Java集合总结Map篇
Posted 低调的洋仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java集合总结Map篇相关的知识,希望对你有一定的参考价值。
Map
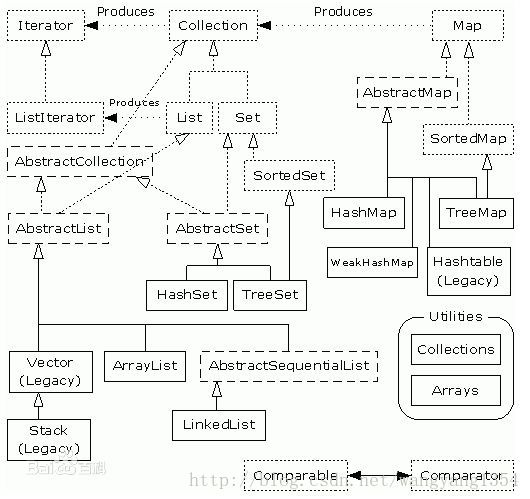
Map是一个接口属于键值对的总接口,也就是集合的另一个大阵营。 其派生的类包括AbstractMap、HashMap、Hashtable、IdentityHashMap、LinkedHashMap、WeakHashMap、ConcurrentHashMap、ConcurrentMap、SortedMap。 这个派系和Collection其实是差不多的,只不过区别在于Map这边直接实现map的比较多而不是直接抽象后进行实现,感觉可能是当初设计的时候可能没有考虑那么周到,将所有的问题都抽象出来。不过键值对这一块抽象可能比较麻烦,毕竟大家的实现策略不尽相同,而且花样蛮多的。AbstractMap
AbstractMap是Map接口的重要的骨架实现。提供了几个常见的实现类。这个类类似于AbstractCollection这个抽象类。ConcurrentHashMap
继承自AbstractMap这个抽象类,实现了ConcurrentMap以及Serializable接口。 线程安全的,用了分段锁的策略,将内部分割成多个段,然后对每个段进行锁定这样有利于并发。 static final class HashEntry<K,V>
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
static final class Segment<K,V> extends ReentrantLock implements Serializable
static final int MAX_SCAN_RETRIES = Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
Segment(float lf, int threshold, HashEntry<K,V>[] tab)
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
每个段中都有一个HashEntry的数组,这个数组与每个进入该段的值存在映射关系,他的每一项都是一个HashEntry的键值对,但是不要忘了,HashEntry中的定义本身就是单链表而不是仅仅指的一个元素而已,所以这个相当于三层的结构,第一层段的概念,进入段后在分数组中映射位置,映射到数组中某一个位置后,在这个位置上存在的是一个链表的形式。 其实这个地方的Segment就已经相当于HashMap的概念了,实现上而言基本一致,只不过在这里ConcurrentHashMap是再添加了一层段的概念。 如果对哈希表数据结构比较熟悉的话会知道,哈希表内部一般会有初始容量ic和加载因子lf,当哈希表中的元素数量达到(ic * lf)的时候,就会触发哈希表进行rehash。这有什么影响呢?假设哈希表使用链表法来解决哈希冲突,那么如果加载因子太大,会导致哈希表中每个桶里面的链表平均长度过长,这样会影响查询性能;但如果加载因子过小,又会浪费太多内存空间。所以也是一种时间和空间的权衡,需要按实际情况来选择合适的加载因子。在8里面已经解决了过长的问题,使用红黑树来解决,深度肯定小很多,查找明显要快很多。
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel)
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel)
++sshift;
ssize <<= 1;
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
public ConcurrentHashMap(int initialCapacity, float loadFactor)
this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL);
private int hash(Object k)
int h = hashSeed;
if ((0 != h) && (k instanceof String))
return sun.misc.Hashing.stringHash32((String) k);
h ^= k.hashCode();
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
private Segment<K,V> segmentForHash(int h)
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
return (Segment<K,V>) UNSAFE.getObjectVolatile(segments, u);
- final Segment<K,V> segmentFor(int hash)
- return segments[(hash >>> segmentShift) & segmentMask];
看下put怎么放进去值的。
public V put(K key, V value)
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
先hash了一次,调用上面提到的方法。 先计算其映射的segment对应的地址值,然后看意思返回这个地址处的这个Segment了。
private Segment<K,V> ensureSegment(int k)
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null)
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null)
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
return seg;
final V put(K key, int hash, V value, boolean onlyIfAbsent)
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;)
if (e != null)
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k)))
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
++modCount;
break;
e = e.next;
else
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
finally
unlock();
return oldValue;
/**
* Scans for a node containing given key while trying to
* acquire lock, creating and returning one if not found. Upon
* return, guarantees that lock is held. UNlike in most
* methods, calls to method equals are not screened: Since
* traversal speed doesn't matter, we might as well help warm
* up the associated code and accesses as well.
