解读:阿里文娱搜索算法实践与思考
Posted 小爷毛毛(卓寿杰)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解读:阿里文娱搜索算法实践与思考相关的知识,希望对你有一定的参考价值。
参阅 https://mp.weixin.qq.com/s/7hvYdOTnnw5pDDMx6N66Uw
1、搜索算法大图
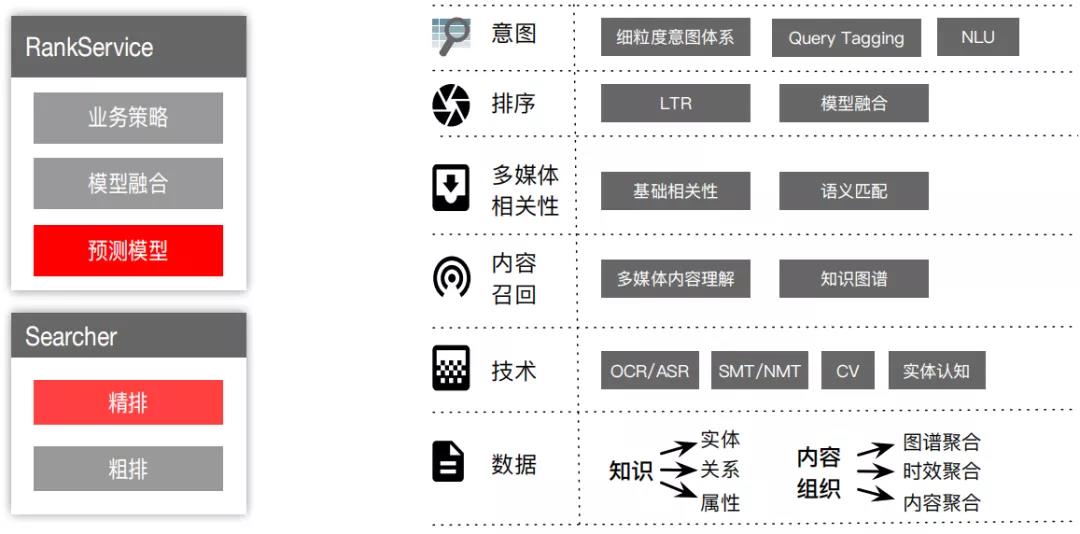
上图中的右图是整个阿里文娱搜索算法的大图,通过这里的介绍作者希望大家对视频搜索技术有一个全貌的理解,方便大家对后面内容的理解。
-
意图
作者这里主要讲了QP服务。QP服务在排序中的作用:首先在意图层面,会把用户意图细粒度的切分出来,对 query 的各个意图做成分分析,比如说 query 是"乡村爱情赵四跳舞",经过 QP 服务的成分分析后,判断乡村爱情属于一个节目名,赵四属于角色,跳舞是一个动作。 -
排序和多媒体相关性
这两个内容后面再详细介绍。 -
内容召回和技术
主要是多媒体内容的理解,为什么要做多媒体内容理解,因为视频内容传递的信息非常丰富,不可能用文本标题全面表述,用户在搜索时表达需求差异非常大,存在语义鸿沟,各个业务的搜索都存在语义鸿沟,视频搜索中的鸿沟更大,所以不能把视频当成黑盒直接用标题概述。我们的问题是从什么维度去理解视频?得益于深度学习在各个领域的全面发展,现在有能力做相关技术,包括 OCR/ASR,对话的理解,通过 CV 的技术对人物、动作、物体的元素级的结构识别,视频的指纹,实体关联,比如某个视频是属于哪个 ip ( 电视剧/电影等 )。基于这些相关技术,不仅仅只是做标题的文本匹配,与相关性匹配密切的关联起来,能更好的帮助理解视频和视频间的关联关系。 -
数据
有实体的关系数据,能够通过技术挖掘这种关系;内容组织,通过图谱聚合、时效聚合、内容聚合,把内容聚合成更方便用户浏览的聚合形态。
