论文解读:记忆网络(Memory Network)
Posted yealxxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读:记忆网络(Memory Network)相关的知识,希望对你有一定的参考价值。
在了解vqa问题的论文时,发现有很多论文采用了记忆网络的思路,模拟推理过程,这篇文章主要总结关于记忆网络的三篇经典论文,目的是对记忆网络有个认识。分别是:
MEMORY NETWORKS,End-To-End Memory Networks,Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
一,MEMORY NETWORKS
这是Facebook AI在2015年提出来的:MEMORY NETWORKS。论文是第一次提出记忆网络,利用记忆组件保存场景信息,以实现长期记忆的功能。对于很多神经网络模型,RNN,lstm和其变种gru使用了一定的记忆机制,在Memory Networks的作者看来,这些记忆都太小了。这就是这篇文章的目的。
我将从三个部分讲解这篇文章:
- 记忆网络各个组件的内容
- 记忆网络在nlp的使用
- 损失函数
1,记忆网络:
一个记忆网络(memory networks,简称为MemNN),包括了记忆m,还包括以下4个组件I、G、O、R(lstm的三个门,然后m像cell的list):
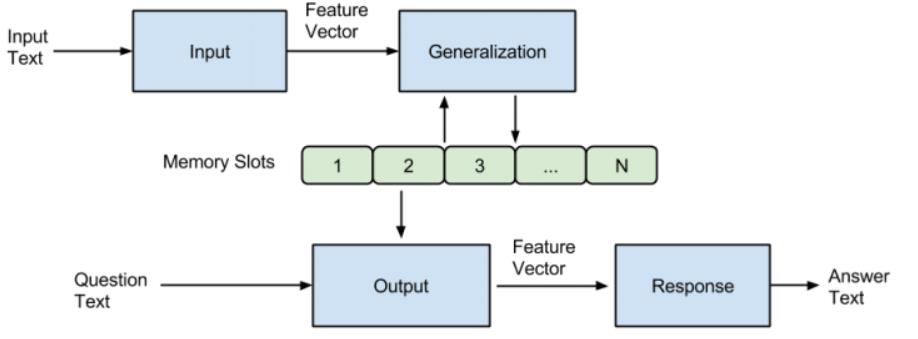
- I: (input feature map):用于将输入转化为网络里内在的向量。(可以利用标准预处理,例如,文本输入的解析,共参考和实体解析。 还可以将输入编码为内部特征表示,例如,从文本转换为稀疏或密集特征向量)
- G: (generalization):更新记忆。在作者的具体实现里,只是简单地插入记忆数组里。作者考虑了几种新的情况,虽然没有实现,包括了记忆的忘记,记忆的重新组织。(最简单的G形式是将I(x)存储在存储器中的“slot”中)
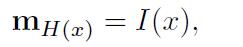
- O: (output feature map):从记忆里结合输入,把合适的记忆抽取出来,返回一个向量。每次获得一个向量,代表了一次推理过程。
- R: (response):将该向量转化回所需的格式,比如文字或者answer。
2,记忆网络在nlp的使用:
场景:给一个段落和一个问题,给出回答
-
I: 输入的是一句话,简单地将I转换为一个频率的向量空间模型。
-
m: 记忆卡槽list。
-
G:简单地把读到的对话组里的每一句话的向量空间模型,插到记忆的list里,这里默认记忆插槽比对话组句子还多。
-