*
* @return a new node if key not found, else null
*/
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value)
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
while (!tryLock())
HashEntry<K,V> f; // to recheck first below
if (retries < 0)
if (e == null)
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
else if (++retries > MAX_SCAN_RETRIES)
lock();
break;
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first)
e = first = f; // re-traverse if entry changed
retries = -1;
return node;
重新计算Hash值 扩容为原来的两倍,这里扩容仅仅对Segment段内的表进行扩容而不是说所有的,然后这个地方扩容思路和HashMap差不多,基本上都是循环整个原来的数组中每个链表,重新计算hash值并进行映射,然后重新组建成一个链表放在最新的这个HashEntry的数组中。
/**
* Doubles size of table and repacks entries, also adding the
* given node to new table
*/
@SuppressWarnings("unchecked")
private void rehash(HashEntry<K,V> node)
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++)
HashEntry<K,V> e = oldTable[i];
if (e != null)
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
for (HashEntry<K,V> last = next;
last != null;
last = last.next)
int k = last.hash & sizeMask;
if (k != lastIdx)
lastIdx = k;
lastRun = last;
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next)
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
get方法获取想得到的这个值 先找到段,然后得到数组,得到数组中的映射,然后遍历整个链表知道找到这个key对应的value值。
public V get(Object key)
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null)
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next)
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
return null;
ConcurrentHashMap基本的原理差不多结束,但是8里面已经变了,需要进行对比,8里面换成了synchronized锁,加红黑树而不是单链表。 注意下他的size方法,需要锁住所有的段然后统计count的累加。
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creationsum += seg.modCount;ConcurrentSkipListMap
继承自AbstractMap抽象类,实现了ConcurrentNavigableMap、cloneable和Serializable。 线程安全的Map。 1. 是一种线程安全的有序map,有序map的话,不要求线程安全的话就用TreeMap但是要求线程安全的话就用ConcurrentSkipListMap,前提是要求有序的Map。 2. 内部的数据结构是SkipList,应该是跳跃表了。内部实现的entry之所以存在顺序是因为其实现了Comparator的Key来确定的,或者是由构造方法时指定了Comparator来保证的。时间复杂度是O(logn) * Head nodes Index nodes
* +-+ right +-+ +-+
* |2|---------------->| |--------------------->| |->null
* +-+ +-+ +-+
* | down | |
* v v v
* +-+ +-+ +-+ +-+ +-+ +-+
* |1|----------->| |->| |------>| |----------->| |------>| |->null
* +-+ +-+ +-+ +-+ +-+ +-+
* v | | | | |
* Nodes next v v v v v
* +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+
* | |->|A|->|B|->|C|->|D|->|E|->|F|->|G|->|H|->|I|->|J|->|K|->null
* +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+
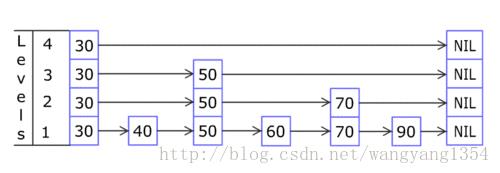 这里有个base-level的概念,这个base-level本身我认为应该是最底层的单链表,然后index会在其上面创建索引,这就是为什么求index的level的时候不允许是0的原因。
这里有个base-level的概念,这个base-level本身我认为应该是最底层的单链表,然后index会在其上面创建索引,这就是为什么求index的level的时候不允许是0的原因。
final void initialize()
keySet = null;
entrySet = null;
values = null;
descendingMap = null;
randomSeed = seedGenerator.nextInt() | 0x0100; // ensure nonzero 保证非零值
head = new HeadIndex<K,V>(new Node<K,V>(null, BASE_HEADER, null),
null, null, 1);
Node定义单链表
static final class Node<K,V>
final K key;
volatile Object value;
volatile Node<K,V> next;
*/
Node(K key, Object value, Node<K,V> next)
this.key = key;
this.value = value;
this.next = next;
/**
* Creates a new marker node. A marker is distinguished by
* having its value field point to itself. Marker nodes also
* have null keys, a fact that is exploited in a few places,
* but this doesn't distinguish markers from the base-level
* header node (head.node), which also has a null key.
