存储设计——如何优化 ClickHouse 索引
Posted FesonX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了存储设计——如何优化 ClickHouse 索引相关的知识,希望对你有一定的参考价值。
Keypoint
- ClickHouse 索引与其他 RDMS 区别
- 稀疏主键索引及其构建
- ClickHouse 索引最佳实践
ClickHouse 的索引设计
Whole data: [---------------------------------------------]
CounterID: [aaaaaaaaaaaaaaaaaabbbbcdeeeeeeeeeeeeefgggggggghhhhhhhhhiiiiiiiiikllllllll]
Date: [1111111222222233331233211111222222333211111112122222223111112223311122333]
Marks: | | | | | | | | | | |
a,1 a,2 a,3 b,3 e,2 e,3 g,1 h,2 i,1 i,3 l,3
Marks numbers: 0 1 2 3 4 5 6 7 8 9 10
从文件目录看 ClickHouse 存储设计
/var/lib/clickhouse
- DataBase
- Table
- Parts all/Partition_key xxxx (分区键影响parts 数量)
- checksum.txt (例如因为同步导致all broken parts to remove错误)
- columns.txt (列及对应格式的数据)
- count.txt (当前数据块条数)
- default_compression_codec.txt(压缩格式,默认 LZ4)
- primary.idx 主键索引 (可以与 ORDER BY 不同)
- Column.bin(数据文件,压缩后可能是 1:6,2:7,3:4....,在 Compact 模式下,只有一个 bin)
- Column.mk2 (好像都一样大小,像是 Mark的缩写?)
从存储文件夹中可以看到,分级大概是
表 -> Parts -> 主键索引(idx)、各个列数据文件(bin)、列数据对应 Mark(mk2) 及其他元数据文件。
bin 文件受主键排序及 ORDER BY 键以及插入顺序所影响。
相同数据受低基数及高基数主键排序影响,如下所示,是数据相同但主键不同的表的相同 part,高基数排列的表,除 URL 列外,其他两个列的数据文件大小均比低基数排列的表要大。但实际查询的时候是否高基数会更快呢?打个问号。
# 高基数排列
drwxr-x--- 13 root root 416 Nov 8 01:25 .
drwxr-x--- 7 clickhouse clickhouse 224 Nov 8 01:34 ..
-rw-r----- 1 root root 349 Nov 8 01:25 checksums.txt
-rw-r----- 1 root root 82 Nov 8 01:25 columns.txt
-rw-r----- 1 root root 7 Nov 8 01:25 count.txt
-rw-r----- 1 root root 10 Nov 8 01:25 default_compression_codec.txt
-rw-r----- 1 root root 269624 Nov 8 01:25 IsRobot.bin
-rw-r----- 1 root root 21624 Nov 8 01:25 IsRobot.mrk2
-rw-r----- 1 root root 75638 Nov 8 01:25 primary.idx
-rw-r----- 1 root root 120469184 Nov 8 01:25 URL.bin
-rw-r----- 1 root root 21624 Nov 8 01:25 URL.mrk2
-rw-r----- 1 root root 9964518 Nov 8 01:25 UserID.bin
-rw-r----- 1 root root 21624 Nov 8 01:25 UserID.mrk2
# 低基数排列
drwxr-x--- 13 root root 416 Nov 8 01:34 .
drwxr-x--- 8 clickhouse clickhouse 256 Nov 8 01:45 ..
