监控服务器体系
Posted Drw_Dcm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了监控服务器体系相关的知识,希望对你有一定的参考价值。
目录
6.Data Visualization(Dashboards)
(2)只列出与静态Prometheus.yml文件区别的地方
(3)编写prometheus.yml文件发现指定的targets文件
一、常用监控简介
1.cacti
Cacti(英文含义为仙人掌〉是一套基于 php、mysql、SNMP和 RRDtool开发的网络流量监测图形分析工具。
通过snmpget来获取数据,使用RRDTool绘图,但使用者无须了解RRDTool复杂的参数。它提供了非常强大的数据和用户管理功能,可以指定每一个用户能查看树状结构、主机设备以及任何一张图,还可以与LDAP 结合进行用户认证,同时也能自定义模板,在历史数据的展示监控方面,其功能相当不错。
Cacti通过添加模板,使不同设备的监控添加具有可复用性,并且具备可自定义绘图的功能,具有强大的运算能力(数据的叠加功能)。
2.Nagios
Nagios是一款开源的免费网络监视工具,能有效监控windows、Linux和Unix的主机状态,交换机路由器等网络设置打印机等。在系统或服务状态异常时发出邮件或短信报警第一时间通知网站运维人员,在状态恢复后发出正常的邮件或短信通知。
nagios主要的特征是监控告警,最强大的就是告警功能,可支持多种告警方式,但缺点是没有强大的数据收集机制,并且数据出图也很简陋,当监控的主机越来越多时,添加主机也非常麻烦,配置文件都是基于文本配置的,不支持web方式管理和配置,这样很容易出错,不宜维护。
3.Zabbix
zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。zabbix能监视各种网络参数,保证服务器系统的安全运营;并提供强大的通知机制以让系统运维人员快速定位/解决存在的各种问题。
zabbix由2部分构成,zabbix server与可选组件zabbix agent。zabbix server可以通过SNMP,zabbix agent,ping,端口监视等方法提供对远程服务器/网络状态的监视,数据收集等功能,可以运行在Linux,Solaris,HP-UX,AIX,Free BSD,Open BSD,os x等平台上。
zabbix解决了cacti没有告警的不足,也解决了nagios不能通过web配置的缺点,同时还支持分布式部署,这使得它迅速流行起来,zabbix也成为目前中小企业监控最流行的运维监控平台。
当然,zabbix也有不足之处,它消耗的资源比较多,如果监控的主机非常多时(服务器数量超过500台),可能会出现监控超时、告警超时、告警系统单点故障等现象,不过也有很多解决办法,比如提高硬件性能、改变zabbix监控模式、多套zabbix等。
①agent代理:专门的代理服务方式进行监控,专属的协议,装有zabbix-agent的主机就可以被zabbix-server监控,主动或被动的方式,把数据给到server进行处理。
②ssh/telent:linux主机支持ssh/telent协议
③snmp:网络设备路由器、交换机不能安装第三方程序(agent),使用简单网络协议。大多数的路由器设备支持SNMP协议
④ipmi:通过ipmi接口进行监控,我们可以通过标准的ipmi硬件接口,监控被监控对象的物理特征,比如电压,温度,风扇状态电源情况,被广泛使用服务监控中,包括采集cpu温度,风扇转速,主板温度,及远程开关机等等,而且ipmi独立于硬件和操作系统,无论是cpu,bios还是os出现故障,都不会影响ipmi的工作,因为ipmi的硬件设备BMC(bashboard management controller)是独立的板卡,独立供电。
zabbix核心组件介绍
①Zabbix Server:Zabbix软件实现监控的核心程序,主要功能是与Zabbixproxies和Agents进行交互、触发器计算、发送告警通知;并将数据集中保存。与prometheus的类似可以保存收集到的数据,但是prometheus告警需要使用alter manager组件。
②Database storage:存储配置信息以及收集到的数据
③web Interface: Zabbix的GUI接口,通常与server运行在同一台机器上
④Proxy:可选组件,常用于分布式监控环境中,一个帮助zabbix Server收集数据,分担zabbix Server的负载的程序
⑤Agent:部署在被监控主机上,负责收集数据发送给server
4.Prometheus
