[机器学习] Coursera笔记 - 机器学习应用的建议-Part3
Posted WangBo_NLPR
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[机器学习] Coursera笔记 - 机器学习应用的建议-Part3相关的知识,希望对你有一定的参考价值。
序言
机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,包括在线课程或Tutorial的学习笔记,论文资料的阅读笔记,算法代码的调试心得,前沿理论的思考等等,针对不同的内容会开设不同的专栏系列。
机器学习是一个令人激动令人着迷的研究领域,既有美妙的理论公式,又有实用的工程技术,在不断学习和应用机器学习算法的过程中,我愈发的被这个领域所吸引,只恨自己没有早点接触到这个神奇伟大的领域!不过我也觉得自己非常幸运,生活在这个机器学习技术发展如火如荼的时代,并且做着与之相关的工作。
写博客的目的是为了促使自己不断总结经验教训,思考算法原理,加深技术理解,并锻炼自己的表述和写作能力。同时,希望可以通过分享经验帮助新入门的朋友,结识从事相关工作的朋友,也希望得到高人大神的批评指正!
前言
[机器学习] Coursera笔记系列是以我在Coursera上学习Machine Learning(Andrew Ng老师主讲)课程时的笔记资料加以整理推出的。内容涵盖线性回归、逻辑回归、Softmax回归、SVM、神经网络和CNN等等,主要学习资料来自Andrew Ng老师在Coursera的机器学习教程以及UFLDL Tutorial,Stanford CS231n等在线课程和Tutorial,同时也参考了大量网上的相关资料。
本篇博客主要整理自“Advice for Applying Machine Learning”课程的笔记资料,包括假设函数的评估、数据集划分、模型选择问题、偏差和方差,以及机器学习诊断法等方面,涵盖了大量的器学习应用的建议和技巧。
同时,我也会将自己在机器学习算法应用中的经验分享出来,供大家参考。
文章小节安排如下:
1)如何评价一个模型(Evaluating a Hypothesis)
2)欠拟合与过拟合(Underfit and Overfit)
3)模型选择与数据集划分(Model Selection and Train/Validation/Test Sets)
4)如何诊断一个机器学习算法(How to diagnose a algorithm)
5)如何调试一个机器学习算法(How to debug a algorithm)
6)误差分析(Error Analysis)
7)偏斜类问题(Skewed Classes)
8)查全和查准的权衡(Trading Off Precision and Recall)
9)数据的重要性(Importance of Data)
10)最后的总结
这是第三篇,前两篇请参考:
Coursera笔记 - 机器学习应用的建议与方法1
Coursera笔记 - 机器学习应用的建议与方法2
七、偏斜类问题(Skewed Classes)
7.1 什么是偏斜类
在一个数据集中,如果某一类样本数量远远小于另一类样本数量,那么将这种情况称为偏斜类问题。
在偏斜类情况下,一些评价指标会出现严重问题(例如分类误差或分类准确率)。例如,在癌症鉴别任务中,测试集中只有0.5%的患者真正得了癌症,那么如果我们的分类模型得到1%的错误率(看起来还不错),这其实就是有严重问题的,因为我们的误报比实际高出整整两倍。
进一步说,如果我们设计一个算法忽略输入,总是让输出=0(也就是总是预测人没有得癌症),那么在上述测试集中,模型就可以得到0.5%的错误率(非常不错吧?),但这会是毁灭性的、会造成严重诊断失误的0.5%!同时,这并非一个机器学习算法!
因此,准确率或者误报率已经无法正确评价一个存在偏斜类问题的模型。
7.2 如何评价存在偏斜类问题的模型?
基于上一节的举例,我们可以提出如下问题:
假如说你有一个算法,它的精确度是99.2%,误差是0.8%,如果你对算法做出了一点改动,得到了99.5%的精确度,只有0.5%的误差。这到底是不是算法的一个提升呢?