-rw-r----- 1 root root 348 Nov 8 01:34 checksums.txt
-rw-r----- 1 root root 82 Nov 8 01:34 columns.txt
-rw-r----- 1 root root 7 Nov 8 01:34 count.txt
-rw-r----- 1 root root 10 Nov 8 01:34 default_compression_codec.txt
-rw-r----- 1 root root 32717 Nov 8 01:34 IsRobot.bin
-rw-r----- 1 root root 21528 Nov 8 01:34 IsRobot.mrk2
-rw-r----- 1 root root 77519 Nov 8 01:34 primary.idx
-rw-r----- 1 root root 158361024 Nov 8 01:34 URL.bin
-rw-r----- 1 root root 21528 Nov 8 01:34 URL.mrk2
-rw-r----- 1 root root 785254 Nov 8 01:34 UserID.bin
-rw-r----- 1 root root 21528 Nov 8 01:34 UserID.mrk2
隐含的 Granule —— 并发的最小读取单位
mk2 是一眼看不出内容的文件,不同列的文件大小(几乎)相同。
在创建表时经常看到一个设置, granule=8192,但在存储文件中似乎没有与之相关的内容。这个 Granule 实际上就与 mk2 绑定,而 idx 大小也和它挂钩。
ClickHouse 借由二分索引对主键索引数据块进行搜索,跳过不需要的数据组,这个组就是隐含的 Granule。
默认一个 Granule 由 8192 行数据组成。每 8192 行就有一个主键索引作为数据入口。
为了把主键完整地放入主内存,要求主键必须足够小,因此有时候会独立定义一个主键和 ORDER BY 键(主键必须是 ORDER BY 键的前缀)。
一个 887 万的数据主键索引只有 1083 个索引值。mysql 则必须将主键全部索引,当然,好处是它可以借助 B 树索引到某条记录,而在并发读取数据时, ClickHouse 则至少需要读 8190 行。
除最后一列外,每个 Granule 的主键索引皆为该组合列的最小值,使之单调递增,但未必指向具体的行。如下图所示,UserID 与 URL 构成的主键并不在同一行。
-- Granule0, Mark 0
240.923,goal://metry=10000467796a411...