作为一个数据监控解决方案,由一个大型社区支持,有来自700多家公司的6300个贡献者,13500个代码提交和7200个拉取请求。
特性
① 多维的数据模型(基于时间序列的Key、value键值对)
② 灵活的查询和聚合语言PromQL
③ 提供本地存储和分布式存储
④ 通过基于HTTP和HTTPS的Pull模型采集时间序列数据(pull数据的推送,时间序列:每段
时间点的数据值指标,持续性的产生。横轴标识时间,纵轴为数据值,一段时间内数值的动态变化,所有的点连线形成大盘式的折线图)
⑤ 可利用Pushgateway (Prometheus的可选中间件)实现Push模式
⑥ 可通过动态服务发现或静态配置发现目标机器(通过consul自动发现和收缩)
⑦ 支持多种图表和数据大盘
二、运维监控平台设计
1.数据收集模块
2.数据提取模块
3.监控告警模块
| 第六层:用户展示管理层 | 同一用户管理、集中监控、集中维护 |
| 第五层:告警事件生成层 | 实时记录告警事件、形成分析图表(趋势分析、可视化) |
| 第四层:告警规则配置层 | 告警规则设置、告警伐值设置 |
| 第三层:数据提取层 | 定时采集数据到监控模块 |
| 第二层:数据展示层 | 数据生成曲线图展示(对时序数据的动态展示) |
| 第一层:数据收集层 | 多渠道监控数据 |
三、prometheus监控体系
① 系统层监控(需要监控的数据)
1.CPU、Load、Memory、swap、disk i/o、process等
2.网络监控:网络设备、工作负载、网络延迟、丢包率等
② 中间件及基础设施类监控
1.消息中间件:kafka、RocketMQ、等消息代理
2.WEB服务器容器:tomcat
3.数据库/缓存数据库:MySQL、PostgreSQL、MogoDB、es、redis
redis监控内容:
redis所在服务器的系统层监控
redis 服务状态 redis-cli info sentinel redis-cli info replication
RDB AOF日志监控
日志→如果是哨兵模式→哨兵共享集群信息,产生的日志→直接包含的其他节点哨兵信息及mysql信息
③ 应用层监控
用于衡量应用程序代码状态和性能
监控的分类:黑盒监控,白盒监控
白盒监控,自省指标,等待被下载
黑盒指标:基于探针的监控方式,不会主动干预、影响数据
④ 业务层监控
用于衡量应用程序的价值,如电商业务的销售量,ops、dau日活、转化率等,业务接口:登入数量,注册数、订单量、搜索量和支付量
⑤硬件层面监控
交换机 路由器 服务器CPU温度 空气污染值
四、Prometheus简介
Prometheus是一套开源的监控、报警、时间序列、数据库的组合采集的样本以时间序列的方式保存在内存(TSDB时序数据库)中并定时保存到硬盘中(持久化)时序数据库不属于sql数据库也并不是nosql数据库。
1.Prometheus特点
①自定义多维数据模型(时序列数据由metric名和一组key/value标签组成)。
②非常高效的储存平均一个采样数据占大约3.5bytes左右,320万的时间序列,每30秒采样,保持60天,消耗磁盘大概228G。
③在多维上灵活且强大的查询语句(PromQL)
④不依赖分布式储存,支持单主节点工作
⑤通过基于HTTP的pull方式采集时序数据
⑥可以通过push gateway进行时序列数据库推送(pushing)
⑦可以通过服务发现或静态配置去获取要采集的目标服务器
⑧多种可视化图表及仪表盘支持
2.适用场景
Prometheus可以很好地记录任何纯数字时间序列。既适用于以机器为中心的监视,也适用于高度动态的面向服务的体系结构的监视。在微服务世界中,对多维数据收集和查询的支持是一种特别的优势。
Prometheus是为可靠性而设计的,在中断期间要使用的系统,可让快速诊断问题。每个Prometheus服务器都是独立的,而不依赖于网络存储或其他远程服务。当基础结构的其他部分损坏时,可以依靠并且无需设置广泛的基础结构即可使用。
3.不适合的场景
Prometheus重视可靠性。即使在故障情况下,始终可以查看有关系统的可用统计信息。如果需要100%的准确性(例如按请求计费),则Prometheus并不是一个不错的选择,因为所收集的数据可能不会足够详细和完整。在这种情况下,最好使用其他系统来收集和分析数据以进行计费,并使用Prometheus进行其余的监视。
五、prometheus时序数据
时序数据,是在一段时间内通过重复测量(measurement)而获得的观测值的集合将这些观测值绘制于图形之上,会有一个数据轴和一个时间轴,服务器指标数据、应用程序性能监控数据、网络数据等也都是时序数据
1.数据来源