如前所述,如果数据集存在偏斜类问题,那准确率和错误率是白扯了,下面看看哪些是可用的评价指标。
回顾一下前面讲过的图和评价指标定义:
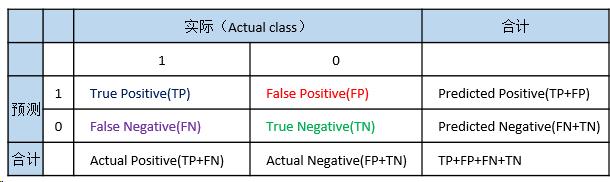
查准率(precision,也称精确度)
Precision(查准率/精确度)= (true positives) / (true positives + false positives)
查全率(recall,也称召回率)
Recall(查全率/召回率) = (true positives) / (true positives + false negatives)
一般来说,使用查准率和查全率可以在偏斜类情况下较好地评价模型的好坏,以前面诊断癌症的例子来说明。
测试数据:
一个癌症特征数据集,其中99.5%是正常的(y=0),0.5%是患癌症的(y=1)
算法设计:
1)设计一个算法,令y恒等于1,即忽略输入值X,总是预测样本是患有癌症的,则,
recall = 100%
precision = 0.5%
accuracy = 0.5%
2)设计一个算法,令y恒等于0,即忽略输入值X,总是预测样本是正常的,则,
recall = 0%
precision = 0%
accuracy = 99.5%
可以看出,利用recall和precision可以很好地处理偏斜类问题,准确评价一个模型的好坏。
7.3 关于偏斜类一点经验
事实上在很多任务中,偏斜类问题都是存在的。我们课题组所从事的涉涉恐涉暴图像/视频识别算法研究,面对的就是严重偏斜的数据集,客户公司每天的数据量成百上千万,而其中的涉恐涉暴样本可能也就几十个最多一两百个,因此对我们的要求就是在保证召回率(查全率)的同时尽量降低虚警率(false alarm)。
拿到这个课题的时候我们也觉得很棘手,但比癌症诊断任务简单的一点是,我们的召回率(查全率)要求没有那么高,但比癌症诊断困难的是,我们的虚警率要求极高(0.01的误检就是上万的样本需要复审)。
面对这样一个严重偏斜的数据分布情况,并且对识别速度有极高的要求,我们在设计算法系统时候采用了层次化识别的思路,类似于Adaboost算法思想(级联分类模型),整个识别系统由一系列分类器组成,每个分类器对负样本(正常图片/视频)的识别准确度比较高,一旦发现样本是负样本(正常的),就不在继续调用后面的分类器,以减少识别时间。与Adaboost主要不同的地方在于,我们级联的每个模型相对来说更加独立,对图片/视频检测角度也各不相同,而且在训练时也是各自独立的。
在一个级联模型的算法系统中,如何选择每个模型是很关键的,对速度、查全查准、互补性等都要做大量实验验证,这样才可以级联得到一个适用的算法系统。
以上供大家参考。
八、查全与查准的权衡(Trading Off Precision and Recall)
8.1 查全与查准不可兼得
首先明确,高查准率与高查全率不可兼得。
从前面的例子也可以看出(极端情况),如果你想要很高的查全率(召回率),那么查准率(精确度)就会很低;反之也是一样。所以在实际任务中必须做出取舍。
幸运的是,在大多数任务中,我们都是可以接受某一项指标较低的,例如我之前提到的涉恐涉暴图像/视频识别任务,客户就可以接受75%左右的查全率,但是会再三叮嘱我们一定要把虚警率降低到0.2%以下,也就是对应99.8%的精确度(precision)。真的是让人扒一层皮的变态要求……
8.2 综合的评价指标
结合查全率(召回率)和查准率(精确度)可以比价好的评价一个模型,可如果想要直观的在两个或多个模型之间进行比较,就会比较麻烦。例如模型A的查全率比较高,模型B的查准率比较高,那到底哪个模型更好一些呢?
