小学生都能看懂的残差网络
Posted 无乎648
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小学生都能看懂的残差网络相关的知识,希望对你有一定的参考价值。
ResNet残差网络
本文适用于初次接触残差网络的小白,只是为了对残差网络有着更好的入门的一篇文章。
问题提出:

所谓深度学习,大部分人都会认为准确率会随着卷积层的增加而增加,但是随着技术的增加,有人开始尝试着用一个56层的卷积来代替20层的卷积,但是实验结果缺发现56层的卷积准确率还要低于20层的卷积,这样的实验结果让人们感到很不解,为什么层数的增加反正还会导致准确率降低呢?
后来通过对深层的卷积研究发现,导致的原因有可能深层的卷积导致了数据过拟合的现象和梯度下降的后果,由于梯度下降导致有些卷积层的参数完全没有任何意义,那么这样的卷积就算是一个随机卷积层了,这样的卷积层效果肯定是很差的。
解决办法
后来有人提出了两种解决办法:
一种是调整求解方法,比如更好的初始化、更好的梯度下降算法等;
另一种是调整模型结构,让模型更易于优化——改变模型结构实际上是改变了error surface的形态。
那么ResNet的作者采用了第二种解决办法,尝试通过改变模型的结构来解决梯度下降的办法,那么为了让更深层的卷积可以有着更好的效果,提出了下图的设计
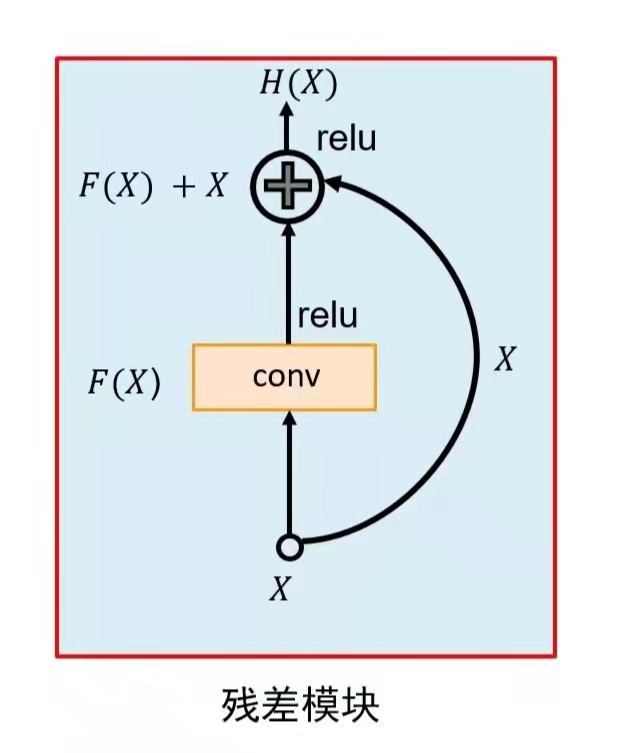
上图按照标准话语来称作残差模块,也就是ResNet的核心技术,
将堆叠的几层layer称之为一个block,对于某个block,其可以拟合的函数为F(x),如果期望的潜在映射为H(x),与其让F(x) 直接学习潜在的映射,不如去学习残差H(x)−x,即F(x):=H(x)−x,这样原本的前向路径上就变成了F(x)+x,用F(x)+x来拟合H(x)。作者认为这样可能更易于优化,因为相比于让F(x)学习成恒等映射,让F(x)学习成0要更加容易——后者通过L2正则就可以轻松实现。这样,对于冗余的block,只需F(x)→0就可以得到恒等映射,性能不减。
按照大白话来说的意思就是,一起每次输入的特征图都是单纯的来着上一次的输出的特征图,之所以梯度下降或爆炸都是因为卷积层都是两两相关,就像是传话一样,第一个人告诉第二个人,之后第二个人理解一下再告诉第三个人,以此类推,直到传到最后一个人的时候,可能跟最初的原话已经大相径庭了,所以ResNet建立另一人传话模式,就是在第二个人告诉第三个人之后,第一个人再告诉一遍第三个人,这样第三个人就收到了第一个人和第二个人两个人的理解的意思了,这样就可以保证最差的效果也是可以知道原话的意思,而且还可以根据前一个人的理解加深理解。