prometheus基于HTTP call (http/https请求),从配置文件中指定的网络端点(endpoint/IP:端口)上周期性获取指标数据。
很多环境、被监控对象,本身是没有直接响应/处理http请求的功能,prometheus-exporter则可以在被监控端收集所需的数据,收集过来之后,还会做标准化,把这些数据转化为prometheus可识别,可使用的数据(兼容格式)
2.收集数据
监控概念:白盒监控、黑盒监控
白盒监控:自省方式,被监控端内部,可以自己生成指标,只要等待监控系统来采集时提供出去即可,被监控端自身可产出指标数据的类型,且监控服务可直接来抓取的监控类型,叫做内建的指标暴露器。
黑盒监控:对于被监控系统没有侵入性,对其没有直接"影响",这种类似于基于探针机制进行监控(snmp协议)
Prometheus支持通过三种类型的途径从目标上"抓取(Scrape)"指标数据(基于白盒监控);
Exporters→工作在被监控端,周期性的抓取数据并转换为pro兼容格式等待prometheus来收集,并不推送
Instrumentation →指被监控对象内部自身有数据收集、监控的功能,只需要prometheus直接去获取
Pushgateway→短周期5s到10s的数据收集,是一种PUSH模型的数据采集方式
3.prometheus(获取方式)
Prometheus同其它TSDB相比有一个非常典型的特性:它主动从各Target上拉取(pull)数据,而非等待被监控端的推送(push)
两个获取方式各有优劣,其中,Pull模型的优势在于:
①集中控制:有利于将配置集在Prometheus server上完成,包括指标及采取速率等
②Prometheus的根本目标在于收集在rarget上预先完成聚合的聚合型数据,而非一款由事件驱动的存储系统。
③通过targets(标识的是具体的被监控端),比如配置文件中的 targets:['localhost:9090']
六、prometheus生态组件
prometheus生态圈中包含了多个组件,其中部分组件可选
1.Prometheus Server
收集和储存时间序列数据
通过scraping以刮擦的方式去获取数据放入storge(TSDB时序数据库),制定Rules/Alerts:告警规则,service discovery是自动发现需要监控的节点。
2.Client Library
客户端库,目的在于为那些期望原生提供Instrumentation功能的应用程序提供便捷的开发途径。
3.Push Gateway
接收那些通常由短期作业生成的指标数据的网关,并支持由Prometheus Server进行指标拉取操作。
4.Exporters
用于暴露现有应用程序或服务(不支持Instrumentation)的指标给Prometheus Server
而pro内建了数据样本采集器,可以通过配置文件定义,告诉prometheus到那个监控对象中采集指标数据,prometheus 采集过后,会存储在自己内建的TSDB数据库中,提供了promQL 支持查询和过滤操作,同时支持自定义规则来作为告警规则,持续分析一场指标,一旦发生,通知给alerter来发送告警信息,还支持对接外置的UI工具(grafana)来展示数据。
采集、抓取数据是其自身的功能,但一般被抓去的数据一般来自于
export/instrumentation (指标数据暴露器) 来完成的,或者是应用程序自身内建的测量系统(汽车仪表盘之类的,测量、展示)来完成。
5.Alertmanager
由告警规则对接,从Prometheus Server接收到"告警通知"后,通过去重、分组、路由等预处理功能后以高效向用户完成告警信息发送。
6.Data Visualization(Dashboards)
与TSDB对接并且展示数据库中的数据,Prometheus web UI (Prometheus Server内建),及Grafana等。
7.Service Discovery
动态发现待监控的Target,从而完成监控配置的重要组件,在容器化环境中尤为有用;该组件目前由PropetheusServer内建支持。
(1)Exporters介绍
node-exporter组件,因为prometheus抓取数据是通过http的方式调用的,假如抓取的数据是操作系统的资源负载情况,而linux操作系统内核是没有内置任何http协议的,并不支持直接通过http方式进行,所以需要在每个被监控端安装node-exporter,由其向内核中拿取各种状态信息,然后再通过prometheus兼容的指标格式暴露给prometheus。
对于那些未内建Instrumentation,且也不便于自行添加该类组件以暴露指标数据的应用程序来说,常用的办法是于待监控的目标应用程序外部运行一个独立指标暴露程序,该类型的程序即统称为Exporter。
