[译]网格着色器渲染数亿面片的模型
Posted 海洋_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[译]网格着色器渲染数亿面片的模型相关的知识,希望对你有一定的参考价值。
现在在工业仿真或者航天以及军事仿真中,会使用数以亿级的模型数量,针对它们的渲染,普通的渲染管线几乎是不可能做出逼真的渲染效果,这就要用到网格着色器。本篇博客主要是给读者介绍 网格着色器渲染技术,我们主要从以下几方面给读者介绍:
1 网格着色器管线
2 网格和网格着色
3 预计算Meshlets
3.1 数据结构
3.2 渲染资源和数据流
3.3 Cluster Culling with Task Shader
我们在使用渲染管线的时候,经常会使用vertex, tessellation和geometry 着色器, 它们虽然非常有效,但当我们绘制的几何分辨率达到数亿个三角形和数十万个对象时,仍然会受到限制。比如下图所示的渲染场景:

上图中并没有显示科学计算使用的几何图形比如,点云,电子线路,运行轨迹等等,这些使用常规的渲染管线很难完成,这里就要用到网格着色器,它可以加快渲染数量繁多的三角形网格。原始网格被分割成更小的网格,如下图所示。理想情况下,每个网格优化顶点重用它。使用新的硬件阶段和分割方案,我们可以在获取较少整体数据的同时并行呈现更多的几何图形。


