Linux高性能服务器程序框架
Posted Jqivin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux高性能服务器程序框架相关的知识,希望对你有一定的参考价值。
首先,按照服务器程序的一般原理,将服务器解构为如下三个主要模块:
- I/O处理单元——介绍I/O处理单元的四种I/O模型和两种高效事件处理模式。
- 逻辑单元——介绍两种高效并发模式,以及高效的逻辑处理方式(有限状态机)。
- 存储单元——不做讨论。
一、 服务器模型
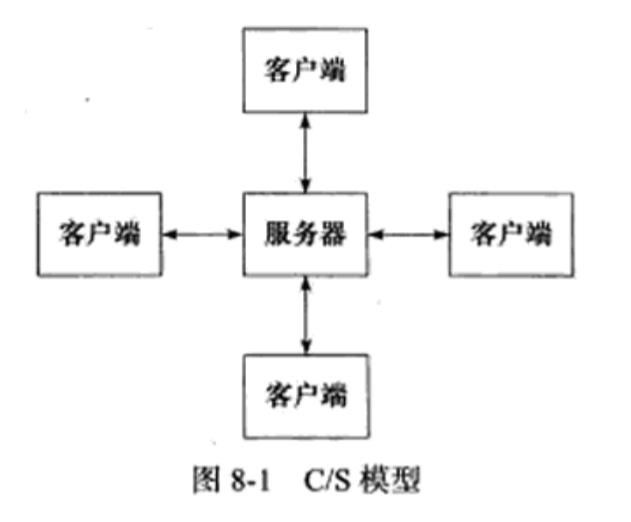
1. C/S模型:
TCP/IP协议在设计和实现上并没有客户端和服务器的概念,在通信过程中所有机器都是对等的。但由于资源(视频、新闻、软件等)都被数据提供者所垄断,所以几乎所有的网络应用程序都很自然地采用了C/S 模型:所有客户端都通过访问服务器来获取所需的资源。
工作流程:
- 服务器启动后,首先创建一个(或多个)监听socket。
- 再调用bind函数将其绑定到服务器感兴趣的端口上。
- 然后调用listen函数等待客户连接。
- 服务器稳定运行之后,客户端就可以调用connect函数向服务器发起连接了。
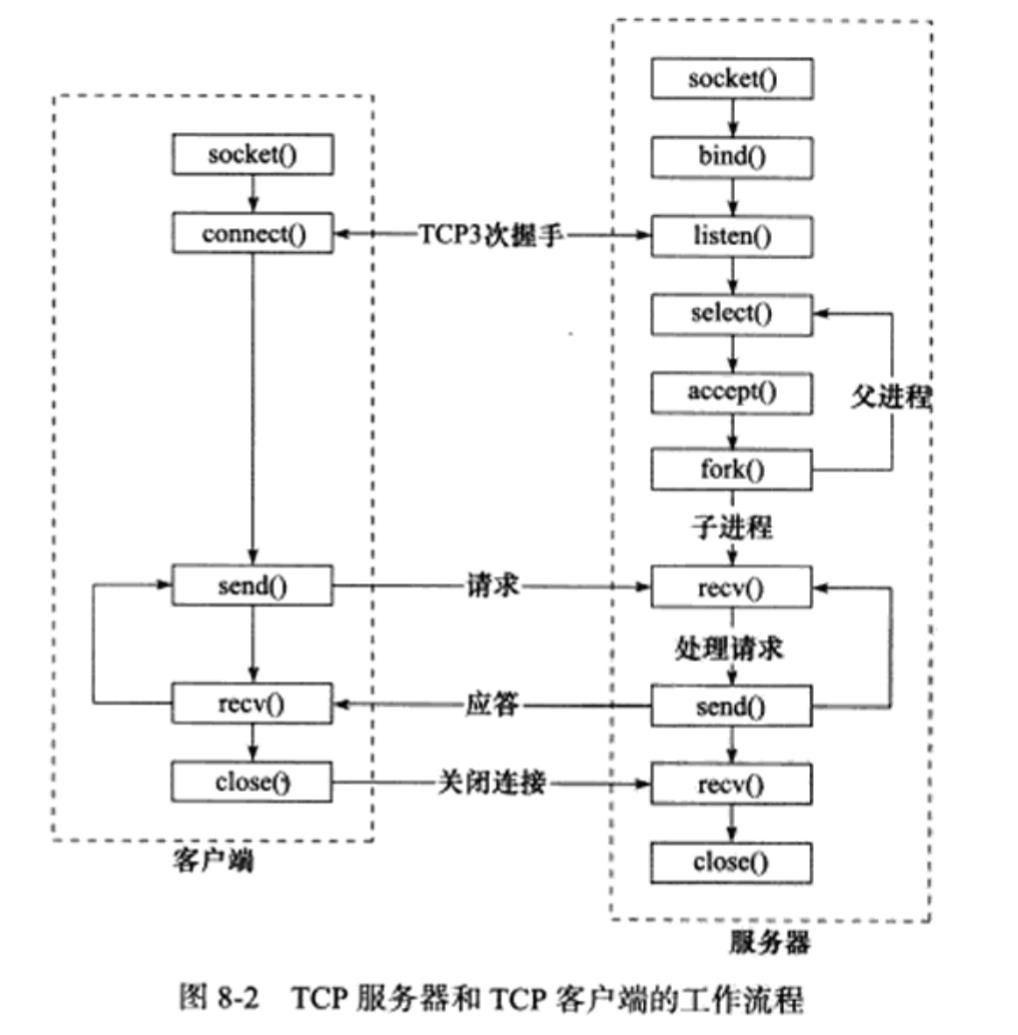
I/O模型:
- 由于客户连接请求是随机到达的异步事件,服务器需要使用某种I/O模型来监听这一事件。
- I/O模型有多种,图8-2中,服务器使用的是I/O复用技术之一的select系统调用。当监听到连接请求后,服务器就调用accept函数接受它,并分配一个逻辑单元为新的连接服务。
- 服务器在处理一个 客户请求的同时还会继续监听其他客户请求。
逻辑单元:
- 逻辑单元可以是新创建的子进程、子线程或者其他。图8-2中,服务器给客户端分配的逻辑单元是由fork系统调用创建的子进程。
- 逻辑单元读取客户请求,处理该请求,然后将处理结果返回给客户端。客户端接收到服务器反馈的结果之后,可以继续向服务器发送请求,也可以立即主动关闭连接。
- 如果客户端主动关闭连接,则服务器执行被动关闭连接,双方的通信结束。
总结:
优点:C/S模型非常适合资源集中的场合,实现也很简单。
缺点:服务器是通信的中心,访问量过大时,可能所有客户都响应很慢。
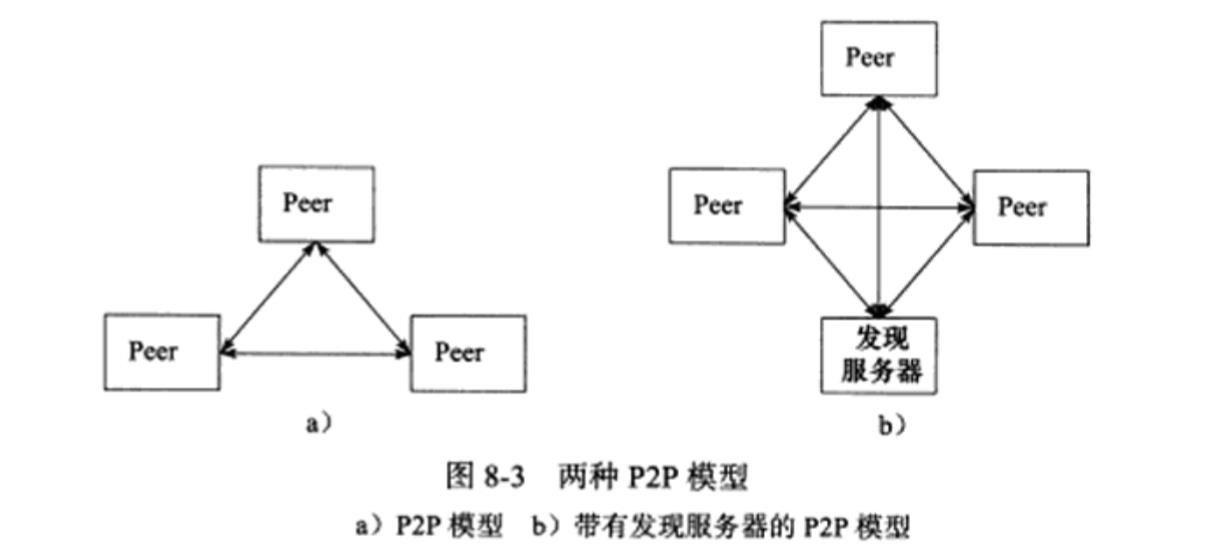
2. P2P模型:
P2P (Peer to Peer,点对点)模型比C/S模型更符合网络通信的实际情况。
它摒弃了以服务器为中心的格局,让网络上所有主机重新回归对等的地位。
P2P模型使得每台机器在消耗服务的同时也给别人提供服务,资源能够充分、自由地共享。
云计算机群可以看作P2P模型的一个典范。
P2P模型的缺点:
- 当用户之间传输的请求过多时,网络的负载将加重,主机之间很难互相发现。
实际改进:
- 实际使用的P2P模型通常带有一个专门的发现服务器。
- 发现服务器通常还提供查找服务(甚至还可以提供内容服务),使每个客户都能尽快地找到自己需要的资源。
二、服务器编程框架
下图既可以描述一台服务器,也可以描述一个服务器机群。
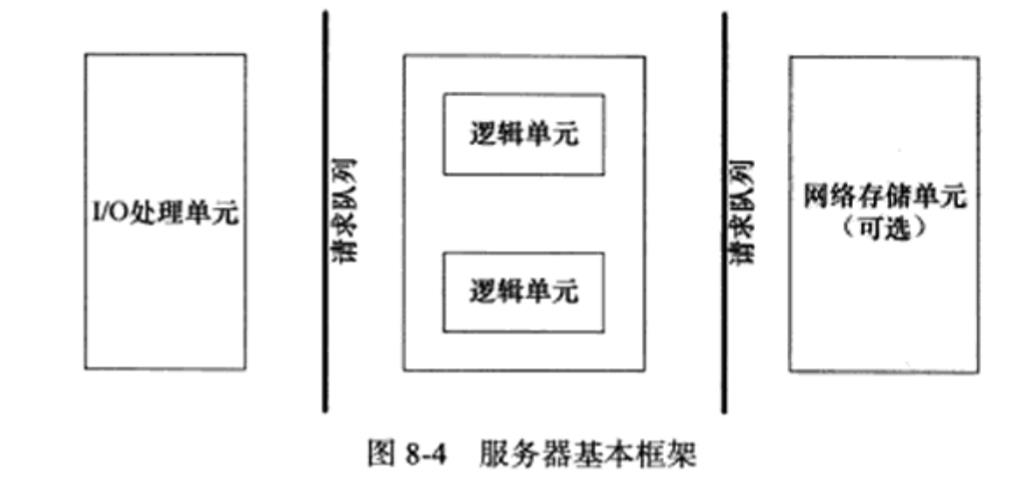
服务器基本模块的功能描述:
| 模块 | 单个服务器程序 | 服务器机群 |
| I/O处理单元 | 处理客户连接,读写网络数据 | 作为接入服务器,实现负载均衡 |
| 逻辑单元 | 业务进程或线程 | 逻辑服务器 |
| 网络存储单元 | 本地数据库、文件或缓存 | 数据库服务器 |
| 请求队列 | 各单元之间的通信方式 | 各服务器之间的永久TCP连接 |
1. I/O处理单元是服务器管理客户连接的模块,它通常要完成以下工作:
- 等待并接受新的客户连接,接收客户数据,将服务器响应数据返回给客户端。
- 数据的收发不一定在I/O处理单元中执行,也可能在逻辑单元中执行,具体在何处执行取决于事件处理模式。
- 对于一个服务器机群来说,I/O 处理单元是一个专门的接入服务器,它实现负载均衡,从所有逻辑服务器中选取负荷最小的一台来为新客户服务。
2. 逻辑单元通常是一个进程或线程。
- 它分析并处理客户数据,然后将结果传递给I/O处理单元或者直接发送给客户端(具体使用哪种方式取决于事件处理模式)。
- 对服务器机群而言,一个逻辑单元本身就是一台逻辑服务器。服务器通常拥有多个逻辑单元,以实现对多个客户任务的并行处理。