PS:Prometheus站点上提供了大量的Exporter,如果是docker技术跑多个服务就要使用docker-exportes监控系统环境,而docker容器内部服务的监控需要使用cAdvisor容器
(2)alerts(告警)介绍
抓取异常值,异常值并不是说服务器的报警只是根据用户自定义的规则标准,prometheus通过告警机制发现和发送警示。
alter负责:告警只是prometheus基于用户提供的"告警规则"周期计算生成,好的监控可以事先预告报警、并提前处理的功能alter接受服务端发送来的告警指示,基于用户定义的告警路由(route)向告警接收人(receivers)发送告警信息(可由用户定义)
ps:在数据查询,告警规则里面会使用到promQL语句
(3)prometheus server
内建了数据样本采集器,可以通过配置文件定义,告诉Prometheus到哪个监控对象中采集指标数据,prometheus采集过后,会存储在自己内建的TSDB数据库中,提供了promQL,支持查询和过滤操作,同时支持自定义规则来作为告警规则,持续分析一场指标,一旦发生,通知给alter来发送报警信息,还支持对接外置的ui工具(grafana)来展示数据,prometheus自带的web展示图像信息比较简单。
采集、抓取数据是其自身的功能。但一般来自于export/instrumentation(指标数据的暴露)来完成,或者是服务自身的内建的测量系统来完成。
七、prometheus架构
1.prometheus-server
retrieval(获取数据pull/discover),TSDB存储,HTPserver 控制台接口,内建了数据样本采集器,可以通过配置文件定义,告诉prometheus到那个监控对象中采集指标数据,prometheus采集过后,会存储在自己内建的TSDB数据库中(默认为2个月时间)),提供了promQL支持查询和过滤操作,同时支持自定义规则来作为告警规则,持续分析一场指标,一旦发生,通知给alerter来发送告警信息,还支持对接外置的UI工具 (grafana)来展示数据。
2.pushgateway(短期周期任务)
允许短暂和批量作业将其指标暴露给普罗米修斯,由于这些类型的作业可能存在时间不足而被删除,因此他们可以将其指标推送到pushgateway,然后pushgateway将这些指标暴露给Prometheus-server端,主要用于业务数据汇报。
3.exporters(常规任务—守护进程)
专门采集一些web服务,nginx,mysql服务。因为不适合直接通过http的方式采集数据,所以需要通过exporter采集数据(下载mysql_exporter,采集mysql数据指标)cadvisor:docker数据收集工具(docker也有自己内置的监控收集方式)。
exporter和instrumtations,负责专门服务数据的收集然后暴露出来等待promtheus收集。
4.service discovery
原生支持k8s的服务发现,支持consul、DNS等
5.prometheus内置TSDB数据库作为存储
时序数据的储存,promtheus的TSDB数据库默认保存15天,可以自行调整
ps:时间序列数据库(时序数据库)主要用于指处理代表签(按照时间的顺序变化,既时间序列化)的数据,带时间标签的数据也成为时间序列数据,这是一种特殊类型的数据库,一般不会保存长时间的数据(与mysql相比)。
数据保存时间 storge.tsdb.retention=90d参数中修改即可(或启动时间指定)
6.alertmanagr
prometheus可以生成告警信息,但是不能直接提供告警,需要使用一个外置的组件altermanager来进行告警,emailetcd优势在于,收敛、支持静默、去重、可以防止告警信息的轰炸
7.data visualization
prometheus web ui(prometheus-server内建),也可以使用grafana
8.PrmoQL
告警规则编写,通常告警规则的文件指定输出到展示界面(grafana)
9.ui表达式浏览器(调试)
八、prometheus数据模型
1.概述
prometheus仅用键值方式存储时序式的聚合数据,不支持文本信息。
其中的"键"成为指标(metric),通常意味着cpu速率、内存使用率或分区空闲比例等,同一指标可能适配到多个目标或设备、因而使用"标签"作为元数据,从而为metric添加更多的信息描述维度。
prometheus每一份样本数据包含
① 时序列标识:key+lables。
