计算机视觉中的深度学习2: 图片分类
Posted SuPhoebe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机视觉中的深度学习2: 图片分类相关的知识,希望对你有一定的参考价值。
计算机视觉中的深度学习2: 图片分类
Slides:百度云 提取码: gs3n
计算机与人眼的区别
对于一张灰度图片,计算机能看到的是像素大小的0~255的灰度值;对于RGB图片,则是一张像素大小的3通道矩阵,即800x600x3。
计算机视觉的挑战
- 视角变化的挑战
- 视角的变化带来的像素的变化是非常巨大的。
- 在不同的角度拍摄一只猫,人类很容易分辨这是同一种猫,而像素的变化却非常巨大,只有设计出了更加完备的算法才能让计算机程序更稳定地运行。
- 图片交叉的挑战
- 多只猫会重叠在一起。
- 粒度更细的分类
- 我们不仅仅需要分辨这是猫,我们还要分辨这是哪一个品种的猫。
- 杂乱的背景的影响
- 光线的变化
- 形状的变化
图片分类的作用
- 用在别的计算机视觉应用中
- Object detection
- Image captioning
图片分类的算法
- 传统计算机视觉算法
- 检测边缘,检测夹角等等
- 缺点:不够通用,当我们输入了一个非常复杂的算法能够识别猫了,同样的算法没法解决一个识别狗的问题。
- 机器学习方法
- 依赖数据源和分类器来进行识别
- 几个著名的数据集:
- MNIST:手写数字识别,10类
- CIFAR10:更大的RGB数据集,10类
- CIFAR100:同上,但有100类
- ImageNet:1000类,更大的数据集;广泛用于论文中
- MIT Places: 365类
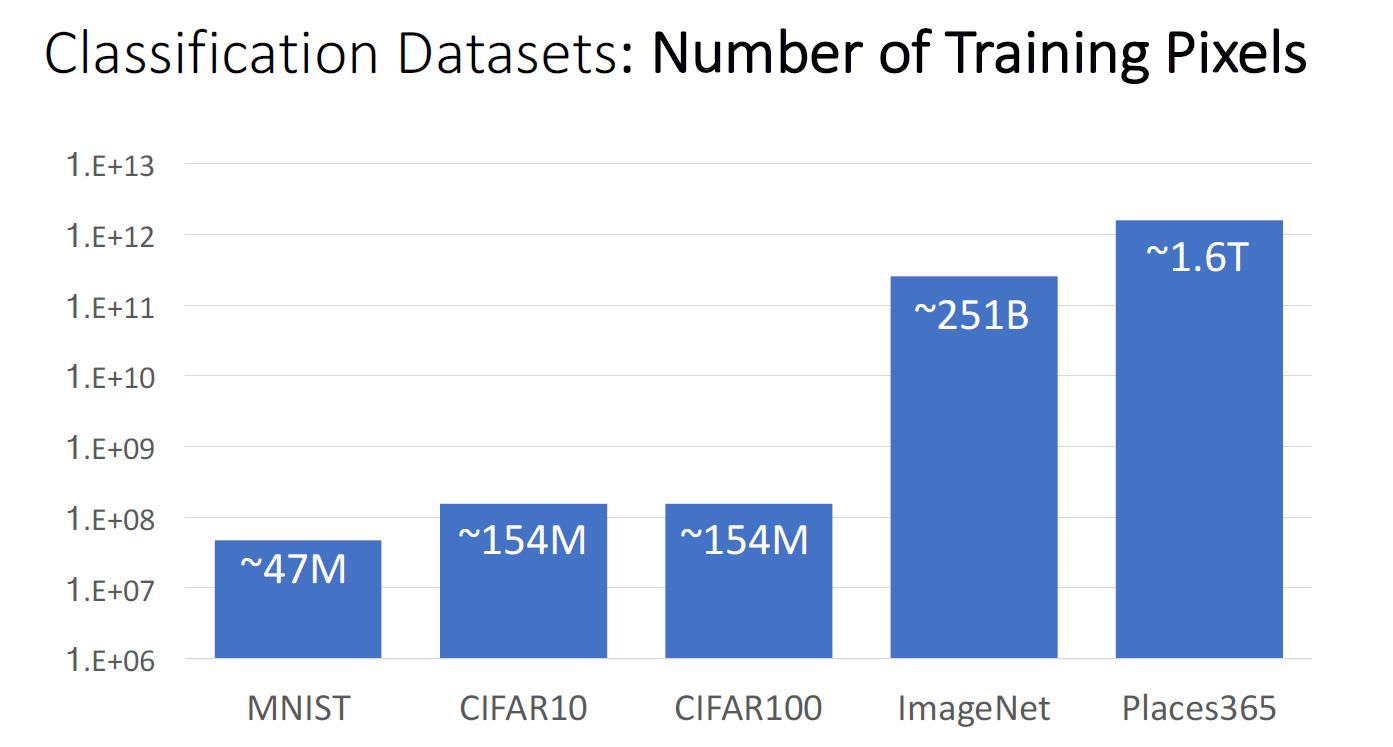
- 训练集中用于训练的像素个数
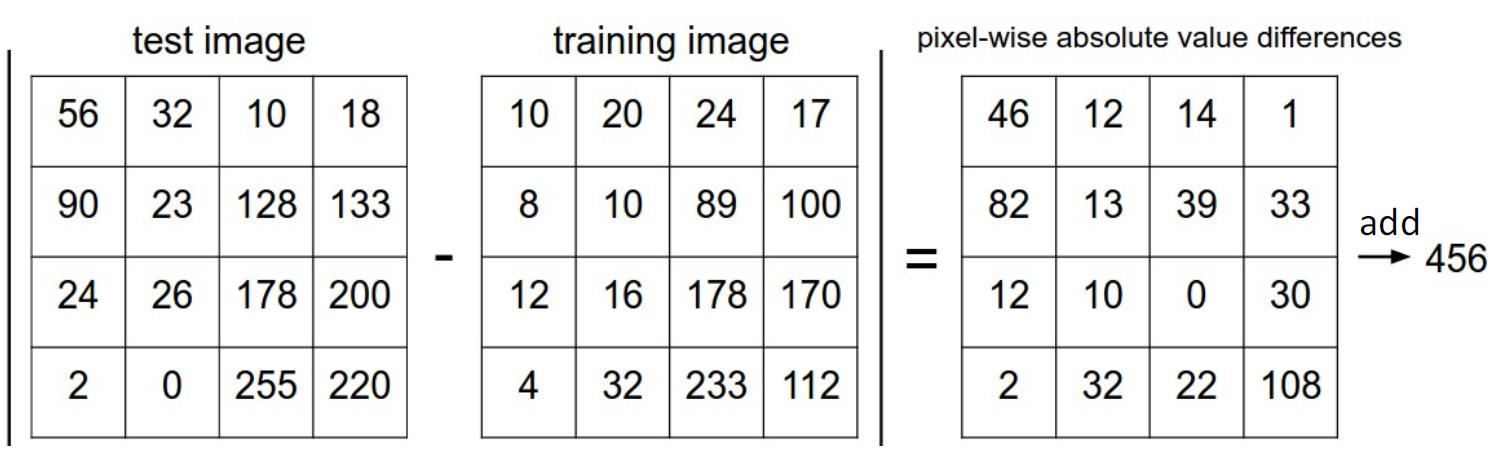
Nearest Neighbor
- 计算L1距离
- 选出距离需要预测的图片最近的那个图片的类型