2、排序
2.1 搜索相关性
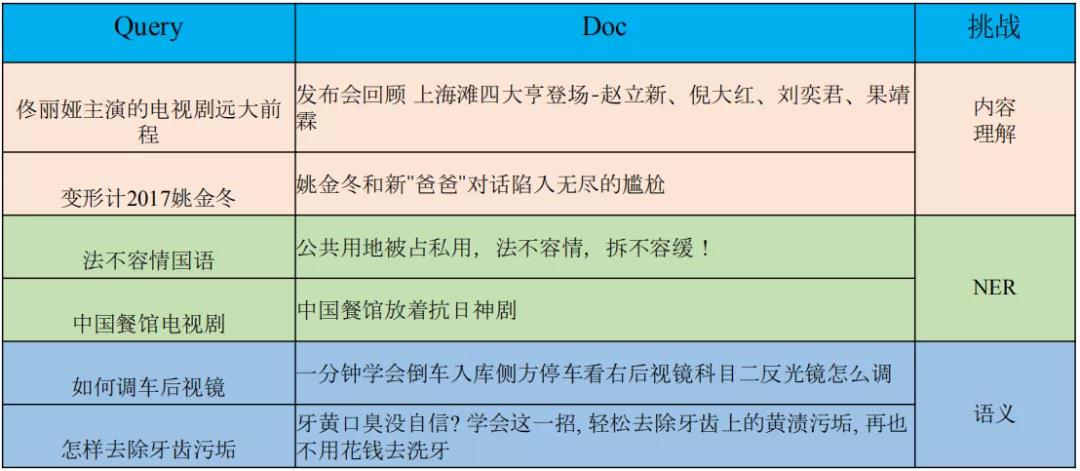
这部分定义到一些具体的 query 和 doc 上,理解能够更全面一些。如上图:
-
第一类 query,"佟丽娅主演的电视剧远大前程"和 doc 在文本上没有直接关系。只有通过内容理解的方式才能把这个 query 和 doc 关联上。
-
第二类 query,"法不容情国语"和对应的 doc 没有关系,要结合 NER 和内容理解的方式才能更准确,对 doc 的意图理解更好。
-
第三类是语义层面的匹配,相关性这一块是需要多个层次的匹配的。
下面分为4个层次详细分析:

- 基础特征。比较通用的是 term weight 和匹配矩阵,通过基础特征能够把文本匹配做的比较好。
- 知识特征。对于知识特征的匹配需要其他辅助信息的补充才能做好的,首先通过内容理解的方式把 UPGC 视频中的一些元数据补充上去,利用 NER 等技术把视频的标题等成分识别准确。在这些基础之上,我们做 query 和 doc 之间的结构化的知识匹配,这块体验能够做的更好。
- 后验特征。包括基于 query 点击的应用判断,知识结合做意图判断,意图和 doc 的匹配,Query_Anchor 是从 doc 维度统计的,哪些 query 是和 doc 是有关系的,能做一些文本的补充和意图补充,这种补充不是纯粹的统计,而是基于浏览模型,比如 UBM 和 DBN 等一些点击浏览的模型,(参阅《基于位置的点击模型》)去消除文本、吸引度的偏差,提高满意度,后面在相关性特征还会详细的去讲一下。