② 当前时间序列的样本值value。
③ 这些标签可以作为过滤器进行指标过滤及聚合运算,如何从上万的数据过滤出关键有限。
的时间序列,同时从有限的时间序列在特定范围的样本那就需要手动编写出时间序列的样本表达式来过滤出需求的样本数据。
2.指标类型
默认都是以双精度浮点型数据(服务端无数据量类型数据)
① counter : 计数器单调递增
② gauge:仪表盘:有起伏特征的
③ histogram:直方图:
在一段时间范围内对数据采样的相关结果,并记入配置的bucket中,他可以存储更多的数据,包括样本值分布在每个bucket的数量,从而prometheus就可以使用内置函数进行计算。
计算样本平均值:以值得综合除以值的数量
计算样本分位值:分位数有助于了解符合特定标准的数据个数,例如评估响应时间超过1秒的请求比例,若超过20%则进行告警等。
④ summary,摘要,histogram的扩展类型,是直接由监控端自行聚合计算出分位数,同时
将计算结果响应给prometheus server的样本采集请求,因而,其分位数计算是由监控端完成。
3.job和实例targets/instance
① job:能够接收prometheus server数据scrape。
② targets 每一个可以被监控的系统,成为targets多个相同的targets的集合(类)称为job
③ instance:实例 与 targets(类似)。
与target相比,instance更趋近于一个具体可以提供监控数据的实例,而targets则更像一个对象、目标性质。
4.prometheusQL
数据查询语言也是时序数据库使用语言,支持两种向量,同时内置提供了一组用于数据处理的函数
① 即时向量:最近以此时间戳上跟踪的数据指标(一个时间点上的数据)。
即时向量选择器:返回0个1个或者多个时间序列上在给定时间戳上的各自的一个样本,
该样本成为即时样本。
② 时间范围向量:指定时间范围内所有时间戳上的数据指标。
范围向量选择器:返回0个1个或多个时间序列上在给定时间范围内的各自的一组样本
(范围向量选择器无法用于绘图)。
九、Prometheus实验
1.环境准备
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
vim /etc/selinux/config
SELINUX=disabled
ntpdate ntp1.aliyun.com 时间同步

2.开启服务
(1)解压安装包
tar zxvf prometheus-2.27.1.linux-amd64.tar.gz -C /usr/local
(2)配置文件解析
默认配置文件
cat prometheus.yml
# my global config
global: //全局组件
每隔多久抓取一次指标,不设置默认1分钟
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
内置告警规则的评估周期
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
对接的altermanager(第三方告警模块)
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files: 告警规则
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
对于指标需要打上的标签,对于PrometheusSQL(查询语句)的标签:比如prometheustarget='values'
# metrics_path defaults to '/metrics' 收集数据的路径
# scheme defaults to 'http'.
static_configs:
对于Prometheus的静态配置监听端口具体数据收集的位置 默认的端口9090
- targets: ['localhost:9090'](3)运行服务查看端口是否开启
直接开启Prometheus
./prometheus
另开一个终端查看9090端口
ss -natp | grep 9090

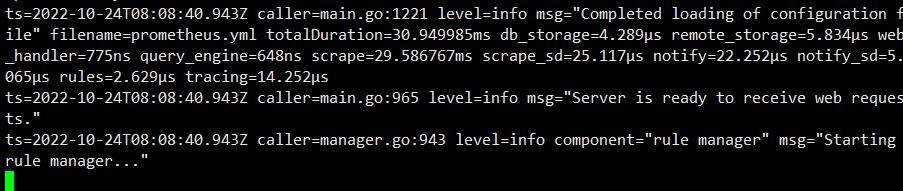
3.访问web页面(表达式浏览器)
(查看表达式浏览器
查看采集数据 Prometheus 会进行周期性的采集数据(完整的),多次周期性(在一个时间区间内)采集的数据集合,形成时间序列。




4.监控其他节点
(1)解压安装包,命令优化路径,设置服务控制,开启服务
tar zxvf node_exporter-1.1.2.linux-amd64.tar.gz
