再学DataX
Posted Shi Peng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了再学DataX相关的知识,希望对你有一定的参考价值。
一、DataX简介
DataX官网文档:https://github.com/alibaba/DataX/blob/master/introduction.md
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(mysql、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
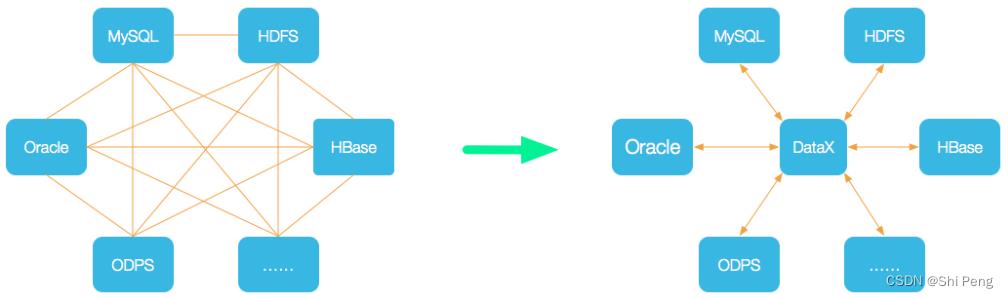
1.1、DataX 3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
1.2、DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行
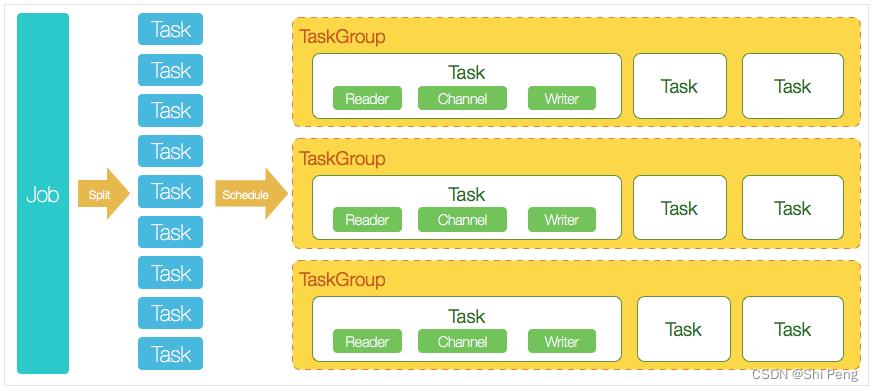
1、Job
DataX完成单个数据同步的作业。一个Job对应一个进程。Job模块负责task切分,TaskGroup管理等。
2、Task
Task是DataX的最小单元,每个task负责一部分数据同步工作。
3、TaskGroup
Job在切分完多个Task后,会调用DataX的scheduler模块,根据配置的并发量,将拆分成的多个Task分配到不同的TaskGroup中,每个TaskGroup负责以一定并发运行分配给他的全部Task,每个TaskGroup默认的并发量是5.
4、Task的执行流程
每个Task由TaskGroup启动,每个Task对固定启动Reader—>Channel—>Writer的线程来完成数据同步工作。
DataX Job运行起来后,由Job监控并等待每个TaskGroup的task执行完成,等所有TaskGroup任务执行完成后,Job成功退出。否则,异常退出。
5、DataX调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。
DataX的调度决策思路是:
1)DataX Job根据分库分表切分成了100个Task。
2)由于配置了20个并发,每个TaskGroup默认并发度是5,所以需要4个TaskGroup
3)由4个TaskGroup平均切分100个Task,每个TaskGroup被分到了25个Task,共启动5个并发。
1.3、DataX优势
1、可靠的监控
2、数据转换功能丰富
3、精准的流控
4、同步性能好
5、容错机制健壮
6、使用体验好
二、DataX源码解读
2.1、入口类:Engine
入口类为com.alibaba.datax.core.Engine.java main函数
1、解析args入参:
Options options = new Options();
options.addOption("job", true, "Job config.");
options.addOption("jobid", true, "Job unique id.");
options.addOption("mode", true, "Job runtime mode.");
BasicParser parser = new BasicParser();
CommandLine cl = parser.parse(options, args);
针对命令行参数采用了org.apache.commons的BasicParser解析,针对任务的配置文件则通过其本身的ConfigParser进行解析(可以支持本地和网络文件)。
2、启动Engine
参数启动完毕后,调用Engine.start方法启动
ConfigurationValidate.doValidate(configuration);
Engine engine = new Engine();
engine.start(configuration);
然后选择是Job模式还是TaskGroup模式:
boolean isStandAloneMode = "standalone".equalsIgnoreCase(RUNTIME_MODE);
实际上基本都是Job模式,后续我们主要以JobContainer为切入点,另一个则为TaskGroupContainer。两者均继承自AbstractContainer基类,并通过调用他们的start方法进行启动。
2.2、JobContainer
JobContainer.start方法是入口
preHander
Job前置操作,即初始化preHandler插件并执行其preHandler
1)init
初始化reader和writer,实际方法中根据读写插件各自执行了对应的初始化方法:
//必须先Reader ,后Writer
