yolov3-tools使用说明
Posted henreash
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了yolov3-tools使用说明相关的知识,希望对你有一定的参考价值。
配置yolo训练环境比较复杂,同时需要大量样本。各种拷贝、各种标注、各种修改配置文件,新手需要大概三五天时间才能摸透,因此开发了这个小工具。收集好样本后,一个界面搞定配置、标注、训练过程。
github地址:https://github.com/henreash/yolov3-tools
已编译的发布程序:cuda10.0版本(https://pan.baidu.com/s/1ESi9HaVlRx6UpfsP_Uk6Eg 提取码: mi2u)
cuda10.2版本( https://pan.baidu.com/s/12QCNC38QnHGqMLhbplpiYQ 提取码: kwiz )
运行提示缺少dll,请下载对应的cuda和cudnn安装包。
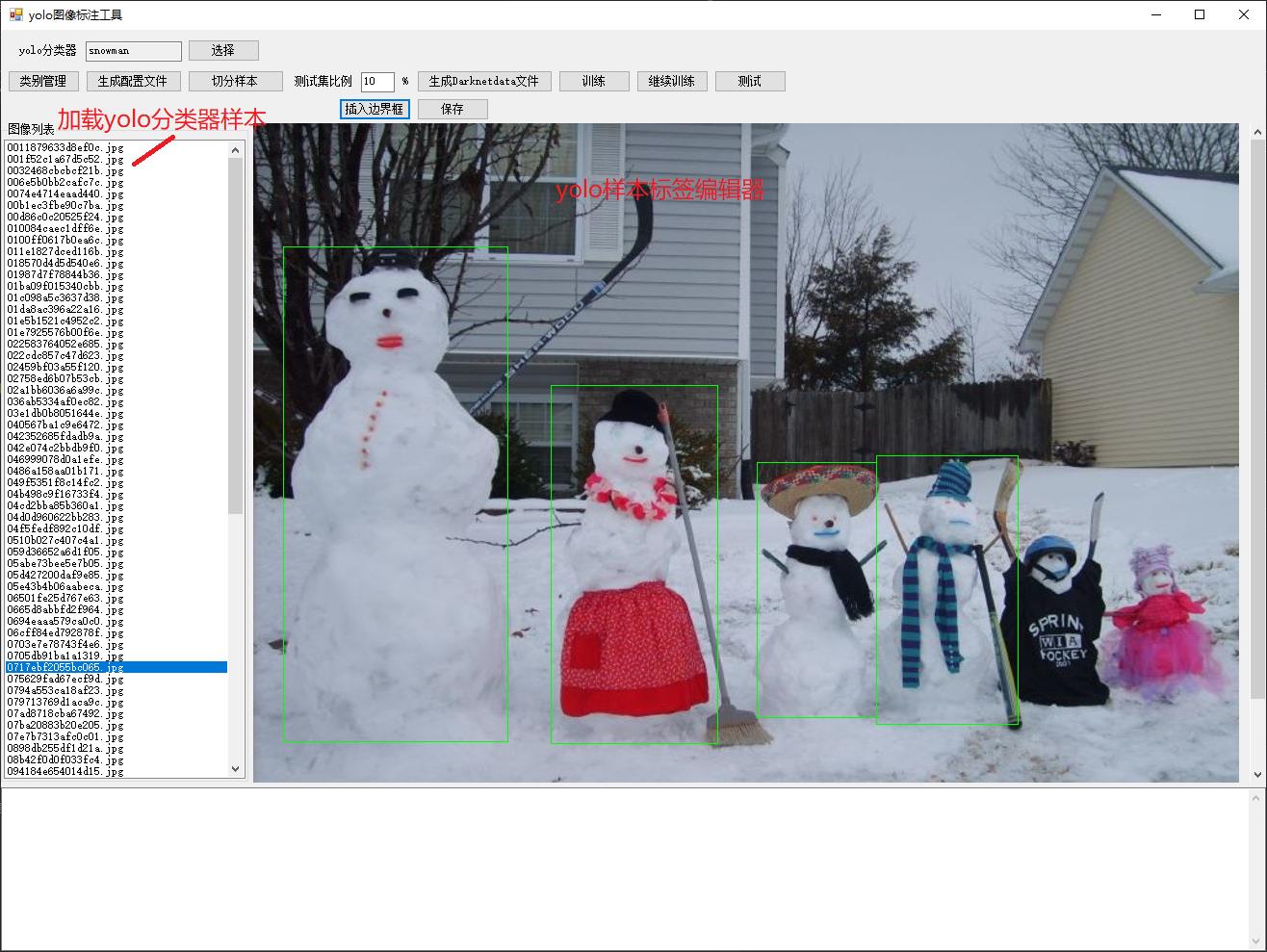
运行界面如上图。
工具自带了谷歌的机器视觉图像snowman的样本及标注数据。如需要创建新的yolov3检测器,请首先打开资源管理器,找到本工具目录,和snowman目录同级创建存放yolov3检测器目录,例如detectorA,创建detectorA/images目录,将样本图像存放到detectorA/images下;创建detectorA/test-images目录,将测试图像存放到detectorA/test-images下,如下图:

yolo分类器
界面的yolo分类器内容默认是snowman,点击后面的选择按钮,选择detectorA目录,yolo分类器则变为detectorA,界面下方的样本列表自动加载detectorA/images目录中的样本图像列表;软件启动默认的yolo检测器是snowman,加载snowman/images目录中的样本。