CAD数据可以达到数千万到数亿个三角形。即使做过裁剪后,仍然可以存在大量的三角形。我们会想到使用顶点的合并和不可见顶点的剔除来优化我们的场景。
网格着色器为开发人员提供了避免这种瓶颈的新可能性,与以前的方法不同,新方法允许只读取内存一次并保存在内存上,而以前的方法是间接计算和绘制可见三角形的索引缓冲区。
网格着色器阶段为光栅化生成三角形,但在内部使用协作线程模型,而不是使用与计算着色器类似的单线程程序模型。在网格着色器前面的管道是任务着色器。任务着色器的操作类似于tessellation 的控制阶段,因为它能够动态生成。然而,就像网格着色器一样,它使用了一个协作线程模型,它的输入和输出都是用户定义的。
这简化了几何体的创建,而以前的刚性和有限的tessellation 和几何体着色器中,线程只能用于特定的任务,如下图所示。
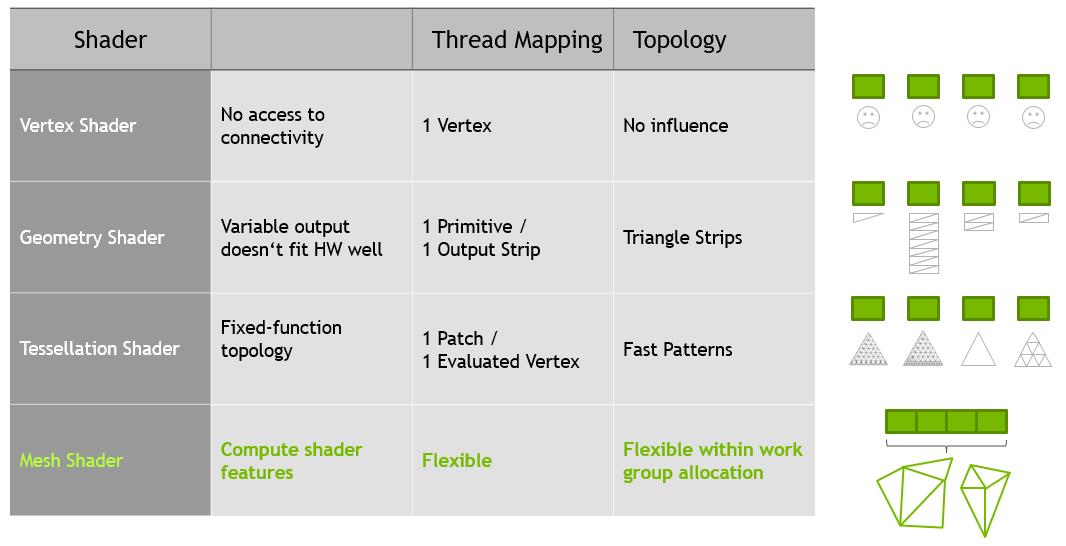
- 网格着色器管线
一个新的,两阶段管道替代补充了经典的attribute fetch,vertex,tessellation,几何着色管道,这个新的管道包括一个任务着色器和网格着色器:
任务着色器: 一种可编程单元,在工作组中运行,允许每个工作组发出(或不发出)网格着色器工作组。
网格着色器: 一种可编程单元,在工作组中运行,允许每个工作组生成primitives
网格着色器阶段使用上述内部协作线程模型为光栅化器生成三角形。任务着色器的操作类似于tessellation着色器阶段,因为它能够动态生成。然而,像网格着色器一样,任务着色器也使用合作线程模式。它的输入和输出是用户定义的,而不需要将补丁作为输入,并将tessellation决策作为输出。
当然,与像素/片段着色器的接口不受影响,传统管道仍然可用,并且可以根据用例提供非常好的结果,下图突出显示了管道样式之间的差异。
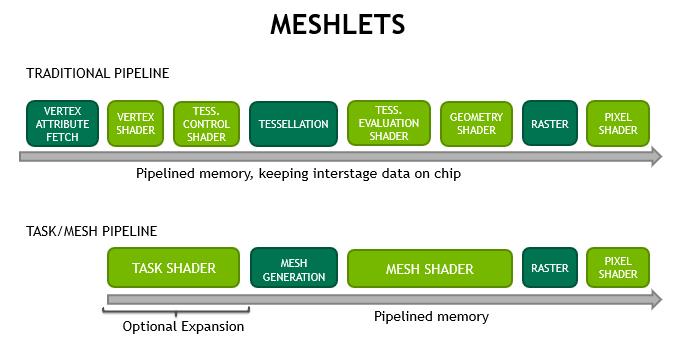
新的网格材质管道为开发者提供了许多好处:
通过减少基本处理中固定功能的影响,通过着色器单元获得更高的可伸缩性。现代gpu的通用用途帮助更多的应用程序添加更多的内核,提高着色器的通用内存和计算性能。
带宽减少,作为顶点的重复去重(顶点重用)可以预先完成,并在许多帧上重用。使用当前的API模型意味着每次都必须由硬件扫描索引缓冲区。更大的网格意味着更高的顶点重用,也降低了带宽要求。此外,开发人员可以提出自己的压缩或过程生成方案。可选的扩展/过滤通过任务着色器允许跳过获取更多的数据。
定义网格拓扑和创建图形工作的灵活性,以前的tessellation着色器被限制在固定的tessellation模式,而几何着色器遇到了一个低效的线程,不友好的编程模型,创建三角形带每个线程。
网格着色遵循计算着色器的编程模型,使开发人员可以自由地将线程用于不同的目的,并在线程之间共享数据。当栅格化被禁用时,这两个阶段还可以使用一个级别的展开来执行一般的计算工作。
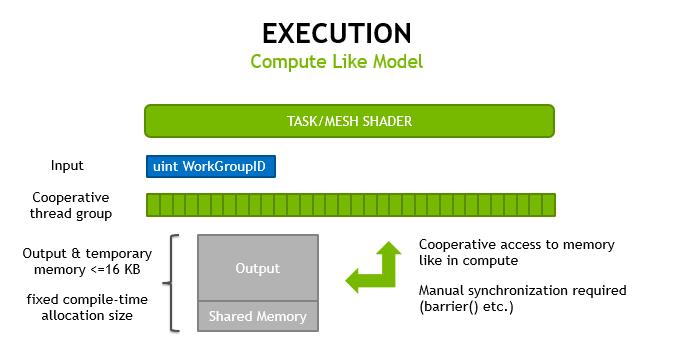
网格和任务着色器都遵循计算着色器的编程模型,使用协作线程组来计算结果,除了工作组索引之外没有其他输入,它们在图形管道上执行;因此,硬件直接管理各阶段之间的内存传递和芯片上的存储。
我们将展示一个示例,说明如何使用它来执行基本筛选,因为稍后线程可以访问工作组中的所有顶点。下图说明了任务着色器处理早期剔除的能力。

