Flink实战之StreamingFileSink如何写数据到其它HA的Hadoop集群
Posted scx_white
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink实战之StreamingFileSink如何写数据到其它HA的Hadoop集群相关的知识,希望对你有一定的参考价值。
前言
我们公司使用的集群都是 EMR 集群,于是就分别创建了一个 flink 集群专门用户实时计算,一个 hadoop 集群专门用于 spark、hive 的离线计算。两个集群是完全隔离的。但是有一些实时数据的采集需求,需要把数据写入到我们做离线计算的集群,有人说我只需要在 StreamingFileSink 需要传入的hdfs 路径前加上离线集群的 ip 就好了,比如:hdfs://otherIp:/usr/hive/warehouse/ 这样固然能写入数据,但是我们的hadoop 集群都是 HA 的。namenode 切换的时候会导致写不进去数据,所以此方法不可行。本文主要提供 flink 写入其它 HA 集群的方法和思路
原因查找
如果我们直接通过指定 StreamingFileSink 的写入路径为其它 HA 的 Hadoop 集群时,比如:hdfs://HDFS42143/usr/hive/warehouse/hour_hive ,会出现这样的异常
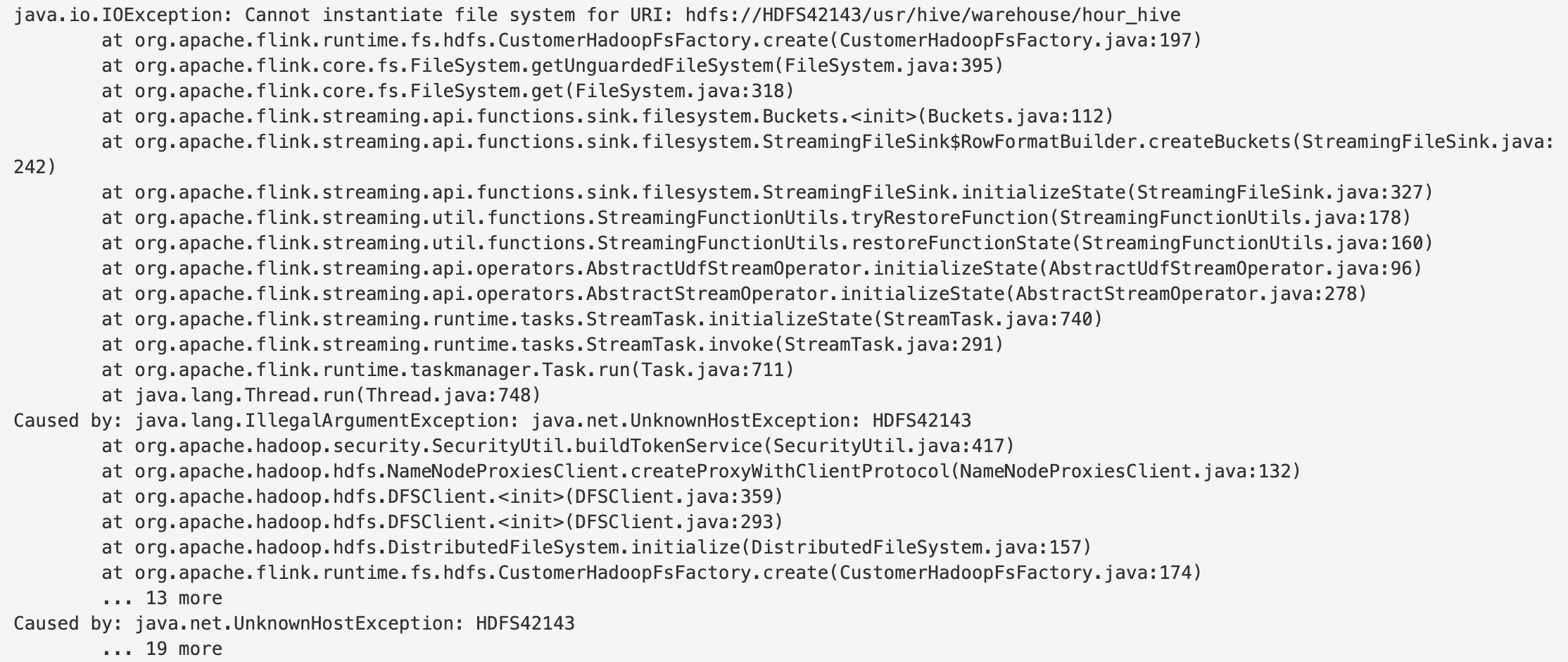
大家都知道我们在创建 HA 集群时,需要指定一个 nameservice,这个 nameservice 可以是你喜欢的符号,然后还需要一些额外的 HA 配置。比如
dfs.client.failover.proxy.provider.HDFS42142=org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.nameservices=HDFS42142
dfs.namenode.rpc-address.HDFS42142.nn1=172.xx.xx.01:port
dfs.namenode.rpc-address.HDFS42142.nn2=172.xx.xx.02:port
dfs.ha.namenodes.HDFS42142=nn1,nn2
可是在 StreamingFileSink源码里面没有找到含有的 hadoop 配置的构造方法。怎么搞呢?我们可以先理解以下StreamingFileSink的写入原理
StreamingFileSink 源码剖析
一般我们创建 StreamingFileSink 都会使用以下方式
package com.tuya.sink;
import com.tuya.AppArgs;
import com.tuya.sink.filesystem.HdfsBucketAssigner;
import com.tuya.sink.filesystem.MyRollingPolicy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.core.fs.Path;
import org.apache.flink.formats.parquet.avro.ParquetAvroWriters;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* desc:
*
* @author scx
* @create 2019/10/24
*/
public class FileSinkFactory
private static final Logger LOG = LoggerFactory.getLogger(FileSinkFactory.class);
/**
* 多久检测一次process状态文件
*/
private static final long CHECK_INTERVAL = 30 * 1000L;
/**
* 默认多久未写入的文件为超时(超时后会生成一个新的文件)
*/
private static final long DEFAULT_INACTIVITY_INTERVAL = 30 * 60L * 1000L;
/**
* 默认多久滚动生成一个hdfs文件
*/
private static final long DEFAULT_ROLLOVER_INTERVAL = 40 * 60L * 1000L;
/**
* hdfs文件最大限制 128M
*/
private static final long DEFAULT_MAX_PART_SIZE = 1024L * 1024L * 128L;
