Detection of Rail Surface Defects Based on CNN Image Recognition and Classification-论文阅读笔记
Posted Dream_WLB
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Detection of Rail Surface Defects Based on CNN Image Recognition and Classification-论文阅读笔记相关的知识,希望对你有一定的参考价值。
Detection of Rail Surface Defects Based on CNN Image Recognition and Classification
基于CNN图像识别和分类的钢轨表面缺陷检测
//2022.7.21下午12:37开始阅读笔记
论文速览
本文提出了一个两阶段的钢轨表面缺陷检测框架,但是不是实时进行检测的。
在第一阶段,作者首先对轨道图像进行预处理,将其图像变为灰色图像,然后使用Canny边缘检测器获取边缘点并保存边缘点列,通过使用图像中轨道的比率d/l(其中d和I表示轨道的宽度和灰度图像的宽度,如图3所示),进一步删除保存的边缘点中的假边缘点;然后,对边缘点再次进行粗略和精细去除假边缘点,然后使用线性拟合的方法对上述过程中去除的真的边缘点进行拟合恢复。
在第二阶段,作者使用InceptionV3骨干网络对第一阶段中得到的图像进行了分类,其中作者为平衡正负样本训练不平衡的问题,提出了一种新的loss函数(即:向交叉熵loss函数中添加了F-score公式)实现了模型的精确度和召回率的平衡。
论文地址
论文贡献
本文提出了一种新的两阶段的钢轨表面缺陷检测流程,通过对钢轨图像进行缺陷定位和分类来检测钢轨缺陷。第一阶段,聚焦于钢轨中有缺陷的图像部分的裁剪图像而不是整个图像部分。在第二阶段,作者将第一阶段中得到的裁剪图像输入微调的CNN中,并提取图像的部分用于分类任务。
同时,作者提出了一种新的损失函数,该损失函数在一定程度上促进了模型召回率的提高。结果表明,该方法具有很强的鲁棒性,在缺陷检测精度方面达到了实用性能。
论文内容
1.介绍
文中说到:目前为止该领域的缺陷检测方法有以下三类:
-
手动检测;
-
物理检测方法,例如:使用超声波等信号进行检测;
-
用于目标检测的计算机视觉方法;
文中提出的两阶段网络中,首先使用独立CNN对输入图像中的缺陷块进行分割定位,然后使用CNN对第一阶段得到的缺陷图像进行裁剪后的图像进行分类。
2.相关工作
一些比较传统的检测方法:
超声波检测是表面缺陷检测的一个重要分支,它利用不同介质界面上的独特反射特性来检测缺陷。
涡流检测依赖于电压和涡流强度和分布引起的检测设备阻抗的变化。但是该方法容易受到物体表面状态和检测标准的影响。
红外探测法基于与被测物体温度分布相关的辐射变化,其效果容易受到周围环境温度的影响。
上述所有的方法都依赖于劳动密集型的检测。
数据不平衡问题是钢轨表面缺陷检测的主要问题,而在CNN训练中,少数类样本往往更能决定网络的训练方向,基于上述问题,一般有两种方法:上采样方法:如SMOTE[37]和ADASYN[33]基于特征空间的相似性合成了新的少数类样本。但是党员是数据集过大时,生成的数据集可能会降低性能;下采样方法:例如EasyEnsemble,单侧选择[34]通过删除多数类样本的数量,在其特征空间中平衡正样本和负样本,这可能会导致特征信息的丢失。
作者并没有采用上采样和下采样的方法,而是在损失函数中添加了一个由召回率和准确率组成的参数,以平衡召回率和检测精度之间的关系。
3.方法提出
3.1 概述
图1展示了文中提出的方法pipeline。

3.2 目标定位
为了实现目标定位,我们采用了轨道图像预处理、假边缘点去除和直线拟合方法。由于充分利用了轨道本身的几何特征,我们的目标定位算法简单高效。
3.2.1 轨道图像预处理
鉴于钢轨的几何特征,我们提出了一种鲁棒且计算量较小的钢轨定位算法。我们首先使用加权平均方法将原始彩色图像转换为灰度图像,并使用自适应中值滤波[5],它可以根据噪声点调整滤波窗口的大小以减少噪声。接下来,我们使用Canny边缘检测器获取边缘点并保存边缘点列。然后,我们通过使用图像中轨道的比率d/l(其中d和I表示轨道的宽度和灰度图像的宽度,如图3所示),进一步删除保存的边缘点中的假边缘点。详细描述如下。