*/
Node(Node<K,V> next)
this.key = null;
this.value = this;
this.next = next;
主要的属性。
private static final Random seedGenerator = new Random();// 随机数生成器
private static final Object BASE_HEADER = new Object();// 用于定义baselevel的头结点
private transient volatile HeadIndex<K,V> head; // 跳跃表最高层的head index
private final Comparator<? super K> comparator;// 比较器。如果没设置这个比较器,那么久用key的自然序来比较。
private transient int randomSeed;// 随机种子没有用volatile修饰,多个线程看到不同的值没关系
/** Lazily initialized key set */
private transient KeySet keySet;
/** Lazily initialized entry set */
private transient EntrySet entrySet;
/** Lazily initialized values collection */
private transient Values values;
/** Lazily initialized descending key set */
private transient ConcurrentNavigableMap<K,V> descendingMap; * Here's the sequence of events for a deletion of node n with
* predecessor b and successor f, initially:
*
* +------+ +------+ +------+
* ... | b |------>| n |----->| f | ...
* +------+ +------+ +------+
*
* 1. CAS n's value field from non-null to null.
* From this point on, no public operations encountering
* the node consider this mapping to exist. However, other
* ongoing insertions and deletions might still modify
* n's next pointer.
*
* 2. CAS n's next pointer to point to a new marker node.
* From this point on, no other nodes can be appended to n.
* which avoids deletion errors in CAS-based linked lists.
*
* +------+ +------+ +------+ +------+
* ... | b |------>| n |----->|marker|------>| f | ...
* +------+ +------+ +------+ +------+
*
* 3. CAS b's next pointer over both n and its marker.
* From this point on, no new traversals will encounter n,
* and it can eventually be GCed.
* +------+ +------+
* ... | b |----------------------------------->| f | ...
* +------+ +------+
/**
* Index nodes represent the levels of the skip list. Note that
* even though both Nodes and Indexes have forward-pointing
* fields, they have different types and are handled in different
* ways, that can't nicely be captured by placing field in a
* shared abstract class.
*/
static class Index<K,V>
final Node<K,V> node;
final Index<K,V> down;
volatile Index<K,V> right; public ConcurrentSkipListMap()
this.comparator = null;
initialize();
public ConcurrentSkipListMap(Comparator<? super K> comparator)
this.comparator = comparator;
initialize();
/**
* Initializes or resets state. Needed by constructors, clone,
* clear, readObject. and ConcurrentSkipListSet.clone.
* (Note that comparator must be separately initialized.)