public static <T> StreamingFileSink<T> bulkSink(AppArgs appArgs, Class<T> clazz)
return StreamingFileSink.forBulkFormat(new Path(appArgs.getHdfsPath()),
ParquetAvroWriters.forReflectRecord(clazz))
.withBucketAssigner(new HdfsBucketAssigner<>())
.withBucketCheckInterval(CHECK_INTERVAL)
.build();
public static <T> StreamingFileSink<T> rowSink(AppArgs appArgs, Class<T> clazz)
return StreamingFileSink.forRowFormat(new Path(appArgs.getHdfsPath()),
new SimpleStringEncoder<T>())
.withBucketAssigner(new HdfsBucketAssigner<>())
.withRollingPolicy(new MyRollingPolicy<>(appArgs, DEFAULT_MAX_PART_SIZE, DEFAULT_ROLLOVER_INTERVAL, DEFAULT_INACTIVITY_INTERVAL))
.withBucketCheckInterval(CHECK_INTERVAL)
.build();
为了处理无界的流数据,
StreamingFileSink会将数据写入到桶中。如何分桶是可以配置的,比如我配置的就是自定义的HdfsBucketAssigner,是根据数据的事件时间写入到不同的桶中。
默认策略是基于时间的分桶,这种策略每个小时创建并写入一个新的桶,从而得到流数据在特定时间间隔内接收记录所对应的文件。
桶目录中包含多个实际输出数据的部分文件(part file),对于每一个接收桶数据的Sink Subtask,至少存在一个部分文件(part file)。额外的部分文件(part file)将根据滚动策略创建,滚动策略是可以配置的,比如我配置的就是MyRollingPolicy。默认的策略是根据文件大小和超时时间来滚动文件。超时时间指打开文件的最长持续时间,以及文件关闭前的最长非活动时间。
StreamingFileSink.forBulkFormat 和 StreamingFileSink.forRowFormat 分别表示行编码格式和块编码格式的写入。由于我使用的是行编码格式并且两者内部获取 hdfs 的 filesyStem 逻辑基本一致,就从 StreamingFileSink.forRowFormat 为入口分析。
在 StreamingFileSink 源码中重写了 initializeState 方法,该方法会在程序启动的时候调用一次
@Override
public void initializeState(FunctionInitializationContext context) throws Exception
final int subtaskIndex = getRuntimeContext().getIndexOfThisSubtask();
this.buckets = bucketsBuilder.createBuckets(subtaskIndex);
final OperatorStateStore stateStore = context.getOperatorStateStore();
bucketStates = stateStore.getListState(BUCKET_STATE_DESC);
maxPartCountersState = stateStore.getUnionListState(MAX_PART_COUNTER_STATE_DESC);
if (context.isRestored())
buckets.initializeState(bucketStates, maxPartCountersState);
主要查看 这一行 this.buckets = bucketsBuilder.createBuckets(subtaskIndex) 使用bucketsBuilder根据task下表创建所有 bucket 的管理者 buckets
BucketsBuilder 有两个实现类,分别是BulkFormatBuilder、RowFormatBuilder.
