三款“非主流”日志查询分析产品初探
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三款“非主流”日志查询分析产品初探相关的知识,希望对你有一定的参考价值。
前言
近些年在开源领域,用于构建日志系统的软件有两类典型:
- Elasticsearch:基于 Lucene 构建倒排索引提供搜索功能,DocValue 存储支持了其统计分析能力。
- Clickhouse:列式存储是其优秀 OLAP 性能的保障。
这里把上述系统归入 schema-on-write 系列。百花齐放,本文介绍三款 "schema-on-read" 类型日志系统。
为什么是打了引号的 schema-on-read?尽管几家厂商对外宣传关键词常常用到 index-free、schema-less,但从技术角度应该理解为一种轻量级索引技术,将大部分计算成本后置到使用时发生。它们的出现有其背景:
- 技术能力:硬件技术快速发展,云计算 IaaS 资源(计算、存储、网络)已足够便宜、弹性。
- 客户诉求:近两年市场紧缩,企业的 IT 预算更加精细。
- 场景固化:相当比例的日志使用场景具有写多读少、随时间变长热度降低特性。
Humio
简介
Humio 是 2016 年成立的一家英国公司,2021 年 3 月被 CrowdStrike 收购($352 million 现金加 $40 million 股票期权)。产品提供日志的搜索、统计、仪表盘、告警服务。
数据路径
Humio 用 Kafka 充当数据 buffer,落盘数据到内置存储供查询分析。可以开启投递到 S3。

由于轻索引方案延迟表现不满足告警、仪表盘场景,但大部分时候它们的 query 模式固定,且按时间顺序进行。Humio 的方案是流计算,在数据摄入的 pipeline 中计算告警和图表:
- 只处理实时数据。
- 数据不需要排序。
- 数据都在内存中更新。

存储
内置存储主要服务的是日志搜索、分析场景,数据的压缩、索引对于后续的计算性能有决定性影响。
Humio 将数据按照 bucket 排列,在 bucket 上做好一些标签,标签内容包括:
- 数据的时间区间。
- 数据的来源、类型。
- 基于数据 key-value 的 bloom filter(增加 4% 存储以支持随机关键词)。

bucket 标签实际是一种粗粒度的索引,区别于以往对单条日志的细粒度索引。query engine 在计算时根据标签信息判断数据是否可能在 bucket 内,只读取相关的 bucket 数据。
计算
Humio 语法是管道式 SPL:
#host=github #parser=json
| repo.name=docker/*
| groupBy(repo.name, function=count())
| sort()
对应的执行计划:读数据、标签过滤、扫描过滤、聚合计算、结果写出。

暴力搜索通过分布式 mapper 可以加速,就单实例而言其加速策略如下图:

ChaosSearch
简介
ChaosSearch 2016 年成立,2020 年 11 月 B 轮融资(估值 $40 million)。在 2021 年,员工增加一倍(50~99 之间),收入 YoY 611% 增长。
ChaosSearch 提供多租户的 SaaS,面向日志和 BI 分析场景,主要是 Elasticsearch 兼容市场。索引对象存储上的数据,支持搜索、SQL、ML 计算。
ChaosSearch 对于数据源的要求最为宽泛(放在对象存储即可),以 Data Lake Engine 来宣传。目前支持 AWS、GCP,计划今年加入 Azure 支持。