F1 Score可以解决这个问题,先回顾下定义:
F1 Score(F1分数) = (2 * precision * recall) / (precision + recall)
F值也叫做F1值(一般写作F1值),取值范围是0~1。它的定义会考虑一部分查准率和召回率的平均值,但是它会给查准率和召回率中较低的值更高的权重,这样便可以突出不足,或者说使算法的不足暴露出来。
F值的分子是查准率和召回率的乘积,因此如果查准率等于0或者召回率等于0,F值也会等于0。对于一个较大的F值,查准率和召回率都必须较大才可以。因此,F1 Score可以反映模型的整体情况。
下面通过表格来看一下F1 Score的神奇功效:
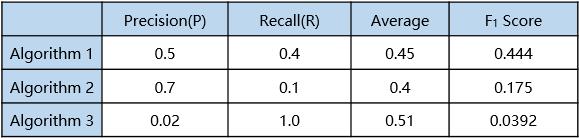
显然,Average是行不通的,而F1 Score可以很好的确定哪一个算法是最优的。
九、数据的重要性(Importance of Data)
是时候祭出那句至理名言了!
It’s not who has the best algorithm that wins. It’s who has the most data.
It’s not who has the best algorithm that wins. It’s who has the most data.
It’s not who has the best algorithm that wins. It’s who has the most data.
恩,重要的事情说三遍!
9.1 数据量对算法性能的影响
我们知道,样本越多(数量和多样)越能反映出样本总体的分布情况,换句话说,我们给算法越多的训练样本,算法就越能学到样本总体的分布,性能就会越好。
Ng老师在课程里给出了不同分类算法在数据量轴上的对比,这里我找到了原图如下:

可以看出,大部分算法都具有相似的性能,随着训练集的增大(从0.1个百万到1000个百万),这些算法的性能也都对应地增强了。因此,我们可以任意选择一个算法,甚至是选择了一个“劣等的”算法,但如果你给这个劣等算法足够多的训练数据,那么它很可能会比其他算法表现更好,甚至会比“优等算法”更好。
事实证明在一定条件下,对于学习算法的性能改善,数据是唯一能实际起到作用的。
9.2 如何利用Large data
提问:我们在什么情况下才能充分利用大数据?
在思考这个问题的时候,我们需要知道,大数据提供了样本数量和样本多样性,可以有效的防止过拟合。因此我们可以确定算法设计的思路:
通过使用一个具有很多参数的学习算法(确保特征值具有足够的信息量),以便能够得到一个较低偏差的算法,再通过使用非常大的训练集来保证算法没有方差问题(确保训练样本的多样性)。这样最终可以得到一个低误差和低方差的学习算法。
9.3 大数据时代算法设计的思路
这个时代最不缺的就是数据,大多数任务中的数据动辄就百万千万上亿,这样的数据规模足以对冲模型潜在的过拟合风险。因此这也改变了我们设计算法的思路:去寻找一个非常复杂的拟合能力非常强的算法,然后适用非常大的数据集来训练它。
深度学习技术,在我看来其实是发现了一个容量很大并且计算速度很快的数据容器,海量的参数带来了极强的拟合能力,同时由于深度网络神奇的层次化结构加上随之而来的各种奇技淫巧,使得算法在海量数据下的训练优化预测的难度大大下降,速度大大提升,于是机器学习迎来了质的飞跃。
至少迄今为止,我们还没有达到深度神经网络算法框架下的拟合能力极限,让我们拭目以待吧!
十、最后的总结
第一,机器学习算法是一项综合的工作,不要只盯着漂亮的数学公式不放,而不愿意去分析具体的样本。想要做好机器学习的工作,算法理论要研究,样本数据也要研究,程序代码也要研究,这些工作没有高低贵贱之分。
第二,必须用证据来引导我们对算法的改进思路。在拿到一个任务时,我们不知道如何选择特征也不知道哪个分类器性能更好,因此最好的实践方法是快速实现一个简单算法,通过交叉验证、学习曲线等手段发现问题所在(高偏差或者高方差或者别的问题),从而得到算法的改进思路。
-
参考资料
Coursera - Machine learning( Andrew Ng)
https://www.coursera.org/learn/machine-learning
以上是关于[机器学习] Coursera笔记 - 机器学习应用的建议-Part3的主要内容,如果未能解决你的问题,请参考以下文章