- 语义。主要解决语义匹配,视频搜索存在很大的语义鸿沟,DSSM 表征的 sentence 级别的语义向量去做匹配,这块是会在相关性层面去做。BERT 这一块是做知识蒸馏的方式,这块计算太复杂了,在排序层做的。SMT(机器翻译统计模型)不是在相关性和排序层面去使用的,是语义的扩展和 query 的改写,能丰富语义内容的召回。点击行为也是做一些语义层面的改写扩展。
2.2 相关性数据集构建和特征体系
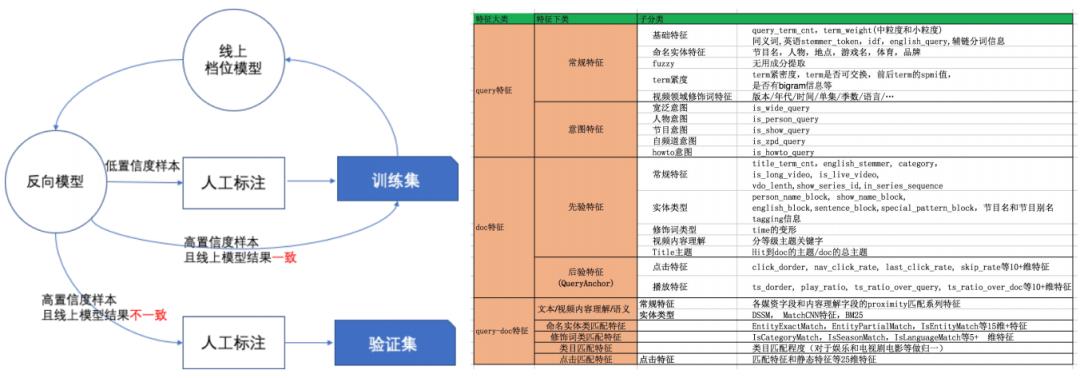
左图是相关数据集的构建流程,方式是采用 active learning 的思想去提升标注效率和质量,降低标注的成本。右图是相关性算法的主要特征(太模糊了。。。)
2.3 语义匹配
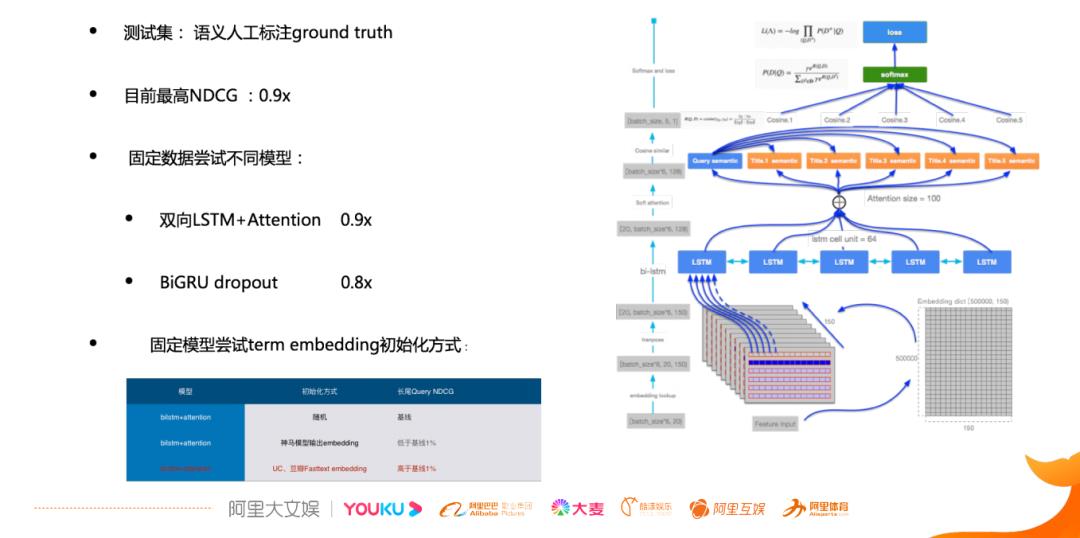
阿里文娱上线了一个 sentence 级别的语义匹配模型
上图比较模糊,我理解模型结构就是把doc拆成sentence粒度的,做向量表示。再把sentence顺序的送入LSTM,每步的输出结果向量相加,得到doc的向量表示。
该模型比较简单,有一个好处是,doc 端的特征是可以离线计算的,可以在相关性层面快速高效的去做语义上的计算,确保基本的语义内容能够被召回,能够排到前面去,能够送到上层的重排序服务上。
2.4 排序特征体系

排序特征体系,包括各个业务领域类的,基础匹配类的,query 统计类的。有一些是视频平台特有的,比如说实时的动态的处于宣发周期的一些特征,对控制节目的排序,可播性,宣发的效果是特别有帮助的;另外,内容质量的评估对视频平台是非常重要的,优酷的人工智能部有一个非常给力的 CV 团队,提供基于视频这种无参考质量的评价框架,能够对低层次的一些特征,比如对比度,亮度,中等的模糊块效应的失真,并综合各种画面质量去解决 UPGC 视频失真,模糊质量评价的难点,能够从视觉层面去理解视频,还有封面图/标题的质量去评判,可以很好的区分好视频和差视频。
