Kafka入门了解
Posted ych9527
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka入门了解相关的知识,希望对你有一定的参考价值。
文章目录
消息队列的优点
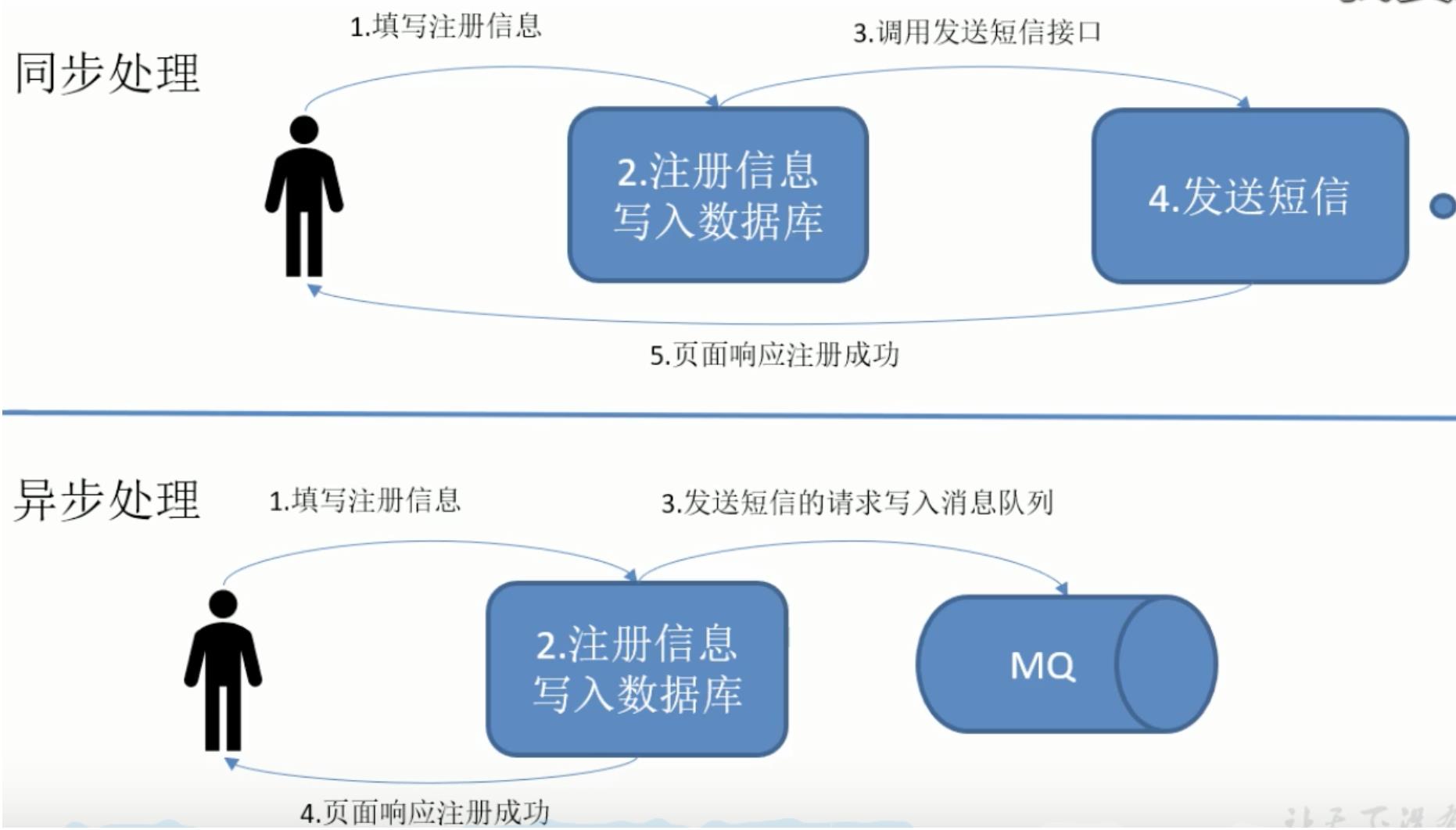
- 异步解耦
- 允许你独立扩展或者修改两边的处理过程,只要确保它们遵守同样的约束即可
- 可恢复性
- 系统一部分组件失效时,不会影响整个系统。消息队列降低了进程之间的耦合性,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理
- 缓冲
- 有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况
- 削峰操作
- 由于不是与服务器直连,而是将数据写入在队列之中,因此当大量数据来临的时候,可以在一定程度上缓解服务器的压力,通过消息队列控制速度,相当于生产者消费者模型。比如双11这天的淘宝业务特别好,不可能在这一天去增加机器,这时消息队列就起到了削峰操作
- 异步通信
- 消息队列提供异步机制,可以往里面存放数据而不去立即处理