类别管理
点击类别管理,打开界面,可在界面中增加、删除、修改类别,后面将根据配置类别生成配置文件、设置标注对象的类别、生成darknet.data文件。类别内容存储在<yolo分类器目录>/classes-auto-gen.names文件中。标记训练样本时也需要使用这里输入的类别。注意,类别名称请使用英文。

生成配置文件
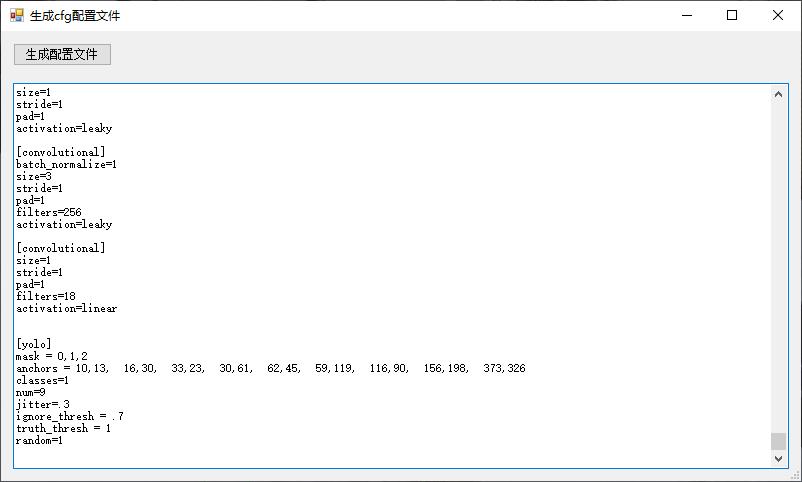
点击生成配置文件按钮,弹出界面,点击其中的<生成配置文件按钮>,自动生成配置文件,存储在<yolo分类器目录>/yolov3-<分类器名称>-auto-gen.cfg文件中。注意,生成的配置和类别数量有关,如果修改过类别数量,请重新生成配置文件。
切分样本
点击切分样本,将图像样本按比例(可在后面的比例框配置,默认10%)拆分为训练样本和测试样本,在<yolo分类器目录>中生成train-auto-gen.txt和test-auto-gen.txt文件,内含训练样本和测试样本图像名称。
生成darknet配置文件
点击<生成darknet配置文件>按钮,自动生成<yolo分类器目录>/<yolo分类器名称>-data-auto-gen.data,其中指定了类别个数、训练集、测试集、类别存储文件、backup目录。
样本标注
双击界面左侧的图像列表,右侧图像显示区域自动显示选中的样本图像,并加载已标注对象的边界框(绿色框),可用鼠标拖动调整大小和位置,可按方向键调整选中对象的位置(存在和界面控件争夺光标的问题,github上代码已改进)。点击插入边界框,在图像上按下鼠标左键,插入一个新的边界框。双击边界框(标注框),弹出调整对象类别的对话框:
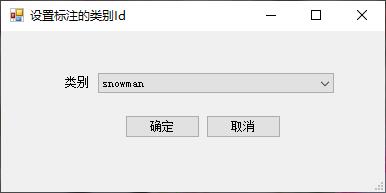
注意:类别下拉框数据来自第一步配置的类别列表。
样本标注好后,记得点主界面的保存按钮,否则修改的数据会丢失。