3. 网络存储单元可以是数据库、缓存和文件,甚至是一台独立的服务器。但它不是必须的,比如ssh、telnet 等登录服务就不需要这个单元。
4.请求队列是各单元之间的通信方式的抽象。
- I/O 处理单元接收到客户请求时,需要以某种方式通知一个逻辑单元来处理该请求。
- 多个逻辑单元同时访问一个存储单元时,也需要采用某种机制来协调处理竞态条件。
- 请求队列通常被实现为池的一部分。
- 对于服务器机群而言,请求队列是各台服务器之间预先建立的、静态的、永久的TCP连接。这种TCP连接能提高服务器之间交换数据的效率,因为它避免了动态建立TCP连接导致的额外的系统开销。
三、IO模型
阻塞I/O(阻塞的文件描述符):
- 执行的系统调用可能因为无法立即完成而被操作系统挂起,直到等待的事件发生为止。
- 比如,客户端通过connect向服务器发起连接时,connect将首先发送同步报文段给服务器,然后等待服务器返回确认报文段。
- 如果服务器的确认报文段没有立即到达客户端,则connect调用将被挂起,直到客户端收到确认报文段并唤醒connecct调用。
- socket 的基础API中,可能被阻塞的系统调用包括accept、send、 recv 和connect。
非阻塞I/O(非阻塞的文件描述符):
- 执行的系统调用则总是立即返回,而不管事件是否已经发生,如果事件没有立即发生,这些系统调用就返回-1,和出错的情况一样。
- 此时我们必须根据errno来区分这两种情况。
- 对accept,send和recv而言,事件未发生时ermo通常被设置成EAGAIN (意为“再来一次")或者EWOULDBLOCK (意为“期望阻塞”);
- 对conneet而言,ermo 则被设置成EINPROGRESS (意为“在处理中”)。
很显然,我们只有在事件已经发生的情况下操作非阻塞I/0 (读、写等),才能提高程序的效率。因此,非阻塞I/0通常要和其他I/O通知机制一起使用,比如I/0复用和SIGIO信号。
I/O复用:
- 是最常使用的I/O通知机制,它指的是,应用程序通过I/O复用函数向内核注册一组事件,内核通过I/O复用函数把其中就绪的事件通知给应用程序。