数据路径
使用过程如下:
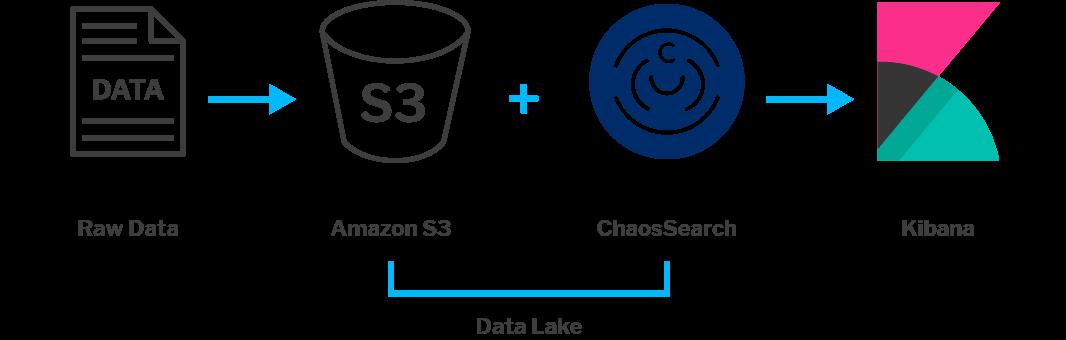
- 存入日志(通过 Logstash/Fluentd/Vector 等软件直接上传到 S3)。
- ChaosSearch 配置连接串,执行索引过程(支持周期性,实时两种模式)。
- 通过 ChaosRefinery 创建数据视图。
- 通过 API 或第三方可视化工具查询分析视图数据。
对象存储上的日志有以下要求:
- 支持三类数据:csv、log files(近 40 种流行格式)、json(BI 分析友好)。
- 文件大小建议为 10MB gzip 或 50~500 MB 原文。超大文件不利于并发度提升且消耗更大索引内存;过小的文件则会导致查询性能降低(依赖 compaction),同时大量文件会导致索引问题(实时索引依赖消息通知,而 AWS SQS 等系统存在系统限制)。
partition 机制有助于提升查询性能,可以在索引阶段将业务字段值设置为 partition 的一部分,建议一个object group 不超过一万 partition。
索引阶段读取 S3 文件,异步建立索引,将索引数据存储到用户的 S3 上作为 metadata。
存储
ChaosSearch 支持自动 schema 探测(可枚举的格式)或主动字段抽取(正则),生成的索引数据称为 ChaosIndex。

按照文档举例,其索引膨胀量在 5-10% 左右。Elasticsearch/Lucene 处理 1 PB 数据(压缩后)产生 5 PB 索引量,对应的 ChaosSearch 索引量在 250 TB 左右。
其索引算法效果描述亮眼,但缺少进一步资料确认,引述文档内容如下:
- In the case of Chaos Index, it provides compression ratios upward or greater than Gzip, with the speed of Google’s Snappy compression algorithm. Up to 95% compression at high performance.
- Text-based queries are up to 10x faster to index and up to 2x faster to search when compared to Lucene.
- Analytic queries are up to 5x faster to index and up to 2x faster to query when compared to column stores.
计算
计算的一种场景是 ELT(Chaos Refinery),将原始数据做一些简单处理形成视图:

最终的场景是为了搜索、分析,数据存储在 S3,对应的算力由同区域 EC2 提供。算力弹性、query plan 优化、索引优化是体验的三个重要因素。查询结果限制最多返回 500 条(这一点和 Loki 也一样,应该是性能上的保护考虑)。
用户通过 Kibana 来完成查询页、分析图表、仪表盘和告警。提供三种 API 形态:ChaosSearch API、S3 Rest API、Elasticsearch 兼容 API。
费用
作为 SaaS 服务,其计费模式非常简单:按照写入流量计算,$0.8/GB(不限 query 数)。
用户的另一部分费用是存储,直接交给云厂商,包括日志原文以及 ChaosSearch 生成的索引数据。
这种计费模型有一定好处,一次性付费后,查询起来没有心理负担。
厂商在超卖之后如何兑现算力是另一个话题:用户开启 burst 模式申请更多计算资源。

Opstrace
简介
Opstrace 在日志查询、分析上的深入程度比起 Humio、ChaosSearch 有差距,单列出来实为突出 Grafana 生态。
Opstrace 成立于 2019 年初,2021 年底被 GitLab 收购(是其上市以后的首次收购)。Opstrace 的关键词是开源(Datadog/Splunk/SignalFx 替代品),一套自动化编排流程帮助用户实现可观测平台。

Opstrace 目前支持 AWS、GCP 部署,计划扩展至 Azure(好像 Azure 总是被排在后面,跟市占率不太匹配)。
编排
Opstrace 提供 SaaS 能力,有独立的数据写入、读取 API,无论是 log 或 metric 都存储到 S3。
套件的主要部分是:
- 监控:Prometheus API。
- 日志:Loki API。
- 采集:目前覆盖到开源(以 Prometheus、Fluentd、Promtail 作为客户端),未来计划扩展至 Datadog。
当创建出 Opstrace 实例后,编排实现了云资源的准备(VPC、S3、EKS、ELB、Route53、EC2 等)、软件的部署(Prometheus、Loki 等)。