*/
final void initialize()
keySet = null; // 内部域置为空的
entrySet = null;
values = null;
descendingMap = null;
randomSeed = seedGenerator.nextInt() | 0x0100; // ensure nonzero 确保非0的,生成随机的种子用于生成随机数
head = new HeadIndex<K,V>(new Node<K,V>(null, BASE_HEADER, null),
null, null, 1);// 创建了一个头结点,该节点value是Base_head,level是1
public V put(K key, V value)
if (value == null)
throw new NullPointerException();
return doPut(key, value, false);
真正的插入方法
private V doPut(K kkey, V value, boolean onlyIfAbsent)
// 将key转为可比较的key
Comparable<? super K> key = comparable(kkey);
for (;;)
// 通过key找到要插入的位置的前驱节点,这个节点在base_level上
Node<K,V> b = findPredecessor(key);
Node<K,V> n = b.next;
for (;;)
if (n != null)
Node<K,V> f = n.next;
// 检测下如果不一致说明发送了更改,下一次进行尝试
if (n != b.next) // inconsistent read
break;
Object v = n.value;
// v是空的那么就删除n替换为f
if (v == null)
// n is deleted
// 如果没进行标记就先进行标记,不删除,如果标记了,那么就直接删除n和其next
n.helpDelete(b, f);
break;
if (v == n || b.value == null) // b is deleted
break;
int c = key.compareTo(n.key);
if (c > 0)
// 说明了要存储的值比当前的值大了,所以继续向后比较
b = n;
n = f;
continue;
if (c == 0)
// 当她相等的时候如果onlyIfAbsent为true,那么不进行替换
// 否则需要覆盖旧值
if (onlyIfAbsent || n.casValue(v, value))
return (V)v;
else
break; // restart if lost race to replace value 覆盖时竞争失败,重试
// else c < 0; fall through
// 构造一个新的节点
Node<K,V> z = new Node<K,V>(kkey, value, n);
// 尝试插入z在b和n之间,插入失败就重新尝试
if (!b.casNext(n, z))
break; // restart if lost race to append to b
// 随机生成一个level(不超过31)
int level = randomLevel();
if (level > 0)
// 随机选取的这level上面插入索引
insertIndex(z, level);
return null;
大概描述一下put方法(里面的一些细节后面分析):
1.首先要找出当前节点(其实还没有节点,这里只是给定的key和value)在Node链表(注意这个链表是图中最下层的部分,也就是base-level)中的前驱节点。
2.然后从前驱节点往后找到要插入的位置,进行插入。
3.插入成功后,可能会生成一个层级作为其索引,百分之五十的机会生成0的,所以大部分的数据不会进行索引,只有一少部分的数据索引。
* 50%几率返回0,25%的几率返回1,12.5%的几率返回的是2。。。。最大的返回31
*/
private int randomLevel()
int x = randomSeed;
x ^= x << 13;
x ^= x >>> 17;
randomSeed = x ^= x << 5;
if ((x & 0x80000001) != 0) // test highest and lowest bits
return 0;
int level = 1;
while (((x >>>= 1) & 1) != 0) ++level;
return level;
再次更细致的总结一下put方法:
1.首先要根据给定的key找出在base_level链表中对应的前驱节点(从结构图的左上角往右或往下一路找过来),注意put方法使用的log(n)时间主要体现在这个过程,这个查找过程中会顺便帮忙推进一些节点的删除。
2.找到前驱节点后,然后从这个前驱节点往后找到要插入的位置(注意当前已经在base_level上,所以只需要往后找),这个查找过程中也会顺便帮忙推进一些节点的删除。。
3.找到了要插入的位置,尝试插入,如果竞争导致插入失败,返回到第1步重试;如果插入成功,接下来会随机生成一个level,如果这个level大于0,需要将插入的节点在垂直线上生成level(level<=maxLevel + 1)个Index节点。
查找元素
public V get(Object key)
return doGet(key);
private V doGet(Object okey)
Comparable<? super K> key = comparable(okey);
/*
* Loop needed here and elsewhere in case value field goes
* null just as it is about to be returned, in which case we
* lost a race with a deletion, so must retry.
*/
for (;;)
Node<K,V> n = findNode(key); // 查找节点,在上面insert的时候就使用了findNode这个方法
if (n == null)
return null;
Object v = n.value;
if (v != null)
return (V)v;
public V put(K key, V value) if (table == EMPTY_TABLE) inflateTable(threshold); if (key == null) return putForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; modCount++; addEntry(hash, key, value, i); return null;
查找节点,这个问题应该说稍微简单些。
private Node<K,V> findNode(Comparable<? super K> key)
for (;;)
Node<K,V> b = findPredecessor(key);
Node<K,V> n = b.next;
for (;;)
if (n == null)
return null;
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read 说明存在不一致的情况,其他线程可能进行了更改。
break;
Object v = n.value;
if (v == null) // n is deleted 助推删除节点
n.helpDelete(b, f);
break;
if (v == n || b.value == null) // b is deleted
break;
int c = key.compareTo(n.key);
if (c == 0)
return n; // 找到了这个key对应分值且是相等的情况下
if (c < 0)
return null;
b = n; // 相当于b = b.next;
n = f; // 相当于n = n.next;
注意
/**
* Initializes or resets state. Needed by constructors, clone,
* clear, readObject. and ConcurrentSkipListSet.clone.
