Attention Transfer
Posted 爆米花好美啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Attention Transfer相关的知识,希望对你有一定的参考价值。
Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer
Motivation
大量的论文已经证明Attention在CV、NLP中都发挥着巨大的作用,因为本文利用Attention做KD,即让student学习teacher的attention maps

Activation-based attention transfer
如果定义是spatial attention map
- 各个channel相同位置绝对值求和
- 各个channel相同位置p次方求和:对比1,会更加注重于响应高的地方
- 各个channel相同位置p次方求最大值
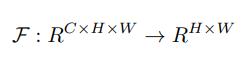
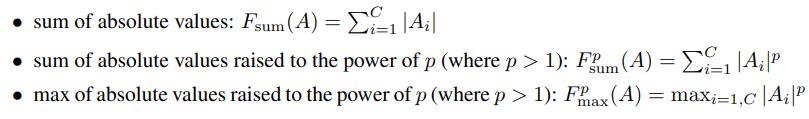
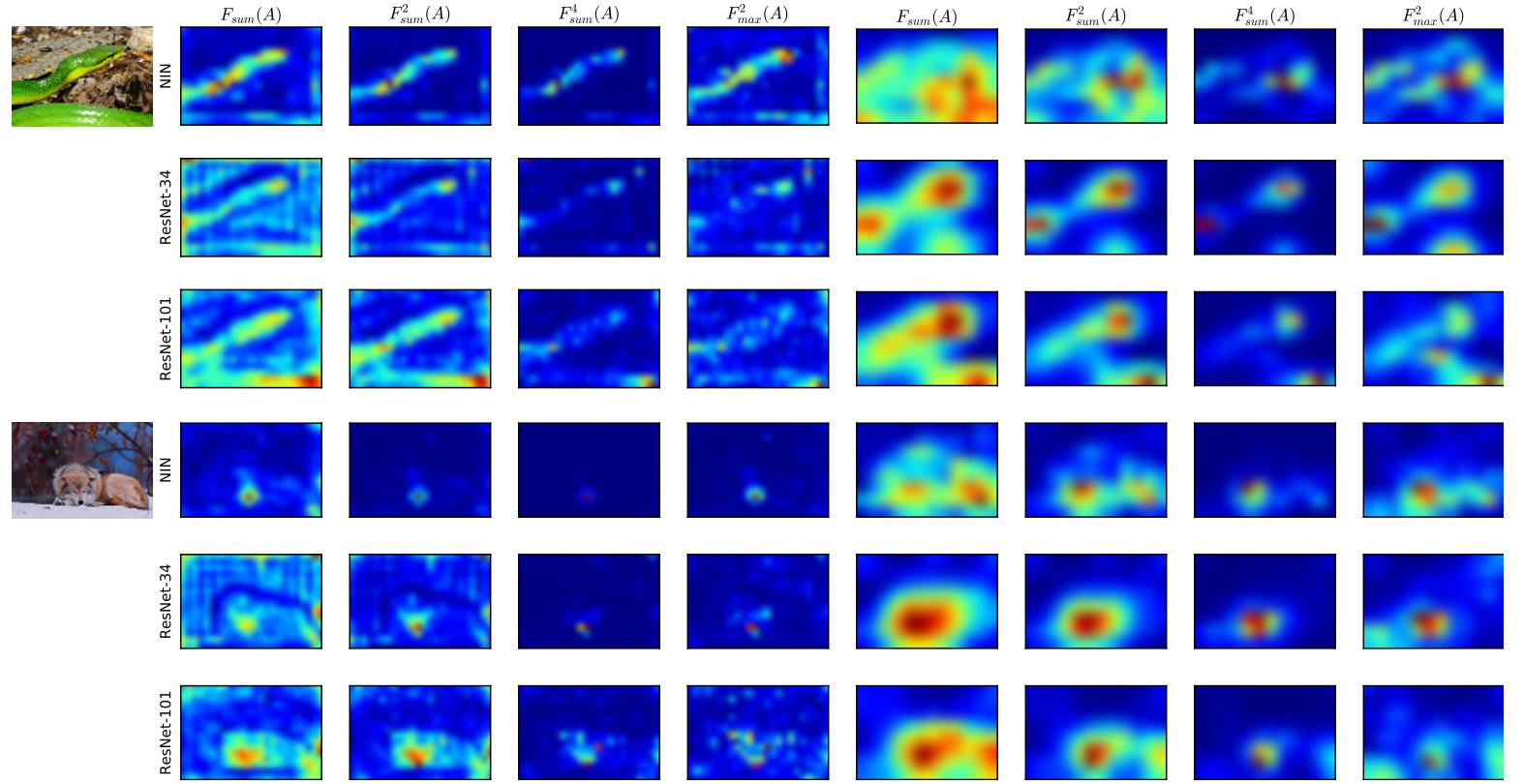
3种方式得到的attention map各有侧重,后两种更加侧重一些响应更突出的位置
最终的Loss:
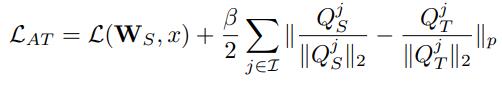
Qs Qt为第j对student和teacher的attention map
beta取1000,式子后半部会在所有位置取平均,整体来说后半部的权重在0.1左右
Gradient-based attention transfer
网络对某些位置输入的敏感性,比如调整某些位置的像素然后观察网络输出的变化,如果某些位置调整后网络输出变化大即说明网络更加paying attention to这个位置
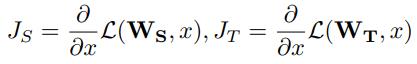
Experiments
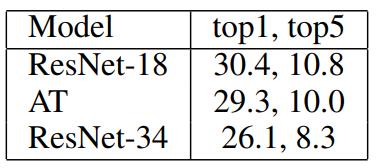
activation-based AT, F-AcT(类似FitNets,1x1做feature adaptation后做L2 loss)

平方和效果最好

activation-based好于gradient-based

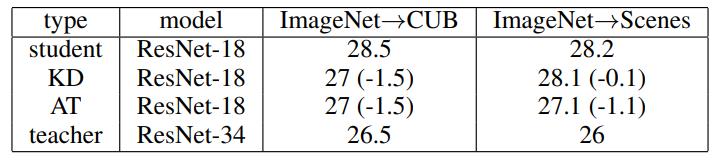
其他在Scenes这个数据集上AT做的比传统的KD要好很多,猜测是因为we speculate is due to importance of intermediate attention for fine-grained recognition
好像作者写错了吧,这里明明CUB才是fine-grained的数据集
重要
KD struggles to work if teacher and student have different architecture/depth (we observe the same on CIFAR), so we tried using the same architecture and depth for attention transfer.
We also could not find applications of FitNets, KD or similar methods on ImageNet in the literature. Given that, we can assume that proposed activation-based AT is the first knowledge transfer method to be successfully applied on ImageNet.
以上是关于Attention Transfer的主要内容,如果未能解决你的问题,请参考以下文章