MySQL事务的实现原理
Posted 归田
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL事务的实现原理相关的知识,希望对你有一定的参考价值。
1. 开篇
相信大家都用过事务以及了解他的特点,如原子性(Atomicity),一致性(Consistency),隔离型(Isolation)以及持久性(Durability)等。今天想跟大家一起研究下事务内部到底是怎么实现的,在讲解前我想先抛出个问题:
事务想要做到什么效果?
按我理解,无非是要做到可靠性以及并发处理。
可靠性:数据库要保证当insert或update操作时抛异常或者数据库crash的时候需要保障数据的操作前后的一致,想要做到这个,我需要知道我修改之前和修改之后的状态,所以就有了undo log和redo log。
并发处理:也就是说当多个并发请求过来,并且其中有一个请求是对数据修改操作的时候会有影响,为了避免读到脏数据,所以需要对事务之间的读写进行隔离,至于隔离到啥程度得看业务系统的场景了,实现这个就得用mysql 的隔离级别。
下面我首先讲实现事务功能的三个技术,分别是日志文件(redo log 和 undo log),锁技术以及MVCC,然后再讲事务的实现原理,包括原子性是怎么实现的,隔离型是怎么实现的等等。最后在做一个总结,希望大家能够耐心看完
-
redo log与undo log介绍
-
mysql锁技术以及MVCC基础
-
事务的实现原理
-
总结
2 redo log 与 undo log介绍
1. redo log
什么是redo log ?
redo log叫做重做日志,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都会存到该日志中。假设有个表叫做tb1(id,username) 现在要插入数据(3,ceshi)
start transaction;
select balance from bank where name="zhangsan";
// 生成 重做日志 balance=600
update bank set balance = balance - 400;
// 生成 重做日志 amount=400
update finance set amount = amount + 400;
commit;
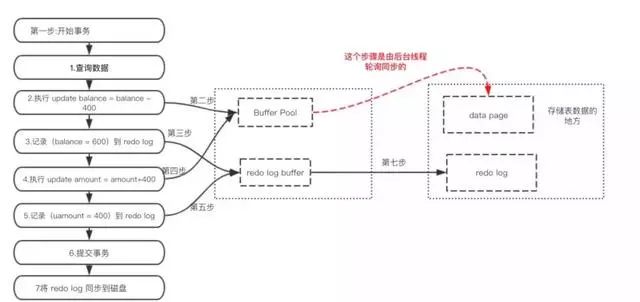
redo log 有什么作用?
mysql 为了提升性能不会把每次的修改都实时同步到磁盘,而是会先存到Boffer Pool(缓冲池)里头,把这个当作缓存来用。然后使用后台线程去做缓冲池和磁盘之间的同步。
那么问题来了,如果还没来的同步的时候宕机或断电了怎么办?还没来得及执行上面图中红色的操作。这样会导致丢部分已提交事务的修改信息!
所以引入了redo log来记录已成功提交事务的修改信息,并且会把redo log持久化到磁盘,系统重启之后在读取redo log恢复最新数据。
总结:
redo log是用来恢复数据的 用于保障已提交事务的持久化特性。
2.undo log
什么是 undo log ?
undo log 叫做回滚日志,用于记录数据被修改前的信息。他正好跟前面所说的重做日志所记录的相反,重做日志记录数据被修改后的信息。undo log主要记录的是数据的逻辑变化,为了在发生错误时回滚之前的操作,需要将之前的操作都记录下来,然后在发生错误时才可以回滚。
还用上面那两张表
每次写入数据或者修改数据之前都会把修改前的信息记录到 undo log。
undo log 有什么作用?