消息队列的两种模式
点对点模式
-
一对一,消费者主动拉取数据,消息收到后消息清除[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
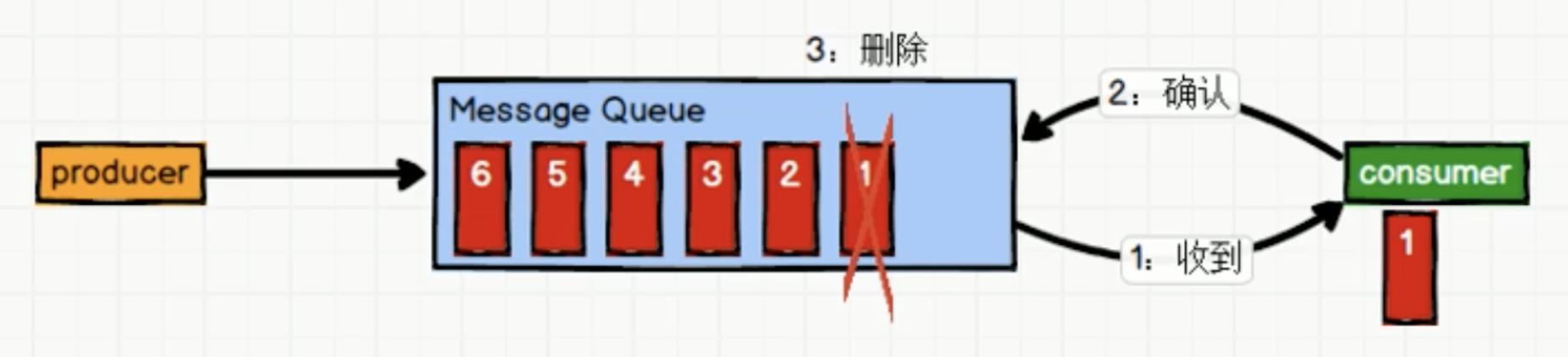
-
生产者生产消息放到队列之中、消费者从队列之中取出并且消费消息。消息被消费之后,队列之中不再进行存储,所以消费者不可能消费到以及消费过的消息
-
队列支持存在多个消费者、但是对一个消息而言,只允许一个消费者的存在
-
缺点
- 消息不可复用。如果消息要给多个人,那么需要生产者再次往队列放入消息
发布/订阅模式
-
一对多,消费者消费数
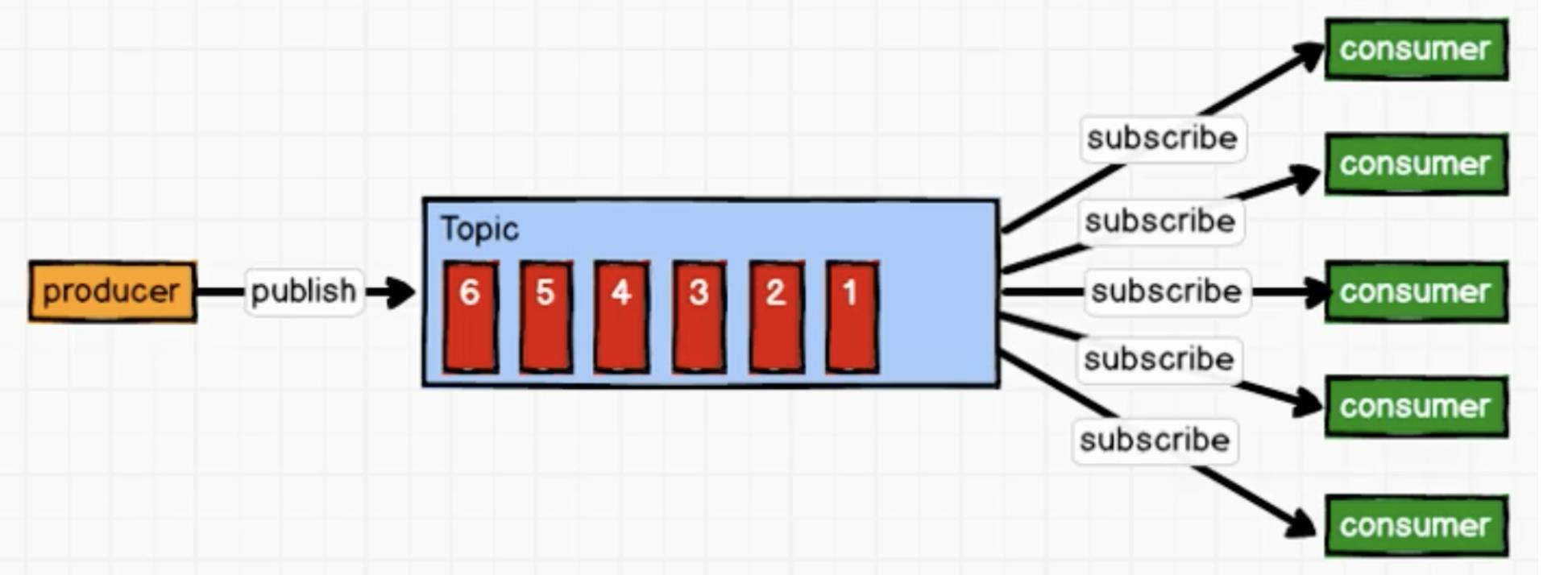
据之后不会清除消息 -
消息生产者(发布)将消息发布到Topic中,同时有多个消费者(订阅)消费该消息。和点对点的方式不同的是,发布到topic(主题/消息队列)中的消息会被所有订阅者消费
-
发布订阅又分为两种模式
- 消费者主动拉取数据的缺点
- 需要消费者维护一个长轮询,不断地去消息队列之中查看是否有消息,当消息队列为空的时候这是一种资源的浪费
- 消息队列主动推送数据