查看RowFormatBuilder实现类
@PublicEvolving
public static class RowFormatBuilder<IN, BucketID> extends StreamingFileSink.BucketsBuilder<IN, BucketID>
//省略部分代码
@Override
Buckets<IN, BucketID> createBuckets(int subtaskIndex) throws IOException
return new Buckets<>(
basePath,
bucketAssigner,
bucketFactory,
new RowWisePartWriter.Factory<>(encoder),
rollingPolicy,
subtaskIndex);
createBuckets 方法会返回一个 Buckets 对象,继续进入 Buckets 构造方法内
Buckets(
final Path basePath,
final BucketAssigner<IN, BucketID> bucketAssigner,
final BucketFactory<IN, BucketID> bucketFactory,
final PartFileWriter.PartFileFactory<IN, BucketID> partFileWriterFactory,
final RollingPolicy<IN, BucketID> rollingPolicy,
final int subtaskIndex) throws IOException
this.basePath = Preconditions.checkNotNull(basePath);
//省略部分代码
try
this.fsWriter = FileSystem.get(basePath.toUri()).createRecoverableWriter();
catch (IOException e)
LOG.error("Unable to create filesystem for path: ", basePath);
throw e;
//省略部分代码
在这里我们终于看到熟悉的 FileSystem 了,FileSystem.get(basePath.toUri()) 通过我们传入的 basePath 路径来获得一个 FileSystem,点进去
/**
* Returns a reference to the @link FileSystem instance for accessing the
* file system identified by the given @link URI.
*
* @param uri
* the @link URI identifying the file system
* @return a reference to the @link FileSystem instance for accessing the file system identified by the given
* @link URI.
* @throws IOException
* thrown if a reference to the file system instance could not be obtained
*/
public static FileSystem get(URI uri) throws IOException
return FileSystemSafetyNet.wrapWithSafetyNetWhenActivated(getUnguardedFileSystem(uri));
FileSystemSafetyNet.wrapWithSafetyNetWhenActivated 方法封装了FileSystem 来防止未关闭流而导致的资源泄漏问题,不是我们观察的重点,进入getUnguardedFileSystem 方法。
public static FileSystem getUnguardedFileSystem(final URI fsUri) throws IOException
checkNotNull(fsUri, "file system URI");
LOCK.lock();
try
final URI uri;
//判断我们的写入的路径有没有传入scheme,即:hdfs://,file://等前缀
if (fsUri.getScheme() != null)
//如果传入了scheme直接赋值给uri
uri = fsUri;
//省略部分代码
final FSKey key = new FSKey(uri.getScheme(), uri.getAuthority());
// 先检查缓存
FileSystem cached = CACHE.get(key);
if (cached != null)
return cached;
//如果FS_FACTORIES为空进行一下初始化加载
if (FS_FACTORIES.isEmpty())
initialize(new Configuration());
final FileSystem fs;
final FileSystemFactory factory = FS_FACTORIES.get(uri.getScheme());
//如果fileSystem工厂存在,创建fileSystem
if (factory != null)
fs = factory.create(uri);
else
try
//不存在使用失败重试的factory进行创建fileSystem
fs = FALLBACK_FACTORY.create(uri);
catch (UnsupportedFileSystemSchemeException e)
throw new UnsupportedFileSystemSchemeException(
"Could not find a file system implementation for scheme '" + uri.getScheme() +
"'. The scheme is not directly supported by Flink and no Hadoop file " +
"system to support this scheme could be loaded.", e);
CACHE.put(key, fs);
return fs;
finally
LOCK.unlock();
上面代码简单进行了注释,首先判断fsUri 的 schema 是否存在,如果不存在或进行一些默认操作。我们配置的是hdfs://HDFS42143/usr/hive/warehouse/hour_hive ,scheme 为 hdfs,然后先检查缓存是否已经存在,存在的话直接返回。不存在的话判断 FS_FACTORIES 中是否存在,如果继续不存在就使用默认的FALLBACK_FACTORY 工厂创建 filesystem 。这里主要看 initialize 方法
public static void initialize(Configuration config) throws IOException, IllegalConfigurationException
LOCK.lock();
try
//省略部分代码
for (FileSystemFactory factory : RAW_FACTORIES)
factory.configure(config);
String scheme = factory.getScheme();