O:就是输入一个问题x,将最合适的k个支撑记忆(the supporting memories,在下文的数据集里会举出例子),也就是top-k。做法就是把记忆数组遍历,挑出最大的值。最后,O返回一个长度为k的数组。
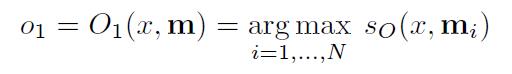
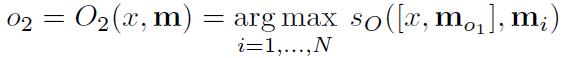
-
R:利用O得到的输出,返回一个词汇w。
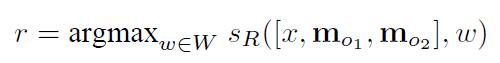
-
打分函数:在O和R中的打分函数:
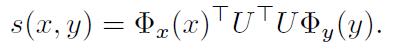
3,损失函数
采用margin ranking loss,这个与支持向量机的损失函数类似。(即是选出最合适中间结果,和得到最好的预测输出。)
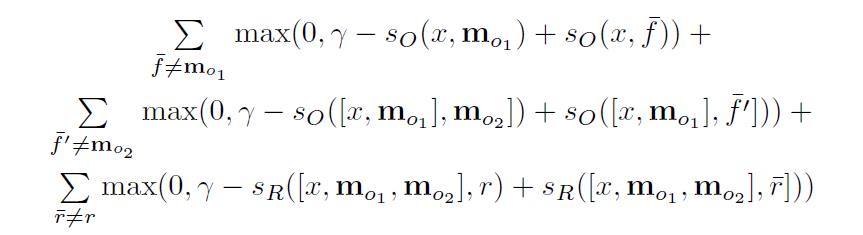
4,理解
- 记忆网络是一个组件形式的模型,每个模型相互对立又相互影响。每个组件没有固定的模型,可以是传统的模型,也可以是神经网络。
- 论文的缺陷没有思想端到端的训练,端到端的训练将在下面介绍。
二,End-To-End Memory Networks
这篇文章是上面一篇文章的基础之上提出来的端到端的训练方式。并提出重复的去提取有用的信息,实现多次推理的过程。End-To-End Memory Networks
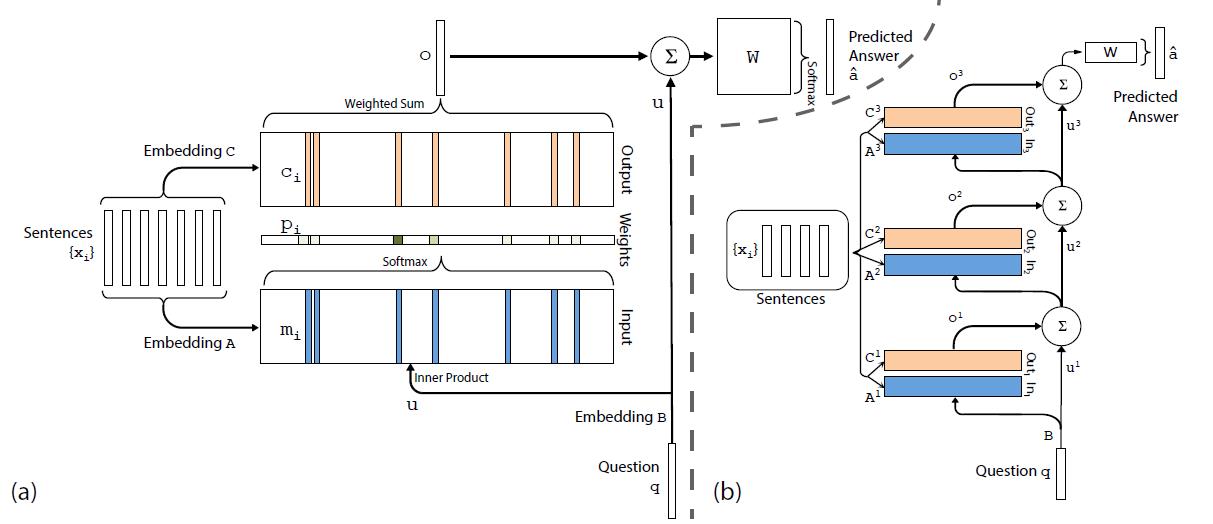
1,单次推理:图a
使用输入集合S=x1,x2,…xi,…,xnS=x1,x2,…xi,…,xn表示上下文知识,使用输入向量q表示问题,使用输出向量aˆ表示预测答案。记忆网络模型通过对上下文集合S和问题向量q的数学变换,得到对应于问题的答案。
- Input memory representation:把 词进行embedding,变成向量放入m中。
- q:对问题q进行同样的embedding
- 计算u和记忆m的匹配程度。
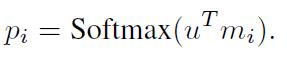
- 输出o:记忆m的加权和
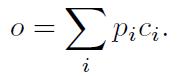
-用o,以及问题u预测答案:
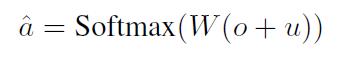
2,多次推理:图b
-
每次的更新:
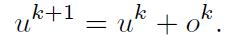
-
经过多次推理,计算输出:
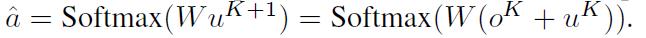
-
对于权重参数设置,作者提出两种方案:

三,Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
