Hadoop——基本概述,初步认识
Posted 保暖大裤衩LeoLee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop——基本概述,初步认识相关的知识,希望对你有一定的参考价值。
参考资料:
Hadoop基本组成
| 组件 | 1.X | 2.X | 3.X |
| Common(辅助工具) | √ | √ | √ |
| HDFS(数据存储、分布式文件系统) | √ | √ | √ |
| Yarn(资源调度) | √ | √ | |
| MapReduce(数据计算处理) | √ | √ | √ |
可以看到2.X与3.X版本的Hadoop从组成上没有太大区别。1.X与其他版本不同的是MapReuce包含了数据计算处理与资源调度。在2.X与3.X中,资源调度与数据计算进行了解耦,作为单独组件Yarn存在。
HDFS
Hadoop Distributed File System,简称HDFS,是一个分布式的文件系统。顾名思义,HDFS的文件分布在集群机器上,同时提供副本进行容错及可靠性保证。例如客户端写入读取文件的直接操作都是分布在集群各个机器上。
HDFS满足master-worker(主从)模式,由NameNode 与 DataNode共同组成。
NameNode
- NameNode(负责管理分布式文件系统的命名空间(Namespace))
- FsImage:维护文件系统树及所有文件、目录的元数据
- EditLog:记录了所有针对文件的创建、删除、重命名等操作
最通俗的理解就是,Name Node是用来告诉别人:数据存在哪个节点上,存了一些什么数据。
注意:为啥会拆成两个呢? 主要是因为fsimage这个文件会很大的,多了之后就不好操作了,就拆分成两个。把后续增量的修改放到EditLog中, 一个FsImage和一个Editlog 进行合并会得到一个新的FsImage。
由于NameNode的负责了重要的文件系统元数据,作为整个集群的引导节点,所以其高可用非常重要,即当NameNode down掉之后,必须有后备方案来接替NameNode的任务。HDFS中充当该替补角色的就是Secondary NameNode。
Secondary NameNode
SNN每隔一段时间会对NameNode进行一次元数据的备份,但其并非完全作为NameNode的热备。
- 辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
- 在紧急情况下,可辅助恢复NameNode
DataNode
DataNode就是实际来存储数据的,并且执行NameNode下发的数据操作指令。除此之外还会进行快数据的校验。
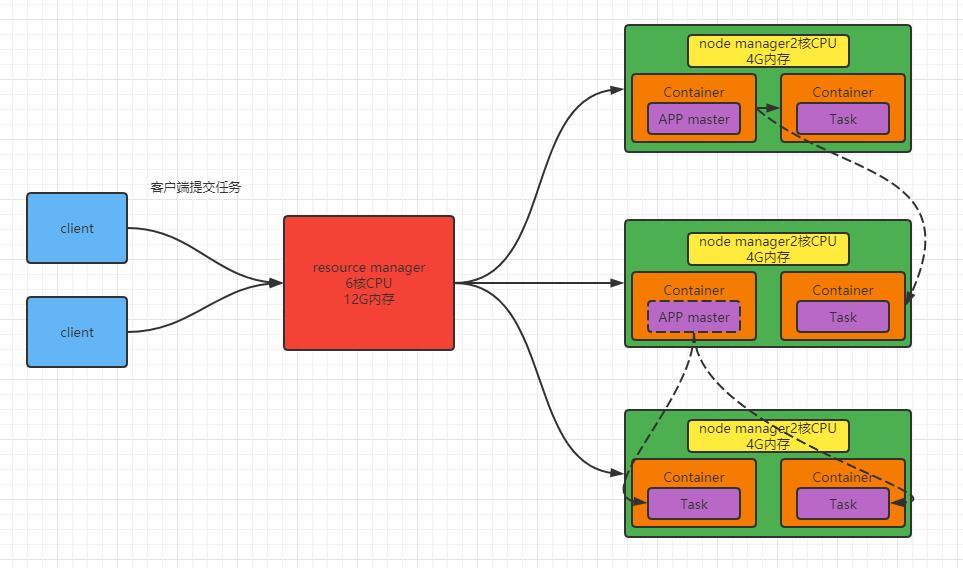
YARN
Yet Another Resource Negotiator简称YARN,另一种资源协调器,是Hadoop的资源管理器。其包含两大部分:Resource Manager和NodeManager。
Resource Manager
整个集群资源的管理者,相当于对所有Node Manager的统一代理。
Node Manager
单个节点的资源管理者。
Container
任务运行容器,相当于一台独立的服务器,有“独立”的资源(内存、CPU、磁盘、网络),这些资源实质上是通过虚拟化技术来虚拟出来的。(默认情况下,一个Container可以分配1G-8G内存,至少一个CPU)
这样做的好处在于,当一个任务运行完成时,运行任务期间占用的资源,在任务运行结束之后可以马上释放。
Application Master
单个任务的管理器。
- 当APP Master需要执行任务的时候,会向Resource Manager申请资源
- 然后在某个Container上使用申请到的资源进行任务的执行。
- 如果当前Node Manager的资源不够运行该任务的时候,则可以跨节点进行资源调度、任务的运行
MapReduce
MapReduce是一个分布式运算程序的框架,负责数据的计算处理。是用户开发基于Hadoop的数据分析应用的核心框架。
MapReduce讲计算分为两个阶段
- Map:并行处理输入数据
- Reduce:对Map结果进行汇总
Map阶段
首先将所有的输入目录里的文件读取到内存当中,分配好对应的MapTask,并按照Map阶段的程序逻辑执行这些任务。每个任务之间是相互独立的。当这些任务执行完毕后,再执行Reduce阶
每个文件的读取次数取决于文件的大小和块(blocker)大小的设置。每个块,会执行一次Map(默认,详细查看 8、MapTask并行机制),而不是每个文件执行一次Map。
Reduce阶段
将Map阶段的输出结果,作为Reduce阶段的输入参数。分配好对应的ReduceTask,并一一执行它们。最终将结果输出到MapReduce程序指定的输出目录当中。
一个MapReduce job只能有一个Map阶段和一个Reduce阶段,如果程序需要多个Map阶段和Reduce阶段,则只能编写多个MapReduce程序,并将它们串行运行。
MapReduce进程
一个完整的MapReduce程序在分布式运行时会有3类实例进程:
- MRAppMaster,负责整个程序运行过程中的资源调度和状态的协调
- MapTask,负责Map阶段的数据处理流程
- ReduceTask,负责Reduce阶段的数据处理流程
暂时写这么多,之后有新的理解再补充...
参考文章:
https://blog.csdn.net/adsl624153/article/details/100059246
以上是关于Hadoop——基本概述,初步认识的主要内容,如果未能解决你的问题,请参考以下文章