- Linux 上常用的I/O复用函数是select、poll 和epoll wait。
- I/O 复用函数本身是阻塞的,它们能提高程序效率的原因在于它们具有同时监听多个I/O事件的能力。
SIGIO信号:
- 也可以用来报告I/O事件。
- 我们可以为一个目标文件描述符指定宿主进程,那么被指定的宿主进程将捕获到SIGIO信号。
- 这样,当目标文件描述符上有事件发生时,SIGIO 信号的信号处理函数将被触发,我们也就可以在该信号处理函数中对目标文件描述符执行非阻塞I/O操作了。
从理论上说,阻塞I/O、I/O 复用和信号驱动I/O都是同步I/O模型,因为在这三种I/O模型中,I/O 的读写操作,都是在I/O事件发生之后,由应用程序来完成的。
而POSIX规范所定义的异步I/O模型则不同。
- 对异步I/O而言,用户可以直接对I/O执行读写操作,这些操作告诉内核用户读写缓冲区的位置,以及I/O操作完成之后内核通知应用程序的方式。
- 异步I/O的读写操作总是立即返回,而不论I/O是否是阻塞的,因为真正的读写操作已经由内核接管。
同步和异步的区别:
- 同步I/O模型要求用户代码自行执行I/O操作——将数据从内核缓冲区读入用户缓冲区,或将数据从用户缓冲区写人内核缓冲区
- 异步I/O机制则由内核来执行I/O操作——数据在内核缓冲区和用户缓冲区之间的移动是由内核在“后台”完成的。
- 可以这样理解:同步I/O向应用程序通知的是I/O就绪事件,而异步I/O向应用程序通知的是I/O完成事件。
I/O模型对比:
| I/O模型 | 读写操作和阻塞阶段 |
| 阻塞I/O | 程序阻塞于读写函数 |
| I/O复用 | 程序阻塞于I/O复用系统调用,但可同时监听多个I/O事件,对I/O本身的读写操作是非阻塞的。 |
| SIGIO信号 | 信号触发读写就绪事件,用户程序执行读写操作,程序没有阻塞阶段。 |
| 异步I/O | 内核执行读写操作并触发读写完成事件,程序没有阻塞阶段。 |
参考链接:同步IO、异步IO、阻塞IO、非阻塞IO之间的联系与区别
Linux高性能服务器编程
以上是关于Linux高性能服务器程序框架的主要内容,如果未能解决你的问题,请参考以下文章