残差网络的作用
残差网络起作用的主要原因就是这些残差块学习恒等函数非常容易,能够保证网络的性能不会收到影响,很多时候甚至可以提高效率,或者说至少不会降低网络效率,因此创建类似残差网络可以提升网络性能。一般卷积神经网络的结构都是几个卷积层后面跟一个池化层,在网络的最后还有一个或多个全连接层。
这是因为残差网络的每一层输入是上一层和以前的层,这样就保证了再差也是跟以前层一样的,就是上述说的“传话”一样,即使这个人再做的不好,他也可以重复以前层的数据,这样就不会出现偏差了,再深的神经网络都可以实现了,由此看来残差网络其实对深度神经网络有着很大的影响。
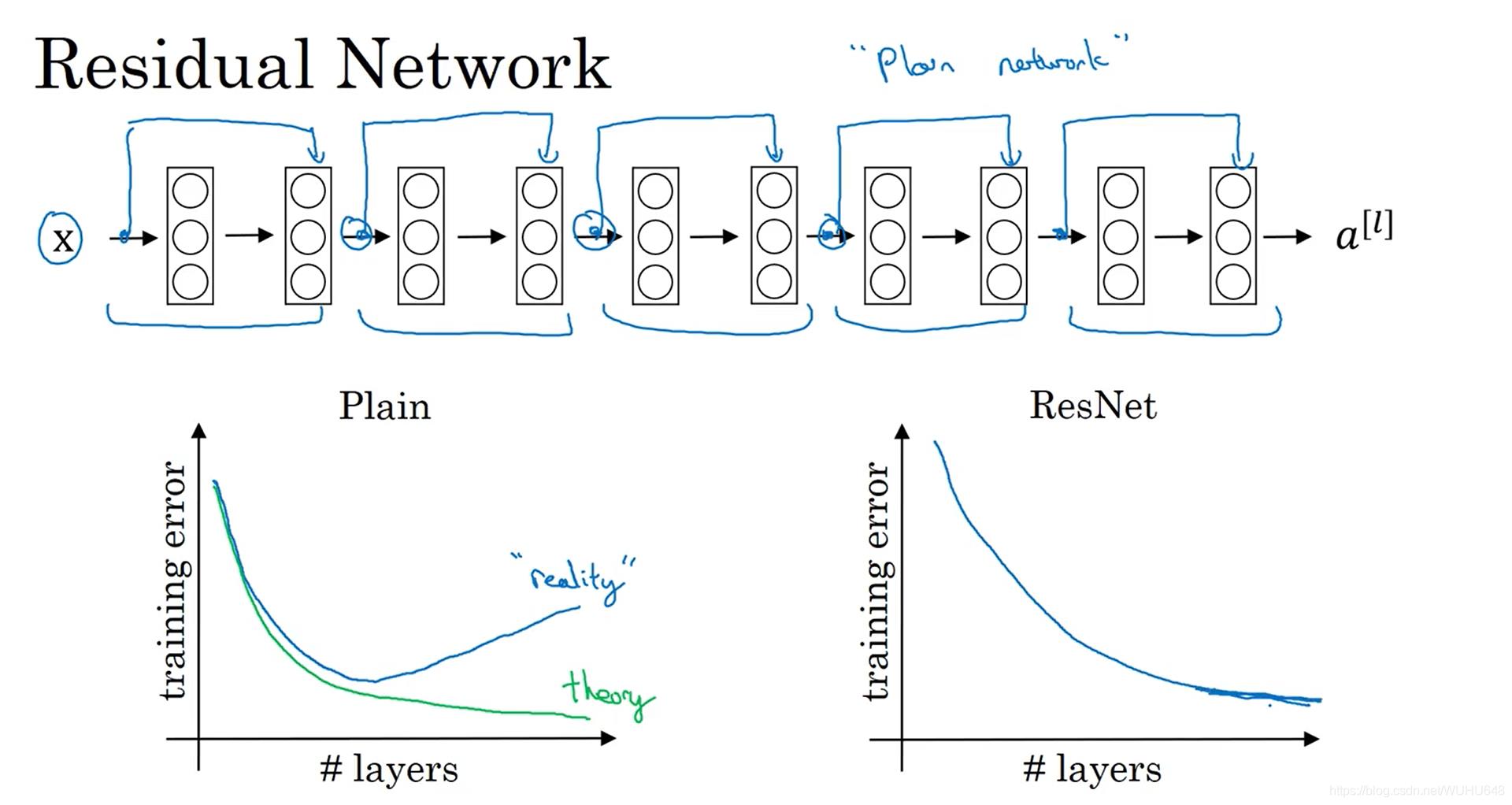
上图左是在没有残差网络之前的错误率会随着层数的增加先减小后增加,图右是有了残差网络之后的错误率会随着层数的增加一直减少。
为了加深理解,我们来看一下下面这张图

可以把原图理解为最初输入特征图,细节是经过卷积处理后逇特征图,这两者通过矩阵相加,就得到了锐化后的特征图,但是如果把细节这张图变成一张全黑的图,也就是没有任何数据,这两者通过矩阵相加,得到的锐化的图其实还是更原图是一个效果,但是这样图并不会因为这个操作而变成还不如原图,这也就是残差网络的最差的一个情况。
结语
通过短短的一篇文章就可以大概对残差网络的概念有了一定的理解,但是这些只是残差的一些概念而已,毕竟像残差网络这么大的成就不可能几句话就讲完,如要是真正学习卷积神经网络的学者们,还是去看一些残差网络的论文或者大佬写的详细教程最为好。
以上是关于小学生都能看懂的残差网络的主要内容,如果未能解决你的问题,请参考以下文章