在用户层面,用户行为的表征在很多宽泛搜索里都会应用,比如用户在频道页的搜索排序,OGC(Occupationally-generated Content,品牌生产内容)节目宽泛意图的检索场面,用的会比较多。因为在很多通用的搜索中,这种宽泛意图的比率比较大。
2.5 表征学习
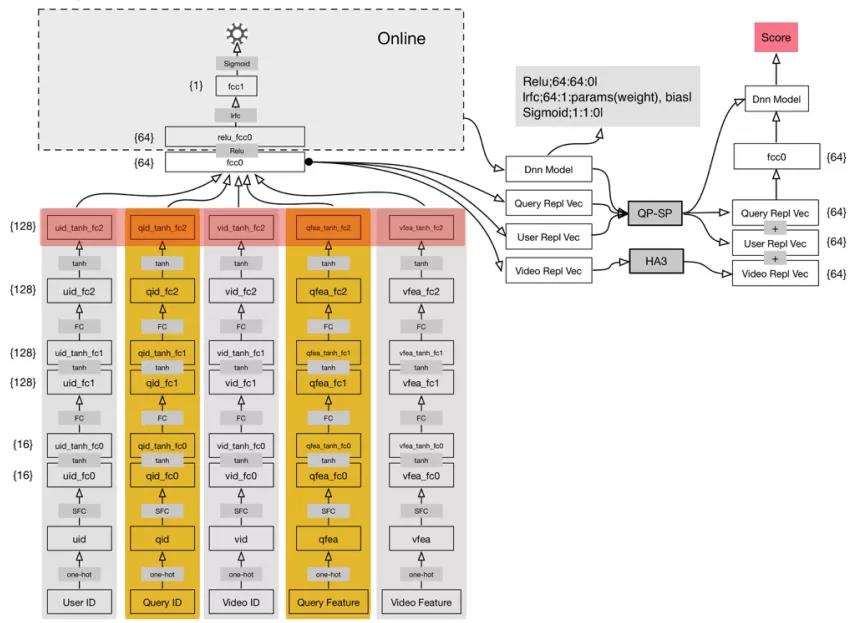
阿里文娱和达摩院一起把表征学习在视频搜索落地的方案。
上图是表征学习的模型,第一层是特征预编码的编码层,用视频元素、搜索意图、用户,这3类特征去分析。
- 在用户维度,又划分了用户 id 和用户观看视频的序列;
- 在搜索意图维度,有搜索的 id,搜索词的视频表达和文本编码的表达。
- 在视频层,包括视频统计特征、视频播放点击量、视频文本编码、视频在整个 session 期间和其他视频的关系数据,来构建这些不同的特征域。
在第2层和第3层,这2个不同特征域之间的网络结构是相互独立的,通过稀疏的编码优化能够全链接到第1层。可以对高维特征进行降维,把高维特征信息投影到低维的向量空间中。
第4层把不同域的表征信息,内部的编码,综合到一起,形成一个综合的多模态的向量融合,再经过上面的2层的全链接实现搜索用户意图和搜索视频维度的排序。
在上线后同样看到了一些问题:这种单一目标的排序模型,它的优化目标是 ts(观看时长),就会忽略一些基本体验。比如,相关性约束对整个体验来说不一定在提高用户体验,可能在头部的一些效果上,我们行为比较多的一些搜索 query 上体验是提升了,但是中长尾的一些效果上其实是比较难以保证的,所以后面我们也是做了不同的尝试,把表征学习和其它的一些维度的排序效果相融合。
2.6 多目标 Deep LTR
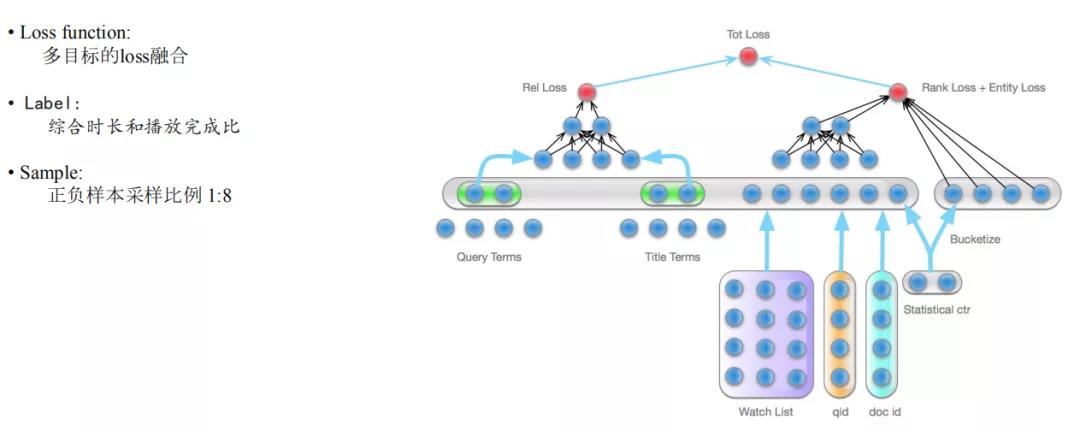
上图为阿里文娱在排序方面的一些实践,多目标的深度排序学习。这里的多目标包括:相关性目标,rank 的 loss,entity loss,即要确保涵盖相关性技术体验的 loss,分发效率的排序 loss,实体匹配上的 loss。