将所有样本图像进行标注,即可启动训练过程。
训练
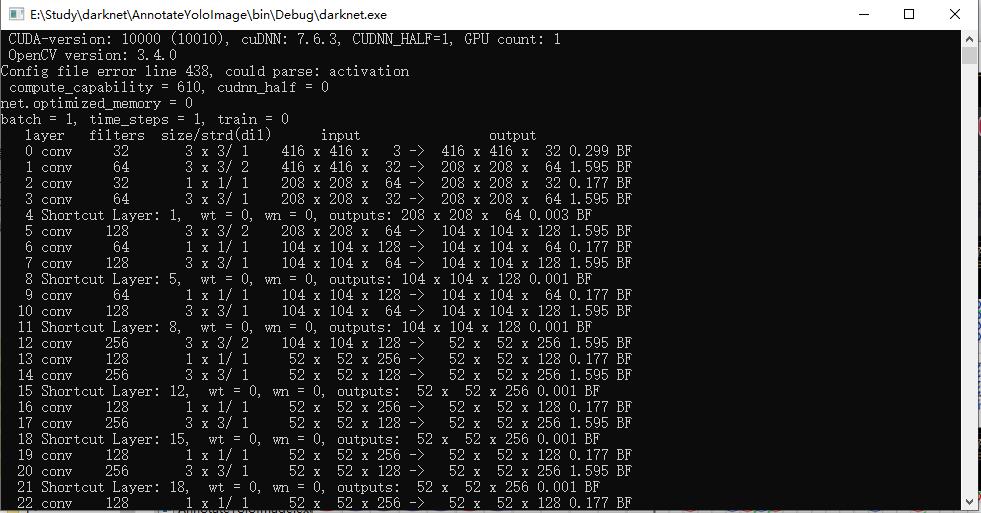
训练过程依赖darknet程序,可从上面给出的百度网盘下载,如运行有问题请自行根据教程进行编译(使用NVIDIA GPU加速,程序在不同配置的机器上运行可能报错,本例中的程序安装的是cuda10.2、cudnn7.6.5)。编译后替换工具目录中darknet相关文件。
darknet教程:https://github.com/henreash/yolov3-tools/blob/master/doc/yolov3-train-tutorial.pdf
点击训练按钮,启动训练界面:

训练过程较长,请耐心等待。打开<yolo分类器目录>,如看到yolov3-<yolo分类器名称>-auto-gen_last.weights文件,即可随时停止训练,去测试效果。测试后,还可继续进行训练。(会丢失一部分数据)
继续训练
点击<继续训练>按钮,会加载<yolo分类器目录>/yolov3-<yolo分类器名称>-auto-gen_last.weights文件中的权重,继续上次的训练过程。
测试
点击<测试>按钮,选择测试图像,启动测试过程。

训练的模型在.net下的应用:
在github上下载Alturos.Yolo项目,将.weights文件、.cfg文件、.names文件拷贝到编译后的程序运行目录中,将测试图像拷贝到images目录中,运行程序即可查看效果。
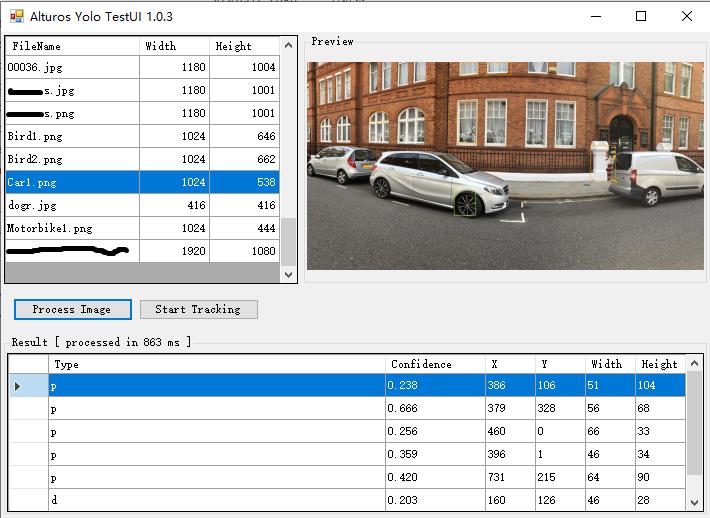
上图测试结果发现,yolov3在cpu下运行,检测一次需要800ms左右,而安装好cuda10.2、cudnn7.6.5后,直接提升到50ms。完全可以达到实时检测的目的。检测到的位置存在几个像素的误差,改进样本标注质量、加大训练量可以进一步提高。
以上是关于yolov3-tools使用说明的主要内容,如果未能解决你的问题,请参考以下文章