都2021年了,不会还有人连深度学习都不了解吧-- 下采样篇
Posted 奋斗の博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了都2021年了,不会还有人连深度学习都不了解吧-- 下采样篇相关的知识,希望对你有一定的参考价值。
导读
该篇文章重点介绍CNN中下采样方式,下采样是CNN中必不可少的阶段之一,CNN中常用的下采样方式有平均池化和最大池化,同时平均池化和最大池化也是注意力机制的重要组件。
目前深度学习系列已经更新了6篇文章,分别是激活函数篇、卷积篇、损失函数篇、评估指标篇,另还有1篇保姆级入门教程,1篇总结性文章CNN中十大令人拍案叫绝的操作,想要入门深度学习的同学不容错过!

一、下采样方式
平均池化和最大池化是CNN中使用最多的下采样方式,所谓的池化,是指特征图分别在高、长方向上的缩小运算,下采样目的在于增加模型的鲁棒性,所谓的鲁棒性,可以简单理解为当输入数据发生微小偏差时,结果仍是相同的。池化的特征主要有3个:
- ①池化层没有要学习的参数,这与卷积层有质的区别。
- ②经过池化层后,特征图的通道数不会发生变化,即输入数据和输出数据的通道数是相同的。
- ③对微小的位置变化具有鲁棒性。
下面我们分别介绍最大池化(MaxPool)和平均池化(AvgPool)两种最常见的下采样方式。
1.1 最大池化
假设有一张特征图X,size为(4,4),池化窗口kernel size为2,池化步长为2。
step1:
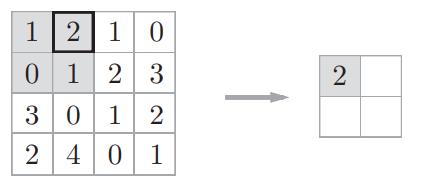
step2:
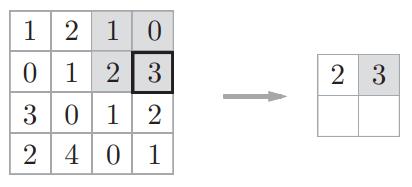
step3:
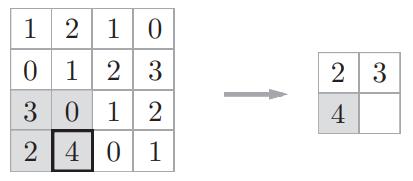
step4:
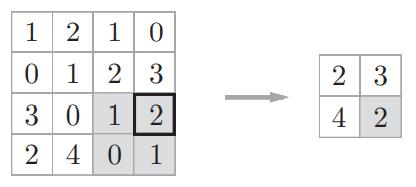
1.2 平均池化
平均池化的运行原理跟最大池化基本一样,唯一不同之处在于平均池化是计算目标区域的平均值。
step1:
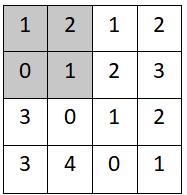
- (1+2+0+1)/ 4=1
step2:

- (1+2+2+3)/ 4=2
step3:
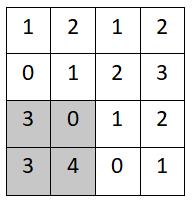
- (3+0+3+4)/ 4=2
step4:
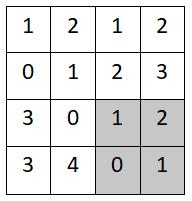
- (1+2+0+1)/ 4=1
最后特征图变为:
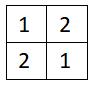
1.3 size的变化
假设输入大小为(H, W),滤波器大小为(FH, FW),输出大小为(OH, OW),填充为P,步幅为S,输出大小可通过下式计算得到。
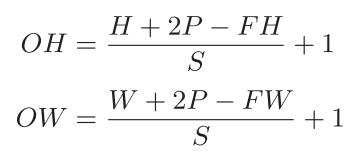
二、下采样作用
下采样的优势主要有以下几点:
- ①降维,减少网络要学习的参数数量。
- ②防止过拟合。
- ③增大感知野
- ④可以实现不变性:平移不变性,旋转不变性,尺度不变性。
下采样最大的劣势在于在下采样过程中会丢失大量的特征信息,但是这些信息可以通过一些特有的手段在一定程度上进行弥补。
文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个专注于医学图像处理领域前沿科技的公众号。坚持以实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。更有上百部深度学习入门资料免费等你来拿,只有实践才能成长的更快,关注我们,一起学习进步~
计划
深度学习保姆级入门教程 – 论文+代码+常用工具
1个字,绝! – CNN中十大令人拍案叫绝的操作
都2021年了,不会还有人连深度学习还不了解吧?(一)-- 激活函数篇
都2021年了,不会还有人连深度学习还不了解吧?(二)-- 卷积篇
都2021年了,不会还有人连深度学习还不了解吧?(三)-- 损失函数篇
都2021年了,不会还有人连深度学习还不了解吧?(四)-- 上采样篇
都2021年了,不会还有人连深度学习还不了解吧?(五)-- 下采样篇
都2021年了,不会还有人连深度学习还不了解吧?(六)-- Padding篇
都2021年了,不会还有人连深度学习还不了解吧?(七)-- 评估指标篇
都2021年了,不会还有人连深度学习还不了解吧?(八)-- 优化算法篇
都2021年了,不会还有人连深度学习还不了解吧?(九)-- 注意力机制篇
都2021年了,不会还有人连深度学习还不了解吧?(十)-- 数据归一化篇
觉得写的不错的话,欢迎点赞+评论+收藏,欢迎关注我的微信公众号,这对我帮助真的很大很大很大!

以上是关于都2021年了,不会还有人连深度学习都不了解吧-- 下采样篇的主要内容,如果未能解决你的问题,请参考以下文章