* (Note that comparator must be separately initialized.)
*/
final void initialize()
keySet = null;
entrySet = null;
values = null;
descendingMap = null;
randomSeed = seedGenerator.nextInt() | 0x0100; // ensure nonzero
head = new HeadIndex<K,V>(new Node<K,V>(null, BASE_HEADER, null),
null, null, 1);
BASE_HEADER用于区分其他的节点,key是null的,然后value也是null的,HeadIndex
Index(Node<K,V> node, Index<K,V> down, Index<K,V> right)
this.node = node;
this.down = down;
this.right = right;
HashMap
HashMap继承自AbstractMap抽象类,实现了Map、Serializable、Cloneable接口。
默认的容量是16,增长因子是0.75。
hash值是在原来hashcode的基础上进而计算得到的。
final int hash(Object k)
int h = hashSeed;
if (0 != h && k instanceof String)
return sun.misc.Hashing.stringHash32((String) k);
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
static int indexFor(int h, int length)
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
这里比较有意思的地方是,调整这个初始化值并不是在创建的时候调整的,而是真正使用的时候调整了,实际上算是一种改进,推迟到使用的时候调整,然后inflateTable就是用来保证2的次幂的。记得在6里面实际上是在创建这个实例的时候就直接进行调整了。
public V put(K key, V value)
if (table == EMPTY_TABLE)
inflateTable(threshold);
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next)
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
modCount++;
addEntry(hash, key, value, i);
return null;
while (newCapacity < targetCapacity)
newCapacity <<= 1;
if (newCapacity > table.length)
resize(newCapacity);
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash)
int newCapacity = newTable.length;
for (Entry<K,V> e : table)
while(null != e)
Entry<K,V> next = e.next;
if (rehash)
e.hash = null == e.key ? 0 : hash(e.key);
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
LinkedHashMap
继承自HashMap实现了Map接口。
这个类是自己重新定义了一个双向的链表当然这个Entry也是继承自HashMap.Entry这个类,然后里面加了俩对象一个就是before一个就是after,如此生成一个双向的链表,但是这里需要注意的是原来的hashmap的结构依旧是完整的,因为每次不管插入数据还是删除数据等都会优先调用父类的方法,也就是说HashMap中的桶加链表的结构依然是存在的,只不过在这里该类实现了额外的一个双向链表将所有的数据进行串联,保证了数据插入的时候的顺序。双向链表的头结点header节点内部有before和after两个指针来指向链表的结束和开始。-----以下如果与此冲突以此处为准。
private static class Entry<K,V> extends HashMap.Entry<K,V>
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
只是覆盖了父类的节点的定义,HashMap用的是单链表,这里用的是双向链表,然后还有一个遍历的过程来提升效率。
void transfer(HashMap.Entry[] newTable, boolean rehash)
int newCapacity = newTable.length;
for (Entry<K,V> e = header.after; e != header; e = e.after)
if (rehash)
e.hash = (e.key == null) ? 0 : hash(e.key);
int index = indexFor(e.hash, newCapacity);
e.next = newTable[index];
newTable[index] = e;
IdentityHashMap
继承自AbstractMap抽象类,实现了Map、Serializable、Cloneable。
默认的容量32,最小的容量4。
要保证必须是2的次幂,负载因子2/3。扩容机制为原来的2倍。
private int capacity(int expectedMaxSize)
// Compute min capacity for expectedMaxSize given a load factor of 2/3
int minCapacity = (3 * expectedMaxSize)/2;
// Compute the appropriate capacity
int result;
if (minCapacity > MAXIMUM_CAPACITY || minCapacity < 0)
result = MAXIMUM_CAPACITY;
else
result = MINIMUM_CAPACITY;
while (result < minCapacity)
result <<= 1;
return result;
private void init(int initCapacity)
// assert (initCapacity & -initCapacity) == initCapacity; // power of 2
// assert initCapacity >= MINIMUM_CAPACITY;
// assert initCapacity <= MAXIMUM_CAPACITY;
threshold = (initCapacity * 2)/3;
table = new Object[2 * initCapacity];
IdentityHashMap中会调用System.identityHashCode(x)来获得对象的hashCode(也就是对象的hashCode方法没有被覆盖情况下的返回值),仅用“==”来进行后面key的比较。
根据System的identityHashCode来计算其hashCode值的
private static int hash(Object x, int length)
int h = System.identityHashCode(x);
// Multiply by -127, and left-shift to use least bit as part of hash
return ((h << 1) - (h << 8)) & (length - 1);
/**
* Circularly traverses table of size len.