- 推的速度是一样的,但是消费者的速度是不一样的,因此可能导致消费者效率问题
- 消费者主动拉取数据的缺点
Kafka基本架构
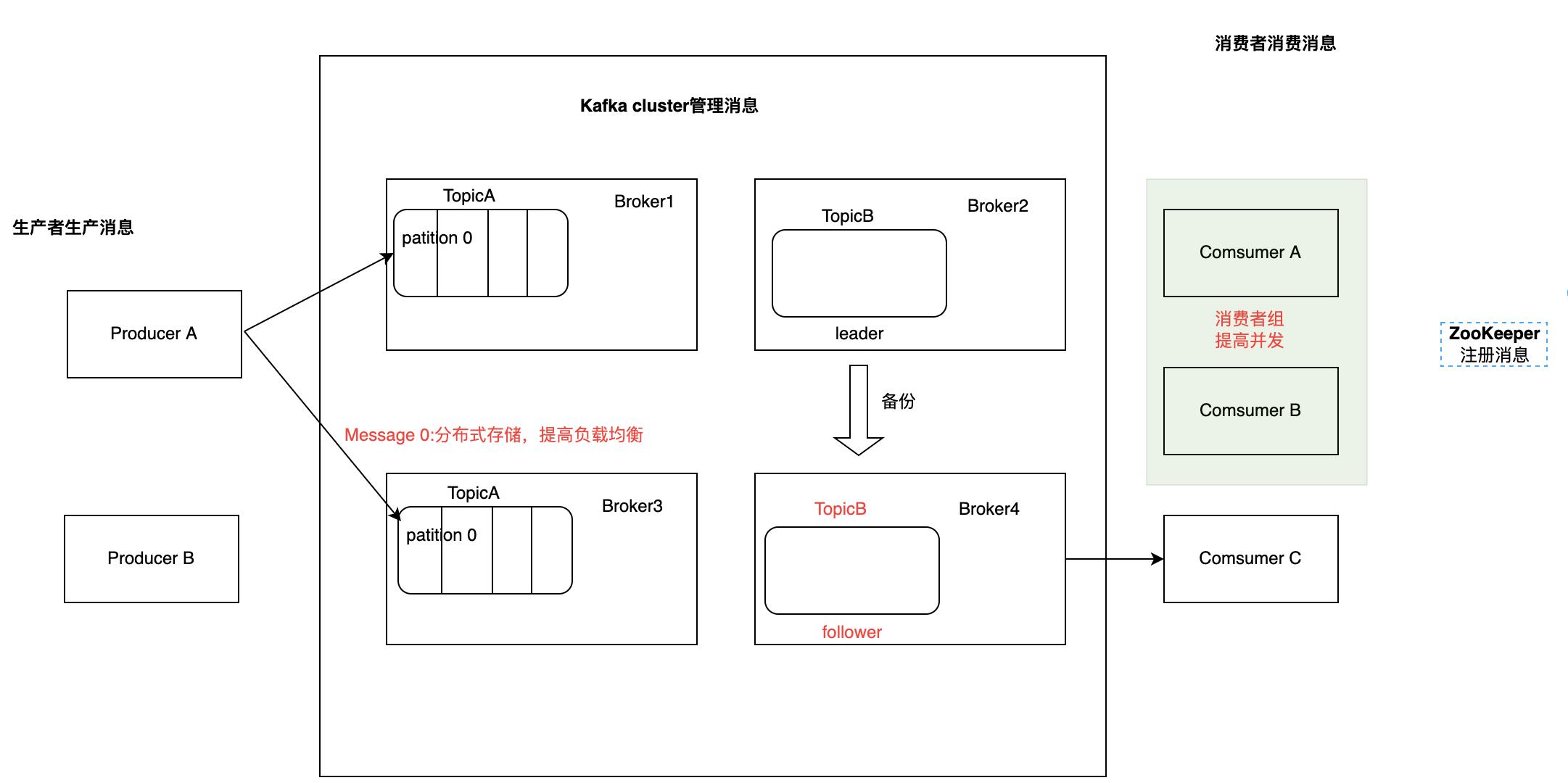
-
Kafka cluster Kafka集群
-
Broker可以认为就是一台服务器
-
Topic 消息主题,也可以认为是消息分类
- 布置消息主题的原因
- 如果所有的消息都存储于Broker之中,那么在进行数据获取的时候是比较混乱的因此,对数据进行分区,更有利于数据的获取就好比超时的水果和生鲜是分开放的,这样有利于效率的提高,如果混在一起就会比较杂乱
- 布置消息主题的原因
-
Partition 主题里面的分区
- patition分区的作用
- 有利于提高负载均衡,因为在进行数据存储的时候,可以存储在不同的服务器上
- patition分区的作用
-
Consumer Group (CG)
- 消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个组内的消费者不能消费同一个分区(A.B不能同时消费 TopicA中的P0,但是A.C可以);
消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者 - 消费者组中的消费者个数多余某一个主题的分区数,是没有意义的,因为一个分区只可以给一个消费者消费,所以1:1是最佳的
消费者组的优势是提高并发,比如A、B就可以同时消费一个主题的两个分区,因为这个消费者组订阅了主题A,同理C每次就只能消费订阅主题的一个分区
- 消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个组内的消费者不能消费同一个分区(A.B不能同时消费 TopicA中的P0,但是A.C可以);
-
ZooKeeper
- 注册消息中心
- 帮助Kafka集群存储一些信息
- 消费者也会存储一些东西(存储消费者消费的位置信息,挂了之后,重新连接接着消费,不需要重新开始,这就是解耦)
- 0.9版本之前offset存储在zk中、0.9版本之后存储在本地,作用都是记录消费位置
- 为什么要改存储位置?
- 消费者要和leader进行数据拉取,同时又要和zk保持联系,这种高并发请求对zk也不是很好,因此改了
- 为什么要改存储位置?
以上是关于Kafka入门了解的主要内容,如果未能解决你的问题,请参考以下文章