undo log 记录事务修改之前版本的数据信息,因此假如由于系统错误或者rollback操作而回滚的话可以根据undo log的信息来进行回滚到没被修改前的状态。
总结:
undo log是用来回滚数据的用于保障 未提交事务的原子性
3 mysql锁技术以及MVCC基础
1. mysql锁技术
当有多个请求来读取表中的数据时可以不采取任何操作,但是多个请求里有读请求,又有修改请求时必须有一种措施来进行并发控制。不然很有可能会造成不一致。
读写锁
解决上述问题很简单,只需用两种锁的组合来对读写请求进行控制即可,这两种锁被称为:
共享锁(shared lock),又叫做"读锁"
读锁是可以共享的,或者说多个读请求可以共享一把锁读数据,不会造成阻塞。
排他锁(exclusive lock),又叫做"写锁"
写锁会排斥其他所有获取锁的请求,一直阻塞,直到写入完成释放锁。
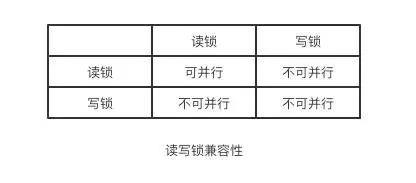
总结:
通过读写锁,可以做到读读可以并行,但是不能做到写读,写写并行
事务的隔离性就是根据读写锁来实现的!!!这个后面再说。
2. MVCC基础
MVCC (MultiVersion Concurrency Control) 叫做多版本并发控制。
InnoDB的 MVCC ,是通过在每行记录的后面保存两个隐藏的列来实现的。这两个列,一个保存了行的创建时间,一个保存了行的过期时间,当然存储的并不是实际的时间值,而是系统版本号
以上片段摘自《高性能Mysql》这本书对MVCC的定义。他的主要实现思想是通过数据多版本来做到读写分离。从而实现不加锁读进而做到读写并行。
MVCC在mysql中的实现依赖的是undo log与read view
-
undo log :undo log 中记录某行数据的多个版本的数据。
-
read view :用来判断当前版本数据的可见性
4 事务的实现
前面讲的重做日志,回滚日志以及锁技术就是实现事务的基础。
事务的原子性是通过undolog来实现的事务的持久性性是通过redolog来实现的事务的隔离性是通过(读写锁+MVCC)来实现的而事务的终极大 boss 一致性是通过原子性,持久性,隔离性来实现的!!!原子性,持久性,隔离性折腾半天的目的也是为了保障数据的一致性!
总之,ACID只是个概念,事务最终目的是要保障数据的可靠性,一致性。
1.原子性的实现
什么是原子性:
一个事务必须被视为不可分割的最小工作单位,一个事务中的所有操作要么全部成功提交,要么全部失败回滚,对于一个事务来说不可能只执行其中的部分操作,这就是事务的原子性。
上面这段话取自《高性能MySQL》这本书对原子性的定义,原子性可以概括为就是要实现要么全部失败,要么全部成功。
以上概念相信大家伙儿都了解,那么数据库是怎么实现的呢?就是通过回滚操作。所谓回滚操作就是当发生错误异常或者显式的执行rollback语句时需要把数据还原到原先的模样,所以这时候就需要用到undo log来进行回滚,接下来看一下undo log在实现事务原子性时怎么发挥作用的