cd node_exporter-1.1.2.linux-amd64
cp node_exporter /usr/local/bin 复制命令让系统可以识别
./node_exporter --help 查看命令可选项
服务开启方式一,使用systemctl控制
[Unit]
Description=node_exporter
Documentation=https:/prometheus.io/
After=network.targets
[serveice]
Type=simple
User=prometheus
ExecStart=/usr/local/bin/node_exporter \\
--collector.ntp \\
--collector.mountstats \\
--collector.systemd \\
--collertor.tcpstat
ExecReload=/bin/kill -HUP $MAINPID
TimeoutStopSec=20s
Restart=always
[Install]
WantedBy=multi-user.target开启服务方法二,直接启动
./node_exporter



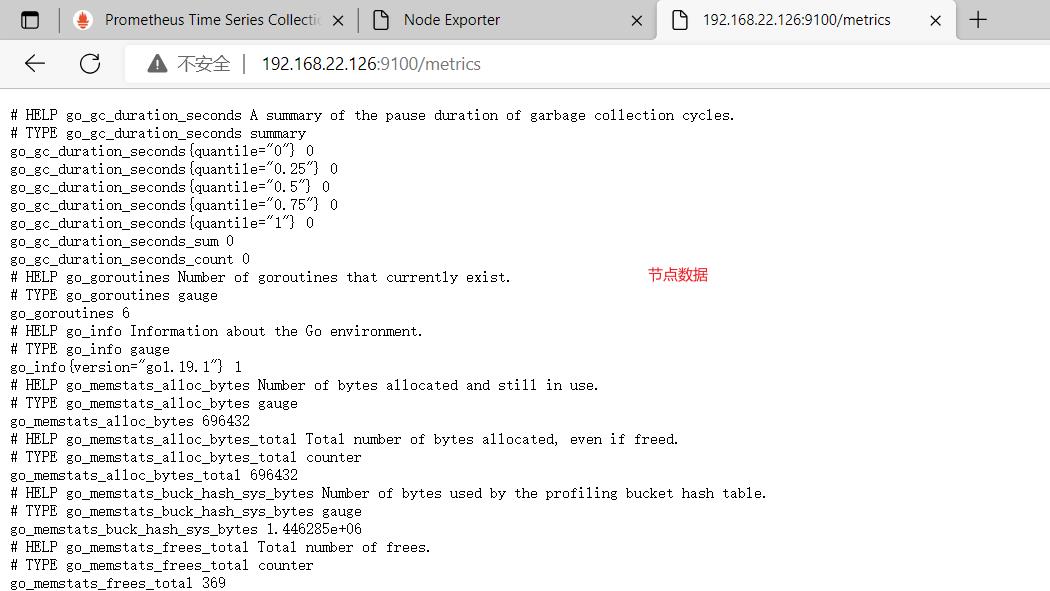
(2)访问
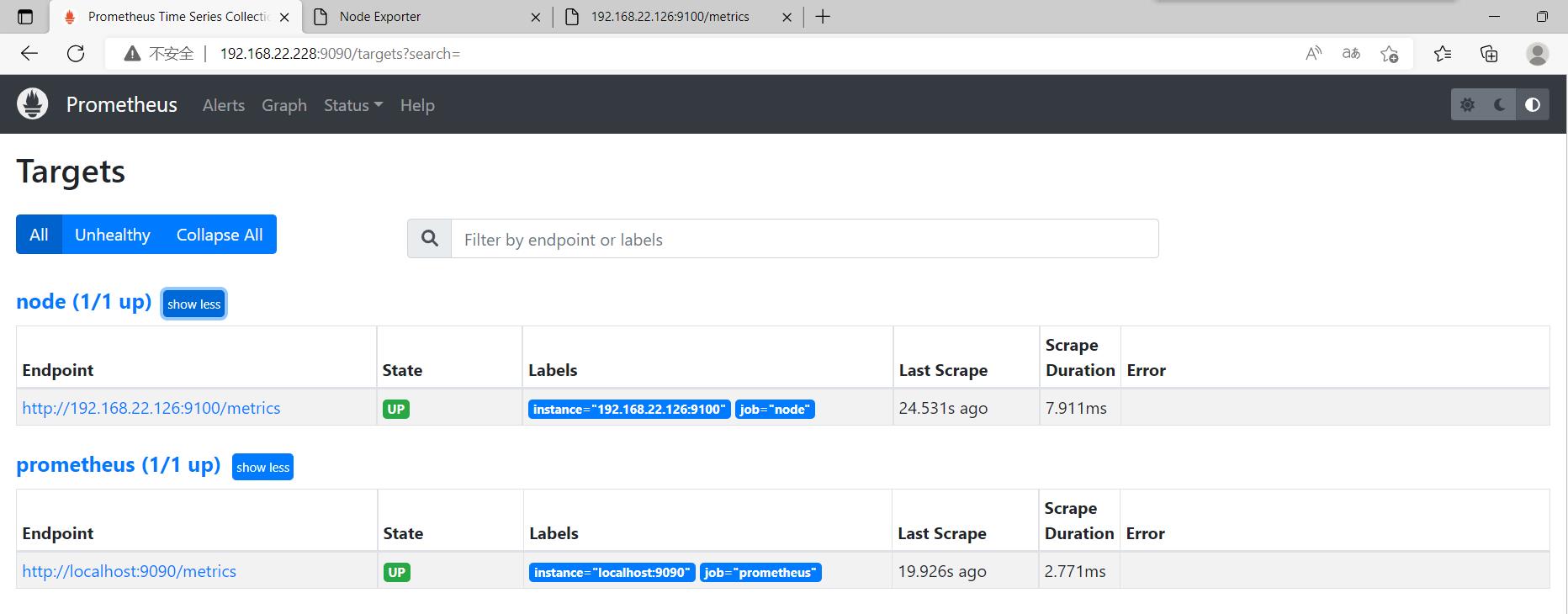
查看抓取内容在这里插入代码片在这里插入代码片
点击→status→targets
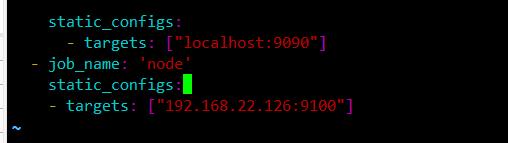
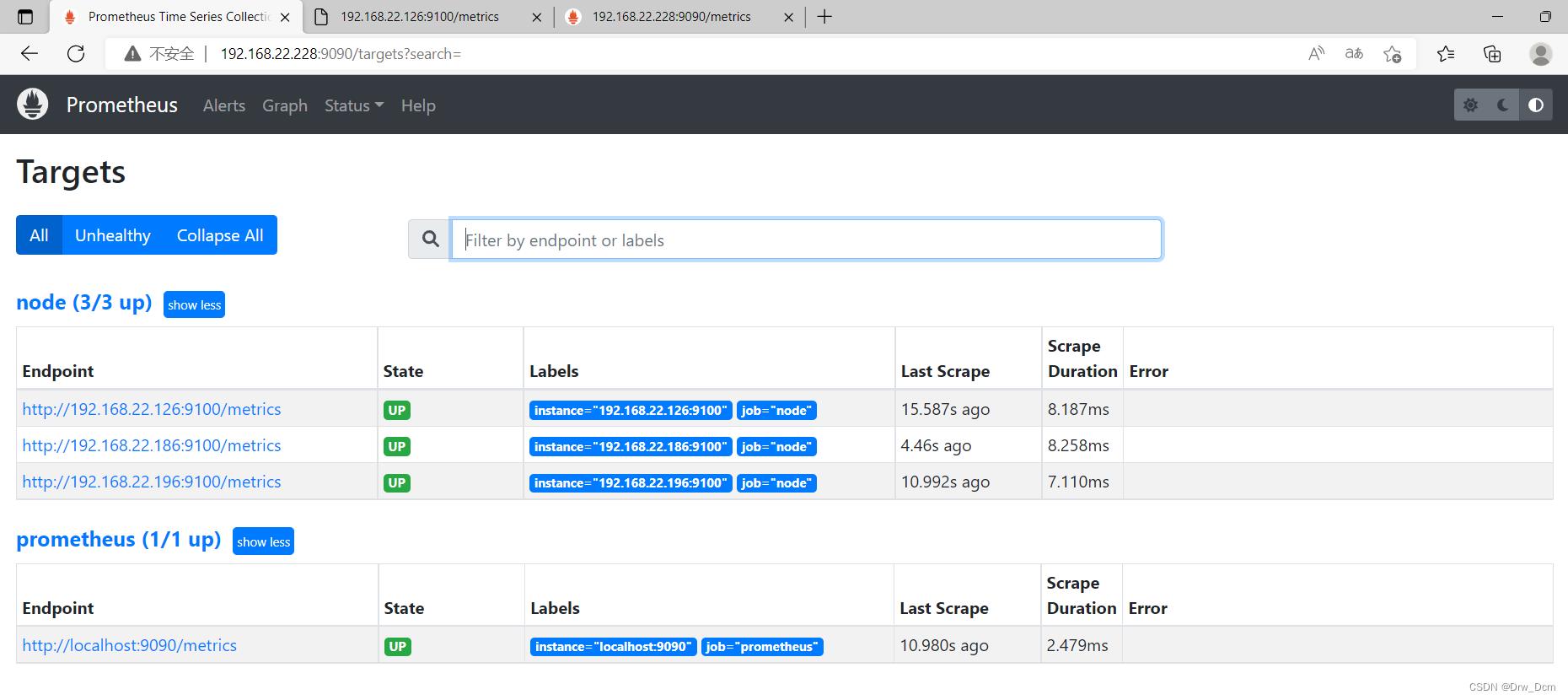
若需要加入其他节点监控端,则需要服务端停止prometheus修改配置文件添加静态targets才能加入其他节点。
netstat -nautp | grep prometheus
killall -9 prometheus
vim /usr/local/prometheus-2.27.1.linux-amd64/prometheus.yml
添加
- job_name: 'nodes'
static_configs:
- targets:
- ip:9100
- ip:9100
- ip:9100
./prometheus






scp /root/node_exporter-1.1.2.linux-amd64 root@ip:/root
scp /root/node_exporter-1.1.2.linux-amd64 root@ip:/root
cd /root/node_exporter-1.1.2.linux-amd64/
./node_exporter
或者优化路径
cp node_exporter /usr/local/bin
./node_exporter
或者放入安装包解压,执行
查看网页






十、表达式浏览器
表达式浏览器常规使用
在prometheusUI控制台上可以进行数据过滤
简单的用法:
CPU使用总量
node_cpu_seconds_total
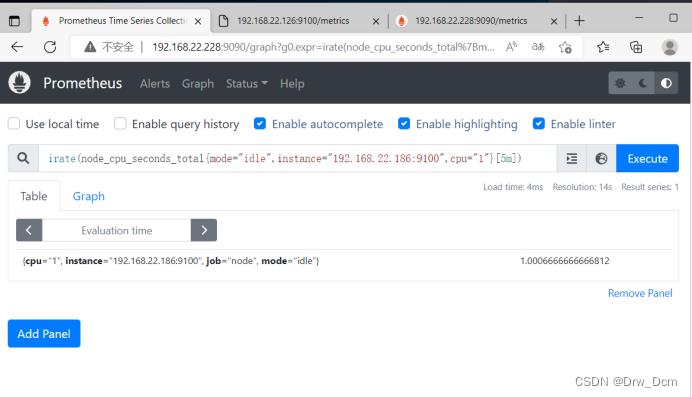
计算过去5分钟内的CPU使用速率(空闲值)
PromQL: irate(node_cpu_seconds_totalmode="idle"[5m])irate:速率计算函数(灵敏度非常高的)
node_cpu_seconds_total:node节点CPU使用总量
mode="idle" 空闲指标
5m:过去的5分钟内,所有CPU空闲数的样本值,每个数值做速率运算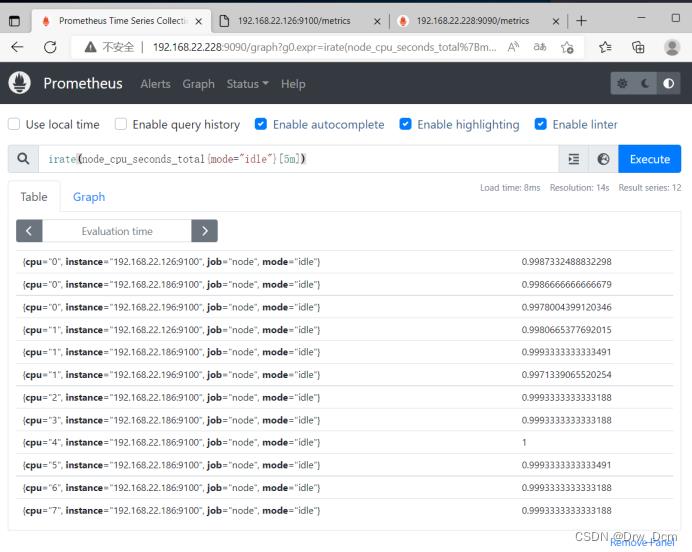
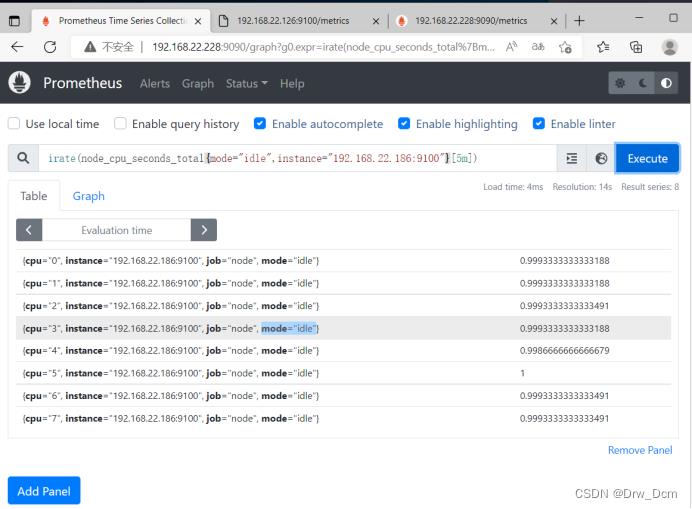
每台主机CPU 在5分钟内的平均使用率
PromQL:(1- avg (irate(node_cpu_seconds_totalmode='idle'[5m]))by (instance))* 100avg:平均值
avg (irate(node_cpu_seconds_totalmode='idle'[5m]):可以理解为CPU空闲量的百分比
by (instance):表示的是所有节点
(1- avg (irate(node_cpu_seconds_totalmode='idle'[5m]))by (instance))* 100:CPU 5分钟内的平均使用率


其他常用的指标
1)查询1分钟平均负载超过主机CPU数量两倍的时间序列
node_load1 > on (instance) 2 * count (node_cpu_seconds_totalmode='idle') by(instance)
