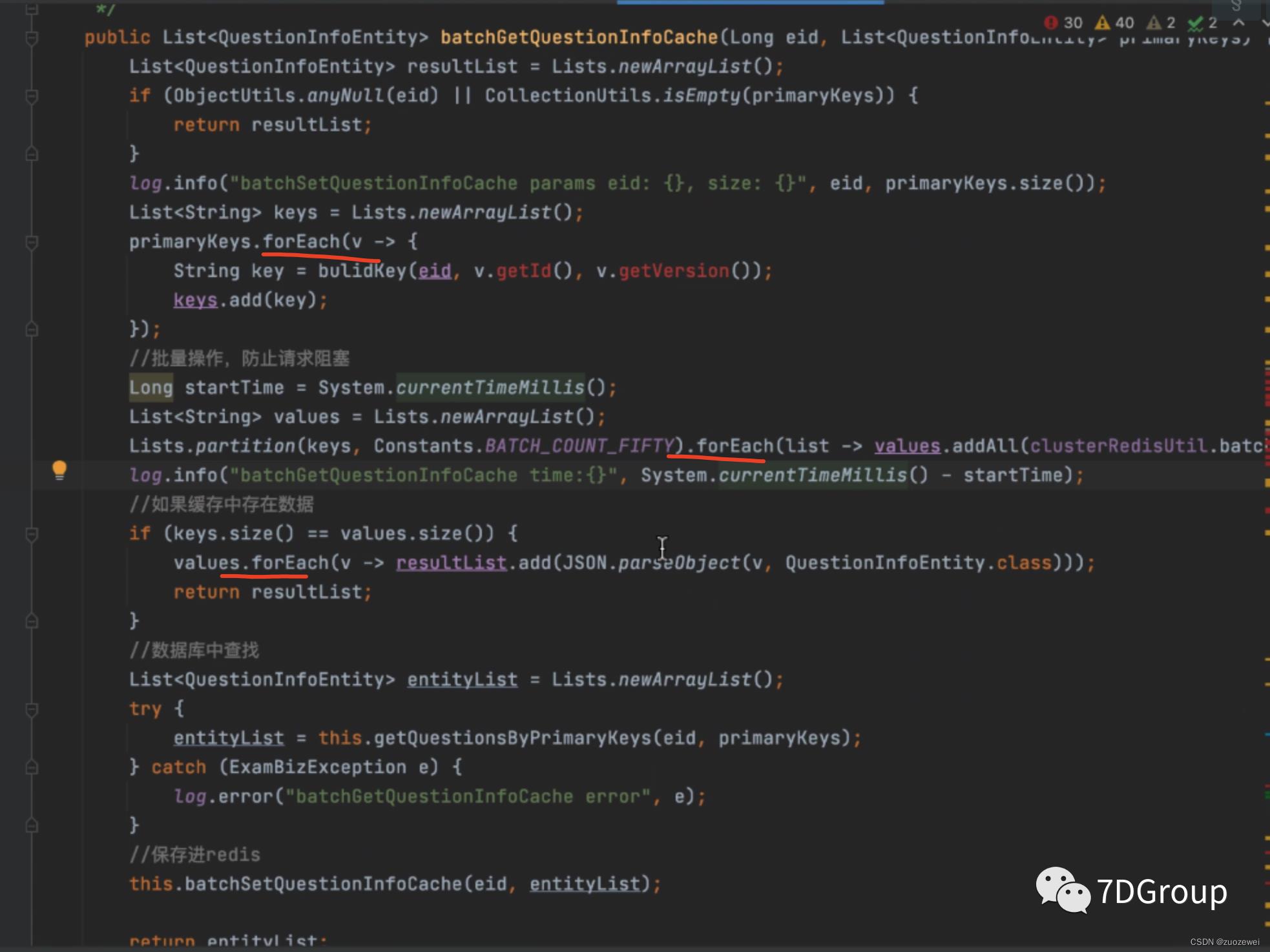
到这里后,就得问一下开发了。如果业务代码必须这样写(通常不是),没有优化空间,那就要考虑用其他的方法提升系统的容量,比如增加节点,请注意,增加节点不一定要增加资源,这取决于整体的资源使用是否均衡。
这个系统的性能瓶颈不止本文描述的三个,我只是把典型的问题写出来。在直播分析的过程中,还有更多的细节讨论,也都比较有意思。有兴趣的可以在 7DGroup 群里面索要分析过程的视频链接。
通常在一个项目初期,都是由多个性能问题同时出现的,这时的分析一定要紧紧抓住证据链。当证据链断裂的时候,就要想办法接上,不然就会陷入分析的坑里。
五、小结
近期我们启动了对个人的培训,希望有兴趣的来咨询我们。我们的目标是做最贴近真实性能项目的技术培训,不是教你工具如何用(当然也会涉及到工具的使用但不是只教工具的功能点),而是教你如何对一个项目进行深入的性能分析以及容量规划
以上是关于在线直播性能分析:用3个小时分析一个系统的性能瓶颈(从现象到代码)的主要内容,如果未能解决你的问题,请参考以下文章