FileSystemFactory fsf = ConnectionLimitingFactory.decorateIfLimited(factory, scheme, config);
FS_FACTORIES.put(scheme, fsf);
// configure the default (fallback) factory
FALLBACK_FACTORY.configure(config);
//省略部分代码
finally
LOCK.unlock();
在 initialize 方法里我们可以看到遍历 RAW_FACTORIES 集合,首先调用configure 方法加载配置,然后把该集合内的 FileSystemFactory 实例以其所支持的 schema 为 key,本身对象为 value 放到FS_FACTORIES 的 map 中,下面还对 FALLBACK_FACTORY 进行了 configure 配置加载。需要注意的是initialize方法会在很多地方被调用,比如jobManager、taskManager启动的时候。
看到这里有两个疑问,RAW_FACTORIES 和 FALLBACK_FACTORY 分别是在哪里创建的
首先看 RAW_FACTORIES
/** All available file system factories. */
private static final List<FileSystemFactory> RAW_FACTORIES = loadFileSystems();
private static List<FileSystemFactory> loadFileSystems()
final ArrayList<FileSystemFactory> list = new ArrayList<>();
list.add(new LocalFileSystemFactory());
LOG.debug("Loading extension file systems via services");
try
ServiceLoader<FileSystemFactory> serviceLoader = ServiceLoader.load(FileSystemFactory.class);
Iterator<FileSystemFactory> iter = serviceLoader.iterator();
while (iter.hasNext())
try
FileSystemFactory factory = iter.next();
list.add(factory);
LOG.debug("Added file system :", factory.getScheme(), factory.getClass().getName());
catch (Throwable t)
ExceptionUtils.rethrowIfFatalErrorOrOOM(t);
LOG.error("Failed to load a file system via services", t);
catch (Throwable t)
ExceptionUtils.rethrowIfFatalErrorOrOOM(t);
LOG.error("Failed to load additional file systems via services", t);
return Collections.unmodifiableList(list);
RAW_FACTORIES 是创建的静态变量,然后从静态方法 loadFileSystems 加载。需要注意的是,loadFileSystems 方法中首先会加一个默认的 factory 即LocalFileSystemFactory。然后其它的 factory使用ServiceLoader.load(FileSystemFactory.class) 通过 SPI 获取,但是我并没有发现Flink源码在 src/main/resources/META-INF/services/org.apache.flink.core.fs.FileSystemFactory 目录下配置FileSystemFactory的实现类,也就是说这些需要我们自己配置,如果不配置,那么默认情况下 SPI 获得的 FileSystemFactory 是为空的。也就是说RAW_FACTORIES 只有一个 LocalFileSystemFactory 实例。而LocalFileSystemFactory 的 scheme 为 file。
然后看 FALLBACK_FACTORY
private static final FileSystemFactory FALLBACK_FACTORY = loadHadoopFsFactory();
private static FileSystemFactory loadHadoopFsFactory()
final ClassLoader cl = FileSystem.class.getClassLoader();
// first, see if the Flink runtime classes are available
final Class<? extends FileSystemFactory> factoryClass;
try
factoryClass = Class
.forName("org.apache.flink.runtime.fs.hdfs.HadoopFsFactory", false, cl)
.asSubclass(FileSystemFactory.class);
catch (ClassNotFoundException e)
LOG.info("No Flink runtime dependency present. " +
"The extended set of supported File Systems via Hadoop is not available.");
return new UnsupportedSchemeFactory("Flink runtime classes missing in classpath/dependencies.");
catch (Exception | LinkageError e)
LOG.warn("Flink's Hadoop file system factory could not be loaded", e);
return new UnsupportedSchemeFactory("Flink's Hadoop file system factory could not be loaded", e);
// check (for eager and better exception messages) if the Hadoop classes are available here
try
Class.forName("org.apache.hadoop.conf.Configuration", false, cl);
Class.forName("org.apache.hadoop.fs.FileSystem", false, cl);
catch (ClassNotFoundException e)
LOG.info("Hadoop is not in the classpath/dependencies. " +
"The extended set of supported File Systems via Hadoop is not available.");
return new UnsupportedSchemeFactory("Hadoop is not in the classpath/dependencies.");
// Create the factory.