可通过任务着色器进行可选的扩展,允许提前剔除一组primitives 或做出LOD决策,它的规模跨越GPU,因此正在取代实例化或多画间接小网格。这种配置类似于tessellation 控制着色器设置一个贴片(~任务工作组)被tessellation 多少,然后影响多少tessellation 评估调用(~网格工作组)被创建。
一个任务工作组可以发出多少网格工作组是有限制的,第一代硬件支持每个任务最多可以生成64K个子任务。在同一个draw调用中,跨所有任务的mesh子节点的总数没有限制。同样地,如果不使用任务着色器,则绘制调用生成的网格工作组的数量不存在限制。下图说明了这是如何工作的。

任务T的子任务保证在任务T-1的子任务之后启动。然而,任务和网格工作组是完全流水线的,这样就不需要等待以前的子任务或任务的完成。
任务着色器应该用于动态生成或过滤,静态设置受益于只使用网格着色器。
网格的栅格化输出顺序和网格内的primitives 被保留。通过禁用栅格化,任务和网格着色器都可以用来实现基本的计算树。
- 网格和网格着色
每个网格表示可变数量的顶点和primitives ,对于这些primitives 的连接没有任何限制。但是,它们必须保持在最大数量以下,在着色器代码中指定。
我们建议使用最多64个顶点和126个primitives 。126中的“6”不是一个错数字。第一代硬件以128字节粒度分配primitives 索引,需要为primitives 计数保留4个字节。因此,3 * 126 + 4最大化适合3 * 128 = 384字节块。超过126个三角形将分配接下来的128个字节。84和40是另一个适用于三角形的极大值。
在每个GLSL网格着色器代码中,每个工作组在图形管道中为每个工作组分配固定数量的网格内存。
最大值和大小以及primitives 输出定义如下:
每个网格的分配大小取决于编译时的大小信息以及着色器引用的输出属性。分配越小,可以在硬件上并行执行的工作组就越多。与计算一样,工作组共享可访问的片上内存的公共部分。因此,我们建议尽可能高效地使用所有输出或共享内存。这对于当前的着色器已经是正确的。但是,内存占用可能更高,因为我们允许比当前编程中更多的顶点和primitives 。

另一个新的GLSL扩展,NV_fragment_shader_barycentric,它使fragment shader能够获取三个顶点的原始数据,这三个顶点构成了一个primitives ,并手工进行插值。这种原始访问意味着我们可以输出“uint”顶点属性,但是使用不同的包/解包函数来将浮点数存储为fp16、unorm8或snorm8。这可以大大减少每个顶点再次为法线,纹理坐标,和基本的颜色值,并受益于标准和网格着色管道。
顶点和基元的附加属性定义如下:

一个目标是拥有最小数量的网格,从而最大化顶点在网格中的重用,从而浪费更少的分配。在生成网格数据之前,在索引缓冲区上应用顶点缓存优化器是有益的。例如,Tom Forsyth的线性速度优化器可以用于此。优化顶点位置和索引缓冲区也是有益的,因为当使用网格着色器时,原始三角形的顺序将被保留。CAD模型通常是用条带“自然”生成的,因此已经具有良好的数据局部性。更改indexbuffer可能会对网格的筛选属性产生负面影响。 - 预计算Meshlets
例如,我们呈现静态内容,其中索引缓冲区是不变的,因此,在向设备内存上传顶点/索引时,可以隐藏生成网格数据的成本。当顶点数据也是静态的(没有每个顶点的动画;不改变顶点位置),允许预计算数据对快速剔除整个网格有用。 - 数据结构
在以后的示例中,我们将提供一个meshlet builder,其中包含一个基本实现,每次遇到大小(顶点或基元计数)限制时,都会扫描提供的索引并创建一个新网格。
对于输入三角形网格,它生成以下数据:

为什么是两个索引?
下面的原始三角形索引缓冲区序列被分割成两个新的索引缓冲区。
当我们迭代三角形索引时,我们构建一组唯一的顶点索引。这个过程也被称为顶点重复。
vertexIndices = 4,5,6, 8, ...
基本索引是相对于vertexIndices条目进行调整的。
// original data
triangleIndices = 4,5,6, 8,4,6, ...
// new data
primitiveIndices = 0,1,2, 3,0,2, ...
// the primitive indices are local per meshlet
一旦达到合适的大小限制(要么是太多的唯一顶点,要么是太多的primitives),一个新的网格就开始了。然后,后续的网格将创建它们自己的唯一顶点集。
- 渲染资源和数据流
在渲染过程中,我们使用原始的顶点缓冲,然而,我们使用三个新的缓冲区来代替原来的三角形索引缓冲区,如下面的图所示:
顶点索引缓冲区如上所述,每个网格引用一组唯一的顶点,这些顶点的索引按顺序存储在所有网格的缓冲区中。
如上所述的基本索引缓冲区,每个网格表示不同数量的primitives。每个三角形都需要三个原始索引,它们存储在一个缓冲区中。注意:额外的索引可以添加到获得四个字节对齐后,每个网格。
Meshlet Desc缓冲区,存储每个网格的工作负载和缓冲区偏移量信息,以及集群选择信息。
这三个缓冲区实际上比原来的索引缓冲区小,因为网格材质允许更高的顶点重用,我们注意到索引缓冲区大小通常会减少到原来的75%左右。
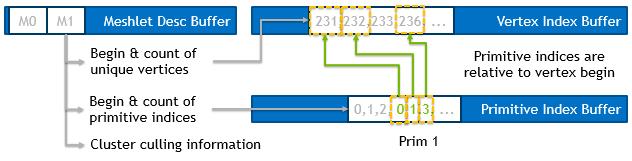
网格顶点:vertexBegin存储我们开始获取顶点索引的起始位置。vertexCount存储所涉及的连续顶点的数量,顶点在网格内是唯一的;没有重复的索引值。
Meshlet Primitives:primBegin存储原始索引的起始位置,我们将从这里开始获取索引。primCount存储网格中涉及到的Primitives的数量。注意,索引的数量取决于基本类型(这里:3表示三角形)。需要注意的是,索引引用的是相对于vertexBegin的顶点,这意味着索引’ 0 '将引用位于vertexBegin的顶点索引。
下面的伪代码描述了每个网格着色器工作组的工作原理。它是串行只是为了说明的目的。

