深度学习系列47:styleGAN总结
Posted IE06
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习系列47:styleGAN总结相关的知识,希望对你有一定的参考价值。
1. styleGAN 1
gan的一个问题是很难生成大尺寸的图片,直到2018年,NVIDIA首次用ProGAN解决了这一挑战。它首先用极低分辨率的图像(如4×4)训练生成器和鉴别器,然后每次增加一个更高分辨率的层。最初的输入向量shape为[512,4,4],最后输出为[3,1024,1024],一共是18层:
18 = 1(初始进入的conv层)+8 * 2(每一个块包含的两个卷积层,将vector从[4,4]变到[1024,1024])+1(to_rgb层,将通道变成3)
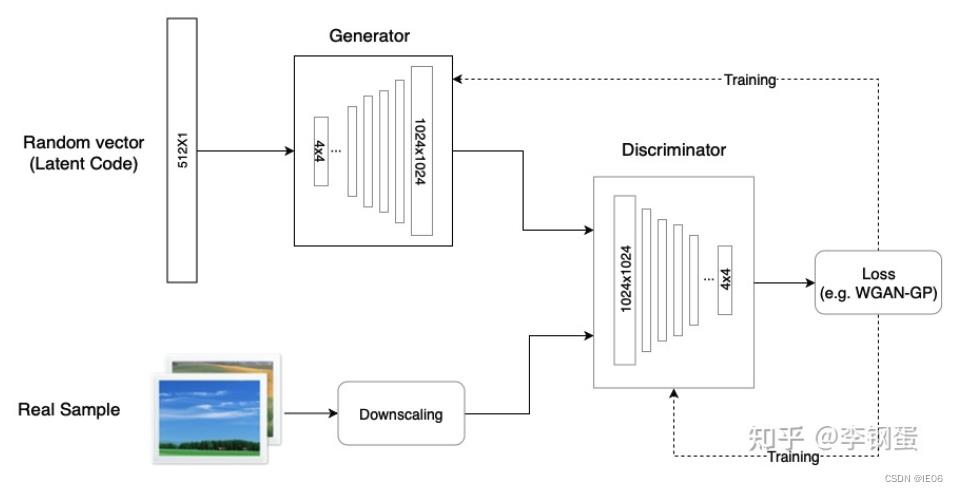
styleGAN是proGAN的升级版:
1)使用8个FC层将输入图片编码为中间向量,类似PCA的转换,将不同的特征(头发、眼睛、鼻子等)进行解耦,否则会出现“特征纠缠”问题,训练数据中某种特征过多会影响其他特征。
2)隐变量w经过A转换后会连接到不同比例的每个层中,用于对每个通道进行缩放、偏移,称为AdaIN模块。这个缩放和偏移存放的是风格信息,不同的值会生成不同的风格。
因为Synthesis network的网络层有18层,所以我们才会说通过w生成得到了18个控制向量,用于控制不同的视觉特征。
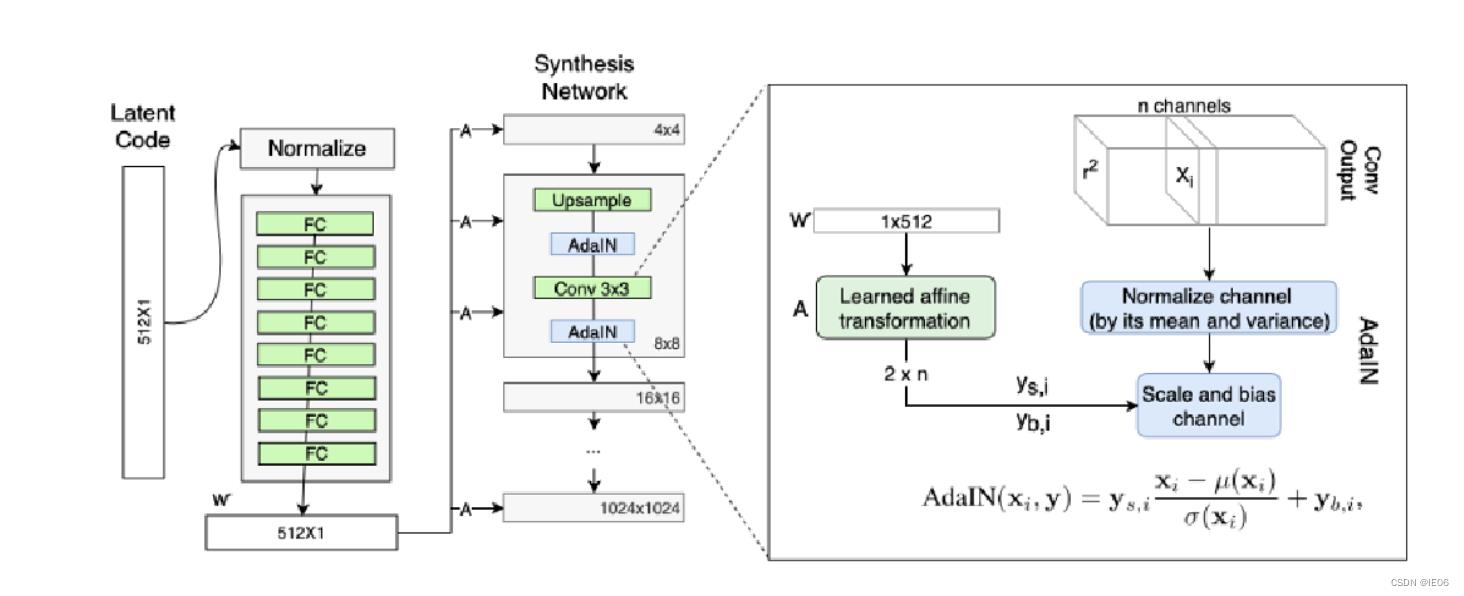
3)噪声不是在原始向量中添加,而是添加在Synthesis的每一层中,修改缩放和偏移的值:

4)训练过程中同时使用了两个w,记为A和B,分别用来训练某些网络级别:
分辨率(4x4 - 8x8)的网络部分使用B的style,其余使用A的style, 可以看到图像的身份特征随souce B,但是肤色等细节随source A;
分辨率(16x16 - 32x32)的网络部分使用B的style,这个时候生成图像不再具有B的身份特性,发型、姿态等都发生改变,但是肤色依然随A;
分辨率(64x64 - 1024x1024)的网络部分使用B的style,此时身份特征随A,肤色随B。
2. styleGAN 2
stylegan2主要是为了解决stylegan生成的图像上容易出现“水滴”问题。导致水滴的原因是Adain操作,Adain对每个feature map进行归一化,因此有可能破坏掉feature之间的信息,产生上述现象。而去除了Adain后,该问题便解决了。
主要修改点包括:
1)移除最开始的数据处理
2)在标准化特征后取消乘以均值
3)将noise模块在外部style模块添加
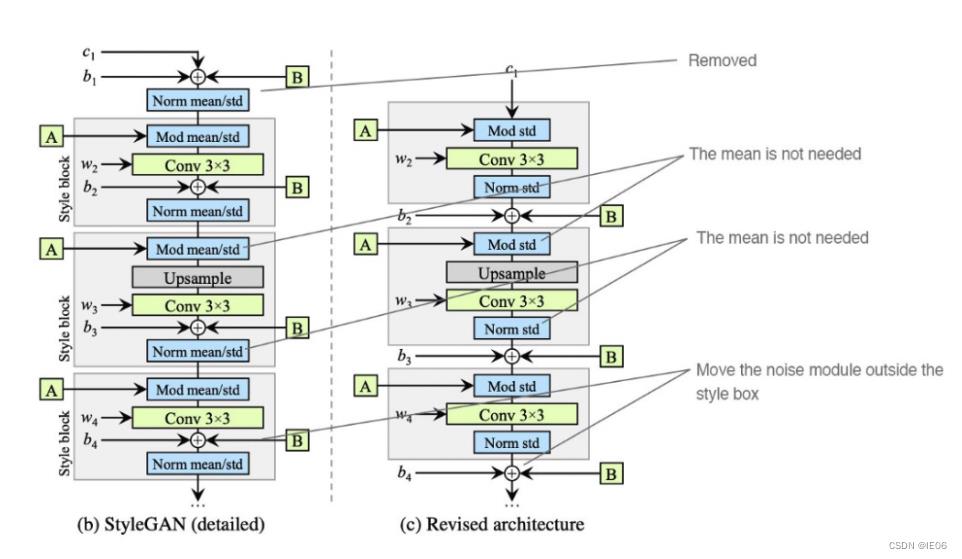
4)加入weight demodulation,解决取消乘以均值后各特征不成比例的问题:

5)Lazy regularization:每16个minibatch才优化一次正则项,这样可以减少计算量,同时对效果也没什么影响。
3. styleGAN 3
在GAN的合成过程中,某些特征依赖于绝对像素坐标,这会导致:细节似乎粘在图像坐标上,而不是所要生成对象的表面。这个问题的出现其实是GAN模型存在的一个普遍问题:生成的过程并不是一个自然的层次化生成。粗糙特征(GAN的浅层网络的输出特征)主要控制了精细特征(GAN的深层网络的输出特征)的存在与否,并没有精细控制它们的出现的精确位置。