1.1 undo log 的生成
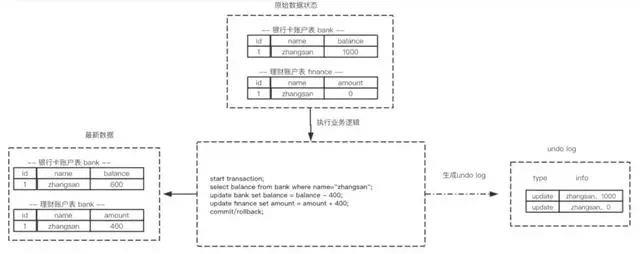
假设有两个表 bank和finance,表中原始数据如图所示,当进行插入,删除以及更新操作时生成的undo log如下面图所示:

从上图可以了解到数据的变更都伴随着回滚日志的产生:
(1) 产生了被修改前数据(zhangsan,1000) 的回滚日志
(2) 产生了被修改前数据(zhangsan,0) 的回滚日志
根据上面流程可以得出如下结论:
1.每条数据变更(insert/update/delete)操作都伴随一条undo log的生成,并且回滚日志必须先于数据持久化到磁盘上
2.所谓的回滚就是根据回滚日志做逆向操作,比如delete的逆向操作为insert,insert的逆向操作为delete,update的逆向为update等。
思考:为什么先写日志后写数据库?--- 稍后做解释
1.2 根据undo log 进行回滚
为了做到同时成功或者失败,当系统发生错误或者执行rollback操作时需要根据undo log 进行回滚
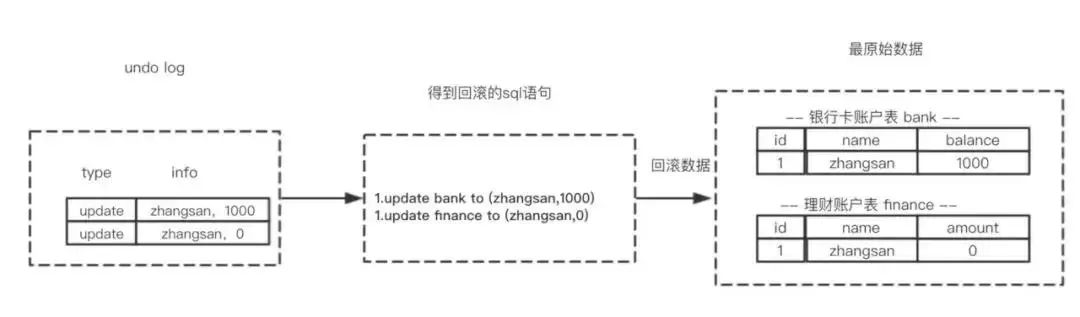
回滚操作就是要还原到原来的状态,undo log记录了数据被修改前的信息以及新增和被删除的数据信息,根据undo log生成回滚语句,比如:
(1) 如果在回滚日志里有新增数据记录,则生成删除该条的语句
(2) 如果在回滚日志里有删除数据记录,则生成生成该条的语句
(3) 如果在回滚日志里有修改数据记录,则生成修改到原先数据的语句
2.持久性的实现
事务一旦提交,其所做的修改会永久保存到数据库中,此时即使系统崩溃修改的数据也不会丢失。
先了解一下MySQL的数据存储机制,MySQL的表数据是存放在磁盘上的,因此想要存取的时候都要经历磁盘IO,然而即使是使用SSD磁盘IO也是非常消耗性能的。为此,为了提升性能InnoDB提供了缓冲池(Buffer Pool),Buffer Pool中包含了磁盘数据页的映射,可以当做缓存来使用:
读数据:会首先从缓冲池中读取,如果缓冲池中没有,则从磁盘读取再放入缓冲池;
写数据:会首先写入缓冲池,缓冲池中的数据会定期同步到磁盘中;
上面这种缓冲池的措施虽然在性能方面带来了质的飞跃,但是它也带来了新的问题,当MySQL系统宕机,断电的时候可能会丢数据!!!
因为我们的数据已经提交了,但此时是在缓冲池里头,还没来得及在磁盘持久化,所以我们急需一种机制需要存一下已提交事务的数据,为恢复数据使用。
于是 redo log就派上用场了。下面看下redo log是什么时候产生的
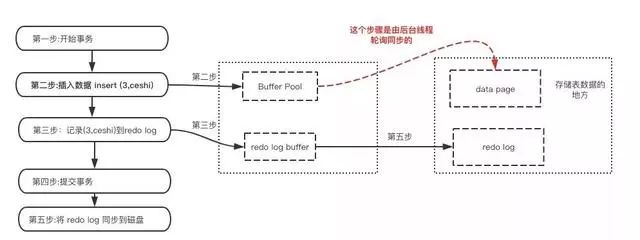
既然redo log也需要存储,也涉及磁盘IO为啥还用它?