*/
private static int nextKeyIndex(int i, int len)
return (i + 2 < len ? i + 2 : 0);
private static final int MAXIMUM_CAPACITY = 1 << 29这里为什么是29次方而不是30次方了呢?
这里看init,注意乘以2了!
private void init(int initCapacity)
// assert (initCapacity & -initCapacity) == initCapacity; // power of 2
// assert initCapacity >= MINIMUM_CAPACITY;
// assert initCapacity <= MAXIMUM_CAPACITY;
threshold = (initCapacity * 2)/3;
table = new Object[2 * initCapacity];
key放在偶数位置,而value放在了奇数的位置上。
public V get(Object key)
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
while (true)
Object item = tab[i];
if (item == k)
return (V) tab[i + 1];
if (item == null)
return null;
i = nextKeyIndex(i, len);
public V put(K key, V value)
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
Object item;
while ( (item = tab[i]) != null)
if (item == k)
V oldValue = (V) tab[i + 1];
tab[i + 1] = value;
return oldValue;
i = nextKeyIndex(i, len);
modCount++;
tab[i] = k;
tab[i + 1] = value;
if (++size >= threshold)
resize(len); // len == 2 * current capacity.
return null;
public V remove(Object key)
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
while (true)
Object item = tab[i];
if (item == k)
modCount++;
size--;
V oldValue = (V) tab[i + 1];
tab[i + 1] = null;
tab[i] = null;
closeDeletion(i);
return oldValue;
if (item == null)
return null;
i = nextKeyIndex(i, len);
private void closeDeletion(int d)
// Adapted from Knuth Section 6.4 Algorithm R
Object[] tab = table;
int len = tab.length;
// Look for items to swap into newly vacated slot
// starting at index immediately following deletion,
// and continuing until a null slot is seen, indicating
// the end of a run of possibly-colliding keys.
Object item;
for (int i = nextKeyIndex(d, len); (item = tab[i]) != null;
i = nextKeyIndex(i, len) )
// The following test triggers if the item at slot i (which
// hashes to be at slot r) should take the spot vacated by d.
// If so, we swap it in, and then continue with d now at the
// newly vacated i. This process will terminate when we hit
// the null slot at the end of this run.
// The test is messy because we are using a circular table.