2)内存使用率
node_memory_MemTotal_bytes
node_memory_MemFree_bytes
node_memory_Buffers_bytes
node_memory_Cached_bytes
计算使用率:
可用空间:以上后三个指标之和
已用空间:总空间减去可用空间
使用率:已用空间除以总空间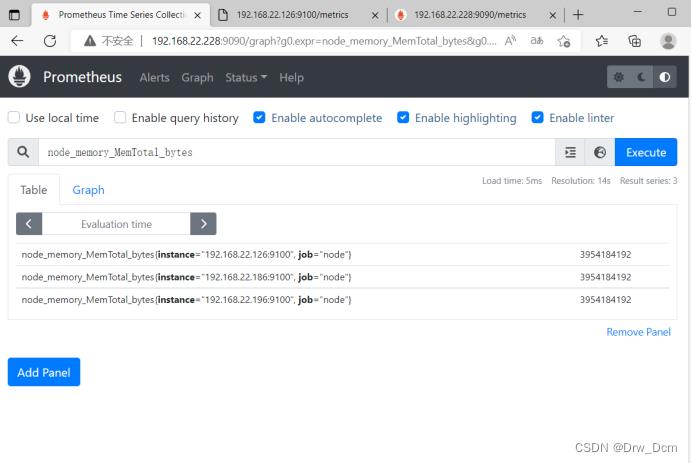

十一、service discovery服务发现
1.相关概念
Prometheus指标抓取的生命周期
发现→配置→relabel→指标数据抓取→metrics relabel
Prometheus的服务发现
① 基于文件的服务发现;
② 基于DNS的服务发现;
③ 基于API的服务发现:Kubernetes、Consul、Azure、重新标记
target重新打标
metric重新打标
④ 基于其他的服务发现
2.prometheus 服务发现机制
① Prometheus Server的数据抓取工作于Pull模型,因而,必须要事先知道各Target
的位置,然后才能从相应的Exporter或Instrumentation中抓取数据。
② 对于小型的系统环境来说,通过static_configs指定各Target便能解决问题,这也是
最简单的配置方法;每个Targets用一个网络端点(ip:port)进行标识
③对于中大型的系统环境或具有较强动态性的云计算环境来说,静态配置显然难以适用;
因此,Prometheus为此专门设计了一组服务发现机制,以便于能够基于服务注册中心(服务总线)自动发现、检测、分类可被监控的各Target,以及更新发生了变动的Target指标抓取的生命周期。
④在每个scrape_interval期间,Prometheus都会检查执行的作业(Job);这些作业首先会根据
Job上指定的发现配置生成target列表,此即服务发现过程;服务发现会返回一个Target列表,其中包含一组称为元数据的标签,这些标签都以" meta_"为前缀
⑤服务发现还会根据目标配置来设置其它标签,这些标签带有"“前缀和后缀,b包括"scheme”
、" address"和" metrics path_",分别保存有target支持使用协议(http或https,默认为
http) 、 target的地址及指标的URI路径(默认为/metrics)
⑥ 若URI路径中存在任何参数,则它们的前缀会设置为" param"这些目标列表和标签会返回给
Prometheus,其中的一些标签也可以配置中被覆盖;
⑦配置标签会在抓取的生命周期中被重复利用以生成其他标签,例如,指标上的instance标
签的默认值就来自于address标签的值;
⑧对于发现的各目标,Prometheus提供了可以重新标记(relabel)目标的机会,它定义在
job配置段的relabel_config配置中,常用于实现如下功能
将来自服务发现的元数据标签中的信息附加到指标的标签上
过滤目标
之后便是数据抓取,以及指标返回的过程,抓取而来的指标在保存之前,还允许用户对
指标重新打标过滤的方式。
它定义在job配置段的metric_relabel_configs配置中,常用于实现如下功能
删除不必要的指标
从指标中删除敏感或者不需要的标签
添加、编辑或者修改指标的标签值或标签格式
3.静态配置发现
修改prometheus服务器上的配置为文件,指定targets的端口上面配置过
- job_name: 'nodes'
static_config:
- targets:
- ip:9100
- ip:9100
- ip:91004.动态发现
基于文件服务发现
基于文件的服务发现仅仅略优于静态配置的服务发现方式,它不依赖于任何平台或第三方服务,因而也是最为简单和通用的实现方式。
prometheus server定期从文件中加载target信息(pro-server pull指标发现机制-job_name 获取我要pull的对象target)文件可以只用json和yaml格式,它含有定义的target列表,以及可选的标签信息;以下第一配置,能够将prometheus默认的静态配置转换为基于文件的服务发现时所需的配置;(rometheus会周期性的读取、重载此文件中的配置,从而达到动态发现、更新的操作)
(1)编写Prometheus.yml文件
prometheus服务端
- targets:
- localhost:9090
labels:
app: prometheus
job: prometheus
#node节点
- targets:
- localhost: 9100
labels:
app: node-exporter
job: node①可以由脚本基于CMDB定期查询生成
②注册中心形式(配置中心(⭐⭐配置清单-配置文件模板)调度中心)
③公有云环境一些配置清单模块
④其他
以上文件可有另一个系统生成,例如Puppet、Ansible或saltstack等配置管理系统,也可能是由脚本基于CMDB定期查询生成。
cd /usr/local/prometheus-2.27.1.linux-amd64/
切换到prometheus的工作目录
mkdir file_sd && cd files_sd
mkdir targets
将修改后的prometheus.yml.0上传至该文件夹中,或者直接编写yml文件
cat prometheus.yml.0
mv prometheus.yml.0 prometheus.yml
vim prometheus.yml

(2)只列出与静态Prometheus.yml文件区别的地方
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
file_sd_configs:
- files:
- targets/prometheus_*.yaml
refresh_interval: 2m
All nodes
- job_name: 'nodes'
file_sd_configs:
- files:
- targets/nodes_*.yaml
refresh_interval: 2m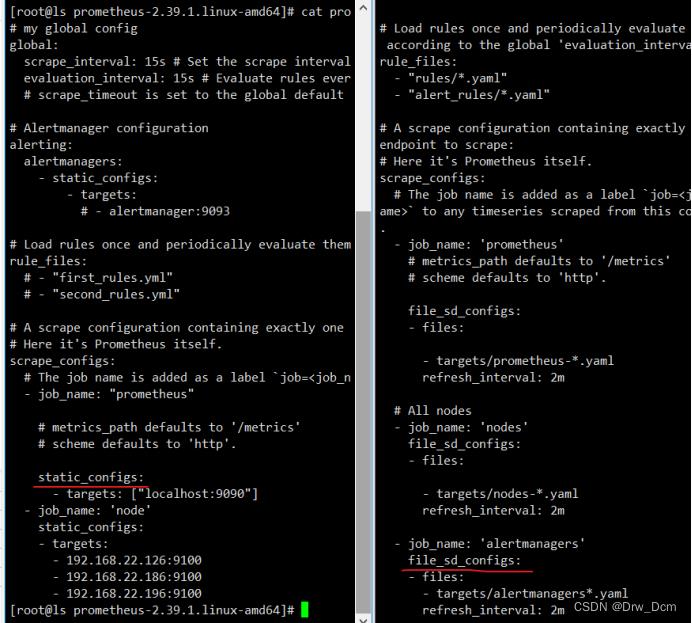
(3)编写prometheus.yml文件发现指定的targets文件
cd targets
ls
nodes_centos.yaml prometheus_server.yaml
或者编写两个yml文件,文件名就是prometheus.yml指定的文件名
vim prometheus_server.yaml
- targets:
- ip:9090
labels:
app: prometheus
job: prometheus
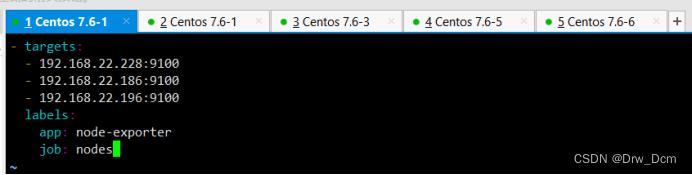
vim nodes_centos.yaml
- targets:
- ip:9100
- ip:9100
- ip:9100
labels:
app: node-exporter
job: node
(4)指定配置文件启动
cd /usr/local/prometheus-2.27.1.linux-amd64
./prometheus --config.file=./file_sd/prometheus.yml(5)注意在node节点开启服务
cd node_exporter-1.1.2.linux-amd64/
./node_exporterkillall prometheus
netstat -nautp | grep prometheus






(6)文件发现的作用
如果增加node或者prometheus服务端节点只需更改nodes_centos.yaml prometheus_server.yaml两个文件添加地址就行,不需要停止服务。
(7)基于DNS自动发现
基于DNS的服务发现针对一组DNS域名进行定期查询,以发现待监控的目标查询时使用的DNS服务器由/etc/resolv.conf文件指定
该发现机制依赖于A、AAAA和SRv资源记录,且仅支持该类方法,尚不支持RFC6763中的高级DNS发现方式。
SRV: SRV记录的作用是指明某域名下提供的服务。
_http._tcp.example.com.SRV 10 5 80. www.example.comSRV
10:优先级,类似MX记录
5:权重
80:端口
www.example.com:实际提供服务的主机名。同时SRV可以指定在端口上对应哪个service
hprometheus 基于Dws的服务中的SRV记录,让prometheus发现指定target上对应的端口对应的是exporter或instrumentation。
(8)基于consul发现
1)相关概念
一款基于golang开发的开源工具,主要面向分布式,服务化的系统提供服务注册、服务一发现和配置管理的功能提供服务注册/发现、健康检查、Key/Value存储、多数据中心和分布式一致性保证等功能。
原理:通过定义json文件将可以进行数据采集的服务注册到consul中,用于自动发现同时使用prometheus做为client端获取consul上注册的服务,从而进行获取数据。
2)安装
unzip consul_1.9.0_linux_amd64.zip -d /usr/local/bin