(1)redo log 的存储是顺序存储,而缓存同步是随机操作。
(2)缓存同步是以数据页为单位的,每次传输的数据大小大于redo log。
3.隔离性实现
隔离性是事务ACID特性里最复杂的一个。在SQL标准里定义了四种隔离级别,每一种级别都规定一个事务中的修改,哪些是事务之间可见的,哪些是不可见的。
级别越低的隔离级别可以执行越高的并发,但同时实现复杂度以及开销也越大。
MySQL隔离级别有以下四种(级别由低到高):
-
READUNCOMMITED(未提交读)
-
READCOMMITED(提交读)
-
REPEATABLEREAD(可重复读)
-
SERIALIZABLE (可重复读)
只要彻底理解了隔离级别以及他的实现原理就相当于理解了ACID里的隔离型。前面说过原子性,隔离性,持久性的目的都是为了要做到一致性,但隔离型跟其他两个有所区别,原子性和持久性是为了要实现数据的可性保障靠,比如要做到宕机后的恢复,以及错误后的回滚。
那么隔离性是要做到什么呢? 隔离性是要管理多个并发读写请求的访问顺序。 这种顺序包括串行或者是并行
说明一点,写请求不仅仅是指insert操作,又包括update操作。
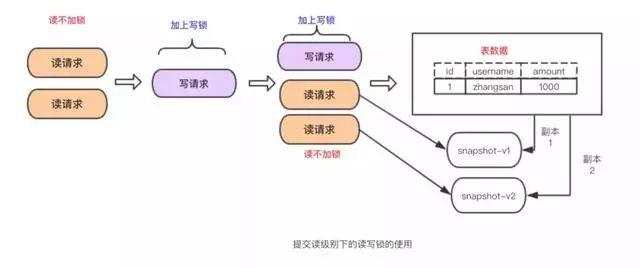
总之,从隔离性的实现可以看出这是一场数据的可靠性与性能之间的权衡:
可靠性性高的,并发性能低(比如Serializable)。可靠性低的,并发性能高(比如 Read Uncommited)READ UNCOMMITTED
在READ UNCOMMITTED隔离级别下,事务中的修改即使还没提交,对其他事务是可见的。事务可以读取未提交的数据,造成脏读。
因为读不会加任何锁,所以写操作在读的过程中修改数据,所以会造成脏读。好处是可以提升并发处理性能,能做到读写并行。
换句话说,读的操作不能排斥写请求。
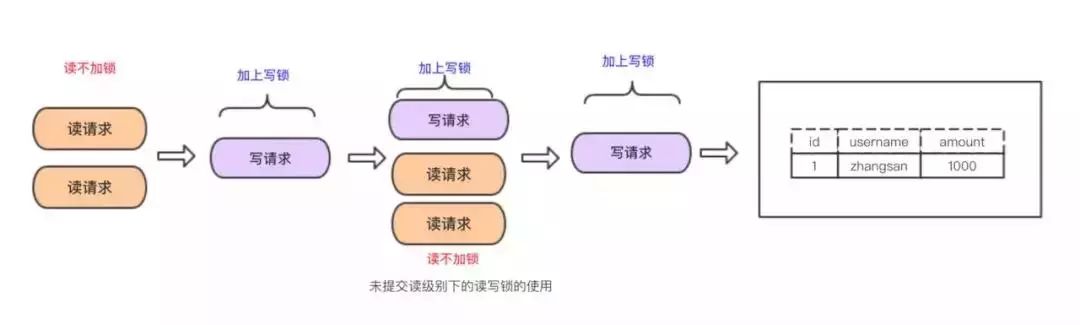
优点:读写并行,性能高
缺点:造成脏读
READ COMMITTED
一个事务的修改在他提交之前的所有修改,对其他事务都是不可见的。其他事务能读到已提交的修改变化。在很多场景下这种逻辑是可以接受的。
InnoDB在 READ COMMITTED,使用排它锁,读取数据不加锁而是使用了MVCC机制。或者换句话说他采用了读写分离机制。
但是该级别会产生不可重读以及幻读问题。
什么是不可重读?
在一个事务内多次读取的结果不一样。
为什么会产生不可重复读?