样本标注方面要综合时长和播放完成比,如果我们按照存点击数据,很多情况是和 ts 目标不一致的。如果只考虑视频时长,那么长视频就会被放在前面,如果只考虑播放完成比,那么短视频就会被放在前面,因为短视频就几十秒,很快就能播放完,长视频几十分钟,有的几个小时,不容易看完。所以我们会综合时长和播放完成比,对时长做分段的处理,在相同时长下作横向比较,形成一个不同时长视频的 label 分级,引导目标去学习。
这里正负样本采样比例1:8,是通过不断迭代调整的结果,并没有一个通用的方法。
3. 多模态视频搜索
阿里文娱的多模态视频搜索上实践:视频很长,覆盖的范围很广,用表征的方式不容易覆盖那么多丰富的内容的,所以对工业界的视频搜索,不是端对端的解决方案,现在的做法是将视频模态信息通过降维的方式,都转换成文本的模态,对视频内容做细粒度的内容拆解,将图像,动作,人物,声音这些背景信息,通过 CV 检测方法识别出来,去做标签化,去完成降维。另外一种降维的方式是通过 OCR 和 ASR,光学文本的识别和语音识别的技术将视频中的对话信息转化成文字,关键字和主题的抽取,再去形成事件的分析和概念主题的理解。
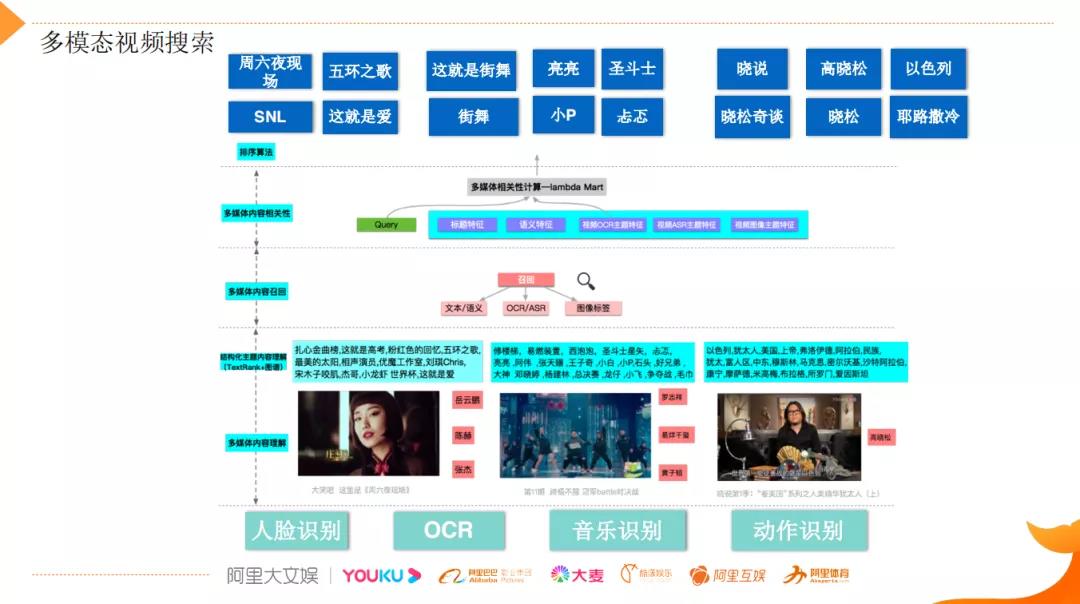
一个完整的视频可以分出不同的片段,然后形成 shot,关键帧,关键元素,通过对关键元素的分析,可以把动作场景人物做一些识别。举个例子,如上图,通过人脸识别可以识别出这个片段中出现了哪些人,"周六夜现场"能检测出岳云鹏,陈赫;"晓说"能检测出高晓松,通过 OCR/ASR 可以把视频中的对话结构化出来,然后做一些关键词的抽取。

如上图,从视频标题看是陶瓷,对文本进行分析理解,在分析理解时,会有一个难点:这么多文字,需要一个完整的实体知识库,但视频内容涉及的领域非常广,包含全行业的丰富的实体。