-- Granule1, Mark1
4073,710,goal://dream...
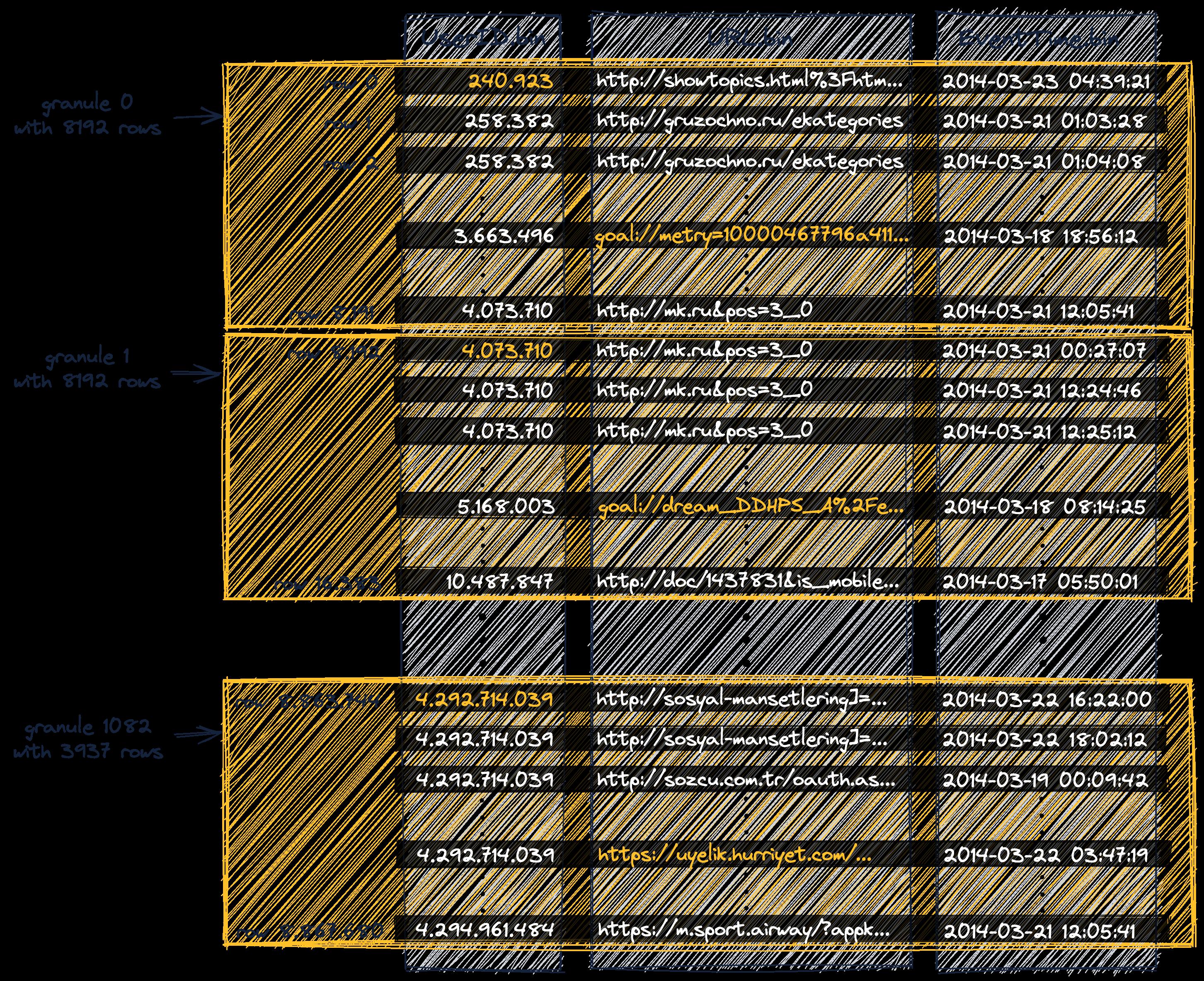
标记主键 idx——ClickHouse 的排除法
假设先按 UserID 再按 URL 排序,这表示 UserID 这一列的数据是 100% 按字母顺序(lexicographical Ordering)单调递增的,240.923 就是所有 UserID 数据中最小的
但 URL 作为次一级,只能保证在该 Granule 里是最小的,例如 Granule 0里的 goal://metry=10000467796a411,其他 Granule 不能保证。
但是是否意味着只能在同一个 Granule 中做排除呢?也不是,如果 Granule0-3 都是相同 UserID,那么同样可以确认 goal://metry=10000467796a411 是这三个块里面最小的,查询小于这个值时,三个皆可排除。
这里你可能看到了优化的曙光,后文将详谈。
Mk2——数据的“指针”
-- Column.mk2 --
-- 压缩后的数据块位置(bin)
-- 解压后的数据块位置
block_offset,granule_offset

标记文件是实际数据的“指针”,分别指向解压前后的具体数据块位置,前面提到 Granule 是最小并发读取单位,这里可以更明确这一概念:
- Stage 1:ClickHouse 通过主键索引排除 Granule
- Stage 2:未被排除的 Granule 根据编号在 mk2 中找到对应的数据块解压获取数据,由于数据是压缩的,解压本身似乎暗含了按块读取的必然性。
mk2 的设计也符合列式数据库的设计方式,方便删除单列(主键除外)而不需要修改索引,需要读取特定列的数据再读以减少内存占用。
而同时也说明一个常见的查询“偷懒”习惯 SELECT * 危害之大:
越多的列被选中,则需要打开的文件解压的数据越多,如果是一个数据量大的列(例如响应体)势必需要消耗更多的内存和 CPU。
下图是查询某用户的 Top 10 URL 访问的数据读取图
SELECT URL, count(URL) AS Count
FROM hits_UserID_URL
WHERE UserID = 749927693
GROUP BY URL
ORDER BY Count DESC
LIMIT 10;

Ref: Block In ClickHouse
以上是关于存储设计——如何优化 ClickHouse 索引的主要内容,如果未能解决你的问题,请参考以下文章