这篇文章是记忆网络的改进版本,提出的DMN网络模型包含输入、问题、情景记忆、回答四个模块,架构图如下所示。模型首先会计算输入和问题的向量表示,然后根据问题触发Attention机制,使用门控的方法选择出跟问题相关的输入。然后情景记忆模块会结合相关的输入和问题进行迭代生成记忆,并且生成一个答案的向量表示。
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
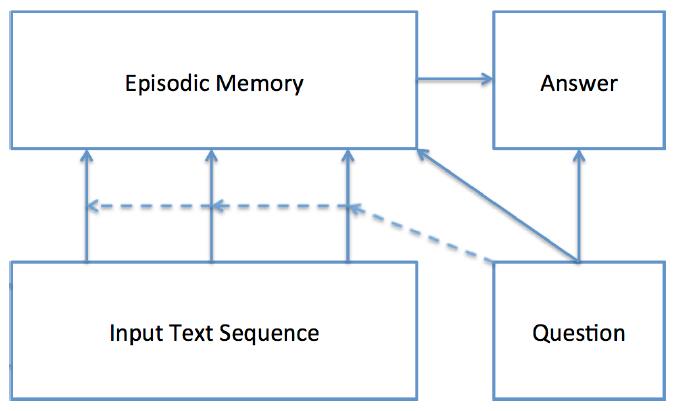
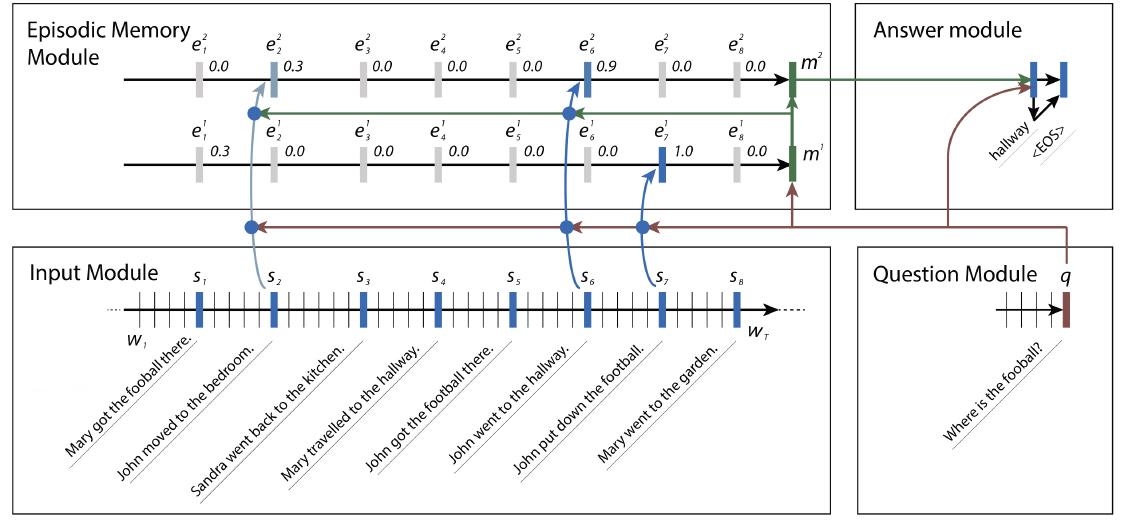
1,Input Module
使用GRU对输入进行编码,(这里论文中有提到GRU和LSTM,说GRU可以达到与LSTM相似的准确度而且参数更少计算更为高效,但都比RNN要好)
- 对于单个句子:使用GRU中间的state作为输入
- 对于多个句子:采用GRU在每个句子的最后状态作为输入
2,Question Module
- 这部分与Input Module一样,就是使用GRU将Question编码成向量。(不同的是,最后只输出最后的隐层向量即可,而不需要像Input模块那样,输入是句子时,会输出句长个向量)。
- q向量除了用于Attention外,还会作为Memory模块GRU的初始隐层状态。
3,Episodic Memory Module
这部分主要有三部分:注意力机制、记忆更新、多次迭代。
- Attention Mechanism:注意力机制:这里使用一个门控函数作为Attention。
输入是本时刻的输入c,前一时刻的记忆m和问题q。首先计算相互之间的相似度作为特征向量传入一个两层的神经网络,最终计算出来的值就是门控函数的值,也就是该输入与问题之间的相似度。(G是得分函数)
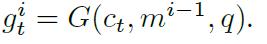

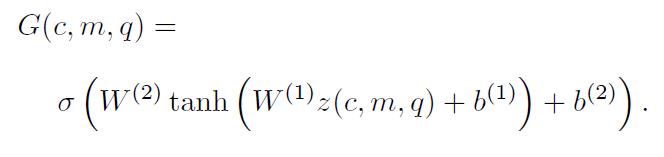
- Memory Update Mechanism:记忆更新:计算出门控函数的值之后,根据其大小对记忆进行更新。更新方法就是GRU算出的记忆乘以门控值,再加上原始记忆乘以1-门控值。
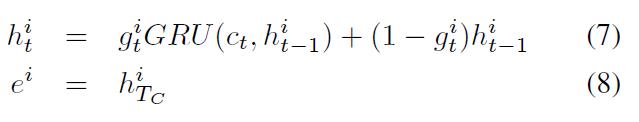

- Need for Multiple Episodes:每次迭代关注不同的内容,这样传递推导,检索不同的信息。
3,Answer Module
使用GRU最为本模块的模型,根据memory模块最后的输出向量(将其作为初始隐层状态),然后输入使用的是问题和上一时刻的输出值连接起来(每个时刻都是用q向量)。并使用交叉熵损失函数作为loss进行反向传播训练。

以上是关于论文解读:记忆网络(Memory Network)的主要内容,如果未能解决你的问题,请参考以下文章