抽取核心内容的元素,比如"伯特格尔"是谁,是个人物,“塞夫勒”,“麦森"这些地名需要理解,以及实体链接和实体之间的关系的推理。这个视频是介绍欧洲陶瓷发展历史的,欧洲陶瓷是从哪里开始的,是从"塞夫勒"开始,是由"伯特格尔"这个炼金师发现出来的,很多对话内容是通过主体引用,要理解指代的实体,上下文引用的主体是需要识别出来的;另外一个就是实体之间的关系,比如"塞夫勒”、"麦森"是欧洲的城市,和中国,日本是什么关系,这种实体之间的关系是需要有的,否则对讲的什么事情是很难理解的,需要知识图谱辅助。在实体知识库的支撑下,候选的关键字通过分类模型得到关键字分级,分成核心关键词,相关关键词,提及的关键词,分完级之后,在相关性匹配上做的更有针对性。

前面是视频理解的方式,如右图视频标题是李健 -《风吹麦浪》( 春晚歌曲 ),但是他是和孙俪一起唱的,标题里没有孙俪,用户经常搜索的内容是"孙俪李健合唱的风吹麦浪", 需要通过人物识别的方式把视频中的关键人物识别出来。在视频搜索中,需要多模态信息的辅助的,才能提高搜索准确率。左边是"甄缳传",通过视频元素级识别,可以把关键人物识别出来,并且可以把人物和角色,人物和 ip 之间的关系获取出来,检索时可以将具体人物出现的关键位置检索出来,以及台词,歌词,内容关键的一个场景的起止时间,如果用户在搜索"甄子丹的打斗视频",我们有相应的内容视频的聚合数据,用户可以搜到开始打斗的起始时间的。
(这部分感觉只是讲个理念上可行的方案,但是具体什么做没有详细讲,有些虚了 == )
以上是关于解读:阿里文娱搜索算法实践与思考的主要内容,如果未能解决你的问题,请参考以下文章
深度学习核心技术精讲100篇(五十四)-阿里文娱多模态视频分类算法中的特征改进
《阿里算法天才盖坤解读阿里深度学习实践,CTR 预估MLR 模型兴趣分布网络等》