int r = hash(item, len);
if ((i < r && (r <= d || d <= i)) || (r <= d && d <= i))
tab[d] = item;
tab[d + 1] = tab[i + 1];
tab[i] = null;
tab[i + 1] = null;
d = i;
EnumMap
EnumMap继承自AbstractMap实现了Serializable接口,Cloneable接口。
public class EnumMap<K extends Enum<K>, V> extends AbstractMap<K, V>
implements java.io.Serializable, Cloneable
public V put(K key, V value)
typeCheck(key);
int index = key.ordinal();
Object oldValue = vals[index];
vals[index] = maskNull(value);
if (oldValue == null)
size++;
return unmaskNull(oldValue);
它的大小是size,就是Enum的size了,然后通过他来创建出数组,然后这个数组的大小不需要扩容了。
public boolean containsKey(Object key)
return isValidKey(key) && vals[((Enum)key).ordinal()] != null;
WeakHashMap
继承自AbstractMap实现了Map接口。
private static final int DEFAULT_INITIAL_CAPACITY = 16;
private static final int MAXIMUM_CAPACITY = 1 << 30;
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
Entry<K,V>[] table;
private int size;
private int threshold;
private final float loadFactor;
private final ReferenceQueue<Object> queue = new ReferenceQueue<>();
int modCount;
private void expungeStaleEntries()
for (Object x; (x = queue.poll()) != null; )
synchronized (queue)
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) x;
int i = indexFor(e.hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> p = prev;
while (p != null)
Entry<K,V> next = p.next;
if (p == e)
if (prev == e)
table[i] = next;
else
prev.next = next;
// Must not null out e.next;
// stale entries may be in use by a HashIterator
e.value = null; // Help GC
size--;
break;
prev = p;
p = next;
软引用 SoftReference
软引用在内存不充足的时候直接被回收掉。
强引用
在内存不足的时候直接抛出OOM而不会回收除非已经没有引用了。
这样保证了虚引用的关联对象永远不可能通过get方法再次获得强引用。但虚引用的关联对象要一直等到虚引用本身不可达或者被回收时才能够被回收,这点不同于软引用和弱引用。
最后说一下java.lang.ref.ReferenceQueue。ReferenceQueue是一个引用队列,构造一个软引用、弱引用或者虚引用可以传入一个ReferenceQueue,表示这个引用注册到传入的引用队列上,简单的说,当GC决定回收引用关联对象时,会将这个引用放到引用队列里。
TreeMap
继承自AbstractMap实现了NavigableMap,Cloneable和Serializable接口。
红黑树的原理:
https://tech.meituan.com/redblack-tree.html
http://brokendreams.iteye.com/blog/2268288
基本的树的定义为
static final class Entry<K,V> implements Map.Entry<K,V>
K key;
V value;
Entry<K,V> left = null;
Entry<K,V> right = null;
Entry<K,V> parent;
boolean color = BLACK;