这跟 READ COMMITTED 级别下的MVCC机制有关系,在该隔离级别下每次 select的时候新生成一个版本号,所以每次select的时候读的不是一个副本而是不同的副本。
在每次select之间有其他事务更新了我们读取的数据并提交了,那就出现了不可重复读
REPEATABLE READ(Mysql默认隔离级别)
在一个事务内的多次读取的结果是一样的。这种级别下可以避免,脏读,不可重复读等查询问题。mysql 有两种机制可以达到这种隔离级别的效果,分别是采用读写锁以及MVCC。
采用读写锁实现:
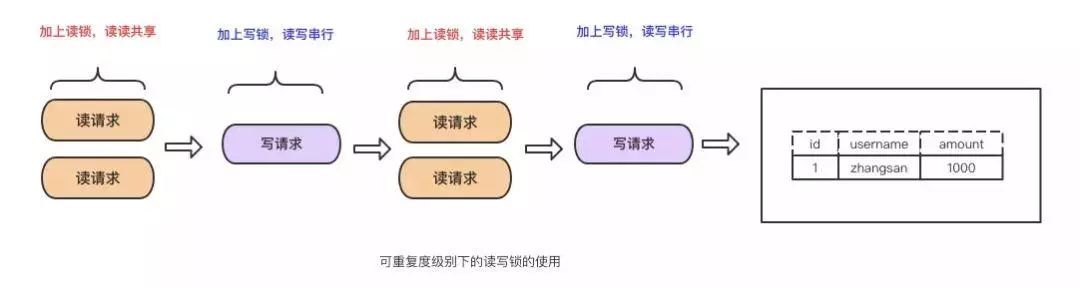
为什么能可重复读?只要没释放读锁,在次读的时候还是可以读到第一次读的数据。
优点:实现起来简单
缺点:无法做到读写并行
采用MVCC实现:
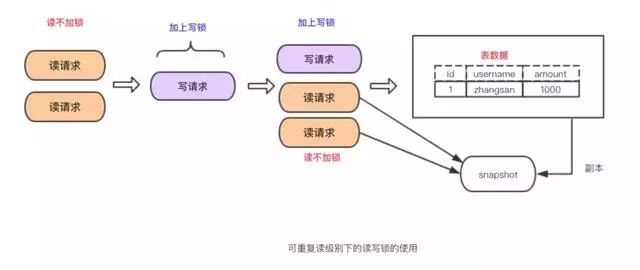
为什么能可重复读?因为多次读取只生成一个版本,读到的自然是相同数据。
优点:读写并行
缺点:实现的复杂度高
但是在该隔离级别下仍会存在幻读的问题,关于幻读的解决我打算另开一篇来介绍。
SERIALIZABLE
该隔离级别理解起来最简单,实现也最简单。在隔离级别下除了不会造成数据不一致问题,没其他优点。
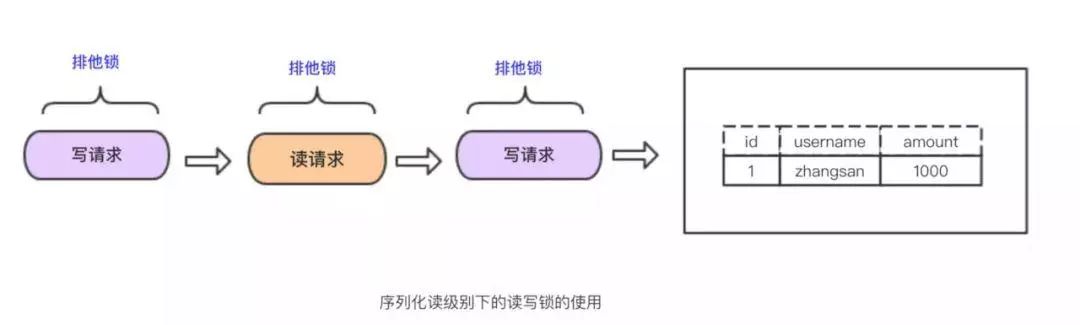
 --摘自《高性能Mysql》
--摘自《高性能Mysql》
4.一致性的实现
数据库总是从一个一致性的状态转移到另一个一致性的状态。
下面举个例子,zhangsan 从银行卡转400到理财账户:
start transaction;
select balance from bank where name="zhangsan";
// 生成 重做日志 balance=600
update bank set balance = balance - 400;
// 生成 重做日志 amount=400
update finance set amount = amount + 400;
commit;
1.假如执行完 update bank set balance = balance - 400;之发生异常了,银行卡的钱也不能平白无故的减少,而是回滚到最初状态。
2.又或者事务提交之后,缓冲池还没同步到磁盘的时候宕机了,这也是不能接受的,应该在重启的时候恢复并持久化。
3.假如有并发事务请求的时候也应该做好事务之间的可见性问题,避免造成脏读,不可重复读,幻读等。在涉及并发的情况下往往在性能和一致性之间做平衡,做一定的取舍,所以隔离性也是对一致性的一种破坏。
总结
本出发点是想讲一下Mysql的事务的实现原理。
实现事务采取了哪些技术以及思想?
-
原子性:使用 undo log ,从而达到回滚
-
持久性:使用 redo log,从而达到故障后恢复
-
隔离性:使用锁以及MVCC,运用的优化思想有读写分离,读读并行,读写并行
-
一致性:通过回滚,以及恢复,和在并发环境下的隔离做到一致性。
以上是关于MySQL事务的实现原理的主要内容,如果未能解决你的问题,请参考以下文章