try
return factoryClass.newInstance();
catch (Exception | LinkageError e)
LOG.warn("Flink's Hadoop file system factory could not be created", e);
return new UnsupportedSchemeFactory("Flink's Hadoop file system factory could not be created", e);
这里就很简单了,直接通过反射的方式新建 org.apache.flink.runtime.fs.hdfs.HadoopFsFactory 实例,也就是说 FALLBACK_FACTORY 的值为 HadoopFsFactory,scheme 为 *
到这里我们先总结一下
- 我们的
HA集群的路径为hdfs://HDFS42143/usr/hive/warehouse/hour_hive,scheme为hdfs - 我们对
HA集群的CRUD操作的FileSystem是在FileSystem.getUnguardedFileSystem方法中获得的 RAW_FACTORIES集合内的factory都是通过JavaSPI的方式加载的,并且只有一个实例LocalFileSystemFactory,支持的scheme为fileFALLBACK_FACTORY的值为HadoopFsFactory,支持的scheme为*
我们的 HA 集群就是使用 FALLBACK_FACTORY创建的 fileSystem。在上面的 initialize(Configuration config) 方法中会执行 FALLBACK_FACTORY.configure(config);
进入 HadoopFsFactory
public class HadoopFsFactory implements FileSystemFactory
private static final Logger LOG = LoggerFactory.getLogger(HadoopFsFactory.class);
/** Flink's configuration object. */
private Configuration flinkConfig;
/** Hadoop's configuration for the file systems. */
private org.apache.hadoop.conf.Configuration hadoopConfig;
@Override
public String getScheme()
// the hadoop factory creates various schemes
return "*";
@Override
public void configure(Configuration config)
flinkConfig = config;
hadoopConfig = null; // reset the Hadoop Config
@Override
public FileSystem create(URI fsUri) throws IOException
checkNotNull(fsUri, "fsUri");
final String scheme = fsUri.getScheme();
checkArgument(scheme != null, "file system has null scheme");
// from here on, we need to handle errors due to missing optional
// dependency classes
try
// -- (1) get the loaded Hadoop config (or fall back to one loaded from the classpath)
final org.apache.hadoop.conf.Configuration hadoopConfig;
if (this.hadoopConfig != null)
hadoopConfig = this.hadoopConfig;
else if (flinkConfig != null)
hadoopConfig = HadoopUtils.getHadoopConfiguration(flinkConfig);
this.hadoopConfig = hadoopConfig;
else
LOG.warn("Hadoop configuration has not been explicitly initialized prior to loading a Hadoop file system."
+ " Using configuration from the classpath.");
hadoopConfig = new org.apache.hadoop.conf.Configuration();
// -- (2) get the Hadoop file system class for that scheme
final Class<? extends org.apache.hadoop.fs.FileSystem> fsClass;
try
fsClass = org.apache.hadoop.fs.FileSystem.getFileSystemClass(scheme, hadoopConfig);
catch (IOException e)
throw new UnsupportedFileSystemSchemeException(
"Hadoop File System abstraction does not support scheme '" + scheme + "'. " +
"Either no file system implementation exists for that scheme, " +
"or the relevant classes are missing from the classpath.", e);
// -- (3) instantiate the Hadoop file system
LOG.debug("Instantiating for file system scheme Hadoop File System ", scheme, fsClass.getName());
final org.apache.hadoop.fs.FileSystem hadoopFs = fsClass.newInstance();
// -- (4) create the proper URI to initialize the file system
final URI initUri;
if (fsUri.getAuthority() != null)
initUri = fsUri;
else
LOG.debug("URI does not specify file system authority, trying to load default authority (fs.defaultFS)");
String configEntry = hadoopConfig.get("fs.defaultFS", null);
if (configEntry == null)
// fs.default.name deprecated as of hadoop 2.2.0 - see
// http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/DeprecatedProperties.html
configEntry =<以上是关于Flink实战之StreamingFileSink如何写数据到其它HA的Hadoop集群的主要内容,如果未能解决你的问题,请参考以下文章