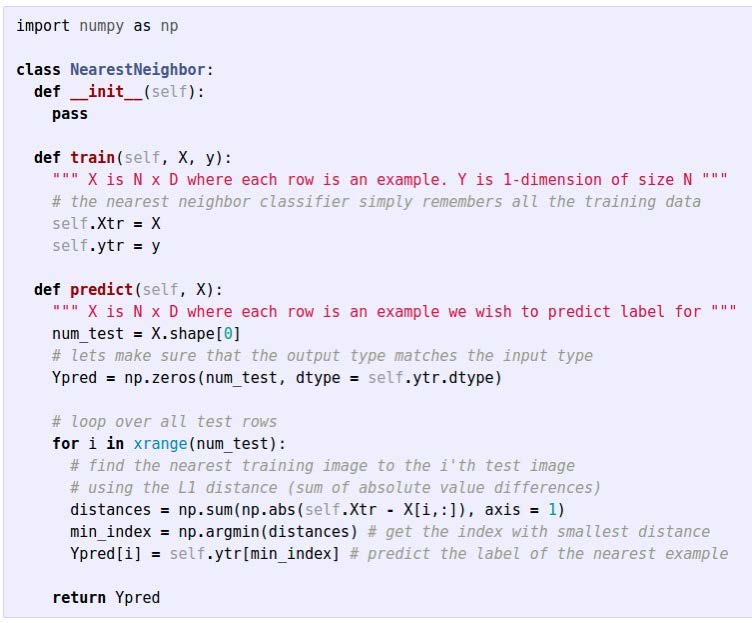
训练时间O(1),预测时间O(N)。
缺点:
- 预测的速度太慢了。我们希望能够花更多时间在训练上,而不是预测上。
- 选出的类是总体来看长得非常相似的图片,而不是相似的图片上的物体。
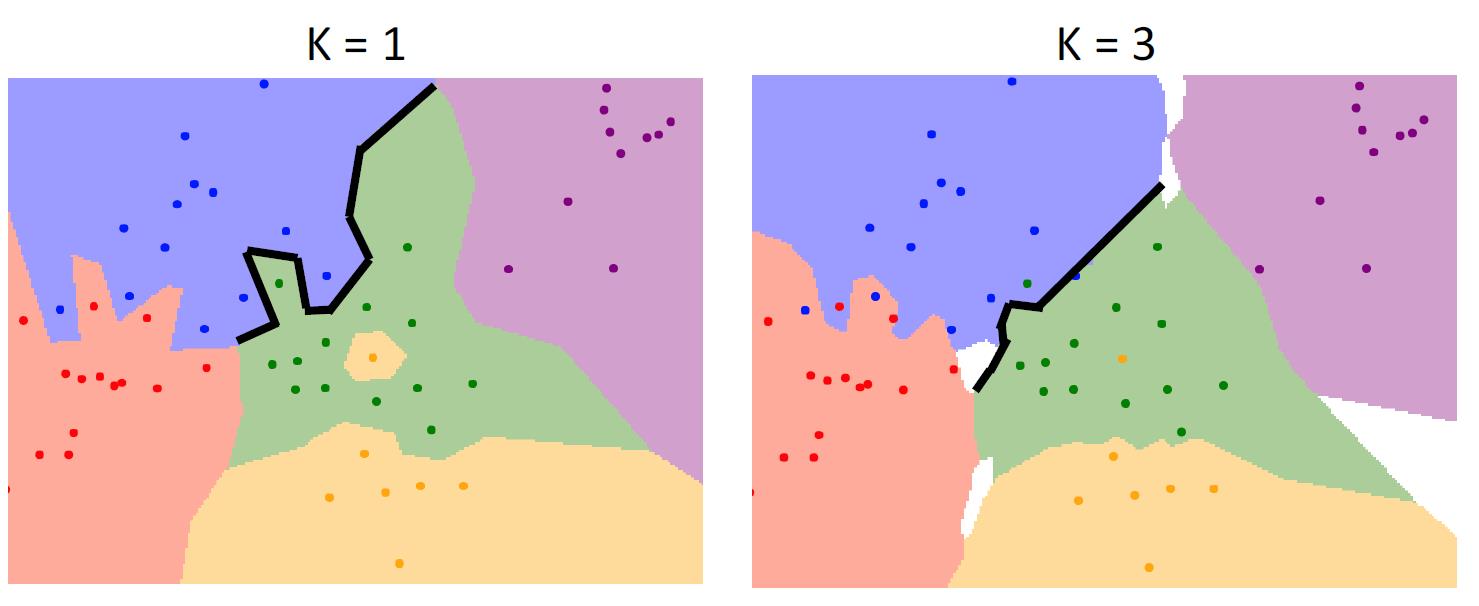
K Nearest Neighbor
第一种算法是k=1的情况,在outlier上有着更糟糕的表现,因为一旦训练集有一些outlier,将会极大地影响边缘处的表现
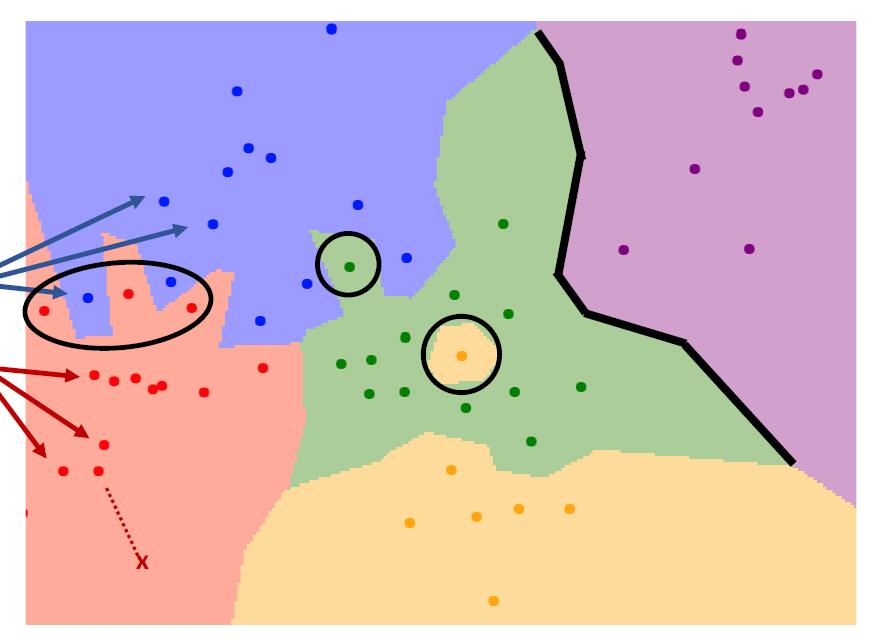
当我们使用k=3时,我们有了更加平滑的分界线,也有了更加健壮的处理outlier的情况。
使用不同的距离计算方式
- L1距离
- L2距离(欧拉距离)
- 对于特殊的数据集,采用特殊的距离计算方式,可能会比传统距离计算方式有更优秀的结果。
- 例如,用tf-idf similarity来比较研究论文使用
超参数
不能通过训练来学习的得到的参数,需要借用人类的知识去设置。(但是不排除通过别的神经网络来训练获得另一个神经网络的超参数。)
网络上所谓的调参工程师,其实也就是通过不断地训练,验证来获得最好的超参数,最终在测试集上面进行测试。
另类的Nearest Neighbor
- 结合ConvNet
- 通过ConvNet提取出图片的特征,比如,一个数组表示不同的特征值
- 再对这个特征值数组采用Nearest Neighbor算法,效果非常好
总结
- 在图像分类中,我们从图像和标签的训练集开始,并且必须在测试集上预测标签。
- 由于人类视觉和计算机视觉上的差距,图像分类具有挑战性:我们需要对遮挡,变形,光照,类内变异等保持不变。
- 图像分类是其他视觉任务的基础。
- K最近邻居分类器基于最近的训练示例预测标签距离度量和K是超参数。使用验证集选择超参数;最后只在测试集上运行一次!
以上是关于计算机视觉中的深度学习2: 图片分类的主要内容,如果未能解决你的问题,请参考以下文章