底层组件(Loki 部分)
Loki 是 Grafana 公司开源的一款日志分析软件,主要思想是用“Label Index + 暴力搜索”来解决问题。和 Elasticsearch 形成明显的差异:
- 写多读多,强 Schema 日志模型能实现可预期的低计算延时。
- 写多读少,非全文索引模式将成本大幅缩减并后置到查询时产生。
Loki 的文档和代码资料都很多,这里只作简单介绍。
数据存储:
- Index:Label 索引定义为 meta 字段索引,要求 cardinality 小(否则会索引爆炸,实测出现系统不可写入情况),例如在 K8s 场景 namespace、container、host、filepath 作为 Label 来搜索是非常合适的。
- Chunk:日志正文,行存格式,一组日志排列在一起,每条日志只包括 Timestamp 和 Line 两个字段。
- Index 存储:历史上写过 NoSQL,就目前情况来看未来都会用 S3(用 boltdb 来写索引文件,定时 flush)。
- Chunk 存储:一直建议用 S3 这样的对象存储。
架构上多个角色分工明确,可以独立扩容:
- Distributor:接受数据写入,根据协调服务内容转发数据给 Ingester。
- Ingester:
- 处理数据写入,负责 Chunk 构建,flush 数据到远端存储。
- 响应赖在 Querier 的查询请求(内存未 flush 部分)。
- Query Frontend:查询请求处理的第一站,负责简单的 query 改写,大 query 切分与分派,cache 处理。
- Querier:查询请求的 mapper 节点,负责 query 解析、执行,数据拉取,结果合并。
- Ruler:调度器,用于预计算。L abel 索引方案在做大规模 metric 计算时可能延时较高,部分场景下可救急。

Loki 的语法是 LogQL:
- 查询:体验优秀,管道式,很顺畅。实测下来性能也不错(例如 600 byte 原文中搜索 32 byte 内容,单核处理 3GB/s),但有 5000 条结果上限(没找到翻页机制)。
- 分析:语法从 Prometheus 继承而来,不好记,并且明显的时序结果导向在分析场景下显得片面了(SQL 已成为标准)。
举一个例子:大括号里面的部分是 Label 匹配,其后的计算都是扫描部分。
container="query-frontend",namespace="loki-dev" |= "metrics.go" | logfmt | duration > 10s and throughput_mb < 500
Loki 存储格式是行存,统计分析很难做出高效率。查询的效率取决于 Label Index,因此其依赖一种 K-V 读写的存储,通过一套编码机制来细化数据读取范围。v11 编码机制如下:
| 用途 | HashValue | RangeValue | Value |
| 查找有哪些日志线(用 label hash 区分)metricName -> seriesId | fmt.Sprintf("%02d:%s:%s", shard, bucket.hashKey, metricName) | encodeRangeKey(seriesRangeKeyV1, seriesID, nil, nil) | empty |
| 根据 label 名查找有哪些候选的取值(用于下拉提示)labelName -> hash(value):seriesID | fmt.Sprintf("%02d:%s:%s:%s", shard, bucket.hashKey, metricName, labelName) | encodeRangeKey(labelSeriesRangeKeyV1, sha256bytes(labelValue), seriesID, nil) | labelValue |
| 根据日志线,查找有哪些可用的 label 名(用于下拉提示)seriesId -> labelNames | seriesID | encodeRangeKey(labelNamesRangeKeyV1, nil, nil, nil) | labelNames |
| 根据日志线,查找 chunk 存储位置(用于拉取命中的 chunk)seriesID -> chunkID | fmt.Sprintf("%s:%s", bucket.hashKey, seriesID) | encodeRangeKey(chunkTimeRangeKeyV3, encodedThroughBytes, nil, []byte(chunkID)) | empty |
在不考虑严重数据时间乱序情况且 label cardinality(万以下)可控时,索引膨胀比在 千分之一到百分之一之间,S3 单价便宜,另外可以和 Grafana metric 生态形成体验的融合。这可能就是 Opstrace 选择 Loki 的原因。
参考
https://library.humio.com/stable/docs/index.html
https://www.youtube.com/watch?v=NF-IDXelm4I&list=PLrhuCswD2Pa0hpPs3XhD_ORmvAiCjiyiX&index=7&t=13s
https://www.chaossearch.io/blog
https://docs.chaossearch.io/docs
https://opstrace.com/blog/why-cortex-loki
https://grafana.com/docs/loki/latest/
绝大部分图片摘自几款产品的文档或博客。
本文为阿里云原创内容,未经允许不得转载。
以上是关于三款“非主流”日志查询分析产品初探的主要内容,如果未能解决你的问题,请参考以下文章