网格着色器可以像这样,当写在平行的方式:
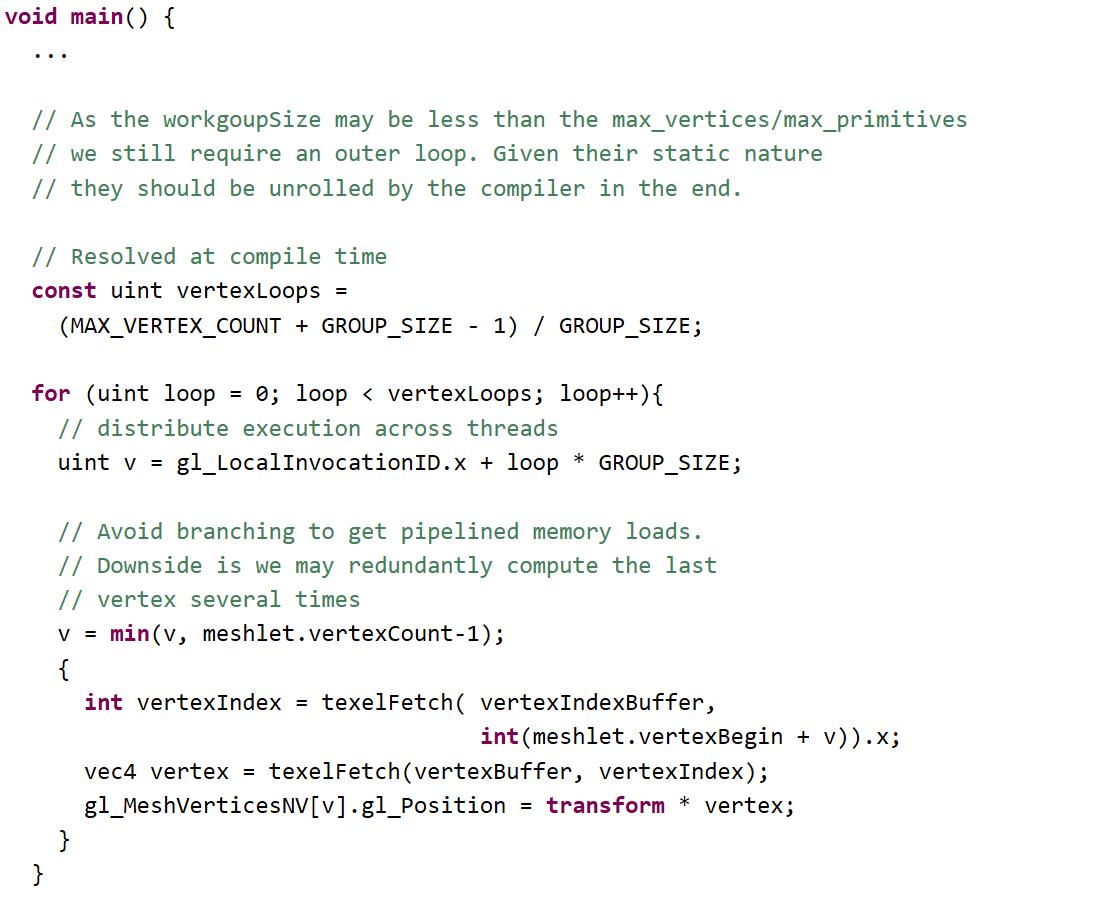
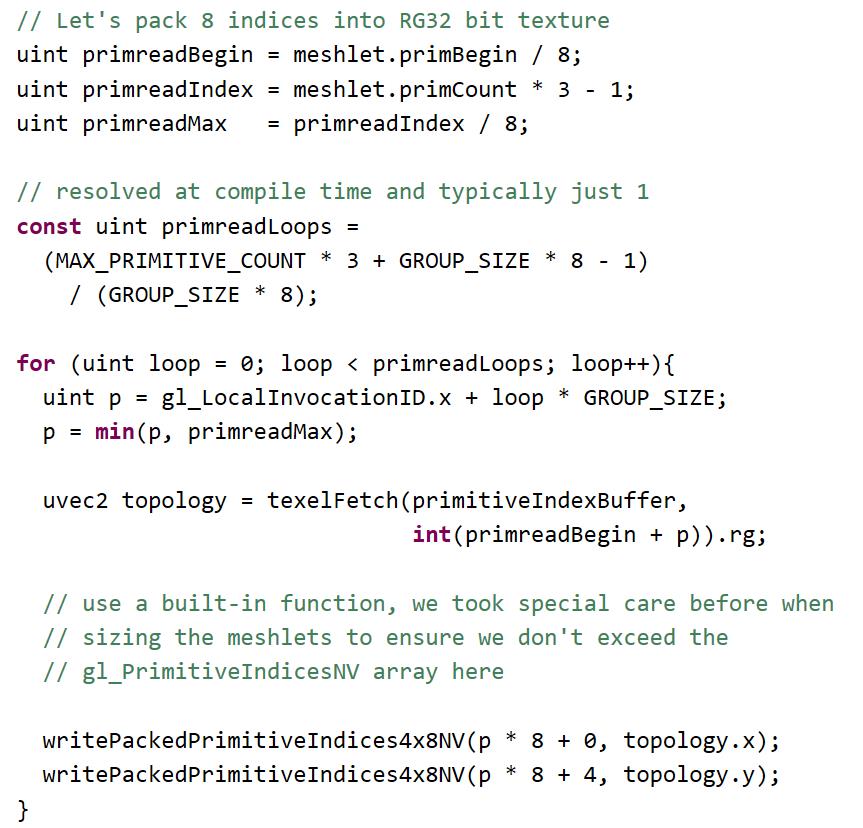

这个例子只是一个简单的实现,由于所有数据获取都是由开发人员完成的,因此可以通过子组内部函数或共享内存进行自定义编码、解压缩,或者暂时使用顶点输出来节省额外的带宽。
- Cluster Culling with Task Shader
我们试图将更多的信息压缩到网格描述符中来执行早期的剔除,我们已经尝试使用128位描述符来编码前面提到的值,以及由G.Wihlidal提供的bbox用于剔除。
下面的任务着色器最多可以剔除32个网格。


相应的网格着色器现在使用来自任务着色器的信息来识别要生成的网格。

我们只在渲染大三角模型的情况下在任务着色器中选择网格,其他场景可能涉及到根据细节级别的决策选择不同的网格数据,或者完全生成几何图形(粒子、色带等)。下面的图来自一个使用任务着色器进行详细级别计算的演示。

原文文章链接:https://devblogs.nvidia.com/introduction-turing-mesh-shaders/
以上是关于[译]网格着色器渲染数亿面片的模型的主要内容,如果未能解决你的问题,请参考以下文章