目前的生成器网络架构是卷积+非线性+上采样等结构,而这样的架构无法做到很好的Equivariance(等变性)
而stylegan3从根本上解决了stylegan2图像坐标与特征粘连的问题,实现了真正的图像平移、旋转等不变性,大幅度提高了图像合成质量。
(1) 利用Fourier特征(傅里叶特征)代替了stylegan2生成器的常数输入
(2) 删除了noise输入(特征的位置信息要完全来自前层粗糙特征)
(3) 降低了网络深度(14层,之前是18层),禁用mixing regularization和path length regularization,并且在每次卷积前都使用简单的归一化 (这里有点直接推翻了stylegan2的一些思想)
(4) 用理想低通滤波器来代替双线性采样。
(5) 为了得到旋转不变性网络,做出来两个改进:将所有层的卷积核大小从3替换为1,通过将feature map的数量增加一倍,用来弥补减少的特征容量
4. styleGAN功能

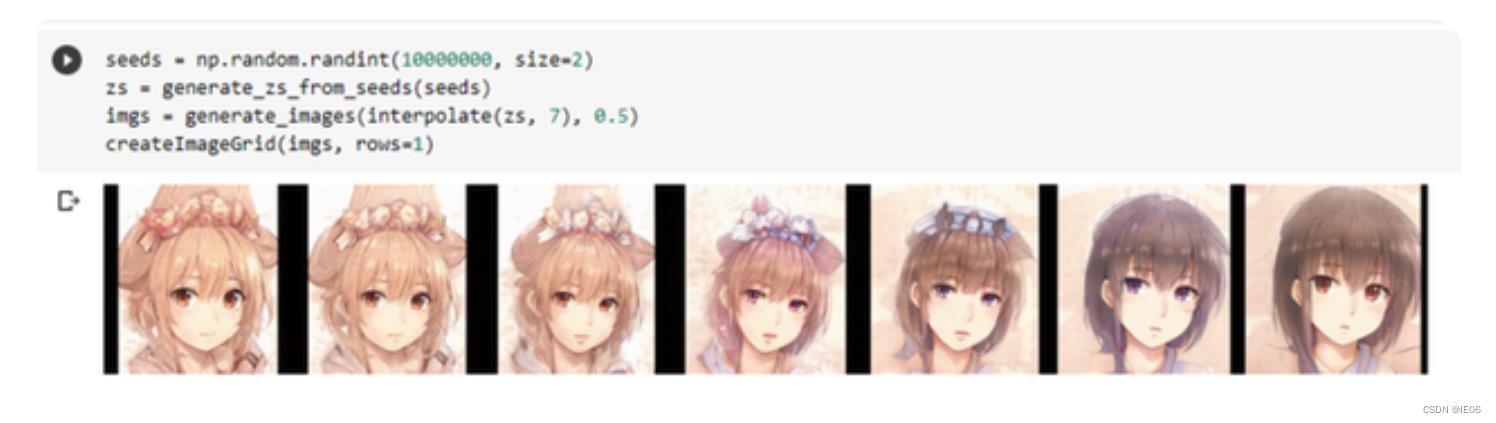
GAN有一个平滑和连续的隐空间,而不像VAE(Variational Auto Encoder)有间隙。因此,当你在潜伏空间中取两个点f1和f2,将产生两个不同的面,你可以通过在两个点之间取一个线性路径来创建两个面的过渡或插值。
以上是关于深度学习系列47:styleGAN总结的主要内容,如果未能解决你的问题,请参考以下文章