this.jobReader = this.initJobReader(jobPluginCollector);
this.jobWriter = this.initJobWriter(jobPluginCollector);
2)prepare
全局准备工作,比如odpswriter清空目标表。由于读写插件的特殊性质,其方法内部主要也是执行了各类型插件的方法来实现准备工作
this.prepareJobReader();
this.prepareJobWriter();
3)split
拆分Task,参数adviceNumber为建议的拆分数。除此之外我们还可以通过字节和事务的限速来进行控制,从而决定Channel的数量。
- job.setting.speed.byte:总BPS限速,如果存在值则单个Channel的BPS不能为空,通过总限速除以单个Channel限速得出Channel的需求数量;
- core.transport.channel.speed.byte:单个Channel的BPS限速;
- job.setting.speed.record:总TPS限速,如果存在则单个Channel的TPS不能为空,通过总限速除以单个Channel限速得出Channel的需求数量;
- core.transport.channel.speed.record:单个Channel的TPS限速;
4)schedule
schedule首先完成的工作是把上一步reader和writer split的结果整合到具体taskGroupContainer中, 同时不同的执行模式调用不同的调度策略,将所有任务调度起来
由于实际任务是由TaskGroupContainer执行,为此我们还需要划分对应TaskGroup需要运行的Task,该参数通过core.container.taskGroup.channel进行配置,默认为5。决定每个Group运行那些Task的则由以下方法进行决定,将直接返回对应任务组的配置参数。
/**
* 通过获取配置信息得到每个taskGroup需要运行哪些tasks任务
*/
List<Configuration> taskGroupConfigs = JobAssignUtil.assignFairly(this.configuration,
this.needChannelNumber, channelsPerTaskGroup);
完成任务分配后我们就需要根据运行模式决定调度器,通过这里的源码可以明显看出其DataX 3.0是经过了阉割,仅保留了单机运行模式。
executeMode = ExecuteMode.STANDALONE;
scheduler = initStandaloneScheduler(this.configuration);
后续我们仅能描述单机模式下关于任务调度的工作原理:
Step1:调度器初始化的核心方法initStandaloneScheduler,其方法主要是初始化了StandAloneJobContainerCommunicator类用于通信(其中collect由ProcessInnerCollector提供,reporter由ProcessInnerReporter提供),StandAloneScheduler则为实际调度器。
最终执行:
scheduler.schedule(taskGroupConfigs);
在AbstractScheduler的schedule中通过StandAloneJobContainerCommunicator类调用了其collect方法:
public Communication collect()
return super.getCollector().collectFromTaskGroup();
该类为ProcessInnerCollector类,其对应的方法依然是LocalTGCommunicationManager静态类其中一个静态方法。
public Communication collectFromTaskGroup()
return LocalTGCommunicationManager.getJobCommunication();
其内部也是将之前每个TaskGroup所创建的Communication维护了一个静态字典并在需要的时候进行合并。
public static Communication getJobCommunication()
Communication communication = new Communication();
communication.setState(State.SUCCEEDED);
for (Communication taskGroupCommunication :
taskGroupCommunicationMap.values())
communication.mergeFrom(taskGroupCommunication);
return communication;
以上是关于再学DataX的主要内容,如果未能解决你的问题,请参考以下文章