3.2.2 粗略去除假边缘点
我们首先从左到右计算由Canny边缘检测器获得的一行中每两个相邻边缘点之间的列差。其中得到的列差表示为:
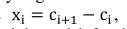
,其中,ci+1和ci分别表示二者的左右边缘点列。
如果xi满足这个大致动态范围:
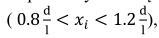
,我们保存ci在左边缘点组和ci+1保存在有边缘点组中。
该操作应逐行执行,最终以两组边缘点结束。该方法旨在排除Canny边缘检测后获得的一些较大偏差假边缘点。
3.2.3 进一步去除假边缘点
计算保存在上述两组不同位置边缘点组标准差:’s’, 如果’si’相对较大,这表明仍然存在部分假边缘点。然后,我们提出了约束条件:

,自适应地缩小动态范围,并从保留的边缘点中进一步去除假边缘点。(’n’表示输入图像的列数)。
参数c在公式中可以进行调整,且参数c对分类结果的影响在下述实验中进行描述。
3.2.4 线性拟合
在进一步移除边缘点之后,可能会将真实的边缘点去掉,因此需要恢复他们。文中作者使用现有的边缘点进行线性拟合,以获得截距和斜率。从而可以得到目标定位。
使用Canny边缘检测器和我们的线性拟合方法的边缘检测结果分别如图2-(a)和图2-(b)所示。基于上述方法,精确地实现了钢轨定位,如图2-(c)所示。

3.3 使用CNN进行分类
3.3.1 基于Inception-v3的迁移学习
使用Inception-v3骨干网络的原因:
-
Inception-v3允许已处理的轨道图像在低维空间收敛,而不必担心丢失大量特征信息;
-
在传播过程中,轨道的特征图缓慢减少,在合流之前,滤波器的数量增加,以减少信息损失和出现瓶颈的概率;
-
将大卷积分解为小卷积。通过这种方式,进一步降低轨道缺陷的特征参数,降低卷积核参数和复杂度,以完成从紧凑网络到稀疏网络的过渡;
-
基于inception-v3等成熟模型的转移学习可以弥补轨道样本不足的缺点,降低计算复杂度;
图像间的迁移学习方法有:
-
当目标域和源域之间的差异较小时,映射相应的数学关系以扩展目标域中的数据量;
-
当目标域和源域之间存在较大差异时,转移学习建立在卷积神经网络层上,并完成特征的迁移;
轨道数据集和Inception-v3网络的数据集之间存在明显的差异,所以文中使用的迁移学习是上述中的第二个类别。
3.3.2 召回率和准确率的平衡
文中,作者将F分数值添加到了交叉熵损失函数中得到了新的loss函数。
最后m个样本的精度、召回率和权重因子分别表示为:P, R和
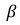
。我们重点关注一些最新样本的精度、召回率和F分数,这些样本的数量都是m的平方,因为只有训练期间的最新样本在现阶段的结果中起着很大的作用。此外,我们将中间迭代指数、当前迭代指数、对应类的估计概率和F分数参数分别地定义为i , m , p, 。
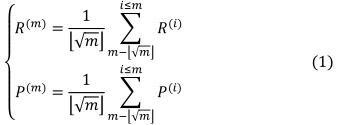
交叉熵损失CE(i)和F-score参数F(i)-i-score如下:


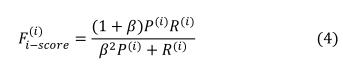
为了正则化这两部分,我们使用Z-分数标准化算法[17]来获得其归一化形式

, 且定义它们为:
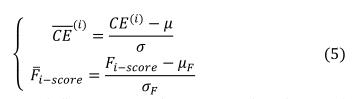
在上述公式中,我们定义

作为 的数据序列均值,且定义 , 为F-score公式的均值和方差。
其中CE(i)序列由所有训练样本的交叉熵,且Fi-score由最后一个训练样本的F-score组成,其数量是m的平方。
包含上述部分的拟议损失函数定义为:

很直观地可以看到,同时具有精度和召回率的F分数是损失函数的强约束,因此该约束使分类器能够朝着正确的方向学习。
4.实验
实验细节:
我们在数据集上评估了我们的方法,该数据集由两个类组成,分别具有缺陷轨道和完整轨道图像。模型在5793个训练图像上进行训练,其中5327个完整轨道图像和466个缺陷轨道图像,并在2276个验证图像上进行评估,其中2033个完整轨道图像和243个缺陷轨道图像。然后,我们得到了1517个测试图像的最终结果。数据集中的每个轨道图像都是由位于特殊机车前方的高速摄像机拍摄的轨道视频中的每一帧。此外,我们的实验是在Intel i5-5200处理器2.20GHz和8G RAM上进行的。
对于第一阶段,我们的基线是在Inception-v3中训练的原始图像产生的结果,其中具有文中所提出的损失函数,且loss函数中的
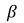
是2。对于第二阶段,我们的基线是使用交叉熵损失函数在Inception-v3中训练的原始图像生成的结果。我们评估了我们的方法和基线的召回率和F分数。
4.1 InceptionV3网络的实现细节
在这一部分中,我们的工作主要分为两个步骤,第一步是充分利用inception-v3进行预训练。G、 Hiton和Y.LeCun等人[38][39]表明,低水平图像特征通常在较低卷积层捕获。更高的卷积层捕获更高级的功能。最后一个完全连接的层被认为是捕捉与解决相应任务相关的信息。第二步是修改全连接层,将转移学习与网络相结合,并将训练好的权重迁移到修改后网络的相应部分。
Inception-v3模型共有46层,由11个Inception模块组成。共有96个卷积层,它们大多并行组合。我们保留了在Inception-v3模型中训练的原始卷积层的参数,仅替换最后一个完全连接层并训练新的单层神经网络。保留该层的原因是,完全连接的层可以在转移学习中充当防火墙[12]。特别是,当源域和目标域差异很大时,完全连接层可以保持模型的能力。然后,我们在连接层后面添加一个退出层,以防止过度拟合,并将该值设置为0.5[11]。
网络输入为960×1280预处理图像。图像经过Inception-v3模型训练后,输入35×35×288卷积层,然后进入8×8×288池层进行进一步的特征压缩。最后,图像输入1×1×2048全连接层以训练新参数。在我们的实验中,网络学习率为0.01,批大小和迭代数分别设置为64和5000。
4.2 目标定位模块的性能
图4显示了,精度和召回率都随着参数c先增加后减少。从结果来看,当参数c为5时,在softmax函数的作用下,召回率和准确率分别达到95.36%和90.86%,使用SVM时分别为94.96%和90.34%。所以,结果显示了使用softmax分类的性能较高于svm分类。
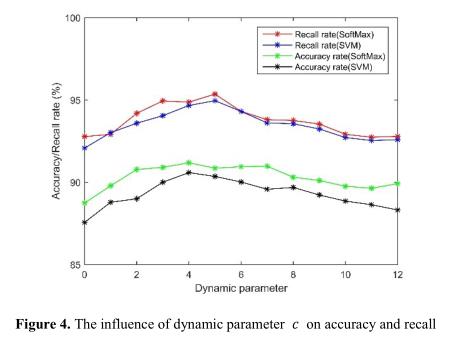
作者在后续的分类实验中,选择参数c为5.
为了进一步验证文中提出的定位算法的性能,作者将原始图像和裁剪图像分别输入到CNN中,然后输入softmax函数中,表1展示了结果。
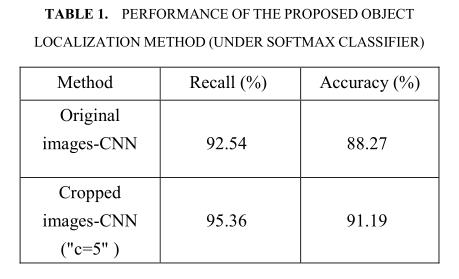
表明,当参数c为5时,使用裁剪图像输入到CNN中较于原始图像在准确率和召回率分别提高了2.82%和2.92%。
这进一步验证了文中提出的图像中缺陷定位的第一阶段对该类任务的作用很重要。
4.3 训练轨道图像分类过程
归一化参数
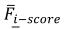
随着 的变化而变化,所以我们不能认为 和 是没有任何关系的。我们分别用不同的 值评估召回率和准确率的变化。此外,基线是 。当 增加时,召回率增加,但精确度降低。召回率的变化如图5所示,精度如图6所示。
我们可以看到当

增加超过2时,文中提出模型的召回率缓慢增加,但准确率迅速下降,由于突然下降,这是精度的临界值。


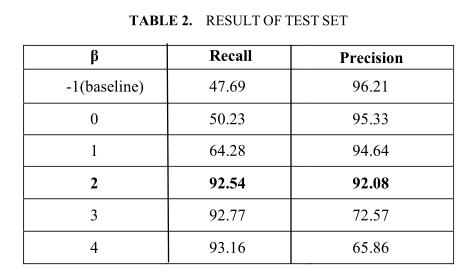
4.4 与测试集的结果进行比较
表2中显示了测试集上的召回率和精确率。
5.结论
文中提出的定位方法是这对钢轨图像表面进行设计的,但是这种方法无法保证实时性。
//本文仅作为日后复习之用,并无他用。
以上是关于Detection of Rail Surface Defects Based on CNN Image Recognition and Classification-论文阅读笔记的主要内容,如果未能解决你的问题,请参考以下文章