红黑树并不能够像AVL那样较为稳定的维持一个较为稳定的树的深度,红黑树的这些定义基本上可以满足左右子树的高度差不是另一侧的两倍。
其主要的定义要求:
RBTree的定义如下:
1.任何一个节点都有颜色,黑色或者红色
2.根节点是黑色的
3.父子节点之间不能出现两个连续的红节点
4.任何一个节点向下遍历到其子孙的叶子节点,所经过的黑节点个数必须相等
5.空节点被认为是黑色的
注意:有的说法中是认为叶子节点是黑色的,那么这里的空节点实际上就是他们称为的叶子节点。
插入的过程基本上就是二叉搜索树的查找并插入的过程,但是插入的时候因为是红色的节点进行插入的,所以可能需要进行调整。
public V put(K key, V value)
Entry<K,V> t = root;
if (t == null)
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null)
do
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
while (t != null);
else
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
do
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
while (t != null);
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
插入完成后对整个红黑树进行调整,调用fixAfterInsertion()方法。
/** From CLR */
private void fixAfterInsertion(Entry<K,V> x)
x.color = RED;
while (x != null && x != root && x.parent.color == RED)
// 父节点是祖父节点的左侧子节点
if (parentOf(x) == leftOf(parentOf(parentOf(x))))
// 右侧的兄弟节点
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
// 1
// 当这个兄弟节点的颜色是红色的时候
if (colorOf(y) == RED)
// 当前一个红色的,父节点是红色的,然后兄弟节点也是红色的情况
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
// 兄弟节点是黑色的时候
else
// 2
if (x == rightOf(parentOf(x))) // X是父节点的右侧子节点,然后其父节点的兄弟节点是黑色的
x = parentOf(x);
rotateLeft(x); // 设置x为父亲节点,并进行旋转,旋转的时候是将右侧子节点旋转到父亲节点的位置,然后就形成了左侧的这边俩红色的
// 设置父亲节点为黑色的
setColor(parentOf(x), BLACK);
// 设置祖父节点为红色的
setColor(parentOf(parentOf(x)), RED);
// 右旋,使得父亲节点上升为祖父节点,然后祖父节点变为父亲节点的子节点
rotateRight(parentOf(parentOf(x)));
// 父节点不是祖父节点的左侧节点
else
// 获取左侧的父节点的兄弟节点
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
// 当这个兄弟节点的颜色是红色的
if (colorOf(y) == RED)
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
// 兄弟节点的颜色是黑色的
else
if (x == leftOf(parentOf(x)))
x = parentOf(x);
rotateRight(x);
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
root.color = BLACK; // 最后将root的color设置成黑色
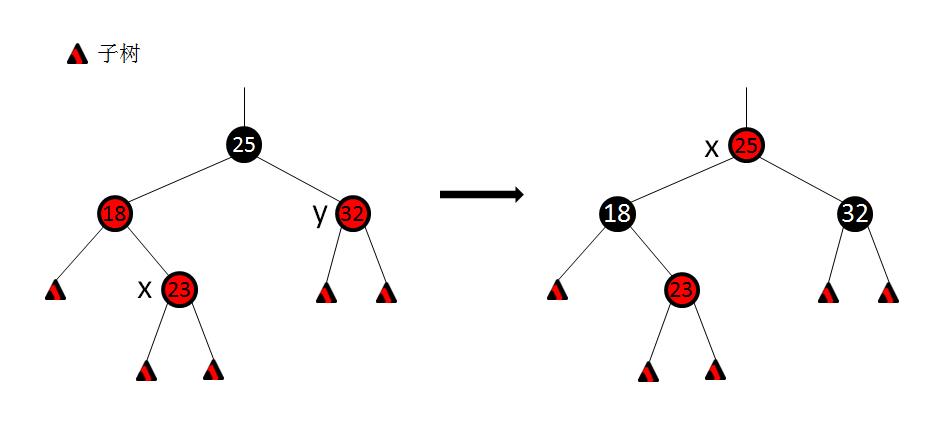
在情况1下做出的处理过程如图示。我们分析下,处理之前,性质4被破坏。然后做出如下处理: 1.将x的父结点设置为黑色。 2.将x的叔结点y设置为黑色。 3.将x的父结点的父结点设置为红色。 4.将x指向x的父结点的父结点。 这个处理过程首先恢复了性质4,也并没有破坏性质5,而且将x向上(根结点)推进了2层。 注:图中画的是x是右子结点的情况,x是左子结点也做相同的操作,没差别。 做完这个处理后,继续下一轮迭代。 情况2:x的叔结点y是黑色,且x的是一个右子结点。
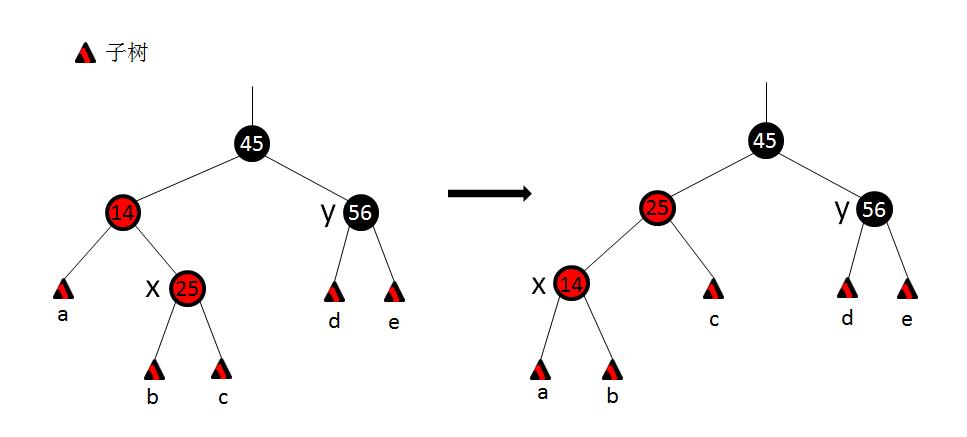
在情况2下做出的处理过程如图示。处理过程如下: 1.首先将x指向x的父结点。 2.对x做左旋转。 情况2只是个过渡阶段,过渡到情况3。 情况3:x的叔结点y是黑色,且x的是一个左子结点。
